
一箇中心+三大原則 -- 阿里這樣做智慧對話開發平臺
在阿里巴巴智慧服務事業部的X蜂會上,小蜜北京團隊的高階演算法專家李永彬(水德)分享了小蜜智慧對話開發平臺的構建,圍繞平臺來源、設計理念、核心技術、業務落地情況四大維度講述了一個較為完整的智慧任務型對話開發平臺的全景。以下為演講具體內容。
平臺由來
為什麼要做一個平臺?我覺得還是從一個具體的任務型對話的例子說起,在我們日常工作中,一個很高頻的場景就是要約一個會議,看一下我們內部的辦公助理是怎麼來實現約會議的:我說“幫我約一個會議”,然後它問“你是哪一天開會?”,跟它說是“後天下午三點”,接下來它又會問“你跟誰一起開會啊?”,我會把我想約的人告訴它,這個時候它在後臺發起一次服務呼叫,因為它要去後臺拿到所有參會者的日程安排,看一下在我說的這個時間有沒有共同的空閒時間,如果沒有的話它會給我推薦幾個時間段,我看了一下我說的那個時間段大家沒有共同的空閒時間,所以我就會改一個時間。我說“上午十一點吧”,然後它會接著問,“你會持續多長時間”,我會告訴它“一個小時”,然後它接著問“會議的主題是什麼”,然後我跟它說“我們討論一下下週的上線計劃”,到此為止它把所有的資訊收集全了,然後它會給我一個 summary,讓我確認是不是要傳送會議邀約,我回復確認以後,它在後臺就會呼叫我們的郵件系統,把整個會議邀約發出來。
這是一個非常典型的任務型的對話,它滿足兩個條件,第一,它有一個明確的目標;第二,它通過多輪對話互動來達成這個目標。像這樣的任務型對話在整個辦公行業裡面,除了約會議以外還有查考勤、請假、定會議室或者日程安排等等。
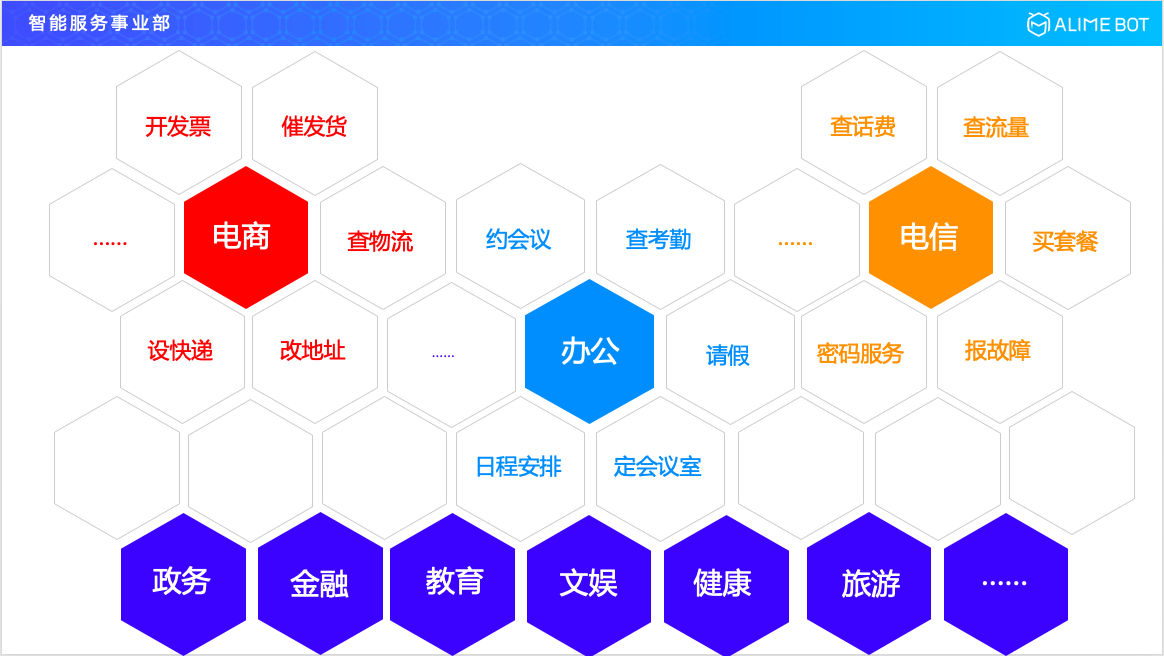
如果我們把視野再放大一點的話,再看一下電商行業,電商行業裡面就會涉及到開發票、催發貨、查物流、改地址、收快遞等等,也會涉及到很多很多的這樣的任務型對話場景;視野再放大一下,我們再看一下電信行業或者整個運營商的行業裡面,會有查話費、查流量、買套餐、報故障或者是進行密碼的更改服務等,也會有大量的這種任務型的對話場景。如果我們再一步去看的話,像政務、金融、教育、文娛、健康、旅遊等,在各行各業的各種場景裡面我們都會發現這種任務型的對話,它是一種剛需,是一種普遍性的存在。
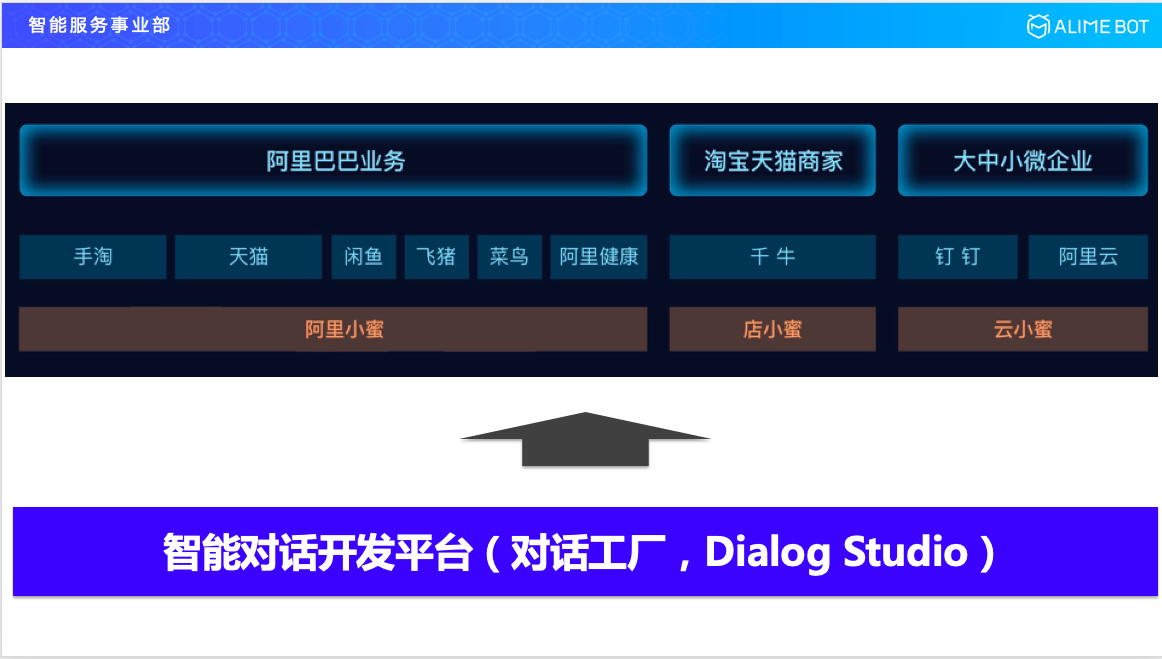
所有的這些場景落地到我們小蜜家族的時候,是通過剛剛介紹過的三大小蜜來承載:阿里小蜜、店小蜜和雲小蜜。我們不可能給每一個行業裡面的每一個場景去定製一個對話流程,所以我們就沿用了阿里巴巴一貫做平臺的思路,這也是我們整個智慧對話開發平臺的由來。這款產品在內部的名字叫對話工廠(Dialog Studio)。
以上主要是給大家介紹我們為什麼要做智慧對話開發平臺,總結起來就是我們目前面臨的業務,面臨的場景太寬泛了,不可能鋪那麼多人去把所有的場景都定製化,所以我們需要有一個平臺來讓開發者進來開發各行各業的各種場景對話。
設計理念
再看第二部分,對話工廠的一些核心設計理念。整個設計理念這塊我覺得概括起來就是“一箇中心,三個原則”。一箇中心就是以對話為中心,這句話大家可能覺得有點莫名其妙,你做對話的,為何還要強調以對話為中心呢?這是有來源的,因為在過去幾年全世界範圍的技術實踐以及直到今天很多巨頭的對話平臺裡面,我們能看到的基本還是以意圖為中心的設計模式,它把意圖平鋪在這裡,比如你想完成音樂領域的一些事情,可是你看到的其實是一堆平鋪的意圖列表,完全看不出對話在哪裡。
我們在這次對話工廠的設計中徹底把它扭轉回來,對話就是要以對話為中心,你在我們的產品介面裡面看到的不再是一個個孤立的意圖,而是關聯在一起的、有業務邏輯關係的對話流程。以意圖為中心的設計中,你看到的其實是一個區域性視角,就只能實現一些簡單的任務,比如控制一個燈,講個笑話,或者查個天氣,如果你想實現一個複雜的任務,比如開一個發票,或者去 10086 裡開通一個套餐,它其實是較難實現,很難維護的。我們把整個理念轉換一下,回到以對話為中心以後,就會看到全域性視野,可以去做複雜的任務,可以去做無限的場景。

整個對話工廠剛剛也說過了,它是一個平臺,要做一個平臺就會遇到很多挑戰:第一個挑戰就是對使用者來說,希望使用門檻越低越好;第二個挑戰是要面對各行各業的各種場景,就要求能做到靈活定製;第三個挑戰是上線以後所有的使用者肯定都希望你的機器人,你的對話系統能夠越用越好,而不是停留在某一個水平就不動了。這就是我們平臺所面臨的三大挑戰。

為了應對這三個挑戰,我們提出了在整個平臺的設計以及實現過程中始終要遵循三個原則。
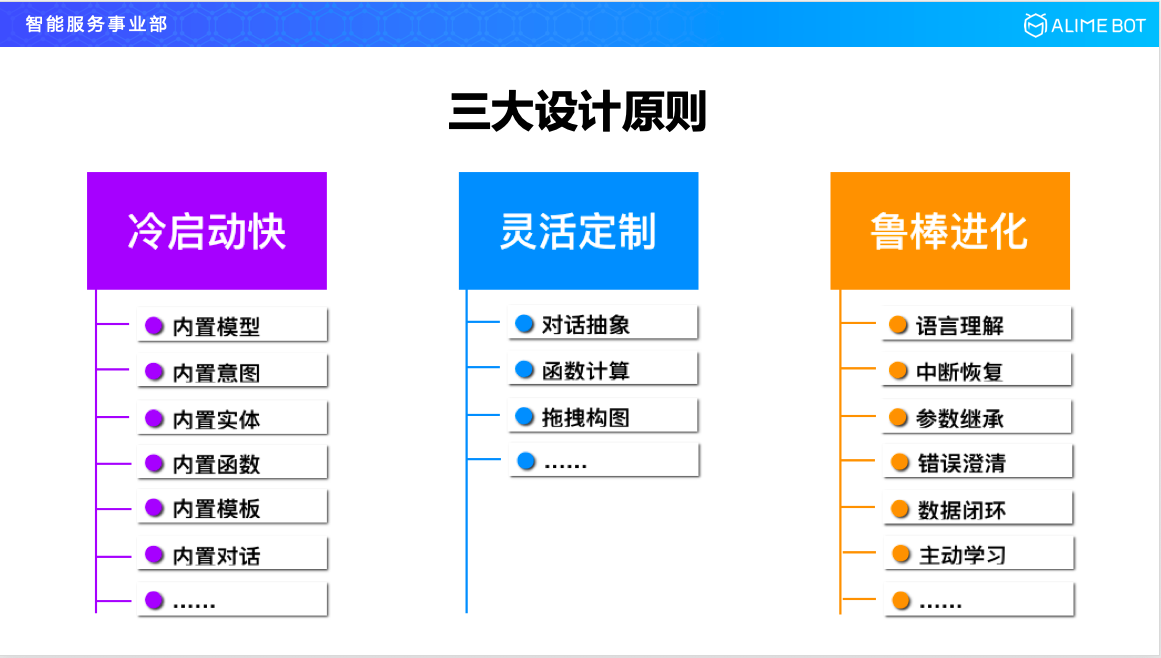
第一個原則是冷啟動要快,其實就是要讓使用者的使用門檻低一點;第二個原則是要有靈活定製的能力,只有這樣才能滿足各行各業的各種場景需求;第三個是要有魯棒進化的能力,就是模型上線以後,隨著時間的變化,隨著各種資料的不斷迴流,模型效果要不斷提升。
- 冷啟動,就是要把使用者用到的各種能力和各種資料都儘量變成一種預置的能力,簡單來說就是平臺方做得越多,使用者就做得越少;
- 靈活定製,就要求我們把整個對話平臺的基礎元素進行高度抽象,你抽象的越好就意味著你平臺的適應能力越好,就像是經典力學只要三條定律就夠了;
- 魯棒進化,這一塊就是要在模型和演算法上做深度了,語言理解的模型,對話管理的模型,資料閉環,主動學習,在這些方面能夠做出深度來。
以上說的都是一些理念和原則,接下來給大家介紹一下具體在實現過程中是怎麼來做的。
核心技術
講到技術這塊的話,因為我們做的是一個平臺,涉及到的技術非常廣,是全棧的技術,從演算法到工程到前端到互動所有的技術都會涉及到。我摘取裡面演算法的核心部分來給大家做一個介紹。
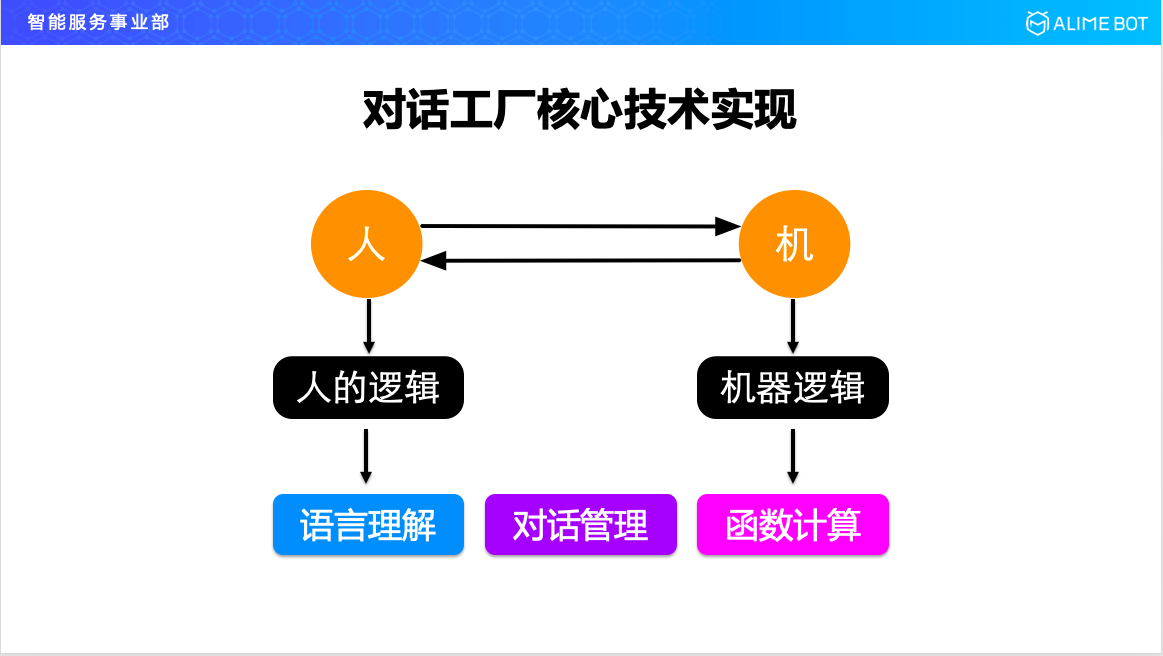
對話工廠首先是用來做對話的,人機對話有兩個主體,一個是人,一個是機器,人有人的邏輯,人的邏輯使用什麼來表達呢?到今天為止主要還是通過語言,所以我們需要有一個語言理解的服務來承載這一塊;機器有機器的邏輯,機器的邏輯到今天為止還是通過程式碼來表達的,所以我們需要一個函式計算的服務;在人和機器對話的過程中,這種對話過程需要有效的管理,所以我們需要一個對話管理模組。整個對話工廠最核心的三個模組就是語言理解、對話管理和函式計算。
第一個模組是語言理解。
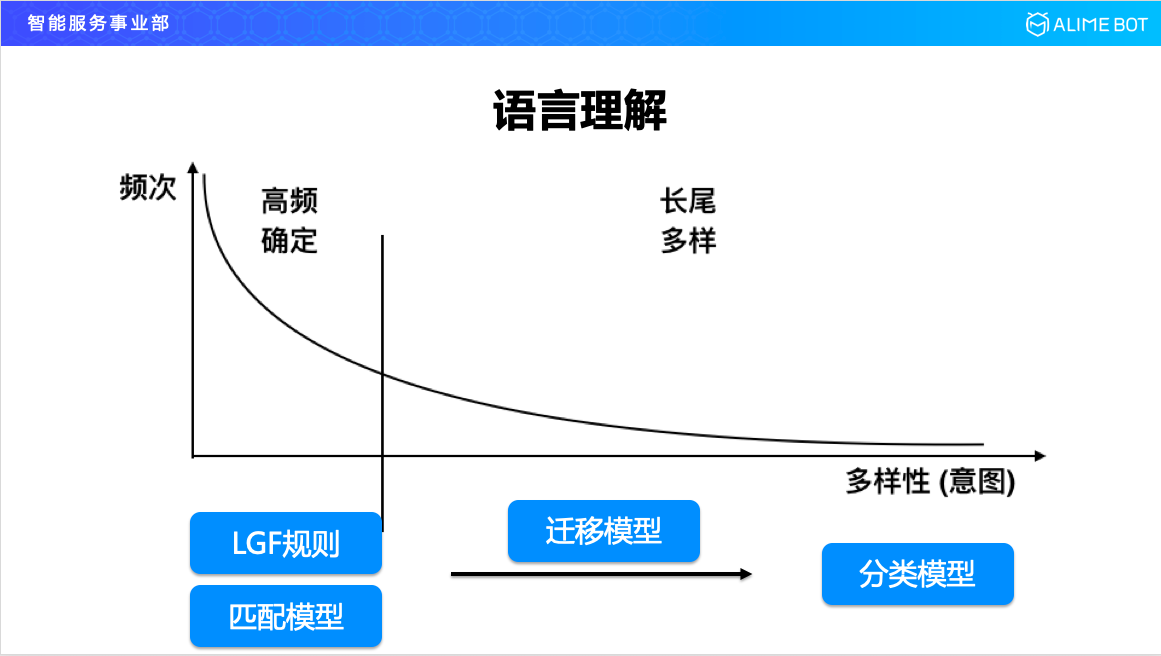
我們先看一下這個圖,在整個這個圖裡面,橫軸是意圖的多樣性,縱軸是頻次,這樣說有點抽象,我舉一個具體的例子,比如說我要開發票,這是一個意圖,如果去取樣十萬條這個意圖的使用者說法作為樣本,把這些說法做一個頻率統計,可能排在第一位的就是三個字“開發票”,它可能出現了兩萬次,另外排在第二位可能是“開張發票”,它可能出現了八千次,這些都是一些高頻的說法,還有一些說法說的很長,比如“昨天我在你們商鋪買了一條紅色的裙子,你幫我開個發票唄”,這種帶著前因後果的句式,在整個說法裡面是比較長尾的,可能只出現了一次或兩次。
我們統計完以後,整個意圖的說法的多樣性分佈符合冪律分佈。這種特徵可以讓我們在技術上進行有效的針對性設計,首先針對這種高頻的部分,我們可以上一些規則,比如上下文無關文法,可以比較好的 cover 這一塊,但是基於規則的方法,大家也知道,規則是沒有泛化能力的,所以這時候要上一個匹配模型,計算一個相似度來輔助規則,這兩塊結合在一起就可以把我們高頻確定性的部分解決的比較好;對於長尾的多樣性的這一部分,基本到今天為止還是上有監督的分類模型,去收集或者去標註很多資料,把這一塊做好;在規則和分類模型之間,我們又做了一部分工作,就是遷移學習模型,為什麼要引入這個模型呢?我們看下一張圖。
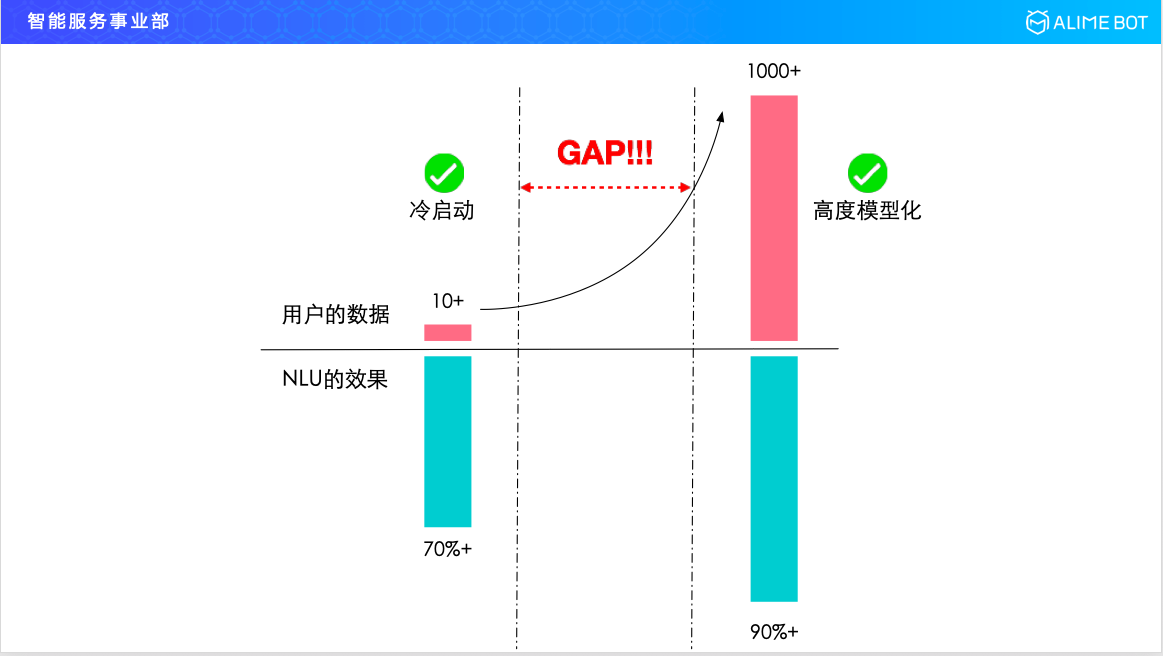
在冷啟動階段,使用者在錄入樣本的時候,不會錄入太多,可能錄入十幾條几十條就已經很多了,這個時候按照剛才那個冪律分佈,二八原則的話,它的效果的話可能也就是 70% 多,它不可能再高了。但對於使用者的期望來說,如果想要上線,想要很好的滿足他的使用者需求,其實是想要模型效果在 90% 以上,如果想要達到這個效果,就需要複雜的模型,需要標註大量資料。所以其實是存在一個 gap 的,我們引入了遷移學習模型。
具體來說,我們把膠囊網路引進來和 few-shot learning 結合在一起,提出了一個網路結構叫 Induction Network,就是歸納網路。整個網路結構有三層,一層是 Encoder層,第二層是 Induction,歸納層,第三層是 Relation 層。
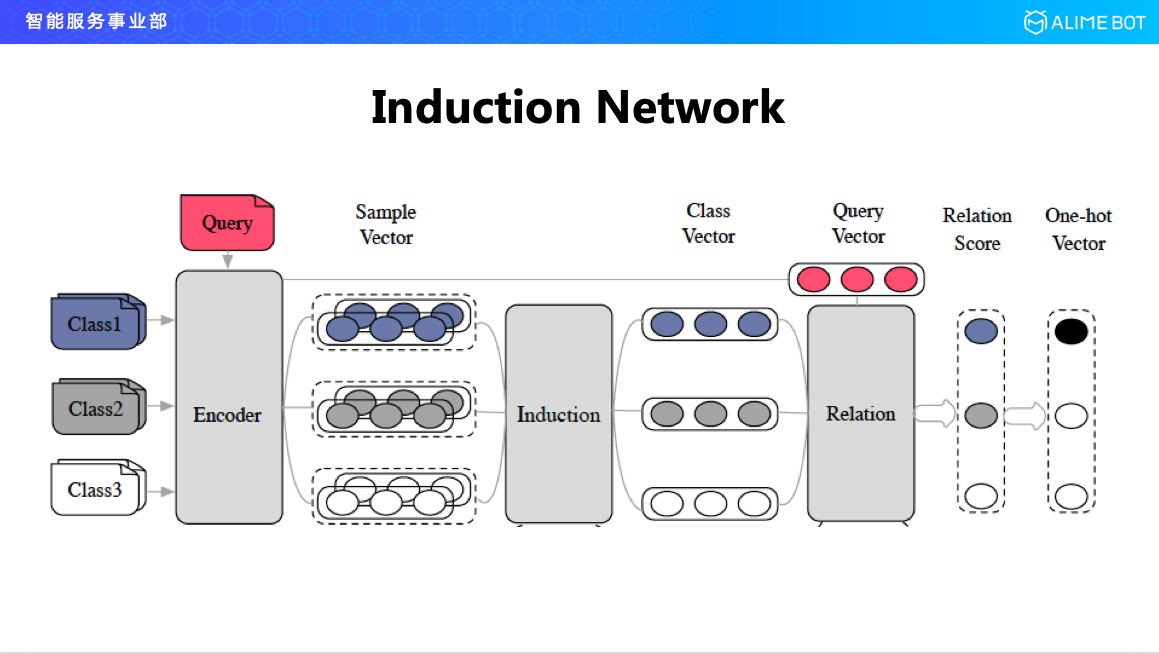
第一層負責將每一個類的每一個樣本進行編碼,編碼成一個向量;第二層是最核心的一層,也就是歸納層,這裡面利用膠囊網路的一些方法,把同一個類的多個向量歸納成一個向量;然後第三層 Relation 層把使用者新來的一句話和每一個類的歸納向量進行關係計算,輸出他們的相似性打分。如果我們想要一個分類結果就輸出一個 One-hot,如果不想要 One-hot,就輸出一個關係的 Relation score,這是整個 Induction network 的網路結構。
這個網路結構提出來以後,在學術圈裡面關於 few-shot learning 的資料集上,我們以比較大的提升幅度做到了 state-of-the-art 的效果,目前是最好的,同時我們將整個網路結構上線到了我們的產品裡面,這是語言理解。
第二塊我們看對話管理。
對話管理其實我剛剛也說過了,如果想要讓平臺有足夠的適應性的話,那麼它的抽象能力一定要好。
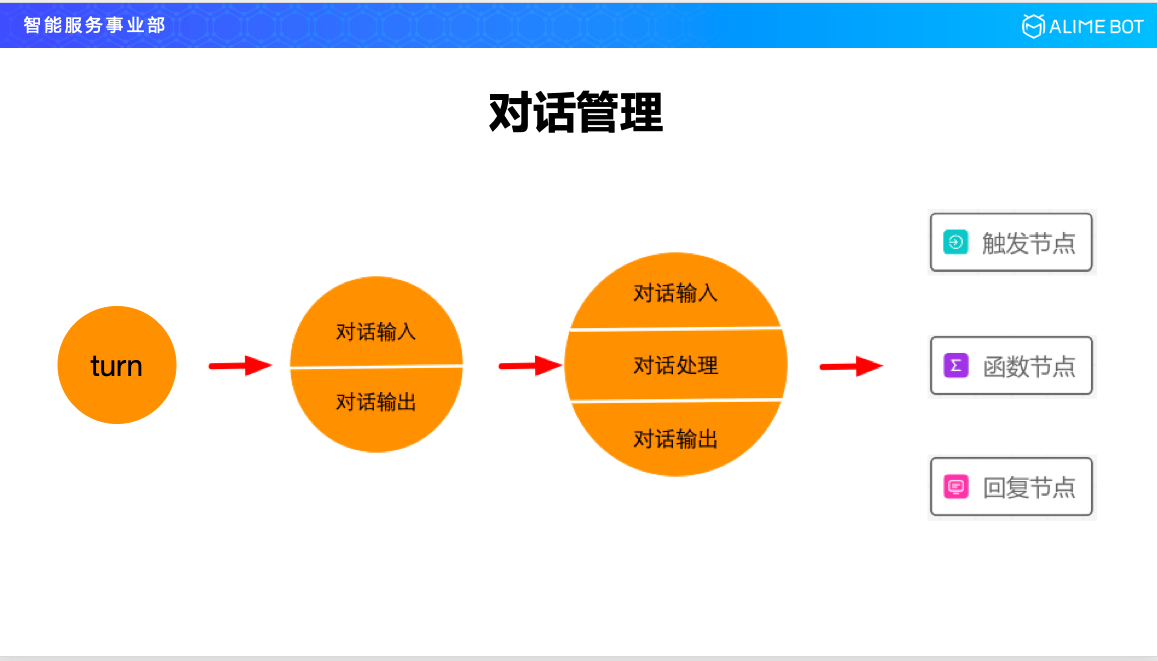
對話管理是做什麼的?對話管理就是管理對話的,那麼對話是什麼呢?對話的最小單位就是一輪,一個 turn,我們進去看的話,一個 turn 又分為兩部分,一個叫對話輸入,一個叫對話輸出;在輸入和輸出中間,有一個對話處理的過程,就像兩個人互相交流一樣,我問你答,但其實你在答之前是有一個思考過程的,如果你不思考就回答,那你的答案就是沒有質量的,所以就會有一箇中間的對話處理過程。我們把對話抽象到這種程度以後,整個平臺就三個節點,一個叫觸發節點,一個叫函式節點,一個叫回復節點。
觸發節點是和使用者的對話輸入對著的,函式節點是和對話處理對著的,回覆節點是和對話輸出對著的。有了這一層抽象以後,無論你是什麼行業的什麼場景,什麼樣的對話流程,都可以通過這三個節點通過連線把你的業務流畫出來。

舉兩個例子,先看一個簡單的,你要查一個天氣,很簡單,先來一個觸發節點,把天氣流程觸發起來,中間有兩個函式節點,一個是調中央氣象臺的介面,把結果拿過來,另一個是對結果進行一次解析和封裝,以一個使用者可讀的形式通過回覆節點回復給使用者。這裡面稍微解釋一下就是增加了一個填槽節點,填槽節點是什麼意思呢?就是在任務型對話裡面,幾乎所有的任務都需要收集使用者的資訊,比如你要查天氣,就需要問時間是哪一天的,地點是什麼地方的,這樣就叫做填槽,填槽因為太常用太普遍了,就符合我們冷啟動快裡面做預置的思想,所以通過三個基礎節點,我們自己把它搭建成填槽的一個模板,需要填槽的時候從頁面上拖一個填槽節點出來就可以了。
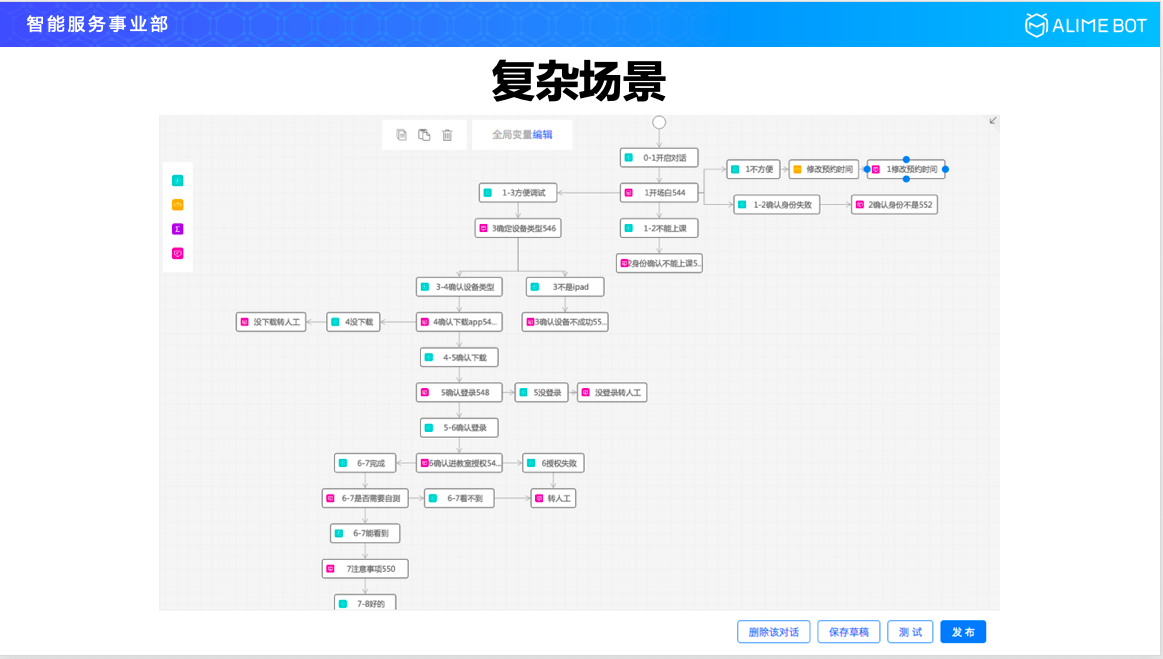
我們再看一個複雜的場景,這是線上教育裡面的一個外呼場景,家裡有小孩的可能知道,這種線上教育特別火,在上課之前半小時,機器人就會主動給使用者打電話,指導軟體下載,指導怎麼登陸,登陸進去以後怎麼進入教室,所有的這些流程都可以通過機器人進行引導。
通過這兩個例子我們就可以看到,無論是簡單還是複雜的場景,通過這三種抽象節點的連線都可以實現。有時候我們開玩笑就會說,整個這種連線就叫一生二,二生三,三生萬千對話。
講了抽象以後,再看一下具體的對話管理技術。從實現上來說,這張圖和大家剛才看到的語言理解那張是一模一樣的,因為很多東西的分佈其實是遵循著共同規律的,區別在與把意圖換成了對話。
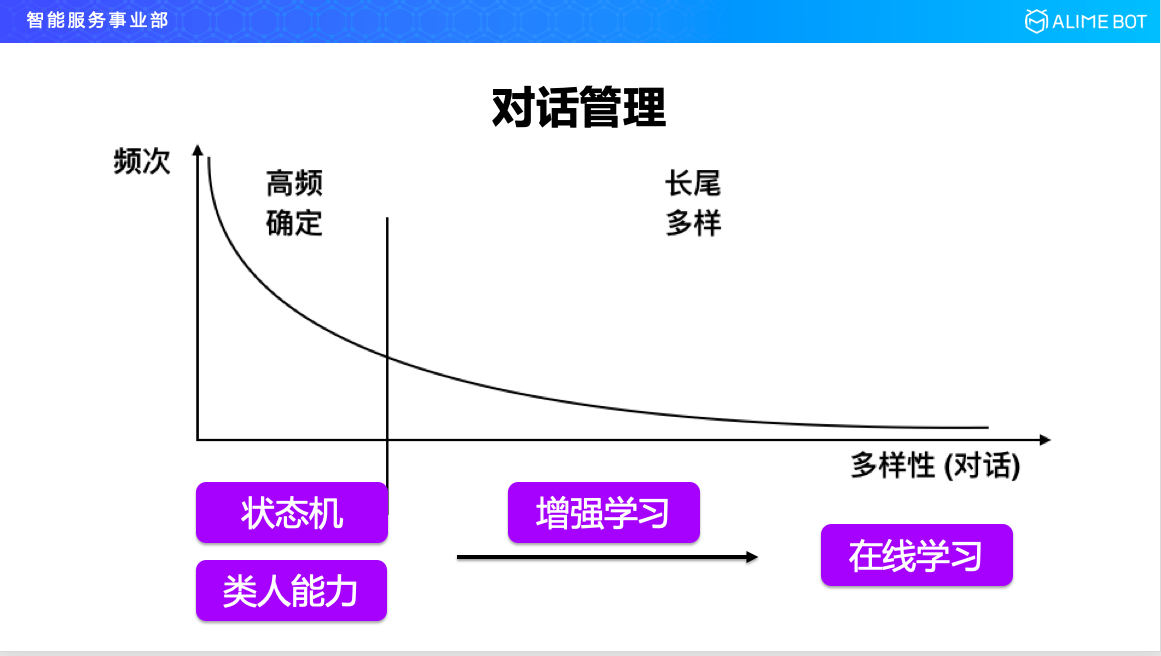
舉一個例子,比如像查天氣這樣的,如果採集十萬個查天氣的樣本,對這些使用者的說法進行一個頻率統計的話,大概就是這樣一個曲線,用兩步能夠完成的,比如說查天氣,先填槽一個時間再填槽一個地點,然後返回一個結果,通過這種流程來完成的,可能有兩萬次;中間可能會引入一些問 A 答 B 的情況,這樣的 B 可能有各種各樣的,就跑到長尾上來了,這樣整個對話其實也遵循一個冪律分佈。
對於高頻確定的部分,可以用狀態機進行解決,但狀態機同樣面臨一個問題,它沒有一個很好的容錯能力,當問 A 答 B 的時候,機器不知道下面怎麼接了。在這種情況下,需要引入一個類人能力,對狀態機的能力進行補充,狀態機加上類人能力以後,基本上可以把高頻的對話比較好的解決了。對於長尾上的對話,目前對於整個學術界或者工業界都是一個難題,比較好的解決方式就是上線以後引入線上互動學習,不斷跟使用者在對話過程中學習對話。在狀態機和線上互動學習之間其實是有 gap 的,因為狀態機自己沒有學習能力,所以需要引入增強學習。接下來我會介紹在類人能力以及增強學習方面的一些工作。
先看一下類人能力。我們把人說的話,做一下分類大概可以分為三種:第一種就是使用者說的話清晰明瞭只有一個意思,這種其實對機器來說是可理解的;第二種機器壓根兒不知道在說啥,也就是 unknown 的;還有一種就是使用者表達的意思可以理解,但是有歧義,有可能包含著兩個意圖、三個意圖,就是uncertain,不確定的。確定性的,狀態機其實是可以很好地捕捉和描述的,類人能力主要關注拒識的和不確定性的。
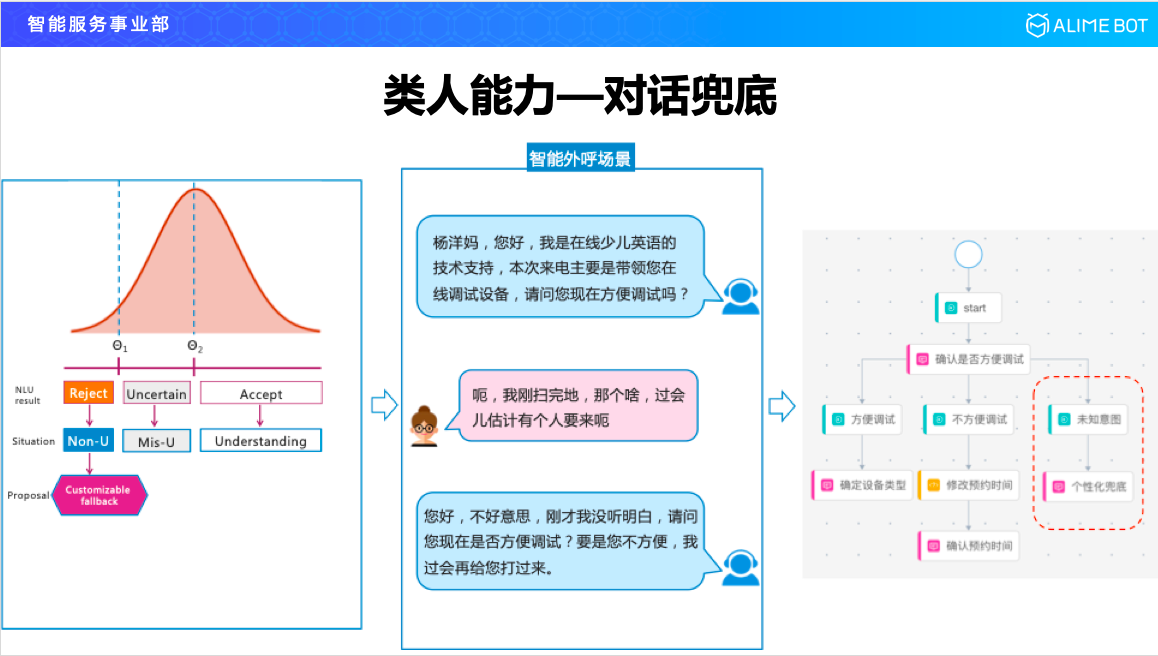
對於拒識這塊,比如還是線上英語的這個例子,機器人打來一個電話,問現在方不方便除錯裝置,這個時候從設計的角度來說希望使用者回答方便或者不方便就OK了,但是一旦這個使用者回答了一個比較個性化的話,比如,“呃,我剛掃完地,過會兒可能有人要來”,這時候我們的語言理解模組很難捕捉到這是什麼語義,這時候需要引入一個個性化的拒識,比如說,“您好,不好意思,剛才沒聽明白,請問您現在是否方便除錯,如果您不方便,我過會兒再給您打過來”,這個就是對話的兜底,是對 unknown 的處理。
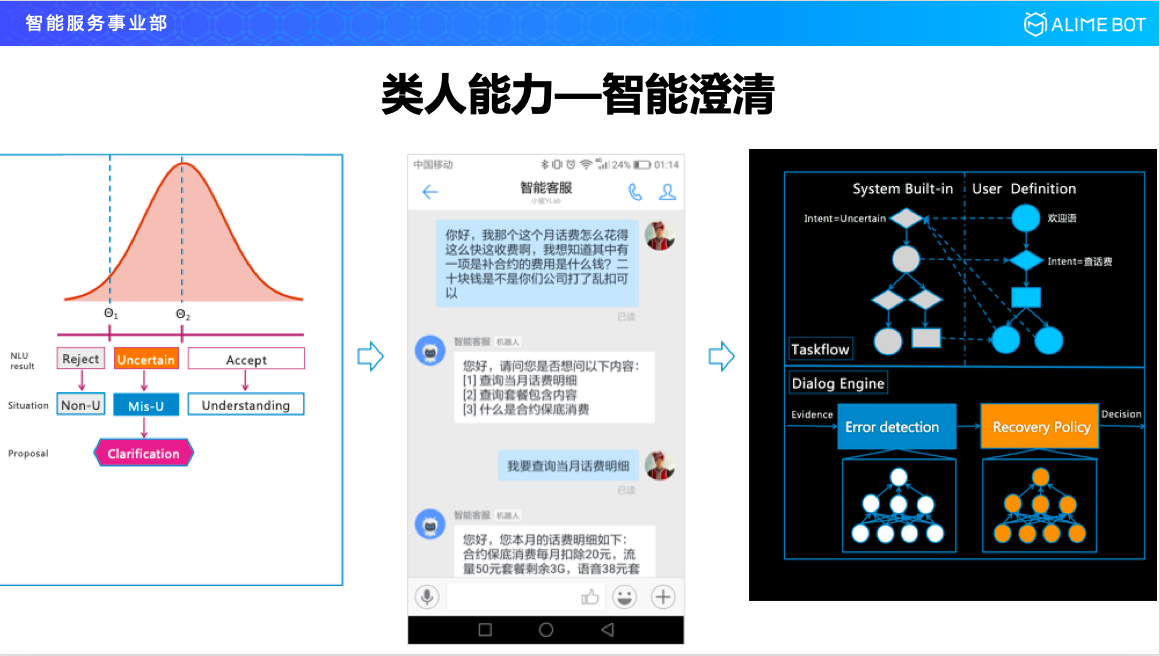
第二個我們看一下澄清,使用者說的一句話裡面,如果是模糊不清的怎麼辦?我們通過大量的資料分析發現這種模糊不清主要出現在兩種情況下,一種是使用者把多個意圖雜糅在一段話裡來表達;第二種是使用者在表達一個意圖之前做了很長的鋪墊,對於這兩種長句子現在的語言理解給出的是意圖的概率分佈,我們把這個概率分佈放到對話管理模組以後就需要讓使用者進行一輪澄清。比如這個例子,這是移動領域的一個例子,這句話理解有三種意圖,到底是想問花費明細,還是套餐的事情還是想問合約的低保,把這三個問題拋給使用者進行澄清就可以了。
從技術上來說是怎麼實現的呢,我們看一下這個圖,開發者負責把對話流程用流程圖清晰描述出來,然後像澄清這種其實是我們系統的一種內建能力,什麼時候澄清是通過下端的這兩個引擎裡面的能力來決定的,第一塊是 Error Detection,它用來檢測使用者當前說的這句話是否需要觸發澄清,一旦它覺得要觸發澄清,就會交給下一個模組,究竟用什麼樣的方式澄清以及怎麼生成澄清的話術,這是目前我們整個智慧澄清這塊做的工作。
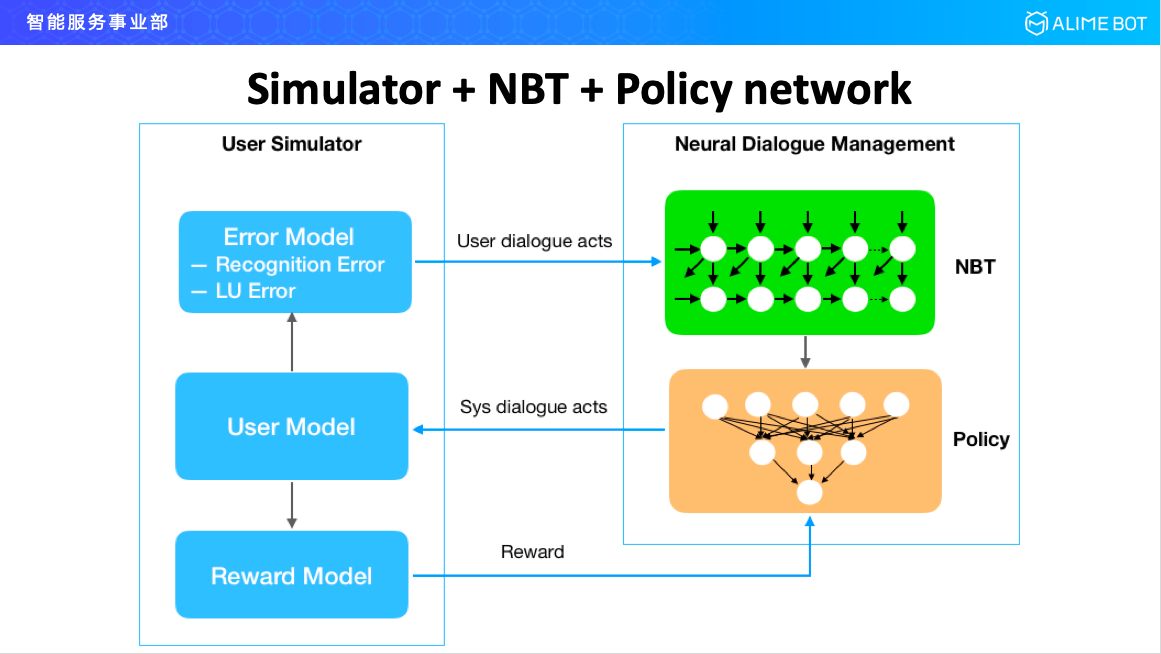
再看一下我們在增強學習方面的工作。在對話管理模型裡面,經典的分成兩個模組,一個是 neural belief tracker,用來做對話狀態追蹤的,另一個是 policy network,用來做行為決策的。在整個框架下,要去訓練這個網路的時候,有兩種訓練方式,一種是端到端的去訓練,用增強學習去訓練,但這種方式一般它的收斂速度會比較慢,訓練出的結果也不好;另外一種方式是先分別做預訓練,這個時候用監督學習訓練就好了,不用增強學習訓練,訓練完以後再用增強學習對監督學習預訓練的模型進行調優就可以了。
無論是端到端的一步訓練還是先預訓練再調優,只要涉及增強學習這一塊,都需要有一個外部環境,所以在我們的實現架構裡面,引入了模擬器的概念,就是user simulator。模擬器這主要分為三大塊,一個是 user model,用來模擬人的行為的;第二個是 error model,模擬完人的行為以後經過 error model 引入一個錯誤擾動,用 user model 產出的只是一個概率為 1 的東西,它對網路訓練是不夠好的,error model 會對這個結果進行擾動並給他引進幾個其他的結果,並且把概率分佈進行重新計算一下,這樣訓練出的模型在擴充套件能力或者泛化能力上會更好一些;第三個模組是 reward model,用來提供 reward 值。這是我們今天在整個增強學習的對話管理這塊的一些工作。
最後看一下函式計算。
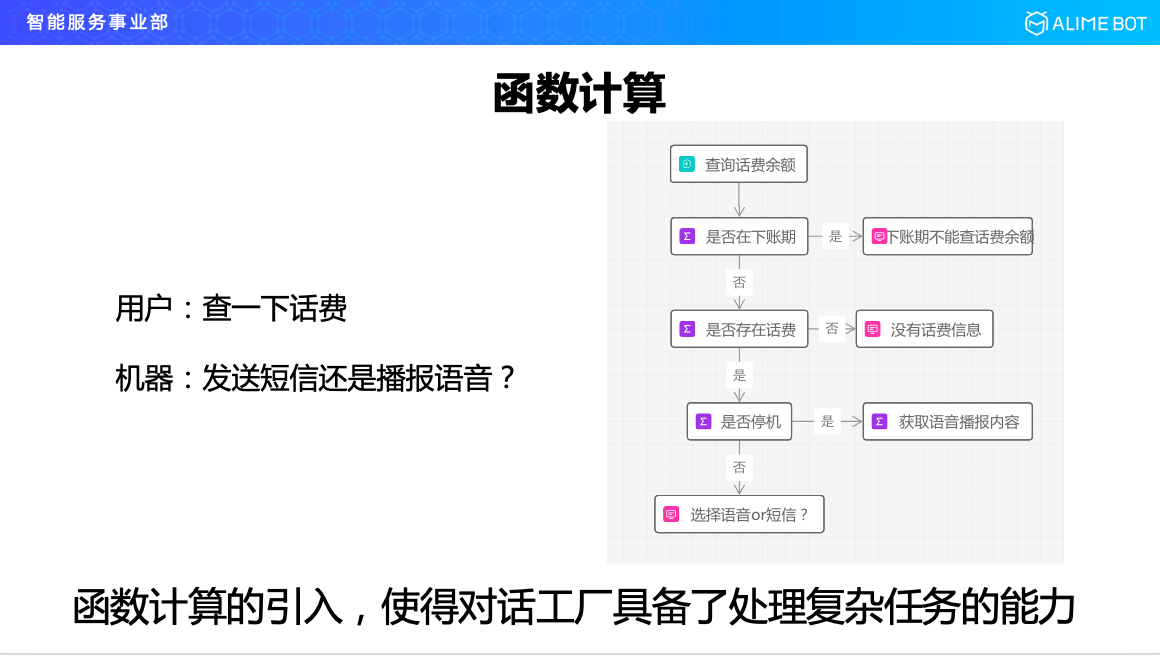
函式計算是什麼東西呢?還是舉一個例子吧,比如說,10086 裡面使用者說要查一下話費,10086 那邊的機器人就會回覆一句是發簡訊還是播放語音,表面看來就是簡單的一入一出,其實在這背後要經過多輪的服務查詢,才能完成這個結果,因為當要查話費的時候,先要經過函式計算查一下現在是哪一天,如果是下賬期的話是不能查話費的,就是每個月的最後一天不能查話費,如果可以查話費的話,先看一下使用者是否存在話費,如果存在花費的話第三步呼叫的服務看是不是停機了,因為停機了的話只能語音播報不能接收簡訊。所以看一下在一個簡單的一入一出的對話背後,是走了一個複雜的流程的,這些流程今天都是在機器端用程式碼來實現的。函式計算的引入,使對話工廠可以去處理複雜的任務。
業務應用
最後我們看一下對話工廠的業務應用情況。這是我們在浙江上線的 114 移車,當有市民舉報違規停車擋路後,就會自動打一個電話讓他移車。第二個是在金融領域裡面關於貸款催收的例子。在剛剛過去的雙十一里面,對話工廠在整個電商裡面也有大量應用,主要是在店小蜜和阿里小蜜裡面。店小蜜主要是一些開發票、催發貨、改地址這樣的流程,這裡是一個開發票的例子,使用者可能會先說一個開發票,進來以後要進行復雜的流程,一種是在說的時候其實他已經把它的訂單號送進來了,如果沒有說訂單號的話需要去後臺系統查訂單號,查出來以後彈一個訂單選擇器選擇訂單,接下來如果是個人發票就走這個流程,如果是公司發票走另一個流程,接下來會問是普通發票還是增值稅發票,如果是普通發票接著往這兒走,如果是增值稅發票需要獲取企業增值稅的稅號,最後彙總到一個節點,呼叫後臺開發票的系統,把發票開出來。這是這次雙十一里面用到的開發票的一個例子。
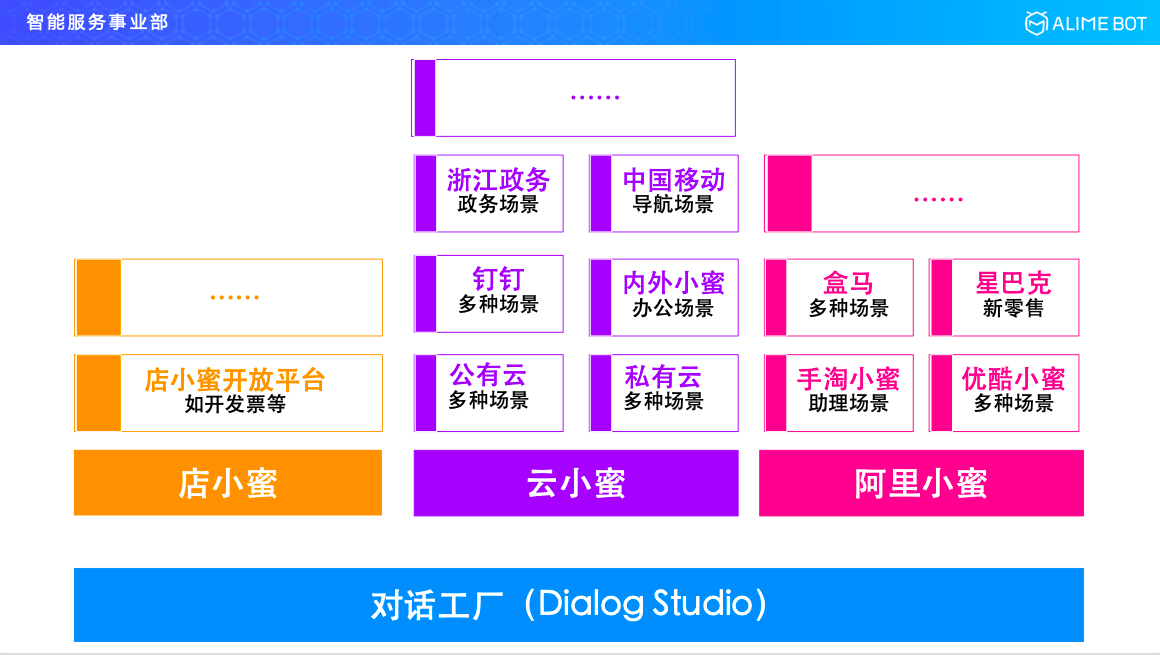
最後看一下我們整體的落地情況。整個對話工廠在店小蜜裡面主要是做像開發票這樣的售後流程的處理。在雲小蜜,公有云是一大塊;私有云現在有很多家客戶了,主要有銀行、電信運營商還有金融等;釘釘是我們另一個重要的端,釘釘上也有幾百萬的企業;內外小蜜是我們集團用小蜜實現的一個辦公助理;另外兩個巨大的客戶,一個是浙江省的政務,第二個是中國移動,這也是是雲小蜜的業務。阿里小蜜主要是負責阿里巴巴集團內部各個 BU 的業務,手淘是一個最大的業務,進入手機淘寶以後,進入“我的”裡面有一個客服小蜜,就是阿里小蜜;上個月我們剛剛在優酷上線了優酷小蜜,星巴克是 9 月份上的,是屬於新零售的一個最大的嘗試點,還有很多其他的場景。
總結
小蜜智慧對話開發平臺,即對話工廠(Dialog Studio),以對話為中心來設計,使得對話開發者能夠看到全域性視野,可以去做複雜的任務,可以去做無限的場景。同時,作為一個平臺性產品,為了能夠實現低門檻、適用於各行各業以及具備效果持續提升能力,在整個設計實現中,遵循冷啟動快、靈活定製、魯棒進化三大原則。技術方面,我們在語言理解、對話管理、遷移學習、增強學習以及模仿學習等各方面做了深入探索,部分成果做到了學術界state-of-the-art。業務方面,對話工廠在小蜜家族的大量業務中落地應用,帶來了良好的業務價值。
對話工廠,“讓人和機器自由對話”!