
大資料開發 | MapReduce介紹
| 1. MapReduce 介紹 |
1.1MapReduce的作用
假設有一個計算檔案中單詞個數的需求,檔案比較多也比較大,在單擊執行的時候機器的記憶體受限,磁碟受限,運算能力受限,而一旦將單機版程式擴充套件到叢集來分散式執行,將極大增加程式的複雜度和開發難度,因此這個工作可能完成不了。針對以上這個案例,MapReduce在這裡能起到什麼作用呢,引入MapReduce框架後,開發人員可以將絕大部分工作集中在業務邏輯的開發上,而將分散式計算中的複雜性交由框架來處理。
可見在程式由單機版擴成分散式時,會引入大量的複雜工作。為了提高開發效率,可以將分散式程式中的公共功能封裝成框架,讓開發人員可以將精力集中於業務邏輯。而
1.2MapReduce架構圖
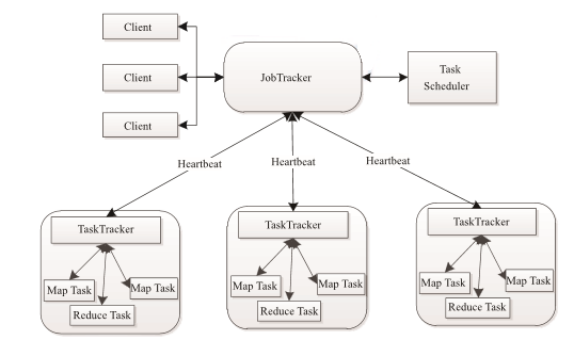
MapReduce 也採用了 Master/Slave(M/S)架構。它主要由以下幾個元件組成 :Client、JobTracker、 TaskTracker 和 Task。下面分別對這幾個元件進行介紹。
(1)Client
使用者編寫的MapReduce程式通過Client提交到JobTracker端;同時使用者可通過Client提供的一些介面檢視作業執行狀態。在Hadoop內部用“作業” (Job)表示MapReduce程式。一個 MapReduce程式可對應若干個作業,而每個作業會被分解成若干個Map/Reduce
(2)JobTracker
JobTracker 主要負責資源監控和作業排程。JobTracker 監控所有 TaskTracker 與作業Job的健康狀況,一旦發現失敗情況後,其會將相應的任務轉移到其他節點;同時,JobTracker 會跟蹤任務的執行進度、資源使用量等資訊,並將這些資訊告訴任務排程器,而排程器會在資源出現空閒時,選擇合適的任務使用這些資源。在Hadoop 中,任務排程器是一個可插拔的模組,使用者可以根據自己的需要設計相應的排程器。
(3)TaskTracker
TaskTracker會週期性地通過Heartbeat將本節點上資源的使用情況和任務的執行進度彙報給
(4)Task
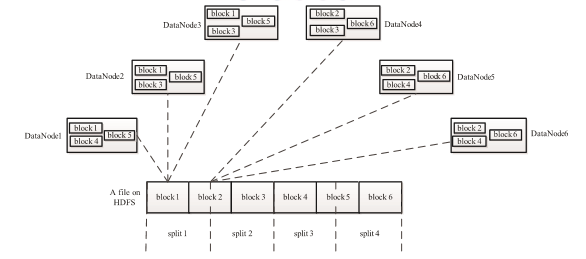
Task 分為 Map Task 和 Reduce Task 兩種,均由TaskTracker啟動。從上一小節中我們知道,HDFS以固定大小的block 為基本單位儲存資料,而對於MapReduce 而言,其處理單位是split。 split 與 block 的對應關係如下圖所示。split 是一個邏輯概念,它只包含一些元資料資訊,比如 資料起始位置、資料長度、資料所在節點等。它的劃分方法完全由使用者自己決定。但需要注意的是,split的多少決定了Map Task的數目,因為每個split會交由一個Map Task處理。
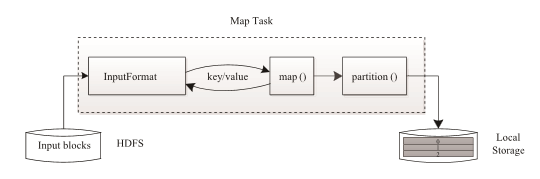
Map Task 執行過程如下圖所示。由該圖可知,Map Task 先將對應的split 迭代解析成一 個個 key/value 對,依次呼叫使用者自定義的map() 函式進行處理,最終將臨時結果存放到本地磁碟上,其中臨時資料被分成若干個partition(分片),每個partition 將被一個Reduce Task處理。
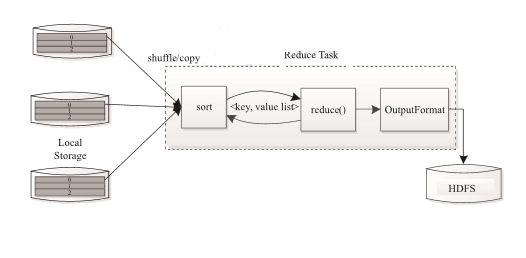
Reduce Task 執行過程如下圖所示。該過程分為三個階段:
①從遠端節點上讀取Map Task 中間結果(稱為“Shuffle階段”);
②按照key對key/value 對進行排序(稱為“Sort階段”);
③依次讀取 <key, value list>,呼叫使用者自定義的 reduce() 函式處理,並將最終結果存到HDFS上(稱為“Reduce 階段”)。
MapReduce是一種並行程式設計模式,利用這種模式軟體開發者可以輕鬆地編寫出分散式並行程式。在Hadoop的體系結構中,MapReduce是一個簡單易用的軟體框架,基於它可以將任務分發到由上千臺商用機器組成的叢集上,並以一種可靠容錯的方式並行處理大量的資料集,實現Hadoop的並行任務處理功能。MapReduce框架是由一個單獨執行在主節點的JobTrack和執行在每個叢集從節點的TaskTrack共同組成的。
主節點負責排程構成一個作業的所有任務,這些任務分佈在不同的節點上。主節點監控它們的執行情況,並且重新執行之前失敗的任務;
從節點僅負責由主節點指派的任務。
當一個Job任務被提交時,JobTrack接收到提交作業和其配置資訊之後,就會配置資訊等發給從節點,同時排程任務並監控TaskTrack的執行。
1.3MapReduce程式執行演示
Hadoop的釋出包中內建了一個hadoop-mapreduce-example-2.6.5.jar,這個jar包中有各種MR示例程式,可以通過以下步驟執行:
啟動hdfs,yarn,然後在叢集中的任意一臺伺服器上啟動執行程式(比如執行wordcount):
hadoop jar hadoop-mapreduce-example-2.6.5.jar wordcount /wordcount/data /wordcount/out
| 2.MapReduce 程式設計 |
2.1程式設計規範
1) 使用者編寫的程式分成三個部分:Mapper,Reducer,Driver(提交執行mr程式的客戶端)
2) Mapper的輸入資料是KV對的形式(KV的型別可自定義)
3) Mapper的輸出資料是KV對的形式(KV的型別可自定義)
4) Mapper中的業務邏輯寫在map()方法中
5) map()方法(maptask程序)對每一個<K,V>呼叫一次
6) Reducer的輸入資料型別對應Mapper的輸出資料型別,也是KV
7) Reducer的業務邏輯寫在reduce()方法中
8) Reducetask程序對每一組相同k的<k,v>組呼叫一次reduce()方法
9) 使用者自定義的Mapper和Reducer都要繼承各自的父類
10) 整個程式需要一個Drvier來進行提交,提交的是一個描述了各種必要資訊的job物件
2.2wordcount 示例編寫
需求:在一堆給定的文字檔案中統計輸出每一個單詞出現的總次數
(1)定義一個mapper類
//首先要定義四個泛型的型別 //keyin: LongWritable valuein: Text //keyout: Text valueout:IntWritable public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ //map方法的生命週期: 框架每傳一行資料就被呼叫一次 //key : 這一行的起始點在檔案中的偏移量 //value: 這一行的內容 @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //拿到一行資料轉換為string String line = value.toString(); //將這一行切分出各個單詞 String[] words = line.split(" "); //遍歷陣列,輸出<單詞,1> for(String word:words){ context.write(new Text(word), new IntWritable(1)); } } }
(2)定義一個reducer類
//生命週期:框架每傳遞進來一個kv 組,reduce方法被呼叫一次 @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { //定義一個計數器 int count = 0; //遍歷這一組kv的所有v,累加到count中 for(IntWritable value:values){ count += value.get(); } context.write(key, new IntWritable(count)); } }
(3)定義一個主類,用來描述job並提交job
public class WordCountRunner { //把業務邏輯相關的資訊(哪個是mapper,哪個是reducer,要處理的資料在哪裡,輸出的結果放哪裡……)描述成一個job物件 //把這個描述好的job提交給叢集去執行 public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job wcjob = Job.getInstance(conf); //指定我這個job所在的jar包 // wcjob.setJar("/home/hadoop/wordcount.jar"); wcjob.setJarByClass(WordCountRunner.class); wcjob.setMapperClass(WordCountMapper.class); wcjob.setReducerClass(WordCountReducer.class); //設定我們的業務邏輯Mapper類的輸出key和value的資料型別 wcjob.setMapOutputKeyClass(Text.class); wcjob.setMapOutputValueClass(IntWritable.class); //設定我們的業務邏輯Reducer類的輸出key和value的資料型別 wcjob.setOutputKeyClass(Text.class); wcjob.setOutputValueClass(IntWritable.class); //指定要處理的資料所在的位置 FileInputFormat.setInputPaths(wcjob, "hdfs://hdp-server01:9000/wordcount/data/big.txt"); //指定處理完成之後的結果所儲存的位置 FileOutputFormat.setOutputPath(wcjob, new Path("hdfs://hdp-server01:9000/wordcount/output/")); //向yarn叢集提交這個job boolean res = wcjob.waitForCompletion(true); System.exit(res?0:1); }
2.3叢集執行模式
1) 將mapreduce程式提交給yarn叢集resourcemanager,分發到很多的節點上併發執行
2) 處理的資料和輸出結果應該位於hdfs檔案系統
3) 提交叢集的實現步驟:
將程式打成JAR包,然後在叢集的任意一個節點上用hadoop命令啟動hadoop jar wordcount.jar cn.bigdata.mrsimple.WordCountDriver inputpath outputpath
作者:傑瑞教育出處:
臺傑瑞教育科技有限公司和部落格園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連線,否則保留追究法律責任的權利。
技術諮詢:

相關推薦
大資料開發 | MapReduce介紹
1. MapReduce 介紹 1.1MapReduce的作用 假設有一個計算檔案中單詞個數的需求,檔案比較多也比較大,在單擊執行的時候機器的記憶體受限,磁碟受限,運算能力受限,而一旦將單機版程式擴充套件到叢集來分散式執行,將極大增加程式的複雜度和開發難度,因此這個工作可能完成不了。針對以上這個
學習大資料開發需要讀的書籍有哪些?大資料開發書籍推薦介紹
學習大資料少不了平時的技術經驗的積累,只有不斷的積累才能在熟能生巧中精益求精。 今天向大家推薦一批大資料書籍,大家可以在業餘的時候閱讀,加深對大資料的瞭解,分享給大家看看~ 1.資料之巔 內容簡介: 在《資料之巔》這本書中,從小資料時代到大資料的崛起,作者以巨集大的歷史觀、文化觀、大資料
大資料開發之Hadoop篇----mapreduce概念以及架構
在我們瞭解了hdfs的一些基礎概念以後,我們現在就來進一步瞭解一下mapreduce的相關概念。 首先,mapreduce在hadoop體系裡面充當一個計算者的角色,但如我們之前所演示一樣我們在開啟hdfs和yarn時都有相關的程序,但mapreduce就是沒有的。mapreduce是直接執行在
大資料開發之Hadoop篇----配置yarn和mapreduce
上一篇部落格中我們已經完成了hdfs的部署,現在我們開始部署yarn了。 我們先使用jps命令來檢視下現在與java相關的程序: 這裡NameNode以後簡稱為NN,DataNode簡稱為DN,而SecondaryNameNodel簡稱為SNN。 我們先切換到had
大資料開發 面試 自我介紹
自我介紹 您好!我叫郭寒,來自黃山腳下安徽宣城,接下來我可能會多花幾分鐘時間講述一下我過往的經歷,以便於您能在最短的時間最迅速的瞭解我大概是一個什麼樣的人! 之所以要強調這塊是因為人與人之間的能力差距並不是很大,能力都是可以通過後天學習得到的,因此能力高低往往不是是
大資料開發進階之HBase開發例項介紹
這周學習了HBase的開發例項,主要有一些HBase API的使用。(文中的程式碼,是經過實際執行有效的,只擷取片段,關於全部的可參考前一篇文章中全域性變數的設定,關於執行環境也與前一篇一樣) 一、HBase基本操作 1.追加插入-Append 在原有的value中追加值,
【大資料】MapReduce開發小實戰
Before:前提:hadoop叢集應部署完畢。 一、實戰科目:做一個Map Reduce分散式開發,開發內容為統計檔案中的單詞出現次數。 二、戰前準備 1、本人在本地建立了一個用於執行MR的的檔案,檔案中有209行,每行寫了“這是一個測試檔案”的句子。 2、將該檔案上傳至HDFS中。
大數據開發 | MapReduce介紹
file 數據開發 編程模式 silver red 文本文 接口 runner data- 1. MapReduce 介紹 1.1MapReduce的作用 假設有一個計算文件中單詞個數的需求,文件比較多也比較大,在單擊運行的時候機器的內存受限,磁盤受限,運算能
大資料開發學習路線圖
入門知識 推薦書籍 1、舍恩伯格的《大資料時代》; 2、巴拉巴西的《爆發》; 3、塗子沛的《大資料》; 4、吳軍《智慧時代》; 5、《大資料架構商業之路:從業務需求到技術方案》 工具技能 1、hadoop: 常用於離線的複雜的大資料處理 2、Spark:常用於離線
大資料開發----Hive(入門篇)
前言 本篇介紹Hive的一些常用知識。要說和網上其他manual的區別,那就是這是筆者寫的一套成體系的文件,不是隨心所欲而作。 本文所用的環境為: CentOS 6.5 64位 Hive 2.1.1 Java 1.8 Hive Arc
大資料開發----Fabric(入門篇)
一 前言 本篇介紹Fabric的一些常用知識。要說和網上其他manual的區別,那就是這是筆者寫的一套成體系的文件,不是隨心所欲而作。 二 安裝 Fabric現在支援Python2和Python3,安裝: pip install fabric pip i
職業發展之大資料開發工程師理解
大資料工程師需要具備哪些能力? (1)數學及統計學相關的背景; (2)計算機編碼能力; (3)對特定應用領域或行業的知識。 大資料工程師這個角色很重要的一點是,不能脫離市場,因為大資料只有和特定領域的應用結合起來才能產生價值。 所以,在某個或多個垂直行業的經歷能為應聘
零基礎怎麼學spark?大資料開發學習
隨著大資料時代的到來。各種技術衍生,市場工作崗位的需求越亦增長。今天科多大資料挑選大資料裡高頻技術詞彙“spark”跟大家分享。 spark 如何入手? 概述 Apache Spark是一個快速和通用的叢集計算系統。它提供Java,scala,Python、R語言的APIs,以及支援一
全網最牛乾貨!!! 年薪80萬的大資料開發【教程】讀完此文全掌握!!!
事實上,大資料工作者可以施展拳腳的領域非常廣泛,從國防部、網際網路創業公司到金融機構,到處需要大資料專案來做創新驅動。 其實JAVA工程師轉型大資料有著天然優勢,不僅僅是前景和薪資等。技術層面來說,大資料使用的Hadoop(在分散式伺服器叢集上儲存海量資料並執行分散式分析應用的一種方法)需要JA
學習大資料必須瞭解的大資料開發課程大綱
大資料開發最核心的課程就是Hadoop框架,幾乎可以說Hadoop就是大資料開發。這個框架就類似於Java應用開發的SSH/SSM框架,都是Apache基金會或者其他Java開源社群團體的能人牛人開發的貢獻給大家使用的一種開源Java框架。 Java語言是王道就是這個道理,Java的核心
接地氣,到底什麼才是大資料開發工程師?
最近發現有些同學並不太瞭解大資料開發工程師這個職位,自己轉大資料開發也已經三年了,所以想簡單介紹一下什麼是大資料開發工程師,當前網際網路公司的資料開發到底是什麼樣子的?和一般的java或者php工程師在工作上有什麼區別? 宣告:本文僅代表個人觀點,有不同意見歡迎提出。另外本文對大資料開發工程師沒什麼參考價值~
掌握Spark機器學習庫 大資料開發技能更進一步
掌握Spark機器學習庫 大資料開發技能更進一步 第1章 初識機器學習 在本章中將帶領大家概要了解什麼是機器學習、機器學習在當前有哪些典型應用、機器學習的核心思想、常用的框架有哪些,該如何進行選型等相關問題。 1-1 導學 1-2 機器學習概述 1-
大資料開發之Hadoop篇----pid檔案剖析
這裡我們先看下在我還沒有啟hdfs那三個程序的時候,/tmp目錄下的情況: 現在我啟動一下hdfs三個程序: 這個時候有沒發現在/tmp目錄下多出了幾個檔案 這幾個檔案記錄的是什麼呢? 儲存的就是namenode這個程序的程序號,當我們關掉這幾個程序後,在/t
大資料開發之Hadoop篇----hdfs讀寫許可權操作
由於hdfs的結構和linux是差不多的,所以我們在hdfs的讀寫操作上也是會面臨許可權和路徑問題問題,先讓我們來看下這些都是些什麼問題。 這裡我先上傳了一個README.txt的檔案上去,通過hdfs dfs -ls /user/hadoop命令我們已經可以檢視到hdfs上有了這個檔案了
大資料開發之Hadoop篇----hdfs垃圾回收機制配置
其實要啟動hdfs上的垃圾回收機制只需要配置兩個引數就可以了,也是在core-site.xml上配置就好了,我們先去官網看下這個兩引數的解釋。 官網的解釋是:Number of minutes after which the checkpoint gets deleted. If zero