python聚類演算法以及影象顯示結果--python學習筆記23
資料:
http://download.csdn.net/detail/qq_26948675/9683350
開啟後,點選藍色的名稱,檢視資源,就可以下載了
程式碼:
#-*- coding: utf-8 -*-
#使用K-Means演算法聚類消費行為特徵資料
import pandas as pd
#引數初始化
inputfile = 'chapter5/demo/data/consumption_data.xls' #銷量及其他屬性資料
outputfile = 'chapter5/demo/data_type.xls' #儲存結果的檔名
k = 3 #聚類的類別
iteration = 500 #聚類最大迴圈次數
data = pd.read_excel(inputfile, index_col = 'Id') #讀取資料
data_zs = 1.0*(data - data.mean())/data.std() #資料標準化
from sklearn.cluster import KMeans
model = KMeans(n_clusters = k, n_jobs = 4, max_iter = iteration) #分為k類,併發數4
model.fit(data_zs) #開始聚類
#簡單列印結果
r1 = pd.Series(model.labels_).value_counts() #統計各個類別的數目
r2 = pd.DataFrame(model.cluster_centers_) #找出聚類中心
r = pd.concat([r2, r1], axis = 1) #橫向連線(0是縱向),得到聚類中心對應的類別下的數目
r.columns = list(data.columns) + [u'類別數目'] #重命名錶頭
print(r)
#詳細輸出原始資料及其類別
r = pd.concat([data, pd.Series(model.labels_, index = data.index)], axis = 1) #詳細輸出每個樣本對應的類別
r.columns = list(data.columns) + [u'聚類類別'] #重命名錶頭
r.to_excel(outputfile) #儲存結果
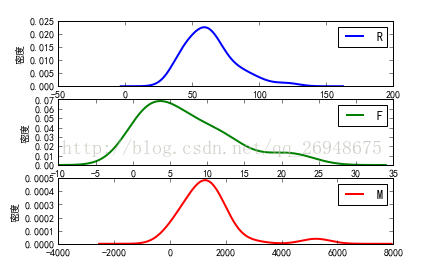
def density_plot(data): #自定義作圖函式
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #用來正常顯示中文標籤
plt.rcParams['axes.unicode_minus'] = False #用來正常顯示負號
p = data.plot(kind='kde', linewidth = 2, subplots = True, sharex = False)
[p[i].set_ylabel(u'密度') for i in range(k)]
plt.legend()
return plt
pic_output = 'chapter5/demo/data' #概率密度圖檔名字首
for i in range(k):
density_plot(data[r[u'聚類類別']==i]).savefig(u'%s%s.png' %(pic_output, i))
#-*- coding: utf-8 -*-
#接k_means.py
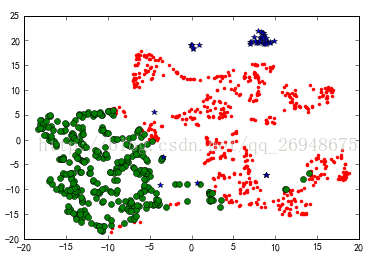
from sklearn.manifold import TSNE
tsne = TSNE()
tsne.fit_transform(data_zs) #進行資料降維
tsne = pd.DataFrame(tsne.embedding_, index = data_zs.index) #轉換資料格式
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #用來正常顯示中文標籤
plt.rcParams['axes.unicode_minus'] = False #用來正常顯示負號
#不同類別用不同顏色和樣式繪圖
d = tsne[r[u'聚類類別'] == 0]
plt.plot(d[0], d[1], 'r.')
d = tsne[r[u'聚類類別'] == 1]
plt.plot(d[0], d[1], 'go')
d = tsne[r[u'聚類類別'] == 2]
plt.plot(d[0], d[1], 'b*')
plt.show()
結果: