
半小時學完Pandas
阿新 • • 發佈:2019-01-13
前面學了Numpy,numpy能夠幫助我們處理數值,但是pandas除了處理數值之外(基於numpy),還能夠幫助我們處理其他型別的資料,同樣半小時學完下面的內容是沒問題的。
pandas主要是兩種資料型別
- Series 一維,帶標籤陣列
- DataFrame 二維,Series容器
第一部分:Series 建立陣列,陣列的索引和切片
In [1]: import pandas as pd #導包 In [2]: t = pd.Series([1,2,3,4,5]) #建立Series型別的一維陣列 In [3]: t Out[3]: #輸出的第一列0-4也就是標籤 可以在建立的時候自己指定,使用index屬性 0 1 1 2 2 3 3 4 4 5 dtype: int64 In [4]: type(t) #t的型別是Series Out[4]: pandas.core.series.Series In [5]: t.dtype Out[5]: dtype('int64') In [6]: t2 = pd.Series([5,6,3,2,9],index=list("abcde")) #建立帶標籤的陣列,使用index屬性 In [7]: t2 Out[7]: a 5 b 6 c 3 d 2 e 9 dtype: int64 #使用字典來建立陣列,key作為標籤,value作為陣列中的元素 In [8]: d = {"name":"Jack","age":20,"sex":"male"} In [9]: d Out[9]: {'name': 'Jack', 'age': 20, 'sex': 'male'} #傳入字典,建立陣列 In [10]: t3 = pd.Series(d) In [11]: t3 Out[11]: age 20 name Jack sex male dtype: object In [12]: t3.dtype Out[12]: dtype('O') #根據標籤來取值 In [13]: t3["age"] Out[13]: 20 In [14]: t3["name"] Out[14]: 'Jack' #索引值,0開始 In [15]: t3[1] Out[15]: 'Jack' #取值方法跟列表和numpy是一樣的 In [16]: t3[1:] Out[16]: name Jack sex male dtype: object In [17]: t3[0:2:1] Out[17]: age 20 name Jack dtype: object #根據索引取不連續的多個值 In [18]: t3[[0,2]] Out[18]: age 20 sex male dtype: object #根據標籤取多個值 In [19]: t3[["name","age"]] Out[19]: name Jack age 20 dtype: object #獲取陣列的標籤 In [20]: t3.index Out[20]: Index(['age', 'name', 'sex'], dtype='object') #遍歷標籤 In [21]: for i in t3.index: print(i) age name sex #獲取陣列的值 In [22]: t3.values Out[22]: array([20, 'Jack', 'male'], dtype=object) In [23]: for i in t3.values: print(i) 20 Jack male #獲取連續標籤 In [24]: t3.index[:2] Out[24]: Index(['age', 'name'], dtype='object')
第二部分:DataFrame建立陣列,常用方法
In [1]: import pandas as pd In [2]: import numpy as np #建立二維陣列,型別DataFrame In [7]: t = pd.DataFrame(np.arange(5,29).reshape(4,6)) In [8]: t Out[8]: #可以看到索引也是二維的,但是也可以自己指定索引 0 1 2 3 4 5 0 5 6 7 8 9 10 1 11 12 13 14 15 16 2 17 18 19 20 21 22 3 23 24 25 26 27 28 #使用index和columns來指定橫縱索引和豎軸索引 In [9]: t2 = pd.DataFrame(np.arange(12).reshape((3,4)),index=list("abc"),columns=list("WXYZ")) In [10]: t2 Out[10]: W X Y Z a 0 1 2 3 b 4 5 6 7 c 8 9 10 11 #使用字典來建立DataFrame,key為豎軸索引 In [11]: d = {"name":["zhangsan","lisi"],"age":[20,18],"address":["Peking","Shanghai"]} In [12]: d Out[12]: {'name': ['zhangsan', 'lisi'], 'age': [20, 18], 'address': ['Peking', 'Shanghai']} In [13]: t3 = pd.DataFrame(d) In [14]: t3 Out[14]: address age name 0 Peking 20 zhangsan 1 Shanghai 18 lisi In [15]: d2 = [{"name":"xiaohong","age":18,"tel":10089},{"name":"xiaohong","tel":10089}, ...: {"name":"xiaohong","age":18}] In [16]: d2 Out[16]: [{'name': 'xiaohong', 'age': 18, 'tel': 10089}, {'name': 'xiaohong', 'tel': 10089}, {'name': 'xiaohong', 'age': 18}] In [17]: t4 = pd.DataFrame(d2) In [18]: t4 Out[18]: age name tel 0 18.0 xiaohong 10089.0 1 NaN xiaohong 10089.0 2 18.0 xiaohong NaN #DataFrame的一些屬性 In [19]: t3.shape Out[19]: (2, 3) In [20]: t3.dtypes Out[20]: address object age int64 name object dtype: object In [21]: t3.index Out[21]: RangeIndex(start=0, stop=2, step=1) In [22]: t3.columns Out[22]: Index(['address', 'age', 'name'], dtype='object') In [23]: t3.values Out[23]: array([['Peking', 20, 'zhangsan'], ['Shanghai', 18, 'lisi']], dtype=object) In [25]: t3.head(1)#獲取頭一行 Out[25]: address age name 0 Peking 20 zhangsan In [26]: t3.tail(1)#獲取最後兩行 Out[26]: address age name 1 Shanghai 18 lisi In [27]: t3.info() #相關資訊概覽 <class 'pandas.core.frame.DataFrame'> RangeIndex: 2 entries, 0 to 1 Data columns (total 3 columns): address 2 non-null object age 2 non-null int64 name 2 non-null object dtypes: int64(1), object(2) memory usage: 72.0+ bytes
第三部分:DataFrame讀取檔案,讀取行列操作
#讀取檔案,這裡讀取的是csv檔案,還提供了其他的比如讀取json檔案的方法 In [47]: df = pd.read_csv("D:/dogNames2.csv") #讀取結果是DataFrame型別,我們取頭4行看看 In [48]: df.head(4) Out[48]: Row_Labels Count_AnimalName 0 1 1 1 2 2 2 40804 1 3 90201 1 #取2-5行 注意:方括號寫數字,表示取行,對行進行操作;寫字串,表示取列索引,對列進行操作 In [49]: df[2:5] Out[49]: Row_Labels Count_AnimalName 2 40804 1 3 90201 1 4 90203 1 In [50]: df[:5] Out[50]: Row_Labels Count_AnimalName 0 1 1 1 2 2 2 40804 1 3 90201 1 4 90203 1 In [51]: df["Row_Labels"][:5] Out[51]: 0 1 1 2 2 40804 3 90201 4 90203 Name: Row_Labels, dtype: object In [52]: df["Row_Labels"].index Out[52]: RangeIndex(start=0, stop=16220, step=1) In [53]: df[2:5]["Row_Labels"] Out[53]: 2 40804 3 90201 4 90203 Name: Row_Labels, dtype: object In [54]: print(df[2:5]["Row_Labels"]) 2 40804 3 90201 4 90203 Name: Row_Labels, dtype: object In [55]: type(df[2:5]["Row_Labels"]) Out[55]: pandas.core.series.Series #按行讀取的結果是DataFrame型別 In [56]: type(df[2:5]) Out[56]: pandas.core.frame.DataFrame #按照列讀取的結果是Series型別 In [58]: type(df["Row_Labels"]) Out[58]: pandas.core.series.Series #還有更多的經過pandas優化過的選擇方式: #df.loc 通過標籤索引行資料 #df.iloc 通過位置獲取行資料 In [71]: t3 = pd.DataFrame(np.arange(12).reshape(3,4),index=list("abc"),columns=list("WXYZ")) In [72]: t3 Out[72]: W X Y Z a 0 1 2 3 b 4 5 6 7 c 8 9 10 11 #逗號前寫行,可以取一行,連續多行,不連續多行,逗號後表示列,取法一樣。 In [73]: t3.loc["a","W"] Out[73]: 0 In [74]: t3.loc[:"c","W":"Y"] Out[74]: W X Y a 0 1 2 b 4 5 6 c 8 9 10 In [75]: t3.loc[["a","c"],["W","Z"]] Out[75]: W Z a 0 3 c 8 11 In [76]: t3.iloc[1] Out[76]: W 4 X 5 Y 6 Z 7 Name: b, dtype: int32 In [77]: t3.iloc[[0,1]] Out[77]: W X Y Z a 0 1 2 3 b 4 5 6 7 In [78]: t3.iloc[0,1] Out[78]: 1 In [79]: t3.iloc[0,[1,2,3]] Out[79]: X 1 Y 2 Z 3 Name: a, dtype: int32 In [80]: t3.iloc[:2,0:3] Out[80]: W X Y a 0 1 2 b 4 5 6 #看下型別,Series 什麼時候是Series型別什麼時候是DataFrame型別是容易知道的 In [81]: type(t3.iloc[1]) Out[81]: pandas.core.series.Series In [84]: type(t3.iloc[:,2]) Out[84]: pandas.core.series.Series
第四部分:Pandas的布林型別索引,str操作,缺失資料的處理,常用統計方法
#假如我們想找到所有的使用次數超過700並且名字的字串的長度大於4的狗的名字,應該怎麼選擇?
In [85]: df = pd.read_csv("D:/dogNames2.csv") #讀取csv檔案
In [89]: df.head(10) #取前10行資料看看格式
Out[89]:
Row_Labels Count_AnimalName
0 1 1
1 2 2
2 40804 1
3 90201 1
4 90203 1
5 102201 1
6 3010271 1
7 MARCH 2
8 APRIL 51
9 AUGUST 14
#解答問題 注意: & 表示且,|表示或
In [90]: df[(df["Row_Labels"].str.len() > 4) & (df["Count_AnimalName"]>700)]
Out[90]:
Row_Labels Count_AnimalName
1156 BELLA 1195
2660 CHARLIE 856
8552 LUCKY 723
12368 ROCKY 823
In [91]: t3 = pd.DataFrame(np.arange(12).reshape(3,4),index=list("abc"),columns=list("WXYZ"))
In [92]: t3
Out[92]:
W X Y Z
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
In [93]: t3.iloc[1:,2:] = np.nan
In [94]: t3
Out[94]:
W X Y Z
a 0 1 2.0 3.0
b 4 5 NaN NaN
c 8 9 NaN NaN
In [95]: pd.isnull(t3)
Out[95]:
W X Y Z
a False False False False
b False False True True
c False False True True
In [96]: t3["W"]
Out[96]:
a 0
b 4
c 8
Name: W, dtype: int32
In [97]: t3["Y"]
Out[97]:
a 2.0
b NaN
c NaN
Name: Y, dtype: float64
#最外層的t3裡面是個Series型別,但是得到的是true對應的那一行
In [98]: t3[pd.notnull(t3["Y"])]
Out[98]:
W X Y Z
a 0 1 2.0 3.0
In [99]: pd.notnull(t3["Y"])
Out[99]:
a True
b False
c False
Name: Y, dtype: bool
In [100]: type(pd.notnull(t3["Y"]))
Out[100]: pandas.core.series.Series
In [101]: t3
Out[101]:
W X Y Z
a 0 1 2.0 3.0
b 4 5 NaN NaN
c 8 9 NaN NaN
#刪除存在nan的那行,如果指定axis = 1那就是刪除列,預設how就是等於any
In [102]: t = t3.dropna(axis=0,how="any")
In [103]: t
Out[103]:
W X Y Z
a 0 1 2.0 3.0
In [104]: t3 #發現t3並沒有改變,操作後會返回個新的DataFrame
Out[104]:
W X Y Z
a 0 1 2.0 3.0
b 4 5 NaN NaN
c 8 9 NaN NaN
In [105]: t3.iloc[2]=np.nan #現在我們將最後一行全改成nan
In [106]: t3
Out[106]:
W X Y Z
a 0.0 1.0 2.0 3.0
b 4.0 5.0 NaN NaN
c NaN NaN NaN NaN
#刪除一行全為nan的那行
In [107]: t2 = t3.dropna(axis=0,how="all")
In [108]: t2
Out[108]:
W X Y Z
a 0.0 1.0 2.0 3.0
b 4.0 5.0 NaN NaN
In [109]: t3.dropna(axis=0,how="all",inplace=True)
In [110]: t3
Out[110]:
W X Y Z
a 0.0 1.0 2.0 3.0
b 4.0 5.0 NaN NaN
#注意這裡,inplace=True表示原地刪除,不會返回新的DataFrame,t3直接就改變了
In [111]: t3.dropna(axis=0,inplace=True)
In [112]: t3
Out[112]:
W X Y Z
a 0.0 1.0 2.0 3.0
#現在做一件事,處理DataFrame中的NaN,利用pandas的統計方法替換為該列的均值
In [115]: d2 = [{"name":"xiaohong","age":18,"tel":100},{"name":"xiaohong","tel":102},
...: {"name":"xiaohong","age":20}]
...: t2 = pd.DataFrame(d2)
In [116]: t2
Out[116]:
age name tel
0 18.0 xiaohong 100.0
1 NaN xiaohong 102.0
2 20.0 xiaohong NaN
#分別計算三個列屬性的均值預設的是axis=0,也可以指定axis=1,age的均值是19=(18+20)、2
In [117]: t2.mean()
Out[117]:
age 19.0
tel 101.0
dtype: float64
In [118]: type(t2.mean())
Out[118]: pandas.core.series.Series
In [119]: t2
Out[119]:
age name tel
0 18.0 xiaohong 100.0
1 NaN xiaohong 102.0
2 20.0 xiaohong NaN
#Nan處替換為均值
In [120]: t2.fillna(t2.mean())
Out[120]:
age name tel
0 18.0 xiaohong 100.0
1 19.0 xiaohong 102.0
2 20.0 xiaohong 101.0
#發現t2並沒有變,我們需要重新定義一個變數來接收
In [121]: t2
Out[121]:
age name tel
0 18.0 xiaohong 100.0
1 NaN xiaohong 102.0
2 20.0 xiaohong NaN
In [123]: t2 = t2.fillna(t2.mean())
In [124]: t2
Out[124]:
age name tel
0 18.0 xiaohong 100.0
1 19.0 xiaohong 102.0
2 20.0 xiaohong 101.0
小練習:現在有關於電影的csv檔案,內容如下
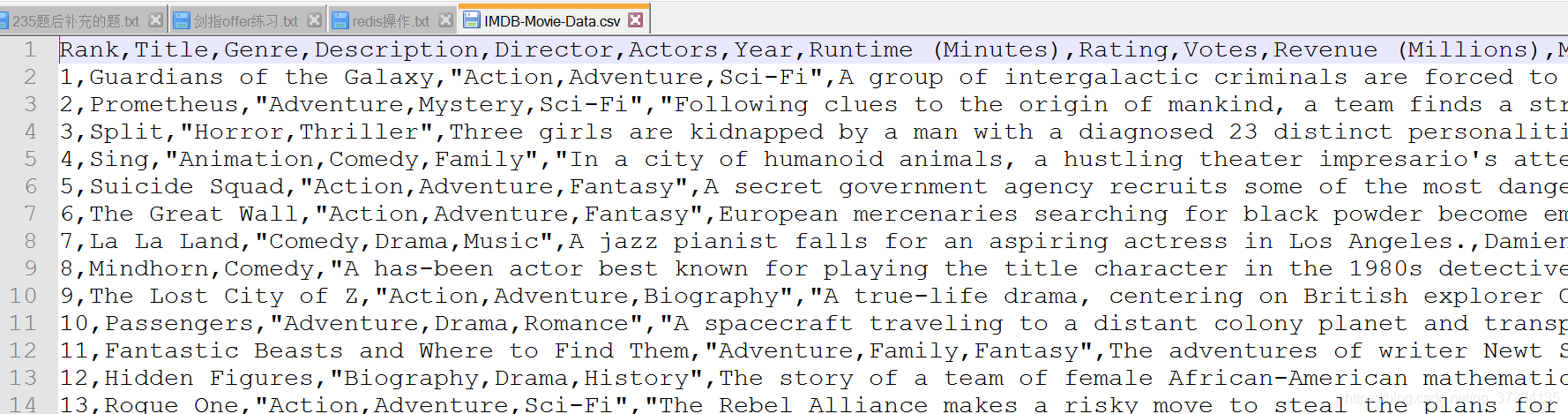
現在來做一些統計資訊
#1、統計電影分類(Genre屬性)
#讀取檔案
In [127]: df = pd.read_csv("D:\IMDB-Movie-Data.csv")
#轉換為str,分割,預設就是都好分割,檢視前5行的樣子
In [132]: df["Genre"].str.split()[:5]
Out[132]:
0 [Action,Adventure,Sci-Fi]
1 [Adventure,Mystery,Sci-Fi]
2 [Horror,Thriller]
3 [Animation,Comedy,Family]
4 [Action,Adventure,Fantasy]
Name: Genre, dtype: object
#放到list裡面去,接著檢視前五行的樣子
In [133]: temp_list = df["Genre"].str.split().tolist()
In [134]: temp_list[:5]
Out[134]:
[['Action,Adventure,Sci-Fi'],
['Adventure,Mystery,Sci-Fi'],
['Horror,Thriller'],
['Animation,Comedy,Family'],
['Action,Adventure,Fantasy']]
#轉到一個列表裡面,形成["",""]的形式 我們可以看到每個電影有幾種型別,接下來進行統計
In [135]: ans = list(set([j for i in temp_list for j in i]))
In [137]: ans[:10]
Out[137]:
['Animation,Family,Fantasy',
'Crime,Drama',
'Adventure,Drama,Horror',
'Comedy,Family,Fantasy',
'Comedy,Horror,Sci-Fi',
'Action,Horror,Thriller',
'Biography,Crime,Drama',
'Mystery,Thriller,Western',
'Drama,Family,Fantasy',
'Action,Horror,Mystery']
#接下來的操作打算寫到開發工具裡面了,如下
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
#讀取csv中的檔案 還可以讀SQL,json等
df = pd.read_csv("./IMDB-Movie-Data.csv")
# print(df)
# print(df["Genre"]) #分類
#統計分類的列表
temp_list = df["Genre"].str.split(",").tolist()#[[],[],[]]
genre_list = list(set(i for j in temp_list for i in j))
#構造全為0的陣列
zeros_df = pd.DataFrame(np.zeros((df.shape[0],len(genre_list))),columns=genre_list)
# print(zeros_df)
print(df.shape[0])
#給每個電影出現分類的位置賦值為1
for i in range(df.shape[0]):
zeros_df.loc[i,temp_list[i]] = 1
# print(zeros_df.head(3))
#統計每個分類的電影的數量和
genre_count = zeros_df.sum(axis = 0)
print(genre_count)
#排序
genre_count = genre_count.sort_values()
_x = genre_count.index
_y = genre_count.values
#畫圖
plt.figure(figsize=(20,8),dpi=80)
plt.bar(range(len(_x)),_y)
plt.xticks(range(len(_x)),_x)
plt.show()
第五部分:資料合併join,merge
#建立兩個二維陣列來進行測試
In [150]: df1 = pd.DataFrame(np.ones((2,4)),index=["A","B"],columns=list("abcd"))
...: df2 = pd.DataFrame(np.zeros((3,3)),index=["A","B","C"],columns=list("xyz"))
In [151]: df1
Out[151]:
a b c d
A 1.0 1.0 1.0 1.0
B 1.0 1.0 1.0 1.0
In [152]: df2
Out[152]:
x y z
A 0.0 0.0 0.0
B 0.0 0.0 0.0
C 0.0 0.0 0.0
#df1和df2合併,以df1為準 注意是往後拼接,df2多餘的就不要了 注意行索引一樣
In [153]: df1.join(df2)
Out[153]:
a b c d x y z
A 1.0 1.0 1.0 1.0 0.0 0.0 0.0
B 1.0 1.0 1.0 1.0 0.0 0.0 0.0
#df2和df1合併,以df1為準 注意是往後拼接,不足的補NaN
In [154]: df2.join(df1)
Out[154]:
x y z a b c d
A 0.0 0.0 0.0 1.0 1.0 1.0 1.0
B 0.0 0.0 0.0 1.0 1.0 1.0 1.0
C 0.0 0.0 0.0 NaN NaN NaN NaN
#合併後是會返回新的二維陣列的
In [155]: df1
Out[155]:
a b c d
A 1.0 1.0 1.0 1.0
B 1.0 1.0 1.0 1.0
In [160]: df1.merge(df3,on="a")
Out[160]:
a b c d f x
0 1 1.0 1.0 1.0 0 2
1 1 1.0 1.0 1.0 0 2
In [161]: df3 = pd.DataFrame(np.arange(9).reshape((3,3)),columns=list("fax"))
In [162]: df3
Out[162]:
f a x
0 0 1 2
1 3 4 5
2 6 7 8
#注意看這裡,on="a"表示按照a相等來進行拼接,相當於SQL中的inner join,為什麼df3中的第一行被拼接了兩次呢,因為df1的a那列兩個1都能跟df3中的第一行a列的那個一進行連線。
In [163]: df1.merge(df3,on="a")
Out[163]:
a b c d f x
0 1 1.0 1.0 1.0 0 2
1 1 1.0 1.0 1.0 0 2
#修改了df1的第一行a列那個1位100,再次拼接就只有一行了
In [165]: df1.loc["A","a"] = 100
In [166]: df1
Out[166]:
a b c d
A 100.0 1.0 1.0 1.0
B 1.0 1.0 1.0 1.0
In [167]: df1.merge(df3,on="a")
Out[167]:
a b c d f x
0 1 1.0 1.0 1.0 0 2
#下面的3個測試分別相當於SQL的外連線(?),左外連線,右外連線。
In [168]: df1.merge(df3,on="a",how="outer")
Out[168]:
a b c d f x
0 100.0 1.0 1.0 1.0 NaN NaN
1 1.0 1.0 1.0 1.0 0.0 2.0
2 4.0 NaN NaN NaN 3.0 5.0
3 7.0 NaN NaN NaN 6.0 8.0
In [169]: df1.merge(df3,on="a",how="left")
Out[169]:
a b c d f x
0 100 1.0 1.0 1.0 NaN NaN
1 1 1.0 1.0 1.0 0.0 2.0
In [170]: df1.merge(df3,on="a",how="right")
Out[170]:
a b c d f x
0 1.0 1.0 1.0 1.0 0 2
1 4.0 NaN NaN NaN 3 5
2 7.0 NaN NaN NaN 6 8
第六部分:分組與聚合
打算通過練習來體現,現有csv檔案如下
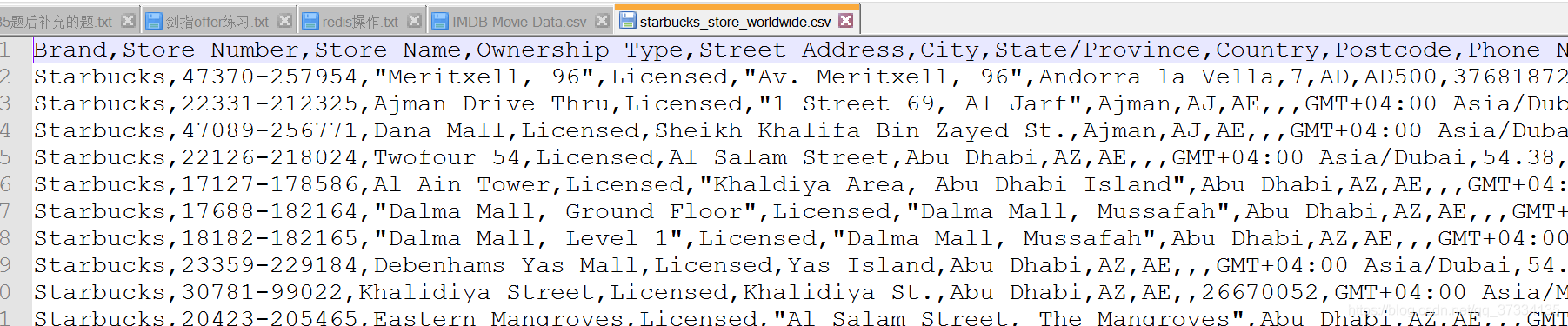
品牌是星巴克,現在來統計每個國家星巴克的數量
#讀取資料
In [178]: df = pd.read_csv("D:/starbucks_store_worldwide.csv")
#根據國家進行分組
In [179]: g = df.groupby(by="Country")
g是可以迭代的,下面給出迭代後結果
#可以進行遍歷
for i,j in grouped:
print(i)
print("-"*100)
print(j)
print("*"*100)
輸出:
****************************************************************************************************
ZA
----------------------------------------------------------------------------------------------------
Brand Store Number Store Name Ownership Type \
25597 Starbucks 47608-253804 Rosebank Mall Licensed
25598 Starbucks 47640-253809 Menlyn Maine Licensed
25599 Starbucks 47609-253286 Mall of Africa Licensed
Street Address City \
25597 Cnr Tyrwhitt and Cradock Avenue, Rosebank Johannesburg
25598 Shop 61B, Central Square, Cnr Aramist & Coroba... Menlyn
25599 Shop 2077, Upper Level, Waterfall City Midrand
State/Province Country Postcode Phone Number \
25597 GT ZA 2194 27873500159
25598 GT ZA 181 NaN
25599 GT ZA 1682 27873500215
Timezone Longitude Latitude
25597 GMT+000000 Africa/Johannesburg 28.04 -26.15
25598 GMT+000000 Africa/Johannesburg 28.28 -25.79
25599 GMT+000000 Africa/Johannesburg 28.11 -26.02
****************************************************************************************************
。。。
可以看到是 國家 + 每行資訊,現在我們只需要統計每個國家裡面的行數即可,比如ZA這個國家的行數就是3,即3家星巴克。
#統計完了
In [180]: g["Brand"].count()
Out[180]:
Country
AD 1
AE 144
AR 108
AT 18
AU 22
AW 3
AZ 4
BE 19
BG 5
BH 21
BN 5
...
現在我們來統計中國每個省的星巴克數量
In [182]: china_data = df[df["Country"]=="CN"]
In [185]: china_data.groupby(by="State/Province")["Brand"].count()
Out[185]:
State/Province
11 236
12 58
13 24
14 8
15 8
21 57
22 13
23 16
31 551
32 354
33 315
34 26
35 75
36 13
37 75
41 21
42 76
43 35
44 333
45 21
46 16
50 41
51 104
52 9
53 24
61 42
62 3
63 3
64 2
91 162
92 13
第七部分:索引與複合索引
In [190]: df1 = pd.DataFrame(np.ones((2,4)),index=["A","B"],columns=list("abcd"))
In [191]: df1
Out[191]:
a b c d
A 1.0 1.0 1.0 1.0
B 1.0 1.0 1.0 1.0
In [192]: df1.index = ["a","b"] #修改索引
In [193]: df1
Out[193]: #發現"A","B"被修改成了"a","b‘’
a b c d
a 1.0 1.0 1.0 1.0
b 1.0 1.0 1.0 1.0
In [195]: df1.reindex(["A","T"]) #重新修改後成了NaN
Out[195]:
a b c d
A NaN NaN NaN NaN
T NaN NaN NaN NaN
In [196]: df1 = df1.set_index("a") #將a那列作為行索引,a那列就消失了
In [197]: df1
Out[197]:
b c d
a
1.0 1.0 1.0 1.0
1.0 1.0 1.0 1.0
In [198]: df1 = pd.DataFrame(np.ones((2,4)),index=["A","B"],columns=list("abcd"))
In [199]: df1
Out[199]:
a b c d
A 1.0 1.0 1.0 1.0
B 1.0 1.0 1.0 1.0
#指定為False那麼a這列就不會消失了
In [200]: df1 = df1.set_index("a",drop=False)
In [201]: df1
Out[201]:
a b c d
a
1.0 1.0 1.0 1.0 1.0
1.0 1.0 1.0 1.0 1.0
第八部分:時間序列
#生成一段時間範圍 表示從什麼時候生成到什麼時候,freq是間隔,D表示天,10D表示10天,M表示month等。注意:時間格式下面寫的三種都可以,不要亂寫
In [204]: pd.date_range(start="20171201",end="20180101",freq="D")
Out[204]:
DatetimeIndex(['2017-12-01', '2017-12-02', '2017-12-03', '2017-12-04',
'2017-12-05', '2017-12-06', '2017-12-07', '2017-12-08',
'2017-12-09', '2017-12-10', '2017-12-11', '2017-12-12',
'2017-12-13', '2017-12-14', '2017-12-15', '2017-12-16',
'2017-12-17', '2017-12-18', '2017-12-19', '2017-12-20',
'2017-12-21', '2017-12-22', '2017-12-23', '2017-12-24',
'2017-12-25', '2017-12-26', '2017-12-27', '2017-12-28',
'2017-12-29', '2017-12-30', '2017-12-31', '2018-01-01'],
dtype='datetime64[ns]', freq='D')
In [205]: pd.date_range(start="20171201",end="20180101",freq="10D")
Out[205]: DatetimeIndex(['2017-12-01', '2017-12-11', '2017-12-21', '2017-12-31'], dtype='datetime64[ns]', freq='10D')
#periods表示生成的個數
In [206]: pd.date_range(start="2017-12-01",periods=10,freq="D")
Out[206]:
DatetimeIndex(['2017-12-01', '2017-12-02', '2017-12-03', '2017-12-04',
'2017-12-05', '2017-12-06', '2017-12-07', '2017-12-08',
'2017-12-09', '2017-12-10'],
dtype='datetime64[ns]', freq='D')
In [207]: pd.date_range(start="2017/12/01",periods=10,freq="M")
Out[207]:
DatetimeIndex(['2017-12-31', '2018-01-31', '2018-02-28', '2018-03-31',
'2018-04-30', '2018-05-31', '2018-06-30', '2018-07-31',
'2018-08-31', '2018-09-30'],
dtype='datetime64[ns]', freq='M')