
Mysql查詢優化——中間表方法優化count()統計大資料量總數問題
在上一篇博文我們提到,分頁有三種方法。其中,第三種是我們最常用的。然而,在實際應用過程中我們會發現,select count(*) from tname 語句在統計某表內記錄總數時,如果表內資料量達到一定規模(比如100W條),這個語句就會執行得非常慢。有什麼辦法可以加快統計出表內記錄總數呢?
這裡,我們需要藉助一箇中間表來記錄資料庫內各表記錄總數。然後,在我們需要知道某表的記錄總數來計算分頁數時直接查詢中間表獲取目的表的記錄總數即可。無需把目的表全部查詢一次然後逐一統計。
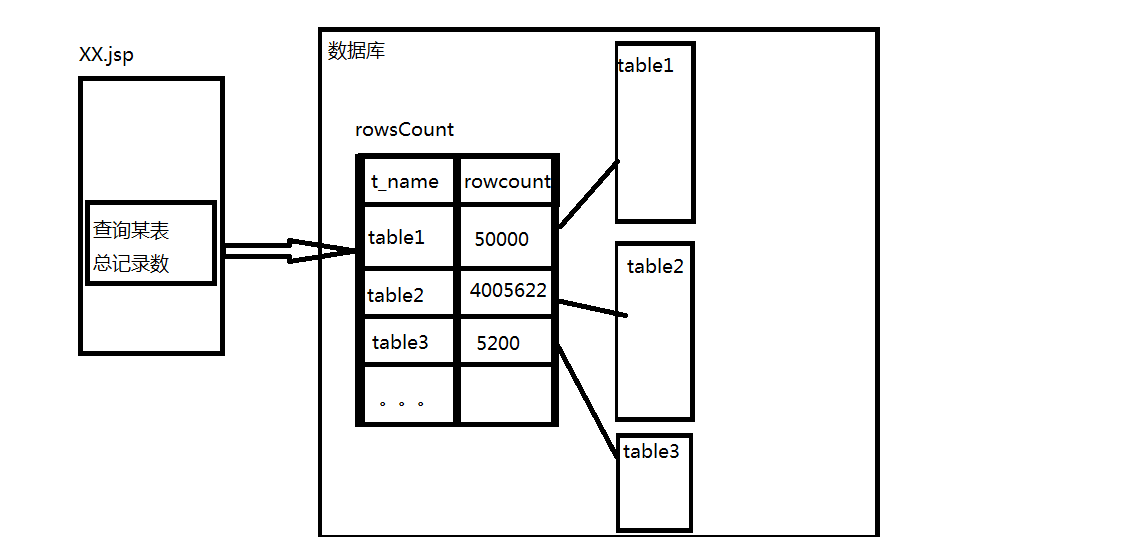
這裡有人要問了,這個中間表哪兒來的呢?嘿嘿,無需再用一個檔案來定期更新!資料庫已經為我們提供了一個很好的工具啦!那就是——觸發器。
觸發器是一種特殊的儲存過程。一般的儲存過程是通過儲存過程名直接呼叫,而觸發器主要是通過事件(增、刪、改)進行觸發而被執行的。其在表中資料發生變化時自動強制執行。所以,我們只需要為每個需要監聽的表建立一個觸發器,使得該表有增、刪操作時,自動對rowsCount中間表裡相應的記錄進行修改,即可同步更新中間表對各表的記錄。
這裡大致講一下觸發器的建立:我用的資料庫桌面工具是SQLyog。
在需要監聽的表上右鍵,選擇“建立觸發器”,工具會自動生成一些通用的程式碼如下:
CREATE
TRIGGER `資料庫名`.`觸發器名` BEFORE/AFTER INSERT/UPDATE/DELETE
ON `資料庫名`.`<Table Name>`
FOR EACH ROW
BEGIN
事件發生後執行的程式碼
END
監聽器有兩種:事前執行與事後執行。分別對應上面的BEFORE/AFTER.
事件型別有三種:插入、修改、刪除
監聽物件為:資料庫名.表名
事件發生後代碼:觸發器的主體部分。用於響應監聽物件發生所監聽的事件前/後所執行的sql操作。比如:修改某中間表中的資料來記錄監聽表的變化。
例項:為admin表建立監聽器,在admin表有資料插入後,啟用觸發器執行,更新pagecount中間表中,tablename為admin的那條記錄的total屬性,因為插入了一條記錄,所以total+1.
CREATE TRIGGER `counter` AFTER INSERTON `admin` FOR EACH ROW BEGIN UPDATE pagecount SET total=total+1 WHERE tablename = 'admin'; END;
相關推薦
Mysql查詢優化——中間表方法優化count()統計大資料量總數問題
在上一篇博文我們提到,分頁有三種方法。其中,第三種是我們最常用的。然而,在實際應用過程中我們會發現,select count(*) from tname 語句在統計某表內記錄總數時,如果表內資料量達到一定規模(比如100W條),這個語句就會執行得非常慢。有什麼辦法可以加快統計
Mysql查詢優化之 觸發器加中間表 方法優化count()統計大資料量總數問題 轉載請註明原文地址:http://www.cnblogs.com/ygj0930/p/6138288.ht
在上一篇博文我們提到,分頁有三種方法。其中,第三種是我們最常用的。然而,在實際應用過程中我們會發現,select count(*) from tname 語句在統計某表內記錄總數時,如果表內資料量達到一定規模(比如100W條),這個語句就會執行得非常慢。有什麼辦法可以加快統計出表內記錄總數呢?
MySQL大資料量分頁查詢方法及其優化 ---方法1: 直接使用資料庫提供的SQL語句 ---語句樣式: MySQL中,可用如下方法: SELECT * FROM 表名稱 LIMIT M,N ---適
測試實驗 1. 直接用limit start, count分頁語句, 也是我程式中用的方法: select * from product limit start, count 當起始頁較小時,查詢沒有效能問題,我們分別看下從10, 100, 1000, 10000開始分頁的執行時間(每頁取20條), 如
MySQL大資料量分頁查詢方法及其優化 MySQL大資料量分頁查詢方法及其優化
MySQL大資料量分頁查詢方法及其優化 ---方法1: 直接使用資料庫提供的SQL語句---語句樣式: MySQL中,可用如下方法: SELECT * FROM 表名稱 LIMIT M,N ---適應場景: 適用於資料量較少的情況(元組百/千級) --
MySQL大資料量分頁查詢方法及其優化
方法1: 直接使用資料庫提供的SQL語句 語句樣式: MySQL中,可用如下方法: SELECT * FROM 表名稱 LIMIT M,N 適應場景: 適用於資料量較少的情況(元組百/千級) 原因/缺點: 全表掃描,速度會很慢 且 有的資料庫結果集返回不穩定(如某次返回
大資料量表的查詢優化及索引使用
一、對於運算邏輯,儘可能將要統計的各專案整合在一個查詢語句中計算,而不是用分組條件或分專案呼叫多個查詢語句,而後在程式碼裡計算結果。 二、查詢語句的優化,諸如不用"select *"、多表關聯查詢時新增別名於查詢欄位上、避免使用in、not in關鍵字、非去除重複時用union all替換uni
MySQL 資料庫效能優化之表結構優化
很多人都將 資料庫設計正規化 作為資料庫表結構設計“聖經”,認為只要按照這個正規化需求設計,就能讓設計出來的表結構足夠優化,既能保證效能優異同時還能滿足擴充套件性要求。殊不知,在N年前被奉為“聖經”的資料庫設計3正規化早就已經不完全適用了。這裡我整理了一些比較常見的資料庫表結構設計方面的優化技巧,希
Mysql千萬級大資料量查詢優化
1.對查詢進行優化,應儘量避免全表掃描,首先應考慮在 where 及 order by 涉及的列上建立索引。2.應儘量避免在 where 子句中對欄位進行 null 值判斷,否則將導致引擎放棄使用索引而進行全表掃描,如:select id from t where num i
MySQL 大資料量表優化方案
單表優化 除非單表資料未來會一直不斷上漲(例如網路爬蟲),否則不要一開始就考慮拆分,拆分會帶來邏輯、部署、運維的各種複雜度 一般以整型值為主的表在 千萬級以下,字串為主的表在 五百萬以下是沒有太大問題的。而事實上很多時候 MySQL 單表的效能依然有不少優化空間,甚至能正
mysql limit做分頁查詢的優化(大資料量)
mysql limit查詢優化,由於limit經常用到,卻沒有注意,因為平時做的專案都比較小,所以也沒有考慮去怎麼優化,MYSQL的優化是非常重要的。其他最常用也最需要優化的就是limit。mysql的limit給分頁帶來了極大的方便,但資料量一大的時候,limit的效能就急
mysql 大資料量時 limit查詢優化
一般,我們在做分頁時,用的是語句如下:select * from table LIMIT 5,10; #返回第6-15行資料但是,如果資料量很大,比如>1000萬,則利用以上的查詢會非常慢,可以利用以下語句進行優化:Select * From table Where I
MySQL中針對大資料量常用技術:查詢優化,資料轉移
如今隨著網際網路的發展,資料的量級也是撐指數的增長,從GB到TB到PB。對資料的各種操作也是愈加的困難,傳統的關係性資料庫已經無法滿足快速查詢與插入資料的需求。這個時候NoSQL的出現暫時解決了這一危機。它通過降低資料的安全性,減少對事務的支援,減少對複雜查詢的支援,來獲取效能上的提升。但是,在有些場合
MYSQL查詢~ 存在一個表而不在另一個表中的數據
ng- isnull post alt idt 連接 pid name 一個 A、B兩表,找出ID字段中,存在A表,但是不存在B表的數據。A表總共13w數據,去重後大約3W條數據,B表有2W條數據,且B表的ID字段有索引。 方法一 使用 not in ,容易
afs在大資料量時查詢優化
afs查詢,mule報錯的問題 1.mule報錯的原因 a)mule預設請求響應時間為10s,當請求返回的時間超過10秒就會報錯 2.導致請求時間過長的原因 a)欄位沒有建索引,count(*)統計記錄總數耗時過長(283W記錄統計耗時8-9s) b)一次性請求數量過多(經測試500條資料4
大資料量 Mybatis 分頁外掛Count語句優化
前言 當在大數量的情況下,進行分頁查詢,統計總數時,會自動count一次,這個語句是在我們的查詢語句的基礎上巢狀一層,如: SELECT COUNT(*) FROM (主sql) 這樣在資料量大的情況下,會出問題,很容易cpu就跑滿了 優化 在mapper.xml
MYSQL查詢語句 group by 與having count()講解--玉米都督
在介紹GROUP BY 和 HAVING 子句前,我們必需先講講sql語言中一種特殊的函式:聚合函式, 例如SUM, COUNT, MAX, AVG等。這些函式和其它函式的根本區別就是它們一般作用在多條記錄上。 SELECT S
mysql大資料量下優化
1 優化sql和索引2 增加快取如:redis3 主從複製或主主複製,讀寫分離4 利用mysql自帶分割槽表5 先做垂直拆分,將一個大系統分為多個小系統,也就是分散式6 水平切分,要選擇一個合理的sharding key,為了有好的查詢效率,表結構也要改動,做一定的冗餘,應用也要改,sql中儘量帶shardi
mysql查詢哪張表資料最大
mysql資料庫中information_schema 資料庫儲存了資料庫很多資訊,可以通過查詢tables表來獲得所需要的表相關資訊。 mysql> select table_name,table_rows from tables order by table_rows
Mysql查詢語句——多表關聯查詢、子查詢
1.查詢一張表: select * from 表名; 2.查詢指定欄位:select 欄位1,欄位2,欄位3….from 表名; 3.where條件查詢:select 欄位1,欄位2,欄位3 frome 表名 where 條件表示式; 例:select
MYSQL查詢~ 存在一個表而不在另一個表中的資料
A、B兩表,找出ID欄位中,存在A表,但是不存在B表的資料。A表總共13w資料,去重後大約3W條資料,B表有2W條資料,且B表的ID欄位有索引。 方法一 使用 not in ,容易理解,效率低 ~執行時間為:1.395秒~ 1 select distinct A.