
【NLP】揭祕馬爾可夫模型神祕面紗系列文章(三)
作者:白寧超
2016年7月11日22:54:57
摘要:最早接觸馬爾可夫模型的定義源於吳軍先生《數學之美》一書,起初覺得深奧難懂且無什麼用場。直到學習自然語言處理時,才真正使用到隱馬爾可夫模型,並體會到此模型的妙用之處。馬爾可夫模型在處理序列分類時具體強大的功能,諸如解決:詞類標註、語音識別、句子切分、字素音位轉換、區域性句法剖析、語塊分析、命名實體識別、資訊抽取等。另外廣泛應用於自然科學、工程技術、生物科技、公用事業、通道編碼等多個領域。本文寫作思路如下:第一篇對馬爾可夫個人簡介和馬爾科夫鏈的介紹;第二篇介紹馬爾可夫鏈(顯馬爾可夫模型)和隱馬爾可夫模型以及隱馬爾可夫模型的三大問題(似然度、編碼、引數學習);第三至五篇逐一介紹三大問題相關演算法:(向前演算法、維特比演算法、向前向後演算法);最後非常得益於馮志偉先生自然語言處理教程一書,馮老研究自然語言幾十餘載,在此領域別有建樹
。
目錄
【自然語言處理:馬爾可夫模型(一)】:
馬爾可夫個人簡介
安德烈·馬爾可夫,俄羅斯人,物理-數學博士,聖彼得堡科學院院士,彼得堡數學學派的代表人物,以數論和概率論方面的工作著稱,他的主要著作有《概率演算》等。1878年,榮獲金質獎章,1905年被授予功勳教授稱號。馬爾可夫是彼得堡數學學派的代表人物。以數論和概率論方面的工作著稱。他的主要著作有《概率演算》等。在數論方面,他研究了連分數和二次不定式理論 ,解決了許多難題 。在概率論中,他發展了矩陣法,擴大了大數律和中心極限定理的應用範圍。馬爾可夫最重要的工作是在1906~1912年間,提出並研究了一種能用數學分析方法研究自然過程的一般圖式——馬爾可夫鏈
1 向前演算法原理描述
向前演算法解決:問題1(似然度問題):給一個HMM λ=(A,B) 和一個觀察序列O,確定觀察序列的似然度問題 P=(O|λ) 。
對於馬爾可夫鏈,表面觀察和實際隱藏是相同的,只需要標記吃冰淇淋數目“3 1 3”的狀態,把加權(弧上)的對應概率相乘即可。而隱馬爾可夫模型就不是那麼簡單了,因為狀態是隱藏的,我們並不知道隱藏的狀態序列是什麼?
簡化下問題:假如我們知道天氣熱冷狀況,並且知道小明吃冰淇淋的數量,我們去觀察序列似然度。如:對於給定的隱藏狀態序列“hot hot cold”我們來計算觀察序列“3 1 3”的輸出似然度。
如何進行計算?首先,隱馬爾可夫模型中,每個隱藏狀態只產生一個單獨的觀察即一一對映,隱藏狀態序列與觀察序列長度相同,即:給定這種一對一的對映以及馬爾可夫假設,對於一個特定隱藏狀態序列 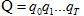 以及一個觀察序列
以及一個觀察序列 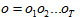 觀察序列的似然度為:
觀察序列的似然度為:

故從隱藏狀態“hot hot cold”到所吃冰淇淋觀察序列“3 1 3”的向前概率為:
P(3 1 3|hot hot cold)=P(3|hot)*P(1|hot)*P(3|cold)=0.4*0.2*0.1=0.008
實際上,隱藏狀態序列“hot hot cold”是我們的假設,並不知道隱藏狀態序列,我們要考慮所有可能的天氣序列,如此一來,我們將計算所有可能的聯合概率,計算將會變得特別複雜。
我們來計算天氣序列Q生產一個特定的冰淇淋事件序列O的聯合概率:
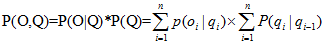
如果隱藏序列只有一個是“hot hot cold”,那麼我們的冰淇淋觀察“3 1 3”和一個可能的隱藏狀態“hot hot cold”的聯合概率為:
P(313|hothotcold)=P(hot|start)*P(hot|hot)*P(hot|cold)*P(3|hot)*P(1|hot)*P(3|cold)=0.8*0.7*0.30.4*0.2*0.1=0.001344
P(3 1 3)= P(313| cold cold cold)+ P(313| cold cold hot) + P(313| hot hot cold ) + P(313| cold hot cold) + P(313|hot cold cold) + P(313| hot hot hot) + P(313| hot cold hot) + P(313| cold hot hot)
對於具有N個隱藏狀態和T個觀察序列,將會有 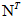 個可能隱藏序列,在實際中T往往很大,比如文字處理中可能有數萬幾十萬個詞彙,計算量將是指數上升。在隱含馬爾可夫模型中有種向前的演算法有效代替這種指數增長的複雜演算法,大大降低了複雜度。實驗證明向前演算法的複雜度是
個可能隱藏序列,在實際中T往往很大,比如文字處理中可能有數萬幾十萬個詞彙,計算量將是指數上升。在隱含馬爾可夫模型中有種向前的演算法有效代替這種指數增長的複雜演算法,大大降低了複雜度。實驗證明向前演算法的複雜度是  。
。
2 向前演算法的例項解析
向前演算法是一種動態規劃演算法,當得到觀察序列的概率時候,它使用一個表來儲存中間值。向前演算法也使用對於生成觀察序列的所有可能的隱藏狀態的路徑上的概率求和的方法計算觀察概率。在向前演算法中橫向表示觀察序列,縱向表示狀態序列。
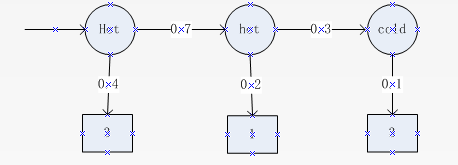
下圖是對於給定的隱藏狀態序列“hot hot cold”計算觀察序列“3 13 ”的似然度的向前網格的例子。其中:
橫向:時間上的觀察序列,縱向:空間上的狀態序列 方框:觀察狀態 圓框:隱藏狀態 續框:不合法轉移 實線上值:加權概率
每個單元 表示對於給定的自動機λ,在前面t個觀察之後,在狀態j的概率:
表示對於給定的自動機λ,在前面t個觀察之後,在狀態j的概率: 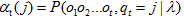 ,其中 表示第t個狀態是狀態j的概率。如:
,其中 表示第t個狀態是狀態j的概率。如: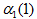 表示狀態1即數3時,q1的概率。
表示狀態1即數3時,q1的概率。
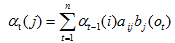
上面公式的3個因素:

向前網格如下:
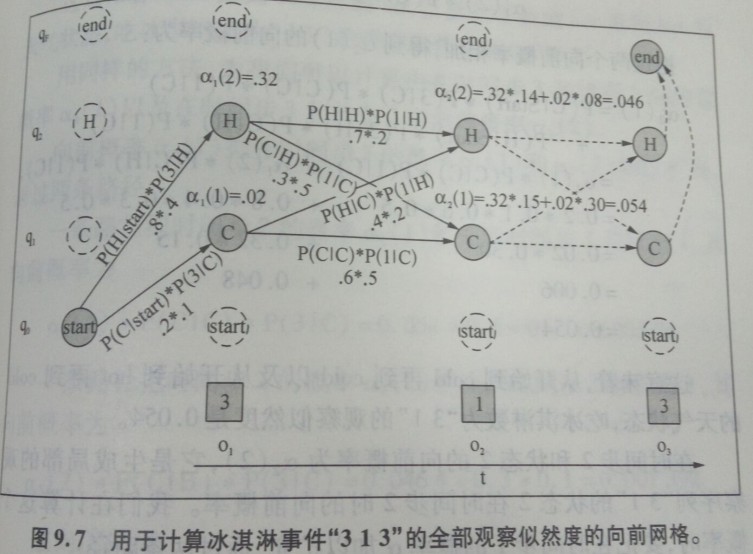
在時間1和狀態1的向前概率:
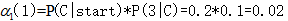
(從狀態cold開始吃3根冰淇淋的似然度0.02)
在時間1和狀態2的向前概率:
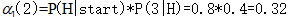
(從狀態hot始吃3根冰淇淋的似然度0.32)
在時間2和狀態1的向前概率:
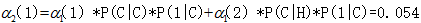
(從開始到cold再到cold以及從開始到hot再到cold的天氣狀態,吃冰淇淋3 1 的觀察似然度0.54)
在時間2和狀態2的向前概率:
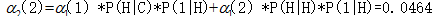
(從開始到cold再到hot以及從開始到hot再到hot的天氣狀態,吃冰淇淋3 1 的觀察似然度0.0464)
用同樣方法,我們可以計算時間步3和狀態步1的向前概率以及時間步3和狀態步2的概率等等,以此類推,直到結束。顯而易見,使用向前演算法來計算觀察似然度可以表示區域性觀察似然度。這種區域性觀察似然度比使用聯合概率表示的全域性觀察似然度更有用。
3 向前演算法定義
向前演算法的遞迴定義:

4 參考文獻
【1】統計自然語言處理基礎 Christopher.Manning等 著 宛春法等 譯
【2】自然語言處理簡明教程 馮志偉 著
【3】數學之美 吳軍 著
【4】Viterbi演算法分析文章 王亞強
宣告:關於此文各個篇章,本人採取梳理扼要,順暢通明的寫作手法。一則參照相關資料二則根據自己理解進行梳理。避免冗雜不清,每篇文章讀者可理清核心知識,再找相關文獻系統閱讀。另外,要學會舉一反三,不要死盯著定義或者某個例子不放。諸如:此文章例子冰淇淋數量(觀察值)與天氣冷熱(隱藏值)例子,讀者不免問道此有何用?我們將冰淇淋數量換成中文文字或者語音(觀察序列),將天氣冷熱換成英文文字或者語音文字(隱藏序列)。把這個問題解決了不就是解決了文字翻譯、語音識別、自然語言理解等等。解決了自然語言的識別和理解,再應用到現在機器人或者其他裝置中,不就達到實用和聯絡現實生活的目的了?
相關推薦
【NLP】揭祕馬爾可夫模型神祕面紗系列文章(三)
作者:白寧超 2016年7月11日22:54:57 摘要:最早接觸馬爾可夫模型的定義源於吳軍先生《數學之美》一書,起初覺得深奧難懂且無什麼用場。直到學習自然語言處理時,才真正使用到隱馬爾可夫模型,並體會到此模型的妙用之處。馬爾可夫模型在處理序列分類時具體強大的功能,諸如解決:詞類標註、語音識別、句
【NLP】揭祕馬爾可夫模型神祕面紗系列文章(二)
作者:白寧超 2016年7月11日15:31:11 摘要:最早接觸馬爾可夫模型的定義源於吳軍先生《數學之美》一書,起初覺得深奧難懂且無什麼用場。直到學習自然語言處理時,才真正使用到隱馬爾可夫模型,並體會到此模型的妙用之處。馬爾可夫模型在處理序列分類時具體強大的功能,諸如解決:詞類標註、語音識別、句
【NLP】揭祕馬爾可夫模型神祕面紗系列文章(一)
作者:白寧超 2016年7月10日20:34:20 摘要:最早接觸馬爾可夫模型的定義源於吳軍先生《數學之美》一書,起初覺得深奧難懂且無什麼用場。直到學習自然語言處理時,才真正使用到隱馬爾可夫模型,並體會到此模型的妙用之處。馬爾可夫模型在處理序列分類時具體強大的功能,諸如解決:詞類標註、語音識別、句
【NLP】揭祕馬爾可夫模型神祕面紗系列文章(五)
作者:白寧超 2016年7月12日14:28:10 摘要:最早接觸馬爾可夫模型的定義源於吳軍先生《數學之美》一書,起初覺得深奧難懂且無什麼用場。直到學習自然語言處理時,才真正使用到隱馬爾可夫模型,並體會到此模型的妙用之處。馬爾可夫模型在處理序列分類時具體強大的功能,諸如解決:詞類標註、語音識別、句
【NLP】揭祕馬爾可夫模型神祕面紗系列文章(四)
作者:白寧超 2016年7月12日14:08:28 摘要:最早接觸馬爾可夫模型的定義源於吳軍先生《數學之美》一書,起初覺得深奧難懂且無什麼用場。直到學習自然語言處理時,才真正使用到隱馬爾可夫模型,並體會到此模型的妙用之處。馬爾可夫模型在處理序列分類時具體強大的功能,諸如解決:詞類標註、語音識別、句
【NLP】驀然回首:談談學習模型的評估系列文章(三)
作者:白寧超 2016年7月19日19:04:51 摘要:寫本文的初衷源於基於HMM模型序列標註的一個實驗,實驗完成之後,迫切想知道採用的序列標註模型的好壞,有哪些指標可以度量。於是,就產生了對這一專題進度學習總結,這樣也便於其他人蔘考,節約大家的時間。本文依舊旨在簡明扼要梳理出模型評估核心指標,
【NLP】驀然回首:談談學習模型的評估系列文章(二)
作者:白寧超 2016年7月19日10:24:24 摘要:寫本文的初衷源於基於HMM模型序列標註的一個實驗,實驗完成之後,迫切想知道採用的序列標註模型的好壞,有哪些指標可以度量。於是,就產生了對這一專題進度學習總結,這樣也便於其他人蔘考,節約大家的時間。本文依舊旨在簡明扼要梳理出模型評估核心指標,
【NLP】驀然回首:談談學習模型的評估系列文章(一)
作者:白寧超 2016年7月18日17:18:43 摘要:寫本文的初衷源於基於HMM模型序列標註的一個實驗,實驗完成之後,迫切想知道採用的序列標註模型的好壞,有哪些指標可以度量。於是,就產生了對這一專題進度學習總結,這樣也便於其他人蔘考,節約大家的時間。本文依舊旨在簡明扼要梳理出模型評估核心指標,
【演算法】 隱馬爾可夫模型 HMM
隱馬爾可夫模型 (Hidden Markov Model,HMM) 以下來源於_作者 :skyme 地址:http://www.cnblogs.com/skyme/p/4651331.html 隱馬爾可夫模型(Hidden Markov Model,HMM)是統計模型,它用來描述一
【機器學習筆記18】隱馬爾可夫模型
【參考資料】 【1】《統計學習方法》 隱馬爾可夫模型(HMM)定義 隱馬爾可夫模型: 隱馬爾可夫模型是關於時序的模型,描述一個由隱藏的馬爾可夫鏈生成的不可觀測的狀態序列,再由各個狀態生成的觀測值所構成的一個觀測序列。 形式化定義HMM為λ=(A,B,π)\la
【中文分詞】隱馬爾可夫模型HMM
Nianwen Xue在《Chinese Word Segmentation as Character Tagging》中將中文分詞視作為序列標註問題(sequence tagging problem),由此引入監督學習演算法來解決分詞問題。 1. HMM 首先,我們將簡要地介紹HMM(主要參考了李航老師的《
NLP之隱馬爾可夫模型
馬爾可夫模型 在介紹隱馬爾可夫模型之前,先來介紹馬爾可夫模型。 我們知道,隨機過程又稱隨機函式,是隨時間而隨機變化的過程。 馬爾可夫模型(Markov model)描述了一類重要的隨機過程。我們常常需要考察一個隨機變數序列,這些隨機變數並不是相互獨立的,每個隨機變數的值依賴於這個序
【統計學習方法-李航-筆記總結】十、隱馬爾可夫模型
本文是李航老師《統計學習方法》第十章的筆記,歡迎大佬巨佬們交流。 主要參考部落格: https://www.cnblogs.com/YongSun/p/4767667.html https://www.cnblogs.com/naonaoling/p/5701634.html htt
【中文分詞】二階隱馬爾可夫模型2-HMM
在前一篇中介紹了用HMM做中文分詞,對於未登入詞(out-of-vocabulary, OOV)有良好的識別效果,但是缺點也十分明顯——對於詞典中的(in-vocabulary, IV)詞卻未能很好地識別。主要是因為,HMM本質上是一個Bigram的語法模型,未能深層次地考慮上下文(context)。對於此,
【中文分詞】最大熵馬爾可夫模型MEMM
Xue & Shen '2003 [2]用兩種序列標註模型——MEMM (Maximum Entropy Markov Model)與CRF (Conditional Random Field)——用於中文分詞;看原論文感覺作者更像用的是MaxEnt (Maximum Entropy) 模型而非MEM
NLP-隱馬爾可夫模型及使用例項
說明:學習筆記,內容來自周志華的‘機器學習’書籍和加號的‘七月線上’視訊。 隱馬爾可夫模型 隱馬爾可夫模型(Hidden Markov Model,簡稱HMM)是結構最簡單的動態貝葉斯網,這是一種著名的有向圖模型,主要用於時序資料建模,在語音識別、
隱馬爾可夫模型(三)
image 之前 下標 如何 最大路 mage 局部最優 .com 紅色 預測算法 還記得隱馬爾可夫模型的三個問題嗎?本篇介紹第三個問題:預測問題,即給定模型參數和觀測序列,求最有可能的狀態序列,有如下兩種算法。 近似算法 在每個時刻t選出當前最有可能的狀態 it,從而得到
隱馬爾可夫模型(一)
回溯 一是 描述 數學 函數 觀測 tran 隱藏 之間 隱馬爾可夫模型 隱馬爾可夫模型(Hidden Markov Model,HMM)是一種統計模型,廣泛應用在語音識別,詞性自動標註,音字轉換,概率文法等各個自然語言處理等應用領域。經過長期發展,尤其
簡單馬爾可夫模型的實現(簡單的機器學習)
自然語言 index 馬爾科夫 ref item model not 次數 read 馬爾可夫模型(Markov Model)是一種統計模型,廣泛應用在語音識別,詞性自動標註,音字轉換,概率文法等各個自然語言處理等應用領域。經過長期發展,尤其是在語音識別中的成功應用,使它成
轉:從頭開始編寫基於隱含馬爾可夫模型HMM的中文分詞器
lan reverse single trim 地址 note str rip resources http://blog.csdn.net/guixunlong/article/details/8925990 從頭開始編寫基於隱含馬爾可夫模型HMM的中文分詞器之一 - 資