
python3__機器學習__神經網路基礎演算法__反向傳播演算法
1.反饋神經網路原理及公式推導
梯度下降演算法在衡量模型的優劣的過程中,需要計算梯度,即求不同權重的偏導數。因此,當隱層神經元個數增加(權重個數增加)或隱層個數增加(求導過程拉長)會大大拉長計算過程,即很多偏導數的求導過程會反覆涉及到,因此在實際中對於權值達到上十萬和上百萬的神經網路來說,此種重複冗餘的計算會浪費大量的計算資源。
同樣是為了求得對權重的更新,反饋神經網路演算法將誤差E作為以權重向量中每個元素為變數的高緯函式,通過不斷的更新權重,尋找訓練誤差的最低點,按誤差函式梯度下降的方向更新權值。
2.反饋神經網路原理與公式推導
2.1 原理
誤差反向更新
step 1.計算輸出層與真實層之間差值
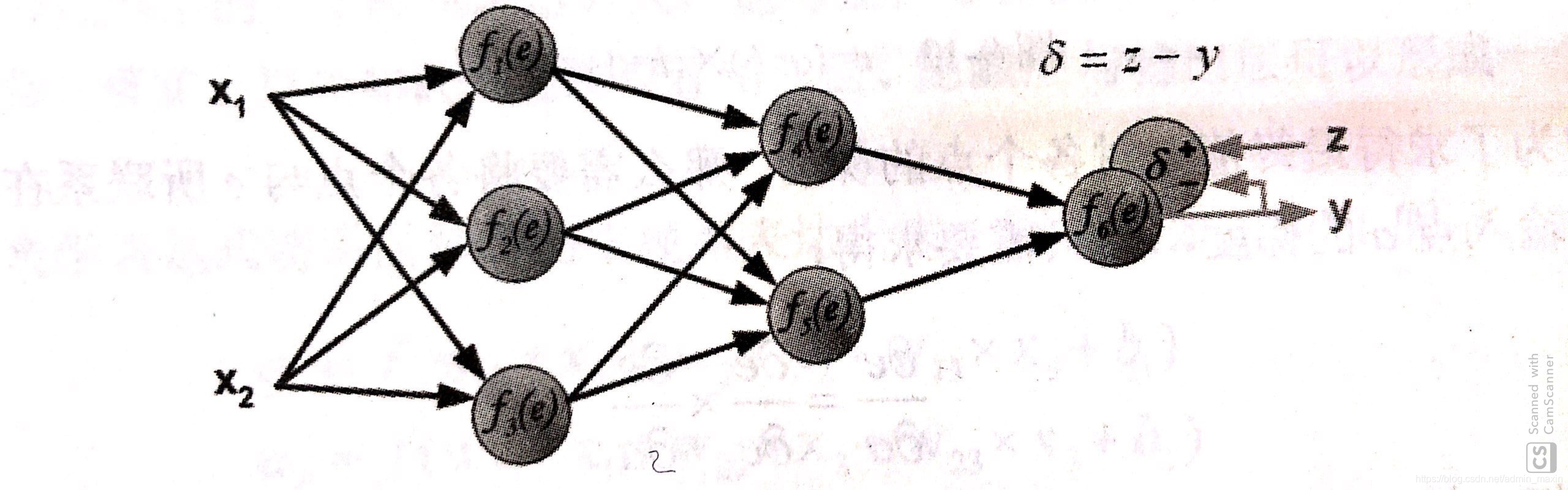
step 2.反向傳播到上一個節點,計算出節點誤差值
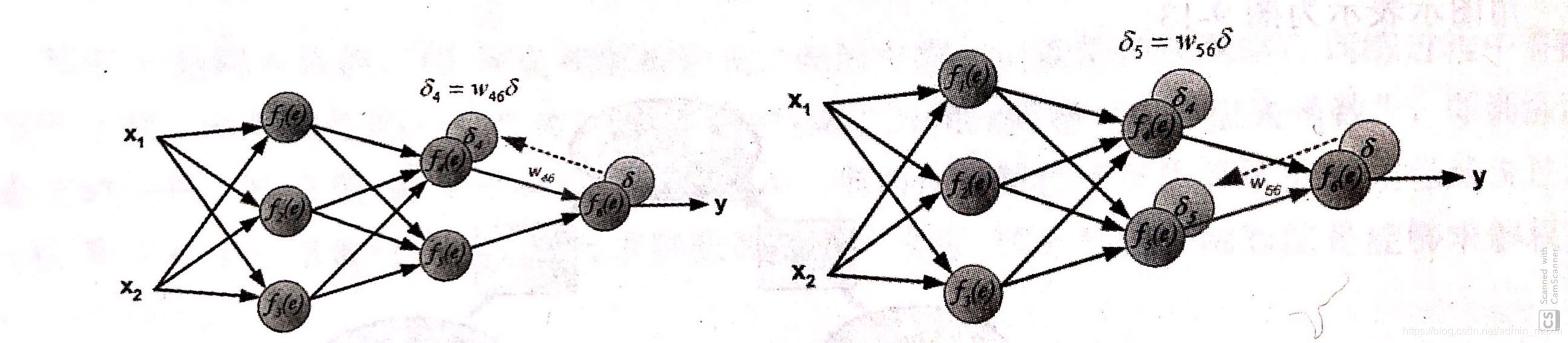
step3. 以step2中計算出的誤差為起點,依次向後傳播誤差。(隱藏層誤差由多個節點共同確定:加權和)
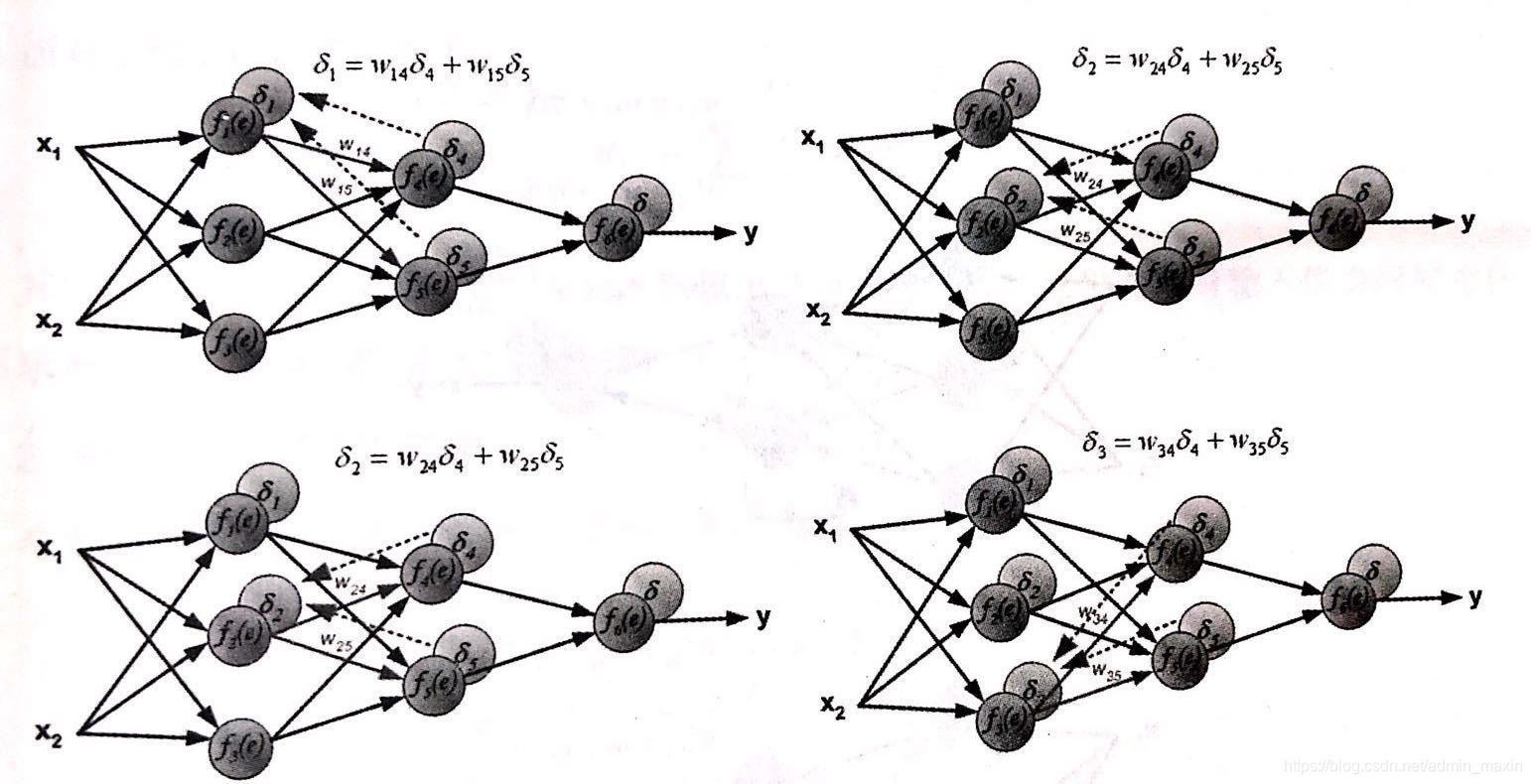
權值正向更新
step4. 通俗解釋,誤差的產生是由於輸入值和權重的計算產生的,同時,輸入值往往固定,因此,對於誤差的調節只能通過權重的更新。權重的誤差是以預測值與真實值之間的誤差為基礎的,當step1中所計算出的誤差被一層層反向傳播回來後,每個節點則僅需要更新其所需承擔的誤差量。


為權重更新之前的權重值,
學習速率,當前層當前神經元所對應的誤差,
當前層中當前神經元的輸入(也是前一層的輸出)。
2.2 公式推導
【注意事項】
①對於輸出層單元,誤差項是真實值與模型計算值之間的差值
②對於隱藏層單元,因為缺少直接的目標值來計算隱藏單元的誤差因此需要以間接的方式來計算隱藏層的誤差項對受隱藏層影響的每一個單元的誤差進行加權求和。
③權值的更新方向,主要依靠學習速率、該權值對應的輸入,以及單元的誤差項。
2.2.1 定義一:前項傳播演算法
隱藏層的輸出值:
輸出層的輸出值:

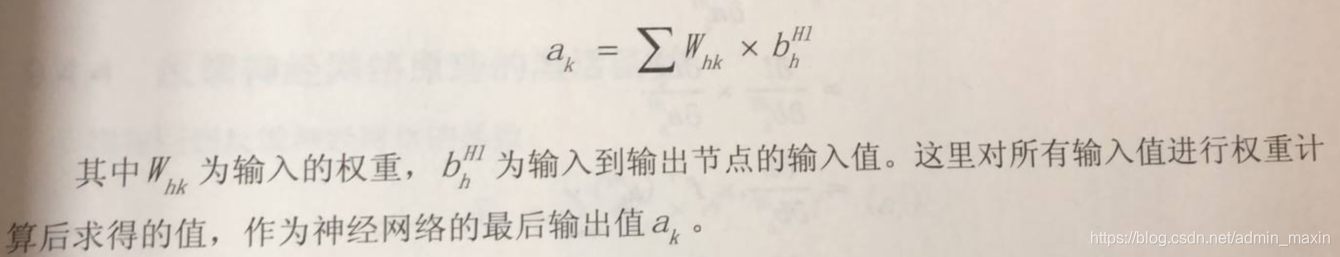
2.2.2 定義二:反向傳播演算法
L:啟用函式
輸出層的誤差項:
輸出層的誤差:
【提示】
對於“輸出層的誤差項”和“輸出層的誤差”來說,無論定義在哪個位置,都可以看做當前的輸出值對於輸入值的梯度計算。(當前層的輸出值對輸入值的偏導數)
反饋神經網路計算公式:
為當前層的下一層的權值和誤差的乘積的和,
為當前層的輸出值對輸入值的梯度,即將當前層的輸出值帶入梯度函式的導函式中。
或者換一種表述形式將上圖中的最終公式轉換為:

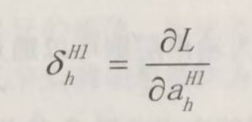


2.2.3 定義三:權重的更新
反饋神經網路計算的目的是對權重的更新,因此與梯度下降演算法類似,其更新可以仿照梯度下降對權值的更新公式:
其中,ji表示為反向傳播是對應的節點係數,通過計算當前層輸出對於輸入的梯度
,就可以更新對應的權重。b的更新類似。
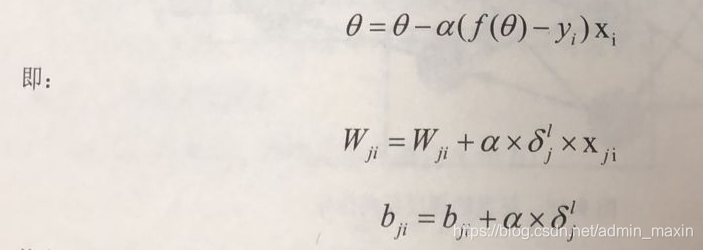
2.2.4 啟用函式
對於生物神經元來說,傳遞進來的電訊號通過神經元進行傳遞,由於每個神經元的突出強弱是有一定的敏感度的,也就是隻會對超過一定範圍的訊號進行反饋。即這個電訊號必須大於某個闕值,神經元才會被啟用引起後續的傳遞。以前應用範圍較廣的為Sigmod函式。因為,其在執行過程中只接受一個值輸出,也為一個值的訊號,且其輸出值為0到1之間。
影象為:
導數:
說明:
Sigmod函式講一個實數值壓縮到0~1之間,特別是對於較大的值的負數被對映成為0,而較大的正數被對映成為1,所以,其經常容易出現區域飽和,即:當一開始數值非常大或非常小時,該區域的梯度(偏導數值:斜率)均接近於0,這樣在後續的傳播時會造成梯度消散的現象,因此,並不適合現代的神經網路模型的使用。
近年來大量的啟用函式模型,均為解決傳統的sigmod模型在更新程度上的神經網路所產生的各種不良影響。Maxout、Tanh和ReLU
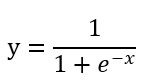

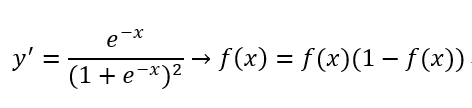
3.反饋神經網路python實現(BP)
import numpy as np
import math
# ==1.定義輔助函式
def make_matrix(m, n):
"""
生成(m, n)列的矩陣
:param m: 行
:param n: 列
:return: 返回m行n列陣列
"""
return np.zeros((m, n))
def sigmoid(x):
"""
啟用函式
:param x: 轉換數值
:return: 返回0~1之間的小數
"""
return 1.0 / (1.0 + math.exp(-x))
def sigmoid_derivate(x):
"""
啟用函式的導數
:param x: 轉換數值
:return: 導數值
"""
return x*(1 - x)
class BPNeuralNetwork:
"""
BP神經網路類
"""
def __init__(self):
"""
資料內容初始化
"""
# 輸入層數
self.input_n = 0
# 隱藏層數
self.hidden_n = 0
# 輸出層數
self.output_n = 0
# 輸入層輸入資料
self.input_cells = []
# 隱藏層輸出資料
self.hidden_cells = []
# 輸出層輸出資料
self.output_cells = []
# 輸入層權重資料
self.input_weights = []
# 輸出層權重資料
self.output_weights = []
def setup(self, ni, nh, no):
"""
對init中定義的資料進行初始化
:param ni: 輸入層節點個數 2
:param nh: 隱藏層節點個數 5
:param no: 輸出層節點個數 1
:return: None
"""
# 第一列為偏執項(調整分類決策面)
self.input_n = ni + 1
self.hidden_n = nh
self.output_n = no
# 初始化節點數值
self.input_cells = [1.0] * self.input_n
self.hidden_cells = [1.0] * self.hidden_n
self.output_cells = [1.0] * self.output_n
# 定義輸出層和隱藏層權重矩陣
# x:(3000, 2)
# iw:(2(特徵數), 4(隱層神經元個數))
# o:(3000, 4)
# ow:(4, 1)
# re:(3000, 1)
self.input_weights = make_matrix(self.input_n, self.hidden_n)
self.output_weights = make_matrix(self.hidden_n, self.output_n)
# 隨機填充權重矩陣元素值
for i in range(self.input_n):
for h in range(self.hidden_n):
self.input_weights[i][h] = np.random.uniform(-0.2, 0.2)
for h in range(self.hidden_n):
for o in range(self.output_n):
self.output_weights[h][o] = np.random.uniform(-0.2, 0.2)
def predict(self, inputs):
"""
反饋神經網路前向計算
:param inputs: 輸入層資料(一行:一個物件)
:return: 輸出層資料
"""
# 將物件資料傳入input_cells
for i in range(self.input_n - 1):
self.input_cells[i] = inputs[i]
# 計算隱藏層輸出
for j in range(self.hidden_n):
total = 0.0
for i in range(self.input_n):
total += self.input_cells[i] * self.input_weights[i][j]
self.hidden_cells[j] = sigmoid(total)
# 計算輸出層輸出
# self.hidden_cells.shape = (1, 4)
for k in range(self.output_n):
total = 0.0
for j in range(self.hidden_n):
total += self.hidden_cells[j] * self.output_weights[j][k]
self.output_cells[k] = sigmoid(total)
return self.output_cells[:]
def back_propagate(self, case, label, learn):
"""
誤差反向傳播,並更新權重和偏執項
:param case: 輸入層資料(一個物件)
:param label: 當前物件對應的分類標籤
:param learn: 學習速率
:return: 當前物件的預測誤差
"""
# 先正向傳播
self.predict(case)
# 計算輸出層誤差
# error:誤差項
# output_deltas:誤差
output_deltas = [0.0] * self.output_n
for k in range(self.output_n):
error = label[k] - self.output_cells[k]
output_deltas[k] = sigmoid_derivate(self.output_cells[k]) * error
# 計算隱藏層誤差
hidden_deltas = [0.0] * self.hidden_n
for j in range(self.hidden_n):
error = 0.0
for k in range(self.output_n):
error += output_deltas[k] * self.output_weights[j][k]
hidden_deltas[j] = sigmoid_derivate(self.hidden_cells[j]) * error
# 更新隱藏層權重
for i in range(self.input_n):
for j in range(self.hidden_n):
self.input_weights[i][j] += learn * hidden_deltas[j] * self.input_cells[i]
# 更新輸出層權重
for j in range(self.hidden_n):
for k in range(self.output_n):
self.output_weights[j][k] += learn * output_deltas[k] * self.hidden_cells[j]
error = 0
for o in range(len(label)):
error += 0.5 * (label[o] - self.output_cells[o])**2
return error
def train(self, cases, labels, maxiter=100, learn=0.05):
"""
模型訓練函式
:param cases: 資料集
:param labels: 標籤集
:param limit: 最大迭代次數
:param learn: 學習速率
:return: None
"""
# 迭代maxiter次
total_error = []
for i in range(maxiter):
# 遍歷每一個物件
error = 0
for i in range(len(cases)):
label = labels[i]
case = cases[i]
error += self.back_propagate(case, label, learn)
total_error.append(error)
return total_error
def test(self):
"""
模型預測函式
:return: None
"""
cases = [[0, 0], [0, 1], [1, 0], [1, 1]]
labels = [[0], [1], [1], [0]]
self.setup(2, 5, 1)
error = self.train(cases, labels, 100000, 0.05)
print("model train error:", error)
for case in cases:
print(self.predict(case))
if "__main__" == __name__:
nn = BPNeuralNetwork()
nn.test()