
[Machine Learning] 機器學習常見演算法分類彙總

宣告:本篇博文根據http://www.ctocio.com/hotnews/15919.html整理,原作者張萌,尊重原創。
機器學習無疑是當前資料分析領域的一個熱點內容。很多人在平時的工作中都或多或少會用到機器學習的演算法。本文為您總結一下常見的機器學習演算法,以供您在工作和學習中參考。
機器學習的演算法很多。很多時候困惑人們都是,很多演算法是一類演算法,而有些演算法又是從其他演算法中延伸出來的。這裡,我們從兩個方面來給大家介紹,第一個方面是學習的方式,第二個方面是演算法的分類。
博主在原創基礎上加入了遺傳演算法(2.9)的介紹,這樣一來,本篇博文所包含的機器學習演算法更加全面豐富。該博文屬於總結型文章,如想具體理解每一個演算法的具體實現方法,還得針對逐個演算法進行學習和推敲。
1. 學習方式
根據資料型別的不同,對一個問題的建模有不同的方式。在機器學習或者人工智慧領域,人們首先會考慮演算法的學習方式。在機器學習領域,有幾種主要的學習方式。將演算法按照學習方式分類是一個不錯的想法,這樣可以讓人們在建模和演算法選擇的時候考慮能根據輸入資料來選擇最合適的演算法來獲得最好的結果。
1.1 監督式學習

在監督式學習下,輸入資料被稱為“訓練資料”,每組訓練資料有一個明確的標識或結果,如對防垃圾郵件系統中“垃圾郵件”“非垃圾郵件”,對手寫數字識別中的“1“,”2“,”3“,”4“等。在建立預測模型的時候,監督式學習建立一個學習過程,將預測結果與“訓練資料”的實際結果進行比較,不斷的調整預測模型,直到模型的預測結果達到一個預期的準確率。監督式學習的常見應用場景如分類問題和迴歸問題。常見演算法有邏輯迴歸(Logistic Regression)和反向傳遞神經網路(Back Propagation Neural Network)。
1.2 非監督式學習

在非監督式學習中,資料並不被特別標識,學習模型是為了推斷出資料的一些內在結構。常見的應用場景包括關聯規則的學習以及聚類等。常見演算法包括Apriori演算法以及k-Means演算法。
1.3 半監督式學習

在此學習方式下,輸入資料部分被標識,部分沒有被標識,這種學習模型可以用來進行預測,但是模型首先需要學習資料的內在結構以便合理的組織資料來進行預測。應用場景包括分類和迴歸,演算法包括一些對常用監督式學習演算法的延伸,這些演算法首先試圖對未標識資料進行建模,在此基礎上再對標識的資料進行預測。如圖論推理演算法(Graph Inference)或者拉普拉斯支援向量機(Laplacian SVM.)等。
1.4 強化學習

在這種學習模式下,輸入資料作為對模型的反饋,不像監督模型那樣,輸入資料僅僅是作為一個檢查模型對錯的方式,在強化學習下,輸入資料直接反饋到模型,模型必須對此立刻作出調整。常見的應用場景包括動態系統以及機器人控制等。常見演算法包括Q-Learning以及時間差學習(Temporal difference learning)。
在企業資料應用的場景下, 人們最常用的可能就是監督式學習和非監督式學習的模型。 在影象識別等領域,由於存在大量的非標識的資料和少量的可標識資料, 目前半監督式學習是一個很熱的話題。 而強化學習更多的應用在機器人控制及其他需要進行系統控制的領域。
2. 演算法分類
根據演算法的功能和形式的類似性,我們可以把演算法分類,比如說基於樹的演算法,基於神經網路的演算法等等。當然,機器學習的範圍非常龐大,有些演算法很難明確歸類到某一類。而對於有些分類來說,同一分類的演算法可以針對不同型別的問題。這裡,我們儘量把常用的演算法按照最容易理解的方式進行分類。
2.1 迴歸演算法

迴歸演算法是試圖採用對誤差的衡量來探索變數之間的關係的一類演算法。迴歸演算法是統計機器學習的利器。在機器學習領域,人們說起迴歸,有時候是指一類問題,有時候是指一類演算法,這一點常常會使初學者有所困惑。常見的迴歸演算法包括:最小二乘法(Ordinary Least Square),邏輯迴歸(Logistic Regression),逐步式迴歸(Stepwise Regression),多元自適應迴歸樣條(Multivariate Adaptive Regression Splines)以及本地散點平滑估計(Locally Estimated Scatterplot Smoothing)。
2.2 基於例項的演算法

基於例項的演算法常常用來對決策問題建立模型,這樣的模型常常先選取一批樣本資料,然後根據某些近似性把新資料與樣本資料進行比較。通過這種方式來尋找最佳的匹配。因此,基於例項的演算法常常也被稱為“贏家通吃”學習或者“基於記憶的學習”。常見的演算法包括 k-Nearest Neighbor(KNN), 學習向量量化(Learning Vector Quantization, LVQ),以及自組織對映演算法(Self-Organizing Map , SOM)。
2.3 正則化方法

正則化方法是其他演算法(通常是迴歸演算法)的延伸,根據演算法的複雜度對演算法進行調整。正則化方法通常對簡單模型予以獎勵而對複雜演算法予以懲罰。常見的演算法包括:Ridge Regression, Least Absolute Shrinkage and Selection Operator(LASSO),以及彈性網路(Elastic Net)。
2.4 決策樹學習

決策樹演算法根據資料的屬性採用樹狀結構建立決策模型, 決策樹模型常常用來解決分類和迴歸問題。常見的演算法包括:分類及迴歸樹(Classification And Regression Tree, CART), ID3 (Iterative Dichotomiser 3), C4.5, Chi-squared Automatic Interaction Detection(CHAID), Decision Stump, 隨機森林(Random Forest), 多元自適應迴歸樣條(MARS)以及梯度推進機(Gradient Boosting Machine, GBM)
2.5 貝葉斯方法

貝葉斯方法演算法是基於貝葉斯定理的一類演算法,主要用來解決分類和迴歸問題。常見演算法包括:樸素貝葉斯演算法,平均單依賴估計(Averaged One-Dependence Estimators, AODE),以及Bayesian Belief Network(BBN)。
2.6 基於核的演算法

基於核的演算法中最著名的莫過於支援向量機(SVM)了。 基於核的演算法把輸入資料對映到一個高階的向量空間, 在這些高階向量空間裡, 有些分類或者回歸問題能夠更容易的解決。 常見的基於核的演算法包括:支援向量機(Support Vector Machine, SVM), 徑向基函式(Radial Basis Function ,RBF), 以及線性判別分析(Linear Discriminate Analysis ,LDA)等。
2.7 聚類演算法

聚類,就像迴歸一樣,有時候人們描述的是一類問題,有時候描述的是一類演算法。聚類演算法通常按照中心點或者分層的方式對輸入資料進行歸併。所以的聚類演算法都試圖找到資料的內在結構,以便按照最大的共同點將資料進行歸類。常見的聚類演算法包括 k-Means演算法以及期望最大化演算法(Expectation Maximization, EM)。
2.8 關聯規則學習

關聯規則學習通過尋找最能夠解釋資料變數之間關係的規則,來找出大量多元資料集中有用的關聯規則。常見演算法包括 Apriori演算法和Eclat演算法等。
2.9 遺傳演算法(genetic algorithm)
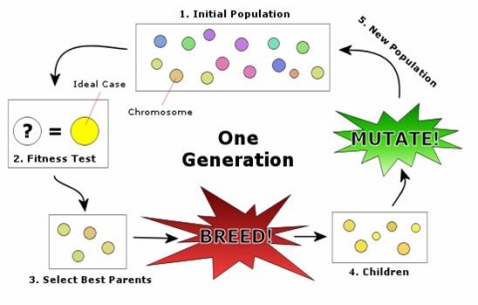
遺傳演算法模擬生物繁殖的突變、交換和達爾文的自然選擇(在每一生態環境中適者生存)。它把問題可能的解編碼為一個向量,稱為個體,向量的每一個元素稱為基因,並利用目標函式(相應於自然選擇標準)對群體(個體的集合)中的每一個個體進行評價,根據評價值(適應度)對個體進行選擇、交換、變異等遺傳操作,從而得到新的群體。遺傳演算法適用於非常複雜和困難的環境,比如,帶有大量噪聲和無關資料、事物不斷更新、問題目標不能明顯和精確地定義,以及通過很長的執行過程才能確定當前行為的價值等。同神經網路一樣,遺傳演算法的研究已經發展為人工智慧的一個獨立分支,其代表人物為霍勒德(J.H.Holland)。
2.10 人工神經網路

人工神經網路演算法模擬生物神經網路,是一類模式匹配演算法。通常用於解決分類和迴歸問題。人工神經網路是機器學習的一個龐大的分支,有幾百種不同的演算法。(其中深度學習就是其中的一類演算法,我們會單獨討論),重要的人工神經網路演算法包括:感知器神經網路(Perceptron Neural Network), 反向傳遞(Back Propagation), Hopfield網路,自組織對映(Self-Organizing Map, SOM)。
2.11 深度學習

深度學習演算法是對人工神經網路的發展。 在近期贏得了很多關注, 特別是百度也開始發力深度學習後, 更是在國內引起了很多關注。 在計算能力變得日益廉價的今天,深度學習試圖建立大得多也複雜得多的神經網路。很多深度學習的演算法是半監督式學習演算法,用來處理存在少量未標識資料的大資料集。常見的深度學習演算法包括:受限波爾茲曼機(Restricted Boltzmann Machine, RBN), Deep Belief Networks(DBN),卷積網路(Convolutional Network), 堆疊式自動編碼器(Stacked Auto-encoders)。
2.12 降低維度演算法

像聚類演算法一樣,降低維度演算法試圖分析資料的內在結構,不過降低維度演算法是以非監督學習的方式試圖利用較少的資訊來歸納或者解釋資料。這類演算法可以用於高維資料的視覺化或者用來簡化資料以便監督式學習使用。常見的演算法包括:主成份分析(Principle Component Analysis, PCA),偏最小二乘迴歸(Partial Least Square Regression,PLS), Sammon對映,多維尺度(Multi-Dimensional Scaling, MDS), 投影追蹤(Projection Pursuit)等。
2.13 整合演算法

整合演算法用一些相對較弱的學習模型獨立地就同樣的樣本進行訓練,然後把結果整合起來進行整體預測。整合演算法的主要難點在於究竟整合哪些獨立的較弱的學習模型以及如何把學習結果整合起來。這是一類非常強大的演算法,同時也非常流行。常見的演算法包括:Boosting, Bootstrapped Aggregation(Bagging), AdaBoost,堆疊泛化(Stacked Generalization, Blending),梯度推進機(Gradient Boosting Machine, GBM),隨機森林(Random Forest),GBDT(Gradient Boosting Decision Tree)。
相關推薦
[Machine Learning] 機器學習常見演算法分類彙總
宣告:本篇博文根據http://www.ctocio.com/hotnews/15919.html整理,原作者張萌,尊重原創。 機器學習無疑是當前資料分析領域的一個熱點內容。很多人在平時的工作中都或多或少會用到機器學習的演算法。本文為您總結一下常見的機器學習演算法,以供您在工作和學習中參考。
【機器學習】機器學習常見演算法分類彙總
轉自http://www.ctocio.com/hotnews/15919.html,尊重原創 機器學習無疑是當前資料分析領域的一個熱點內容。很多人在平時的工作中都或多或少會用到機器學習的演算法。這裡IT經理網為您總結一下常見的機器學習演算法,以供您在工作和學習中參
機器學習常見演算法分類彙總
機器學習無疑是當前資料分析領域的一個熱點內容。很多人在平時的工作中都或多或少會用到機器學習的演算法。這裡 IT 經理網為您總結一下常見的機器學習演算法,以供您在工作和學習中參考。 機器學習的演算法很多。很多時候困惑人們都是,很多演算法是一類演算法,而有些演算
機器學習常見演算法分類,演算法優缺點彙總
機器學習無疑是當前資料分析領域的一個熱點內容。很多人在平時的工作中都或多或少會用到機器學習的演算法。本文為您總結一下常見的機器學習演算法,以供您在工作和學習中參考。 機器學習的演算法很多。很多時候困惑人們都是,很多演算
Machine Learning:機器學習演算法
原文連結:https://riboseyim.github.io/2018/02/10/Machine-Learning-Algorithms/ 摘要 機器學習演算法分類:監督學習、半監督學習、無監督學習、強化學習 基本的機器學習演算法:線性迴歸、支援向量機(SVM)、最近鄰居(KNN)、邏輯迴歸、決策
Machine Learning機器學習公開課彙總
機器學習目前比較熱,網上也散落著很多相關的公開課和學習資源,這裡基於課程圖譜的機器學習公開課標籤做一個彙總整理,便於大家參考對比。 1、Coursera上斯坦福大學Andrew Ng教授的“機器學習公開課”: 機器學習入門課程首選,斯坦福大學教授,Coursera聯合
Machine Learning:機器學習算法
強化學習 支持向量 樸素 隨機森林 圖片 learn 樸素貝葉斯 支持 目錄 原文鏈接:https://riboseyim.github.io/2018/02/10/Machine-Learning-Algorithms/ 摘要 機器學習算法分類:監督學習、半監督學習、無監
Machine learning (機器學習)
就機器學習的課程而言,推薦看網易公開課斯坦福大學的Machine learning,其中涉及的具體內容如下, 算是一個循序漸進的進階步驟: 學習這門課程前的準備課程: 1.計算機學科的基礎知識,基本技能及原理; 2.大O的含義及一些資料結構(列,棧,
machine learning 機器學習入門(三)
分類和邏輯迴歸 在之前說過了線性迴歸的一些問題,線性迴歸常常用在一些預測值為連續的情況下,但生活中有的結果是以離散的形態分佈的,比如下雨還是不下雨,瀏覽到新聞會點選還是不會點選,看到商品買還是不買,這
Data Leakage in Machine Learning 機器學習訓練中的資料洩漏
refer to: https://www.kaggle.com/dansbecker/data-leakage There are two main types of leakage: Leaky Predictors and a Leaky Validation Strategies. L
Machine Learning機器學習入門
機器學習簡單介紹 machine learning是從資料中提取知識,是統計學,人工智慧和電腦科學交叉的研究領域。 機器學習演算法是能夠將決策過程自動化的演算法,決策過程是從已知的示例中泛化得到的: 監督學習(supervised learning):使用者將成對的輸入和
[Machine Learning] 機器學習資源大全
閱讀目錄 本文彙編了一些機器學習領域的框架、庫以及軟體(按程式語言排序)。 1. C++ 1.1 計算機視覺 CCV —基於C語言/提供快取/核心的機器視覺庫,新穎的機器視覺庫
機器學習常見演算法及原理總結(乾貨)
樸素貝葉斯 參考[1] 事件A和B同時發生的概率為在A發生的情況下發生B或者在B發生的情況下發生A P(A∩B)=P(A)∗P(B|A)=P(B)∗P(A|B) 所以有: P(A|B)=P(B|A)∗P(A)P(B) 對於給出的待分類項,求解在此項出現的條件下各個目標類別出
Amazon Machine Learning 機器學習_機器學習服務
20 多年來,Amazon 在人工智慧領域投入了大量資金。機器學習 (ML) 演算法驅動了我們的許多內部系統。這也是我們客戶所體驗的功能的核心 – 從我們運營中心的路徑優化和 Amazon.com 的推薦引擎到 Alexa 提供技術支援的 Echo、我們的無人駕駛飛機 Prime Air 以
機器學習常見演算法優缺點總結
K近鄰:演算法採用測量不同特徵值之間的距離的方法進行分類。 優點: 1.簡單好用,容易理解,精度高,理論成熟,既可以用來做分類也可以用來做迴歸; 2.可用於數值型資料和離散型資料; 3.訓練時間
【整理自用】統計學習、機器學習常見演算法(整理更新)
K近鄰法 詳見《統計學習》P53頁。 程式碼收藏90Zeng的部落格Kd樹的c++實現。 在利用kd樹搜尋最鄰近點的時候有一句話: 當前最近點一定存在於該結點一個子結點對應的區域,檢查子結點的父結點的另一子結點對應的區域是否有更近的點。具體做法是,
機器學習常見演算法總結(二)
5. Adaboost adaboost演算法通俗地講,就是在一個數據集上的隨機資料使用一個分類訓練多次,每次對分類正確的資料賦權值較小,同時增大分類錯誤的資料的權重,如此反覆迭代,直到達到所需的要求。Adaboost演算法步驟如下: 步驟1. 首先初
Machine Learning機器學習自學資料整理
機器學習目前比較熱,網上也散落著很多相關的公開課和學習資源,做一個彙總整理,便於大家參考對比。希望大家持續補充 |– 手冊類 |--- 課程圖譜部落格:http://blog.coursegraph.com/ |--- W3shool 關
機器學習常見演算法總結+ 面試題
1.http://kubicode.me/2015/08/16/Machine%20Learning/Algorithm-Summary-for-Interview/ 2.http://kubicode.me/2015/08/16/Machine%20Learning/Co
機器學習常見演算法總結(面試用)
樸素貝葉斯 參考[1] 事件A和B同時發生的概率為在A發生的情況下發生B或者在B發生的情況下發生A P(A∩B)=P(A)∗P(B|A)=P(B)∗P(A|B) 所以有: P(A|B)=P(B|A)∗P(A)P(B) 對於給出的待分