
聚類演算法推薦:一種元學習的方法
摘要:元學習是一種技術,其目的在於理解什麼型別的演算法解決什麼型別的問題。相比之下,聚類是基於物件的相似性把一個數據集劃分幾個簇,不需要物件類標籤的先驗知識。本文提出了基於無標籤物件特徵的提取,使用元學習推薦出聚類演算法。基於將要被計算的聚類問題的特徵以及不同聚類演算法的排序,從而元學習系統對於聚類問題可以精確的推薦出最好的演算法。
關鍵字:聚類,演算法推薦,排序,元學習
1.介紹
當今大量的資訊被表示和存進行後驗分析。研究者開始致力於開發出不同的方法從資料中提取知識;使用這些方法的過程被稱之為資料探勘。當今被各種演算法特徵化的資料探勘工具從而能解決每一個數據挖掘任務。然而,這個過程缺少選擇最好的演算法解決一個給定的資料探勘問題的指導。
元學習領域以發現哪些問題特徵有助於一個更好的或更壞的演算法效能,並且以此,為解決一個給定的問題推薦出最適當的演算法。為獲得這個目標,元學習建立了兩個關鍵的集合:(1)元屬性:一類問題的例項的共同特徵集合,像物件的數量和二元屬性的數量,以及其他的;(2)排序:基於一個性能度量指標,被應用到相同問題的一些演算法排序位置的集合。通過這兩個集合一個模型被建立,當應用到其他的沒有被用做訓練的問題時基於被提出的元屬性從而推薦出演算法的排序。
對於分類任務資料探勘和元學習之間的聯絡已經被廣泛的研究了。然而,對於聚類任務的研究可得的文獻很少。例如,沒有研究對於無監督學習問題,例如聚類,哪個特徵集最好。
在探討聚類問題的演算法推薦時,執行的實驗是基於分類問題相關文獻中描述的元屬性。儘管如此,這裡將選擇的特徵將不要求類標籤的知識,因此基於分類使我們的設計的方法可以泛化到聚類任務。
論文組織如下:第二部分簡單的介紹關於元學習的理論背景。第三部分解釋了實驗中使用的方法並且給出了實驗結果。論文在第四部分進行了總結,討論了實驗結果和和我們提出的方法的適應性。
2.元學習
元學習是一個關於學習的學習,例如,應用元學習必須學習機器學習演算法的行為以發現最好的演算法。在1994年,EU ESPRIT 工程StatLog擴充套件了這個概念,使演算法的效能和物件的特徵關聯到到分類問題上。
元學習與提取探索元知識的過程緊密相關,從一個演算法的學習過程中提取的元知識可以被假設成不同的形式,並且當被應用到一個問題時可以被定義成任何型別的知識。
元知識,也被稱做元資料,由元屬性和排序組成。元屬性是從問題中提取的特徵,例如, 為了特徵化分類問題,StatLog工程基於簡單度量、統計學和資訊理論提出了十六個元屬性的集合。排序即是當演算法的效能通過一個度量在相同問題上被度量時算法佔據的位置,例如,有效能值最好的算法佔據了第一個位置,第二個最好的佔據了第二個位置,等等。
元演算法負責學習元屬性和排序間關係,並且使用這個得到的知識計算演算法的排序。典型的機器學習演算法經常被用作元演算法,例如決策樹,神經網路,基於例項的學習,以及其他的。
對於元學習系統的概念模型由三個主要模組構造:(1)特徵提取模組:提取特徵(元屬性)負責特徵化和相互區分問題;(2)演算法評估模組:在給定的問題上使用預先定義的評估度量生成演算法的排序;(3)應用模組:使用一個元演算法負責演算法的排序。
元學習系統的概念模型
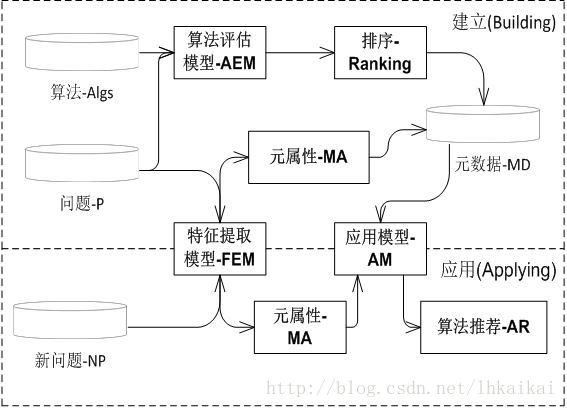
3.實驗
本文的目的是研究應用元學習技術到聚類問題的適應性,聚類問題可以通過從無標籤資料中提取的元屬性進行特徵化。實驗使用來自於相關文獻的資料集和為分類問題定義的資料特徵預測聚類演算法的排序。
3.1資料集
實驗使用的問題集合是30個來自UCI機器學習中心的資料集,有缺失值的物件被移除。選擇的資料集如下:哈伯曼的存活率、氣球、鶯尾花、汽車評估、浴室、乳腺癌、啤酒等等。
3.2元屬性
目前為止沒有固定的工作研究哪些元屬性應該被使用以特徵化在聚類任務中資料集。聚類演算法通常不能使用物件標籤的先驗資訊,本文研究中將要被提取的是無關慮物件的類標籤的元屬性。
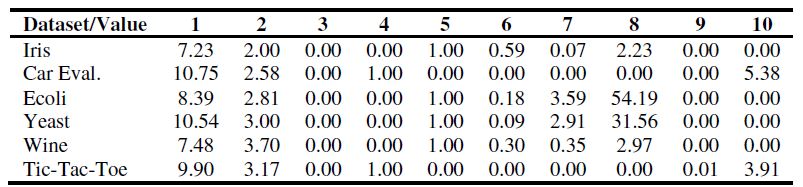
被選擇的是基於StatLog和METAL工程以及相關論文的元屬性,元屬性被規範化到[0, 1]。下表中解釋了一個元屬性的樣本,被選擇的元屬性是:(1)Log2物件的數量(2)Log2屬性的數量;(3)二元屬性的比例;(4)離散屬性的比例;(5)連續屬性的數量;(6)連續屬性間的平均絕對相關性;(7)連續屬性的平均偏度;(8)連續屬性的平均斜度;(9)離散屬性間的平均絕對聚集度;(10)離散屬性的平均熵。
表1: 對於一些資料集的元屬性
3.3聚類演算法
本文的研究評估了下列的聚類演算法:K-平均(KM);單連線(SL);全連線(CL);中心連線(ML)和自組織特徵對映(SOM)。這兒使用的自組織特徵對映是二維的,神經元的數量等於資料集簇的數量。所有的演算法都使用歐幾里德距離作為相異性度量標準。
要評估的聚類結果使用FBCubed度量,計算如下:

其中n是資料集中物件的數量,CL(i)是與物件i在相同的簇並且與物件i有相同的類標籤;Cluster(i)是與物件i在相同的簇中的物件數量。Label(i)與物件i有相同的標籤的物件的數量。
演算法在每一個數據集被執行30次,其效能通過FBC的結果值得到。排序被建立基於每個資料集上每個演算法的最好效能,並被用作預測值。
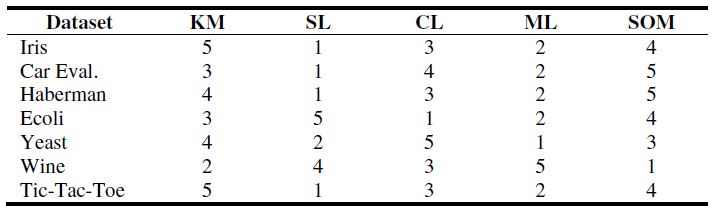
表2顯示了對於一些資料集所有聚類演算法的最好FBC結果,表3顯示了對於相同資料集的預測表,可以發現具有最高FBC值的聚類算法佔據了對於一個數據集排序中的第一個位置,並且第二個最高值佔據了第二個位置,等等。
表2:最好的FBC結果值對於聚類結果
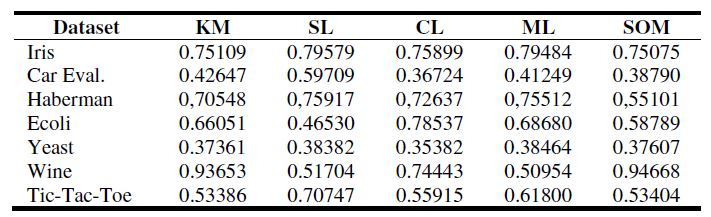
表3:被建立有排序值的預測表
3.4元演算法
元演算法負責學習元屬性和排序之間的關係,本文中將使用有不同的學習機制的4個機器學習演算法做為不同的元演算法:K-最近鄰(KNN);多層感知神經網路(MLP);決策樹(CART);和樸素貝葉斯(NB)。
為了評估預測的質量,將使用斯皮爾曼秩相關性(SRC),度量成對的有序的值之間的相關性。SRC給定的結果範圍在[-1, 1],其中+1意味著兩個排序是相等的,-1意味著它們是相反的。
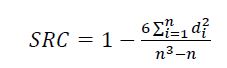
其中n是秩的大小,di是真實的和預測排序值在第i個位置的差異。
為了在元演算法之間比較結果,對於KNN和MLP演算法一個引數化的估算被執行以選擇最好的引數值。
在KNN演算法中,初始引數k確定了被考慮的鄰居的數量以計算輸出。進行了一個實驗k的變化從[1, 6],與其他的元演算法比較時選擇k=2。
在MLP演算法中, 使用不同數量的隱藏層神經元,神經元的數量從[1, 10],與其他的元演算法比較時選擇選擇6作為隱藏層神經元的數量。
3.5結果
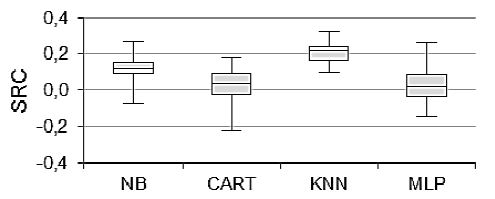
為了獲得每一個元演算法在預測和真實的排序間SRC值,進行了30次的10折交叉驗證。表4顯示了對於所有的元演算法的最終的推薦的SRC值的平均值和標準偏差。圖2解釋了對於所有的元演算法的SRC的方差。
表4: 對於排序推薦的斯皮爾曼秩相關性
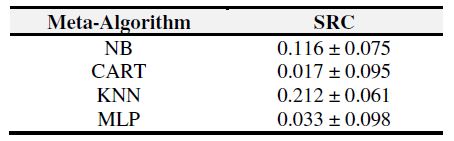
圖2: 元演算法SRC值盒圖
對元演算法進行里爾福斯測試以確定資料的正態性。里爾福斯測試的樣本來自沒有指定期望值和分佈的方差的一個均勻分佈總體的的空假設。使用0.01的顯著性水平,所有的結果被認為來自一個均勻的分佈。
為了驗證結果平均值之間的差別,一個t-測試被執行。t-測試驗證來自具有相等平均值的正態分佈樣本的空假設。通過KNN元演算法獲得的結果具有0.01顯著性水平被認為是不同的。
SRC有它的顯著性測試表的使用秩間沒有相關性的空假設,例如,假設驗證如果統計上相關性等於0。備擇假設(H1)將是一個正相關(SRC>0)或者一致的在排序之間(尾測試)。分析KNN元演算法真實的與推薦的排序之間的SRC;對於最好的SRC有0.05的顯著性水平,對於平均SRC有0.25的顯著性水平。
3.6對於新的資料集執行元學習系統
在設計了完整的元學習系統之後,用它為一個新的、沒有看到的資料集推薦出一個演算法。為了解釋, 使用了哈伯曼生存率資料集。表5顯示了從資料中提取的元屬性。系統使用這些元屬性為每一個聚類演算法推薦出一個排序(表6)。因此這個推薦系統在新的問題上不需要執行所有的演算法提供了關於演算法的效能的資訊。
表5: 從新問題中提取的元屬性

表6:對於新問題的排序推薦

4.總結
本文研究的目的是分析應用元學習技術到聚類問題時的適應性。為了達到這個目的,開發了一個系統負責從問題中提取元屬性、獲得選取的演算法的排序(建立元知識)、並使用元演算法建立一個預測模型。最終,這個元學習系統對於一個新問題只要從中提取元屬性就可以進行聚類演算法推薦。
現實中的聚類問題,資料標籤不是已知的先驗知識,提前推薦出可能的聚類演算法變得很重要。對於每個型別的問題基於其特徵,使用元學習可以為聚類問題選擇一個合適的演算法提供指導,
通過元學習系統得到的結果表明了元屬性的集合可以在問題特徵(元屬性)和聚類演算法的排序之間形成對映。本文中被使用的元屬性具有獨立與物件的類標籤的主要性質,從而元學習系統可以應用到任何聚類問題。保持這個性質,通過提取新的本質特徵擴充套件這個集合可能會得到更好的預測。
相關推薦
聚類演算法推薦:一種元學習的方法
摘要:元學習是一種技術,其目的在於理解什麼型別的演算法解決什麼型別的問題。相比之下,聚類是基於物件的相似性把一個數據集劃分幾個簇,不需要物件類標籤的先驗知識。本文提出了基於無標籤物件特徵的提取,使用元學習推薦出聚類演算法。基於將要被計算的聚類問題的特徵以及不同聚類演算法的排
聚類(clustering):一種無指導的學習演算法
聚類是一種無監督的學習的結果,聚類的結果就是產生一組集合,集合中的物件與同集合中的物件彼此相似,與其他集合的物件相異。聚類演算法是推薦給初學者的演算法,因為該演算法不僅十分簡單,而且還足夠靈活以面對大多數問題都能給出合理的結果。
聚類演算法實踐(一)——層次聚類、K-means聚類
因為百度雲的文章裡面有些圖片丟失了,想起這篇東西之前被一箇中國統計網轉發過,所以自己搜了一下想直接把圖搞回來,結果發現到處轉載的也有不少,自己現在發倒好像是抄襲似的。其實這篇文章裡面特別有價值的東西不算太多,PCCA算是一個知道的人不多而且也挺有意義的演算法,譜
【R與聚類演算法】:確定K值個數
在無監督學習中,很多朋友都會面臨同一個問題,我們應該將使用者聚成幾類?即如何確定K值問題。下面我們介紹兩種常用的方法。輪廓係數法Nbcluster輪廓係數法 首先,我們載入資料,並對資料進行預先處理。請看
《人工智慧:一種現代的方法(第3版)》.pdf
內容簡介 《人工智慧:一種現代的方法(第3版)》是最權威、最經典的人工智慧教材,已被全世界100多個國家的1200多所大學用作教材。 《人工智慧:一種現代的方法(第3版)》的最新版全面而系統地介紹了人工智慧的理論和實踐,闡述了人工智慧領域的核心內容,並深入介紹了各
《人工智慧:一種現代的方法》讀書筆記之 智慧Agent
本人人工智慧小白,為了惡補知識,所以買了一本綜述型的入門教材。終於看完了第一部分,人工智慧概述~~做一下筆記,便於後續記憶。 一、前提 AI的任務是設計Agent程式,實現的是把感知資訊對映到行動的Agent函式。 二、什麼是Agent Agen
Adam:一種隨機優化方法
我們介紹Adam,這是一種基於一階梯度來優化隨機目標函式的演算法。 簡介: Adam 這個名字來源於 adaptive moment estimation,自適應矩估計。概率論中矩的含義是:如果一個隨機變數 X 服從某個分佈,X 的一階矩是 E(X),也就
python聚類演算法以及影象顯示結果--python學習筆記23
資料: http://download.csdn.net/detail/qq_26948675/9683350 開啟後,點選藍色的名稱,檢視資源,就可以下載了 程式碼: #-*- coding: utf-8 -*- #使用K-Means演算法聚類消費行為特徵資
一種改進的自適應快速AF-DBSCAN聚類演算法
本人研究生期間寫的關於聚類演算法的一篇論文,已發表,希望對大家學習機器學習、資料探勘等相關研究有所幫助! 一種改進的自適應快速AF-DBSCAN聚類演算法 An Improved Adaptive and Fast AF-DBSCAN Clustering Algorit
一文盤點5種聚類演算法,資料科學家必備!
聚類是一種將資料點按一定規則分群的機器學習技術。 給定一組資料點,我們可以使用聚類演算法將每個資料點分類到一個特定的簇中。理論上,屬於同一類的資料點應具有相似的屬性或特徵,而不同類中的資料點應具有差異很大的屬性或特徵。 聚類屬於無監督學習中的一種方法,也是一種在許多領域中用於統計
Attention+:一種基於關注關係與多使用者行為的圖推薦演算法
劉夢娟, 王巍, 李楊曦,等. AttentionRank~+:一種基於關注關係與多使用者行為的圖推薦演算法[J]. 計算機學報, 2017(3). 基於Random Walk的TSPR演算法 該演算法採用一階Markov-chain計算遊走 概 率。方
一種面向高維資料的整合聚類演算法
聚類整合已經成為機器學習的研究熱點,它對原始資料集的多個聚類結果進行學習和整合,得到一個能較好地反映資料集內在結構的資料劃分。很多學者的研究證明聚類整合能有效地提高聚類結果的準確性、魯棒性和穩定性。本文提出了一種面向高維資料的聚類整合演算法。該方法針對高維資料的
PersonalRank:一種基於圖的推薦演算法
上面的二部圖表示user A對item a和c感興趣,B對a b c d都感興趣,C對c和d感興趣。本文假設每條邊代表的感興趣程度是一樣的。 現在我們要為user A推薦item,實際上就是計算A對所有item的感興趣程度。在personal rank演算法中不區分user節點和item節點,這樣一來問
大資料:Spark mlib(一) KMeans聚類演算法原始碼分析
1. 聚類1.1 什麼是聚類?所謂聚類問題,就是給定一個元素集合D,其中每個元素具有n個可觀察屬性,使用演算法將集合D劃分成k個子集,要求每個子集內部的元素之間相異度儘可能低,而不同子集的元素相異度儘可能高,其中每個子集叫做一個簇。1.2 KMeans 聚類演算法K-Mean
聚類演算法(一):k-均值 (k-means)演算法
首先確保你在動手寫程式碼之前已經瞭解什麼是聚類分析。 k-均值演算法----一種基於形心地技術的聚類演算法。k-均值演算法的英文名是k-means,那麼這個演算法是怎麼工作的呢? k-均值演算法把簇的形心定義為簇內點的均值。它的處理流程如下:1.在資料點集D中隨機的選擇k個
發表在 Science 上的一種新聚類演算法
今年 6 月份,Alex Rodriguez 和 Alessandro Laio 在 Science 上發表了一篇名為《Clustering by fast search and find of density peaks》的文章,為聚類演算法的設計提供了一種新的思路。雖
聚類演算法之DBSCAN演算法之二:高維資料剪枝應用NQ-DBSCAN
一、經典DBSCAN的不足 1.由於“維度災難”問題,應用高維資料效果不佳 2.執行時間在尋找每個點的最近鄰和密度計算,複雜度是O(n2)。當d>=3時,由於BCP等數學問題出現,時間複雜度會急劇上升到Ω(n的四分之三次方)。 二、DBSCAN在高維資料的改進 目前的研究有
聚類演算法之DBSCAN演算法之一:經典DBSCAN
DBSCAN是基於密度空間的聚類演算法,與KMeans演算法不同,它不需要確定聚類的數量,而是基於資料推測聚類的數目,它能夠針對任意形狀產生聚類。 1.epsilon-neighborhood epsoiln-neighborhood(簡稱e-nbhd)可理解為密度空間,表示半徑為e
吳恩達老師機器學習筆記K-means聚類演算法(一)
今天接著學習聚類演算法 以後堅決要八點之前起床學習!不要浪費每一個早晨。 K-means聚類演算法聚類過程如下: 原理基本就是先從樣本中隨機選擇聚類中心,計算樣本到聚類中心的距離,選擇樣本最近的中心作為該樣本的類別。最後某一類樣本的座標平均值作為新聚類中心的座標,如此往復。 原
ML之Clustering之普聚類演算法:普聚類演算法的相關論文、主要思路、關鍵步驟、程式碼實現等相關配圖之詳細攻略
ML之Clustering之普聚類演算法:普聚類演算法的相關論文、主要思路、關鍵步驟、程式碼實現等相關配圖之詳細攻略 普聚類演算法的相關論文 1、論文推薦 Clustering by fast search and find of density peak.