
Cassandra資料分佈和副本
Cassandra中資料分佈和資料副本是分不開的。這個因為Cassandra被設計為一個在一組節點之間資料備份和分佈的點對點的系統。資料由表組織,並通過行健———主鍵標識。主鍵決定資料儲存在哪個節點。行的備份被稱為副本。當資料第一次寫入,這份資料也被稱作為一個副本。
當你建立一個叢集時,你必須指定如下資訊:1、虛擬節點:分配資料所有權到物理機器
2、分割槽器:決定了叢集中資料的分佈
3、副本策略:定義每行資料的副本放置策略
4、Snitch:定義網路拓撲資訊,以便副本策略放置副本
一致性雜湊
這部分將更詳細講解一致性雜湊機制在Cassandra叢集是如何分配資料的。一致性雜湊分割槽資料基於主鍵。例如,如果你有如下資料:

Cassandra會為每個主鍵分配一個雜湊值(分割槽器使用的是Murmur3Partitioner):
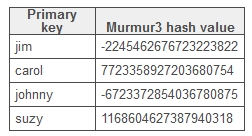
叢集中的每個節點負責雜湊環上的一個範圍(如果有虛擬節點,每個節點配置有256個,則有雜湊環上的256個雜湊值範圍):
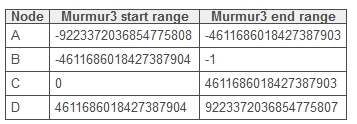
Cassandra根據主鍵和節點負責的雜湊值範圍來儲存資料。例如在4個沒有虛擬節點的叢集裡,上面例子的資料在Cassandra叢集的分佈如下:

存在虛擬節點的叢集是如何分佈資料的
在Cassandra1.2之前,你必須計算和分配一個單獨的令牌給叢集中的每個節點。根據其雜湊值每個令牌決定了節點和部分資料在雜湊環的位置。儘管Cassandra1.2之前的一致性雜湊設計在增加或刪除節點時允許移動資料,但它仍然需要做大量的工作。
從Cassandra1.2開始,Cassandra每個節點可以擁有很多個令牌(雜湊範圍)。這種新的模式叫做虛擬節點。虛擬節點允許每個節點擁有很多叢集中雜湊範圍。虛擬節點也是用一致性雜湊分佈資料,但是是用它卻不需要生成和分配令牌。
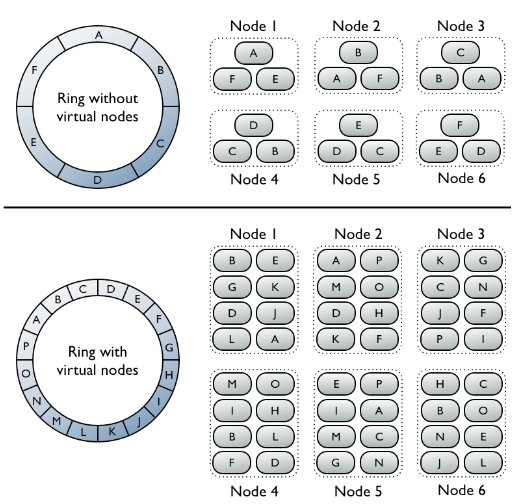
圖片的上部分是沒有虛擬節點的叢集。每個節點需要分配一個單獨的令牌以表示它在雜湊環上的位置。每個節點儲存資料由行健對映的令牌值對應的雜湊值範圍來決定。每個節點也包含叢集中其它節點的資料的副本。例如,E在節點5,6,1有3個副本。請注意,一個節點擁有雜湊環的一個連續區域。
圖片的下部分是有虛擬節點的叢集。在叢集中,環區域是隨機的而不是連續的。一行資料的儲存在行鍵雜湊值對應的環區域所在的節點上。
(20130717補充)對於對多資料中心的雜湊值範圍分佈,cassandra是根據叢集所有節點配置的虛擬節點數(num_tokens)平均分配的。例如有4個節點的叢集,每個節點配置的虛擬節點數都是256,那一致性雜湊環會平均分成4*256=1024份。
使用虛擬節點
虛擬節點簡化了Cassandra中的許多工:
1、你不需計算和分配每個節點的令牌。
2、當增加和刪除節點時不再需要重新平衡叢集。當一個節點加入叢集,它負責叢集中其它節點的平均資料;如果一個節點發生故障時,負載會均勻地分佈在叢集中的其他節點。
3、重建一個死節點很快,因為它儲存在叢集中其它節點上。並且資料會以增量的方式傳送,而不是等待直到驗證階段結束。
4、提高了叢集中異質機器的使用。你也指定適當虛擬節點的個數。
如果想知道更多虛擬節點的資訊,請參考Virtual nodes in Cassandra 1.2。
關於資料副本
Cassandra在多個節點上儲存副本以確保可用性和容錯。副本策略決定了副本的放置方法。叢集中的副本數量被稱為複製因子。複製因子為1的意思是指每行只有一個副本,複製因子為2的意思則每行有兩個副本,兩個副本不在同一個節點。所有副本同等重要,沒有主次之分。作為一般規則,副本因子不應超過在叢集中的節點的數目。但是,您可以增加副本因子,再加入所需的節點。當副本因子超過節點數,寫入不會成功,但讀取只要提供所期望的一致性級別即可滿足。
有兩種副本策略可以使用:
1、SimpleStrategy:僅用於1個數據中心的情況。
2、NetworkTopologyStrategy:對大多數部署強烈推薦使用此種策略,因為為未來的擴充套件需要它更容易擴充套件到多個數據中心。
SimpleStrategy:
僅用於單資料中心。額外的副本不考慮拓撲結構(機架和資料中心位置),按順時針方向找出下N個需要備份的節點。
NetworkTopologyStrategy:
用於多資料中心部署。這種策略可以指定每個資料中心的副本數。在同資料中心中,它按順時針方向直到另一個機架放置副本。它嘗試著將副本放置在不同的機架上,因為同一機架會經常因為電源,製冷和網路問題導致不可用。
每個資料中心配置多少個副本取決於兩個因素:(1)滿足本地讀取,而不會產生讀其它資料中心的延遲時間;(2)故障情況。
多資料中心叢集最常見的兩種配置方式是:
1、每個資料中心2個副本:此配置容忍每個副本組單節點的失敗,並且仍滿足一致性級別為ONE的讀。2、每個資料中心3個副本:此配置可以容忍在強一致性級別LOCAL_QUORUM基礎上的每個副本組1個節點的失敗,或者容忍一致性級別ONE的每個資料中心多個節點的失敗。
非對稱副本分組也是可能的。例如,你可以在每個資料中心配置3個副本用於實時應用程式請求,一個副本用於分析。
Cassandra資料分佈系列文章:
相關推薦
Cassandra資料分佈和副本
原文 Cassandra中資料分佈和資料副本是分不開的。這個因為Cassandra被設計為一個在一組節點之間資料備份和分佈的點對點的系統。資料由表組織,並通過行健———主鍵標識。主鍵決定資料儲存在哪個節點。行的備份被稱為副本。當資料第一次寫入,這份資料也被稱作為一個副本。
cassandra的資料分佈和副本策略
由於cassandra叢集的每個節點是對等的,所以資料的分佈和副本是在一起的。 資料是通過表組織起來的,通過行鍵(主鍵)標識,主鍵決定了資料儲存在哪個節點。每一行會有多個副本(replica),注意第一份資料也被稱為副本。 當建立一個叢集時,必須指定以下內容: 虛擬節點:把
從CDP解析資料備份和副本管理技術
資料資產是企業生存的根本,企業對資料資產保護的訴求推動資料保護技術的一次次變革,從原
Cassandra資料分佈之5分割槽器
分割槽器決定了資料在叢集中節點的分佈。分割槽器的功能是通過為每一行資料的分割槽鍵(partion key)分配一個令牌(token),然後通過這個令牌(token)將資料儲存在cassandra叢集中。 Cassandra提供瞭如下如下4種分割槽器。Cass
在 SQL 裡描述資料分佈情況的時候,有 Cardinality 和 Selectivity 兩個概念,有什麼區別?
What is the difference between cardinality and selectivity? In SQL, cardinality refers to the number of unique values in particular column. So, card
做出一段資料的概率分佈和概率密度?
就是將提問所說的“關於這個隨機變數的一組資料”進行分組(至於如何分組就看實際情況了,你應該會的吧?),得到一系列的組,例如32.5-42.5,42.5-52.5………,組數就是n。觀察數以y表示,例如yi(i為下標)=28,37,……。p的值,例如:p(u<42.5)=p[y<(42
Elasticsearch之資料如何在叢集中分佈和獲取。
路由文件到分片 當你索引一個文件,它被儲存在單獨一個主分片上。Elasticsearch是如何知道文件屬於哪個分片的呢?當你建立一個新文件,它是如何知道是應該儲存在分片1還是分片2上呢? 程序不能是隨機的,因為我們將來要檢索文件。事實上,他根據
Kafka 入門(二)--資料日誌、副本機制和消費策略
一、Kafka 資料日誌 1.主題 Topic Topic 是邏輯概念。 主題類似於分類,也可以理解為一個訊息的集合。每一條傳送到 Kafka 的訊息都會帶上一個主題資訊,表明屬於哪個主題。 Kafka 的主題是支援多使用者訂閱的,即一個主題可以有零個、一個或者多個消費者來訂閱該主題的訊息。 2.
Horizon7.1部署之一:view connection標準服務器和副本服務器安裝
horizon vew connetction準備了很久終於可以進入正題了,Horzion部署涉及的內容比較多,包括:域控制器和DNS服務器2臺 (HA)Horizon Veiw Connection服務器2臺 (HA)Horizon Composer 服務器1臺ThinApp服務器1臺SQL Server服
樸素貝葉斯算法資料整理和PHP 實現版本
樸素貝葉斯樸素貝葉斯算法簡潔http://blog.csdn.net/xlinsist/article/details/51236454 引言先前曾經看了一篇文章,一個老外程序員寫了一些很牛的Shell腳本,包括晚下班自動給老婆發短信啊,自動沖Coffee啊,自動掃描一個DBA發來的郵件啊, 等等。於是我也想
MongoDB 學習筆記之 分片和副本集混合運用
comment ssm table mmap insert ise class 學習 urn 分片和副本集混合運用: 基本架構圖: 搭建詳細配置: 3個shard + 3個replicat set + 3個configserver + 3個Mongos sh
kafka 分區和副本以及kafaka 執行流程,以及消息的高可用
是否存活 發送消息 分布 top 自己的 .net sink 端口號 本地 1、Kafka概覽 Apache下的項目Kafka(卡夫卡)是一個分布式流處理平臺,它的流行是因為卡夫卡系統的設計和操作簡單,能充分利用磁盤的順序讀寫特性。kafka每秒鐘能有百萬條消息的吞吐量,因
MongoDB之主從復制和副本集(四)
dmi 數據庫 mongo alloc already urn tor 安全性 db2 簡單主從復制 采用一主一從或一主多從的布署模式,可以將讀寫分離開來,提高數據庫的可用性,不過mongodb的主從模式並不能在主節點崩潰後,從節點替換主節點的工作,一般可以在開發階段使用
Pandas DataFrame 資料選取和過濾
This would allow chaining operations like: pd.read_csv('imdb.txt') .sort(columns='year') .filter(lambda x: x['year']>1990) # <---this is missin
資料庫分庫分表(sharding)系列(五) 一種支援自由規劃無須資料遷移和修改路由程式碼的Sharding擴容方案(轉)...
作為一種資料儲存層面上的水平伸縮解決方案,資料庫Sharding技術由來已久,很多海量資料系統在其發展演進的歷程中都曾經歷過分庫分表的Sharding改造階段。簡單地說,Sharding就是將原來單一資料庫按照一定的規則進行切分,把資料分散到多臺物理機(我們稱之為Shard)上儲存,從
資料型別和變數的總結
1. 變數 用來記錄狀態的變化。 字串、數字、列表、元組、字典 補充如何檢視 變數名在記憶體中的編號 id(變數名) 可變不可變: 1.可變的資料型別: 1)可變:列表 2)不可變:字串、數字、元組 訪問順序: 1.順序訪問:字串,列表,元組 2.對映: 字典 字典的元素查詢速度比列表
Beginning Data Exploration and Analysis with Apache Spark 使用Apache Spark開始資料探索和分析 中文字幕
使用Apache Spark開始資料探索和分析 中文字幕 Beginning Data Exploration and Analysis with Apache Spark 無論您是想要探索資料還是開發複雜的機器學習模型,資料準備都是任何資料專業人士的主要任務 Spark是一種引擎,它
資料結構和演算法之陣列奇數、偶數分離
今日,博主在面試一家外企的時候,要求白板寫程式。其中就有一道演算法設計題目,下面就來分享一下這道題的演算法思路和相關示例程式碼。 題目:要求將一個整形陣列中的奇數和偶數進行分離,偶數在
談Elasticsearch下分散式儲存的資料分佈
對於一個分散式儲存系統來說,資料是分散儲存在多個節點上的。如何讓資料均衡的分佈在不同節點上,來保證其高可用性?所謂均衡,是指系統中每個節點的負載是均勻的,並且在發現有不均勻的情況或者有節點增加/刪除時,能及時進行調整,保持均勻狀態。本文將探討Elasticsearch的資料分佈方法,
extmail資料備份和mysql庫備份
郵件檔案備份 [[email protected] extman]# df -h Filesystem Size Used Avail Use% Mounted on /dev/mapper/vg_mail-lv_root