
Spark執行模式概述
不多說,直接上乾貨!
目前Apache Spark支援三種分散式部署方式,分別是standalone、spark on mesos和 spark on YARN,其中,第一種類似於MapReduce 1.0所採用的模式,內部實現了容錯性和資源管理,後兩種則是未來發展的趨勢,部分容錯性和資源管理交由統一的資源管理系統完成:讓Spark執行在一個通用的資源管理系統之上,這樣可以與其他計算框架,比如MapReduce,公用一個叢集資源,最大的好處是降低運維成本和提高資源利用率(資源按需分配)。本文將介紹這三種部署方式,並比較其優缺點。
推薦
1. Standalone模式
即獨立模式,自帶完整的服務,可單獨部署到一個叢集中,無需依賴任何其他資源管理系統。從一定程度上說,該模式是其他兩種的基礎。借鑑Spark開發模式,我們可以得到一種開發新型計算框架的一般思路:先設計出它的standalone模式,為了快速開發,起初不需要考慮服務(比如master/slave)的容錯性,之後再開發相應的wrapper,將stanlone模式下的服務原封不動的部署到資源管理系統yarn或者mesos上,由資源管理系統負責服務本身的容錯。目前Spark在standalone模式下是沒有任何單點故障問題的,這是藉助zookeeper實現的,思想類似於Hbase master單點故障解決方案。將Spark standalone與MapReduce比較,會發現它們兩個在架構上是完全一致的:
1) 都是由master/slaves服務組成的,且起初master均存在單點故障,後來均通過zookeeper解決(Apache MRv1的JobTracker仍存在單點問題,但CDH版本得到了解決);
2) 各個節點上的資源被抽象成粗粒度的slot,有多少slot就能同時執行多少task。不同的是,MapReduce將slot分為map
slot和reduce slot,它們分別只能供Map Task和Reduce
Task使用,而不能共享,這是MapReduce資源利率低效的原因之一,而Spark則更優化一些,它不區分slot型別,只有一種slot,可以供各種型別的Task使用,這種方式可以提高資源利用率,但是不夠靈活,不能為不同型別的Task定製slot資源
2. Spark On Mesos模式
這是很多公司採用的模式,官方推薦這種模式(當然,原因之一是血緣關係)。正是由於Spark開發之初就考慮到支援Mesos,因此,目前而言,Spark執行在Mesos上會比執行在YARN上更加靈活,更加自然。目前在Spark On Mesos環境中,使用者可選擇兩種排程模式之一執行自己的應用程式(可參考Andrew Xia的“Mesos Scheduling Mode on Spark”):
1) 粗粒度模式(Coarse-grained Mode):每個應用程式的執行環境由一個Dirver和若干個Executor組成,其中,每個Executor佔用若干資源,內部可執行多個Task(對應多少個“slot”)。應用程式的各個任務正式執行之前,需要將執行環境中的資源全部申請好,且執行過程中要一直佔用這些資源,即使不用,最後程式執行結束後,回收這些資源。舉個例子,比如你提交應用程式時,指定使用5個executor執行你的應用程式,每個executor佔用5GB記憶體和5個CPU,每個executor內部設定了5個slot,則Mesos需要先為executor分配資源並啟動它們,之後開始排程任務。另外,在程式執行過程中,mesos的master和slave並不知道executor內部各個task的執行情況,executor直接將任務狀態通過內部的通訊機制彙報給Driver,從一定程度上可以認為,每個應用程式利用mesos搭建了一個虛擬叢集自己使用。
2) 細粒度模式(Fine-grained Mode):鑑於粗粒度模式會造成大量資源浪費,Spark On Mesos還提供了另外一種排程模式:細粒度模式,這種模式類似於現在的雲端計算,思想是按需分配。與粗粒度模式一樣,應用程式啟動時,先會啟動executor,但每個executor佔用資源僅僅是自己執行所需的資源,不需要考慮將來要執行的任務,之後,mesos會為每個executor動態分配資源,每分配一些,便可以執行一個新任務,單個Task執行完之後可以馬上釋放對應的資源。每個Task會彙報狀態給Mesos slave和Mesos Master,便於更加細粒度管理和容錯,這種排程模式類似於MapReduce排程模式,每個Task完全獨立,優點是便於資源控制和隔離,但缺點也很明顯,短作業執行延遲大。
3. Spark On YARN模式
這是一種很有前景的部署模式。但限於YARN自身的發展,目前僅支援粗粒度模式(Coarse-grained Mode)。這是由於YARN上的Container資源是不可以動態伸縮的,一旦Container啟動之後,可使用的資源不能再發生變化,不過這個已經在YARN計劃中了。
spark on yarn 的支援兩種模式:
1) yarn-cluster:適用於生產環境;
2) yarn-client:適用於互動、除錯,希望立即看到app的輸出
yarn-cluster和yarn-client的區別在於yarn appMaster,每個yarn app例項有一個appMaster程序,是為app啟動的第一個container;負責從ResourceManager請求資源,獲取到資源後,告訴NodeManager為其啟動container。yarn-cluster和yarn-client模式內部實現還是有很大的區別。如果你需要用於生產環境,那麼請選擇yarn-cluster;而如果你僅僅是Debug程式,可以選擇yarn-client。
總結:
這三種分散式部署方式各有利弊,通常需要根據實際情況決定採用哪種方案。進行方案選擇時,往往要考慮公司的技術路線(採用Hadoop生態系統還是其他生態系統)、相關技術人才儲備等。上面涉及到Spark的許多部署模式,究竟哪種模式好這個很難說,需要根據你的需求,如果你只是測試Spark
Application,你可以選擇local模式。而如果你資料量不是很多,Standalone
是個不錯的選擇。當你需要統一管理叢集資源(Hadoop、Spark等),那麼你可以選擇Yarn或者mesos,但是這樣維護成本就會變高。
· 從對比上看,mesos似乎是Spark更好的選擇,也是被官方推薦的
· 但如果你同時執行hadoop和Spark,從相容性上考慮,Yarn是更好的選擇。 · 如果你不僅運行了hadoop,spark。還在資源管理上運行了docker,Mesos更加通用。
· Standalone對於小規模計算叢集更適合!
Spark執行模式簡介(本博文)
Spark執行模式列表(一定要熟悉!)

注意: Spark on Yarn 有 yarn client 和 yarn clusters 模式。
Spark on Standalone 也有 standalone client 和 standalone clusters 模式。
手把手帶你進入官網,來進一步學習Spark執行模式
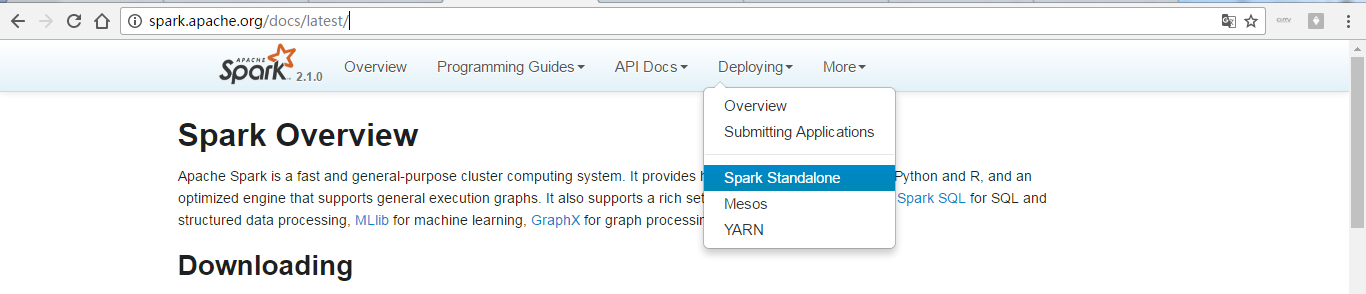

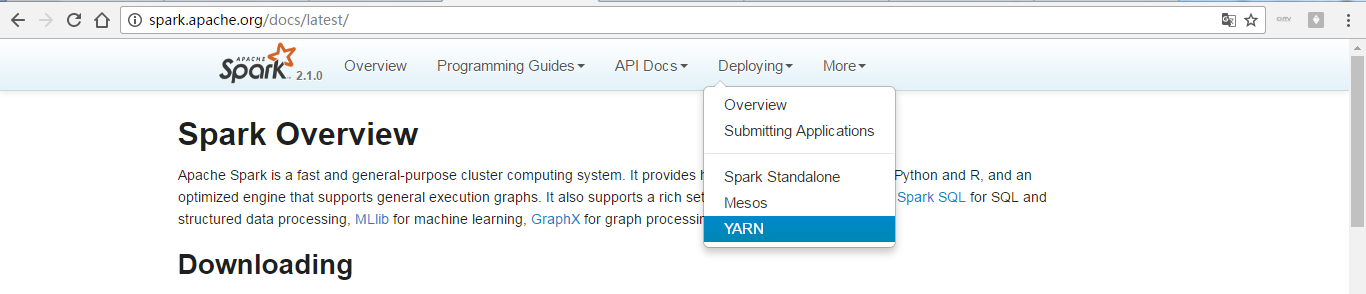
同時,大家可以關注我的個人部落格:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
詳情請見:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我願分享。本公眾號將秉持活到老學到老學習無休止的交流分享開源精神,匯聚於網際網路和個人學習工作的精華乾貨知識,一切來於網際網路,反饋回網際網路。
目前研究領域:大資料、機器學習、深度學習、人工智慧、資料探勘、資料分析。 語言涉及:Java、Scala、Python、Shell、Linux等 。同時還涉及平常所使用的手機、電腦和網際網路上的使用技巧、問題和實用軟體。 只要你一直關注和呆在群裡,每天必須有收穫
對應本平臺的討論和答疑QQ群:大資料和人工智慧躺過的坑(總群)(161156071)![]()
![]()
![]()
![]()
![]()



相關推薦
Spark執行模式概述
不多說,直接上乾貨! 目前Apache Spark支援三種分散式部署方式,分別是standalone、spark on mesos和 spark on YARN,其中,第一種類似於MapReduce 1.0所採用的模式,內部實現了容錯性和資源管理,後兩種則是未來發展的趨勢,部分容錯性
spark執行模式 standlone mesos yarn
不同的執行模式的主要區別就是他們有自己特定的資源分配和任務排程模組,這些模組用來執行實際的計算任務。 常用spark-submit提交spark application 格式如下 submit可選引數如下: standalone模式:資源排
Spark執行模式詳解
Spark執行模式 Local模式 Local[n] 本地模式 啟動n個執行緒 Local模式通常用於測試用,直接bin/spark-shell啟動即可。 Standalone模式 Standalone是Spark自帶的資源管理器,無需依賴任何其他資源管理系統 配置
Spark 執行模式
bin/spark-shell 預設情況下,表示執行在local mode,在本地啟動一個JVM Process,在裡面執行一些執行緒進行資料處理,每個執行緒執行一個Task任務。 每個JVM Process中執行多少個執行緒Thread。可以通過 bin/spark-shel
spark執行模式中的一些錯誤
錯誤一 Caused by: ERROR XJ040: Failed to start database 'metastore_db' with class loader org.apache.spark.sql.hive.client.IsolatedC
spark 執行模式的簡單總結
spark-submit --master spark://192.168.8.19:7077 --deploy-mode client /Users/haozhugogo/Downloads/hd
Spark執行模式(一)-----Spark獨立模式
除了可以在Mesos或者YARN叢集管理器上執行Spark外,Spark還提供了獨立部署模式。你可以通過手動啟動一個master和workers,或者使用提供的指令碼來手動地啟動單獨的叢集模式。你也可以在一臺單獨的機器上啟動這些程序用來測試。 以獨立模式安裝Spark叢集
Spark 系列(五)—— Spark 執行模式與作業提交
一、作業提交 1.1 spark-submit Spark 所有模式均使用 spark-submit 命令提交作業,其格式如下: ./bin/spark-submit \ --class <main-class> \ # 應用程式主入口類 --master <maste
Spark多種執行模式
https://blog.csdn.net/fbsxghvudk/article/details/80608856?utm_source=blogxgwz17 https://www.jianshu.com/p/65a3476757a5
Spark的分散式執行模式 Local,Standalone, Spark on Mesos, Spark on Yarn, Kubernetes
Spark的分散式執行模式 Local,Standalone, Spark on Mesos, Spark on Yarn, Kubernetes Local模式 Standalone模式 Spark on Mesos模式 Spark on Yarn
spark多種執行模式【基於原理講述】
1. 本地模式 該模式被稱為Local[N]模式,是用單機的多個執行緒來模擬Spark分散式計算,通常用來驗證開發出來的應用程式邏輯上有沒有問題。 其中N代表可以使用N個執行緒,每個執行緒擁有一個core。如果不指定N,則預設是1個執行緒(該執行緒有1個core)。 如果是loc
spark on mesos 兩種執行模式
spark on mesos 有粗粒度(coarse-grained)和細粒度(fine-grained)兩種執行模式,細粒度模式在spark2.0後開始棄用。 細粒度模式 優點 spark預設執行的就是細粒度模式,這種模式支援資源的搶佔,spark和
Spark Client和Cluster兩種執行模式的工作流程
1.client mode: In client mode, the driver is launched in the same process as the client that submits the application..也就是說在Client模式下,Dri
蝸龍徒行-Spark學習筆記【五】IDEA中叢集執行模式的配置
問題現象 在IDEA中執行sparkPI,報錯: Exception in thread “main” org.apache.spark.SparkException: A master URL must be set in your configurati
docker run命令概述及Docker容器的兩種執行模式
docker run命令用於根據映象檔案建立並啟動一個容器例項。 一個容器例項就是宿主機器上的一個獨立的程序。每次執行docker run,就建立一個Docker容器程序,擁有獨立的檔案系統、網路和程序樹。 1. 命令格式docker run [OPTIONS] IMAGE
Spark四種執行模式
轉載:http://blog.cheyo.net/29.html 介紹 本地模式 Spark單機執行,一般用於開發測試。 Standalone模式 構建一個由Master+Slave構成的Spark叢集,Spark執行在叢集中。 Spark on Yarn模式 Spark客戶端直
spark在yarn上面的執行模型:yarn-cluster和yarn-client兩種執行模式:
Spark在YARN中有yarn-cluster和yarn-client兩種執行模式: I. Yarn Cluster Spark Driver首先作為一個ApplicationMaster在YARN叢集中啟動,客戶端提交給ResourceManager的每一個job
spark部分:spark的四種執行模式,Spark 比 MapReduce 快的原因,spark執行程式流程,spark運算元種類,spark持久化運算元,cache 和 persist,調節引數的方式
Spark 有 4 中執行模式: 1. local 模式,適用於測試 2. standalone,並非是單節點,而是使用 spark 自帶的資源排程框架 3. yarn,最流行的方式,使用 yarn 叢集排程資源 4. mesos,國外使用的多 Spark 比 M
Spark執行在Standalone模式下產生的臨時目錄的問題
Spark 的Job任務在執行過程中產生大量的臨時目錄位置,導致某個分割槽磁碟寫滿,主要原因spark執行產生臨時目錄的預設路徑/tmp/spark* 專案中使用的版本情況 Hadoop: 2.7.1 Spark:1.6.0 JDK:1.8.0 1、專案運維需求 線上的
Spark 的幾種執行模式
浪費了“黃金五年”的Java程式設計師,還有救嗎? >>>