
[Hadoop] 在Ubuntu系統上一步步搭建Hadoop(單機模式)
1 Hadoop的三種建立模式
單機模式操作是Hadoop的預設操作模式,當首次解壓Hadoop的原始碼包時,Hadoop無法瞭解硬體安裝環境,會保守地選擇最小配置,即單機模式。該模式主要用於開發除錯MapReduce程式的應用邏輯,而不會和守護程序互動,避免增加額外的複雜性。
偽分佈模式操作是指在“單節點叢集”上執行Hadoop,其中所有的守護程序都執行在同一臺機器上。該模式在單機模式操作之上多了程式碼除錯功能,可以查閱記憶體的使用情況、HDFS的輸入輸出以及守護程序之間的互動。
全分佈模式操作是指一種實際意義上的Hadoop叢集,其規模可從幾個節點的小叢集到成百上千個節點的大叢集,甚至是成千上萬的超大叢集。
本文只限於介紹單機模式,偽分佈模式需要在自己的Ubuntu系統下額外建立虛擬的系統,而全分佈模式需要搭建叢集的硬體設施。
2 建立Hadoop使用者組和Hadoop使用者
Step1:建立Hadoop使用者組:
~$ sudo addgroup hadoop
Step2:建立Hadoop使用者:
~$ sudo adduser -ingroup hadoop hadoop
回車後會提示輸入密碼,這是新建Hadoop的密碼,輸入兩次密碼敲回車即可。如下圖所示:

Step3:為Hadoop使用者新增許可權:
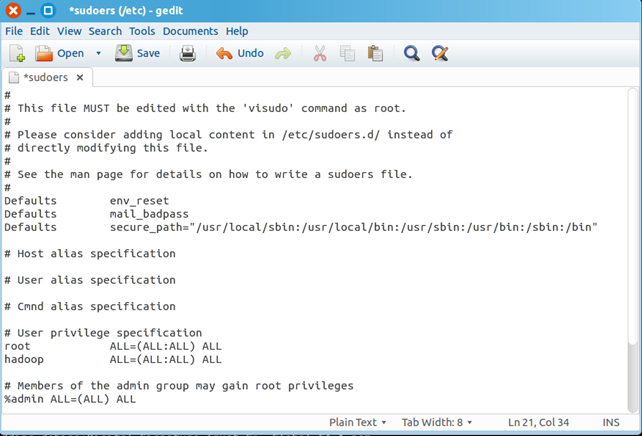
~$ sudo gedit /etc/sudoers
點選回車後,開啟sudoers檔案,在
root ALL=(ALL:ALL) ALL
後新增:
hadoop ALL=(ALL:ALL) ALL
注意:“hadoop” 後為"\t",而不是一個空格,一旦sudoers修改錯誤會引起很嚴重的後果(比如導致sudo命令無法正常使用,這時候只能通過root許可權進行復原)。修改後的sudoers檔案如下圖所示:
3 用新增hadoop使用者名稱登陸Ubuntu系統
~$ su - hadoop
輸入密碼即可。
4 安裝SSH
Step4:安裝Hadoop通訊需要的SSH:
~$ sudo apt-get install openssh-server
安裝完以後,啟動服務:
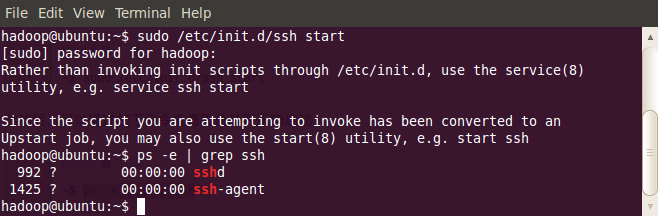
~$ sudo /etc/init.d/ssh start
啟動後,可以通過如下命令來確認服務是否正確啟動:
~$ ps -e | grep ss
如下圖所示:
作為一個安全通訊協議,使用時需要密碼,因此我們要設定成免密碼登入,生成私鑰和公鑰:
~$ ssh-keygen -t rsa -P ""
如下圖所示:
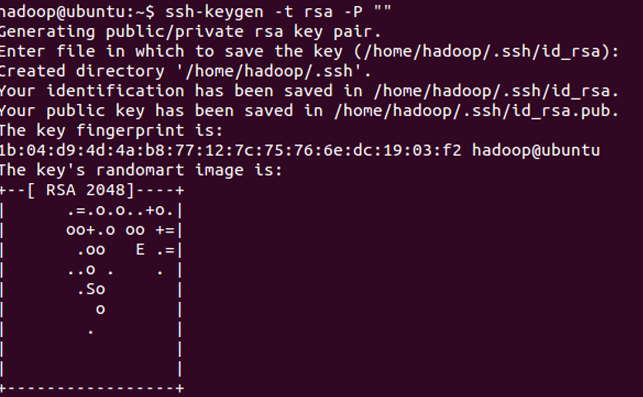
此時會在/home/hadoop/.ssh下生成兩個檔案:id_rsa和id_rsa.pub,前者為私鑰,後者為公鑰。現在我們將公鑰追加到authorized_keys中(authorized_keys用於儲存所有允許以當前使用者身份登入到ssh客戶端使用者的公鑰內容):
~$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
現在可以登入ssh確認以後登入時不用輸入密碼:
~$ ssh localhost

退出:
~$ exit
5 安裝Java
Step5:安裝Java:
~$ sudo apt-get install openjdk-6-jdk
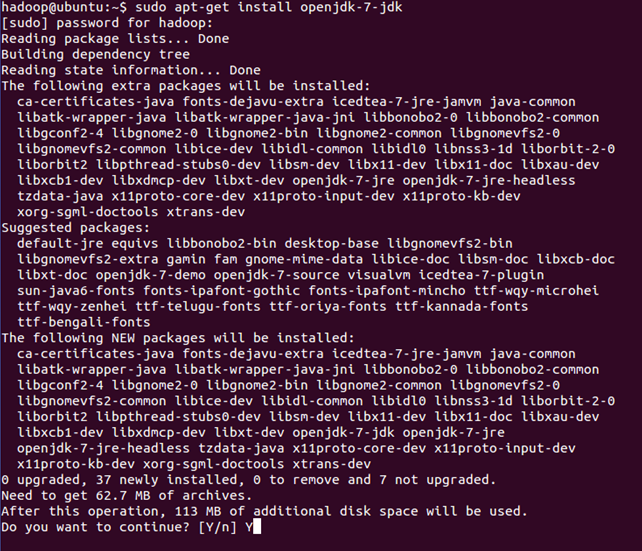
安裝完後,可以輸入如下指令檢視Java的版本:
~$ java -version
6 安裝和配置Hadoop
Step6:安裝Hadoop:
1)下載:
目前最新版本為2.7.0,可以根據自己的需要,安裝不同版本的Hadoop,下載地址:請點選這裡
2)解壓:
~$ sudo tar xzf hadoop-2.7.0.tar.gz
3)將hadoop移動到 /usr/local/hadoop目錄下:
~$ sudo mv hadoop-1.0.2 /usr/local/hadoop
4)要確保所有的操作都是在使用者hadoop下完成的:
~$ sudo chown -R hadoop:hadoop /usr/local/hadoop
Step7:配置Hadoop:
1)配置.bashrc:
配置該檔案,需要知道Java的安裝路徑,可以通過下面的程式碼檢視:
~$ update-alternatives - -config java
執行結果如下:

完整的路徑為:/usr/lib/jvm/java-7-openjdk-amd64/jre/bin/java,我們只取前面的部分 /usr/lib/jvm/java-7-openjdk-amd64。
修改.bashrc檔案:
~$ sudo gedit ~/.bashrc
該命令會開啟該檔案的編輯視窗,在檔案末尾追加下面內容,然後儲存,關閉編輯視窗。
#HADOOP VARIABLES START
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
export HADOOP_INSTALL=/usr/local/hadoop
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib"
#HADOOP VARIABLES END
使新增的環境變數生效:
~$ source ~/.bashrc
2)配置hadoop-env.sh
開啟hadoop-env.sh檔案:
~$ sudo gedit /usr/local/hadoop/etc/hadoop/hadoop-env.sh
找到JAVA_HOME變數,按如下進行修改:
~$ export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
修改後的hadoop-env.sh檔案如下所示:

使配置生效:
~$ source /usr/local/hadoop/conf/hadoop-env.sh
到這裡,單機模式的hadoop就全部安裝完畢了。
7 Hadoop測試
為了測試Hadoop安裝在正確性,我們可以用在帶的例子(比如WordCount)進行測試。
1) 在/usr/local/hadoop路徑下建立input資料夾
~$ mkdir input
2)拷貝 README.txt 到 input 資料夾
~$ cp README.txt input
3)執行WordCount程式例項
~$ bin/hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.7.0-sources.jar org.apache.hadoop.examples.WordCount input output

如果看到這些內容,那麼恭喜你,這說明你的Hadoop已經安裝成功了。
8 結語
從Ubuntu上安裝Hadoop的過程上可以看出,以前你覺得很困難,一直不敢嘗試的東西,其實可能它很簡單。只要你自己想學,就一步步地來,問題總能找到辦法來解決,在此與大家共勉。
9 參考內容
相關推薦
[Hadoop] 在Ubuntu系統上一步步搭建Hadoop(單機模式)
1 Hadoop的三種建立模式 單機模式操作是Hadoop的預設操作模式,當首次解壓Hadoop的原始碼包時,Hadoop無法瞭解硬體安裝環境,會保守地選擇最小配置,即單機模式。該模式主要用於開發除錯MapReduce程式的應用邏輯,而不會和守護程序互動,避免增加額外的複雜性。 偽分佈模式操作是指
linux centos7 從零搭建Hadoop離線處理平臺(單機模式)詳細
hadoop下載網址 http://archive.cloudera.com/cdh5/cdh/5/cdh-5.7.0 1、關閉防火牆 #停止防火牆,重啟後失效 sudo systemctl stop firewalld.service #禁用防火牆,重啟後依然有效 sudo syst
Hadoop 和 Hbase 的安裝與配置 (單機模式)
(一定要看最後我趟過的坑,如果安裝過程有問題,可參考最後我列出的問題及解決方法) 下載Hadoop安裝包 這裡安裝版本:hadoop-1.0.4.tar.gz 在安裝Hadoop之前,伺服器上一定要有安裝的jdk jdk安裝方式之一:在官網上下載Linux下的rpm
一步教你Docker安裝搭建redis(單機版)
1.Docker 安裝 Redis 方案一:使用docker拉取映象 查詢Docker Hub上的redis映象 #docker search redis 拉取
linux系統上傳和下載檔案(命令列)
SecureCRT與linux互相上傳和下載檔案(命令列) 在scrt中檔案的上傳或者下載除了使用命令列以後可以通過ftp,今天咋們就用命令列rz實現檔案的上傳, 上傳 1. 檔案的上傳
在阿里雲伺服器ECS上用Cloudera搭建叢集(隨記)
阿里雲購買的三臺機器,學習用的,所以基本上資源都是按最低買的,按流量時長計費,也花不了多少錢,並且一個賬戶下的機器不用配置,直接能ping通 三臺機器Slave2是我最早買的,安裝的環境都是是CentOS 7.3 64位 修改主機名 hostnamectl set-ho
一、Ubuntu14.04下安裝Hadoop2.4.0 (單機模式)
一、在Ubuntu下建立hadoop組和hadoop使用者 增加hadoop使用者組,同時在該組裡增加hadoop使用者,後續在涉及到hadoop操作時,我們使用該使用者。 1、建立hadoop使用者組 2、建立hadoop使用者
Linux下使用Docker部署nacos-server:1.4.0(單機模式),喪心病狂的我在半夜給UCloud提交了一份工單
## 1. 拉取nacos-server映象 進入 [Docker Hub](https://hub.docker.com/r/nacos/nacos-server/tags?page=1&ordering=last_updated) 檢視nacos-server最新版本為 `nacos-server:1.
linux ubuntu系統下基於eclipse的hadoop開發環境搭建
hadoop是基於linux作業系統的。 本文在linux ubuntu系統下,在eclipse下配置hadoop的開發環境。 這個開發環境對linux下的hadoop偽分散式配置有效,其他配置情況不明。 如果是完全分散式環境,需要重新設定core-site.xml,hdf
在ubuntu上搭建hadoop服務 (叢集模式)
環境:ubuntu 16.04hadoop-3.0.3參考:http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/ClusterSetup.html1.參考上一篇“在Ubuntu上搭建H
區塊鏈探索一(在阿裏雲Ubuntu系統上搭建一個以太坊)
data get date 阿裏 highlight The pro bubuko posit 測試機為阿裏雲主機 1.升級apt sudo apt-get update sudo apt-get -f install 2.安裝git sudo
ASP.NET Core 一步步搭建個人網站(7)_Linux系統移植
window std bce stat 能夠 rpm 設置 with err 摘要 考慮我們為什麽要選擇.NET Core? 因為它面向的是高性能服務器開發,拋卻了 AspNet 的臃腫組件,非常輕量,加上微軟的跨平臺戰略,對 Docker 的親和性,對於開發人員也非常友好
用FastDFS一步步搭建文件管理系統
鏈接 快速 存儲空間 功能 dir BE 主程序 還要 文件 轉載: 作者:bojiangzhou 出處:http://www.cnblogs.com/chiangchou/ 本文版權歸作者和博客園共有,歡迎轉載,但未經作者同意必須保留此段聲明,且在文章頁面明顯位置給出原
windows系統上執行spark、hadoop報錯Could not locate executable null\bin\winutils.exe in the Hadoop binaries
1.下載 winutils.exe:https://download.csdn.net/download/u010020897/10745623 2.將此檔案放置在某個目錄下,比如C:\winutils\bin\中。 3.在程式的一開始宣告:System.s
Ubuntu 18.04.1 LTS 搭建Hadoop環境
1.Ubuntu環境配置 本文使用Ubuntu 18.04.1 LTS,其他版本搭建過程基本一致。 建立hadoop使用者(可略) 1.建立新使用者 $ sudo useradd -m hadoop -s /bin/bash 2.設定密碼 $ sudo pass
FastDfs從一步步搭建到開發應用的上傳,下載,刪除
三、特別注意在下載的時候要在nginx中設定attachment-原檔案的名稱,這樣在下載下來後還是儲存時的名字,而且在下載的時候 也不會直接就在瀏覽器中開啟檔案不能下載,還有就是在下載的時候注意編碼格式才不至於出現下載的名稱亂碼, 四,這個要實現要在ng
(實用篇)一步步搭建 dubbo + zookeeper + SSM 系統
一、前言 本篇內容是基於前一篇(一步步搭建Spring+SpringMVC+MyBatis(SSM)框架)之後的第二個任務,在SSM框架的基礎上,整合構建dubbo與zookeeper。不得不說,此部分內容網上參考資料很多,但是真正適合我這種小白從零開始一步步入門搭建的不多
用FastDFS一步步搭建檔案管理系統
一、FastDFS介紹 1、簡介 FastDFS 是一個開源的高效能分散式檔案系統(DFS)。 它的主要功能包括:檔案儲存,檔案同步和檔案訪問,以及高容量和負載平衡。主要解決了海量資料儲存問題,特別適合以中小檔案(建議範圍:4KB < file_s
在ubuntu下搭建hadoop環境(單機配置)
電腦系統版本:windows7(32位) VMware版本:VMware10 1、安裝ubuntu 版本:16.04.1-desktop-i386 安裝完之後,需要重啟系統,重啟時可能會出現 piix4_smbus : Host SMBus controller
FastDFS一步步搭建檔案管理系統
1、環境virtualBox+CentOs7,前提必須確保主機和虛擬機器網路可以互通,並且虛擬機器可以訪問網路 2、centos下建立目錄/softpackages 3、下載安裝 libfastcommon,libfastcommon是從 FastDFS 和 Fa