
《人工智慧:一種現代的方法》讀書筆記之 智慧Agent
本人人工智慧小白,為了惡補知識,所以買了一本綜述型的入門教材。終於看完了第一部分,人工智慧概述~~做一下筆記,便於後續記憶。
一、前提
AI的任務是設計Agent程式,實現的是把感知資訊對映到行動的Agent函式。
二、什麼是Agent
Agent就是能夠行動的某種東西,具備自主的操作、感知環境、長期持續、適應變化並能建立與追求目標。
三、什麼是合理Agent
合理Agent是一個為了實現最佳結果,或者,當存在不確定性時,為了實現最佳期望結果而行動的Agent。
- 正確的推理
合理行動的一種方法是邏輯地推理出給定行動將實現其目標的結論,然後遵照那個結論行動,但是正確的推理並不是合理性的全部。 - 有限合理性
當沒有足夠的時間來完成所有你想要做的計算時仍能恰當的行動。
四、什麼是智慧Agent
智慧Agent要採取一個環境中最好的可能行為。
智慧主要與理性行為相關。
五、Agent和環境的關係
Agent通過感測器感知環境並通過執行器對所處環境產生影響。
- 感知是用來表示任何給定時刻Agent的感知輸入。
- Agent的感知序列是該Agent所受到的所有輸入資料的完整歷史。Agent在任何給定時刻的行動選擇依賴於到那個時刻為止該Agent的整個感知序列。
- Agent函式描述了Agent的行動,它將任意給定感知序列對映為行動。
- Agent函式是抽象的數學描述
- Agent程式是具體實現
六、理性-好的行為
6.1 什麼是理性Agent
理性Agent是做事正確的Agent。
6.2 理性的判斷依賴
- 定義成功標準的效能度量
- Agent對環境的先驗知識
- Agent可以完成的行動
- Agent截止到此時的感知序列
6.3 理性Agent的定義
對每一個可能的感知序列,根據已知的感知序列提供的證據和Agent具有的先驗知識,理性Agent應該選擇能使其效能度量最大化的行動。
6.4 理性與全知的區別
- 一個全知的Agent明確的知道它的行動產生的實際結果並且做出相應的動作。全知者在現實中是不可能的。
- 理性是使期望的效能最大化,而完美是使實際的效能最大化。對Agent而言,完美是不太合理的要求。
- 理性並不要求全知。理性的選擇只依賴於到當時為止的感知序列。
6.5 理性Agent的兩大特點
- 資訊收集
觀察有助於期望效能的最大化。 - 自主學習
從所感知的資訊中儘可能多的學習,以彌補不完整的或者不正確的先驗知識。
七、任務環境
7.1 定義:PEAS描述
- Performance效能
- Environment環境
- Actuators執行器
- Sensors感測器
7.2 設計Agent的第一步
儘可能完整地詳細說明任務環境。
7.3 性質
7.3.1 完全可觀察的vs部分可觀察的
- 如果Agent的感測器在每個時間節點上都能獲取環境的完整狀態,這個任務環境就是完全可觀察的。否則,則是部分可觀察的。
- 如果感測器能夠檢測所有與行動決策相關的資訊,該任務環境就是有效完全可觀察的。
- 如果Agent根本沒有感測器,環境則是無法觀察的。
7.3.2 單Agent vs 多Agent
區分兩者的關鍵在於Agent B 行為的效能度量最大化是否需要依賴於Agent A的行為。
競爭性的多Agent環境
Agent B想要最大化自己的效能度量,就需要最小化Agent A的效能度量。合作性的多Agent環境
Agent B想要最大化自己的效能度量,就需要最大化Agent A的效能度量。部分合作部分競爭的多Agent環境
上述兩種情況都會發生。
7.3.3 確定的 vs 隨機的
如果環境的下一個狀態完全取決於當前狀態和Agent執行的動作,則該環境是確定的;否則,是隨機的。
不確定與隨機的區別
- 環境不確定是指 環境不是完全可觀察的或不確定的,行動後果可能有多種,但與概率無關。
- 環境隨機是指後果是不確定的並且可以用概率來量化。
7.3.4 片段式 vs 延續式
片段式是指 當前決策不會影響到未來的決策。
延續式是指 當前決策會影響到所有未來的決策。
7.3.5 靜態 vs 動態
如果環境在Agent計算的時候會變化,該環境是動態的,否則是靜態的。
如果環境本身不隨時間變化而變化,但Agent的效能評價隨時間變化,則環境是半動態的。
7.3.6 離線 vs 連續
離線和連續的使用場景有:
- 環境的狀態
- 時間的處理方式
- Agent的感知資訊和行動
7.3.7 已知 vs 未知
Agent的知識狀態。
如果環境是未知的,Agent需要學習環境是如何工作的,以便做出好的決策。
7.4 最難處理的情況
部分可觀察的、多Agent的、隨機的、延續的、動態的、連續的和未知的環境。
8 Agent的結構
Agent = 體系結構 + 程式。
8.1 體系結構
體系結構:某個具備物理感測器和執行器的計算裝置。
體系結構為程式提供來自感測器的感知資訊,執行程式,並把程式計算出的行動決策送達執行器。
8.2 Agent程式的框架
8.2.1 輸入
從感測器得到的當前感知資訊
8.2.2 輸出
執行器的行動抉擇
8.2.3 基本的Agent程式
8.2.3.1 簡單反射Agent
定義
基於當前的感知選擇行動,不關注感知歷史。
最簡單的Agent型別。
針對完全可觀察的環境。方法
Step 1:首先構建一個通用的條件-行為規則直譯器。
Step 2:根據特定任務環境建立相應的規則集合。缺點
在部分可觀察環境中運轉的簡單反射Agent經常不可避免地陷入無限迴圈中。示意圖和虛擬碼見書P44

8.2.3.2 基於模型的反射Agent
定義
世界模型:
- 知識一:世界是如何獨立於Agent而發展的資訊
- 知識二:Agent自身的行動如何影響世界
使用世界模型的Agent稱為基於模型的Agent
- 通過將當前的感知資訊與過去的內部狀態結合來更新當前狀態
- 針對部分可觀測環境
缺點
部分可觀察環境中的Agent不能精準確定當前狀態示意圖和虛擬碼見書P46

8.2.3.3 基於目標的Agent
- 定義
既跟蹤記錄世界的狀態,也記錄它要達到的目標集合,並選擇能(最終)導致目標達成的行動 - 特點
效率低、靈活、可學習。 - 不適用的情況
- 多個目標互相沖突
- 有幾個目標,但沒有一個有把握達到
這兩種情況,通過效用Agent可以解決
- 示意圖見P47

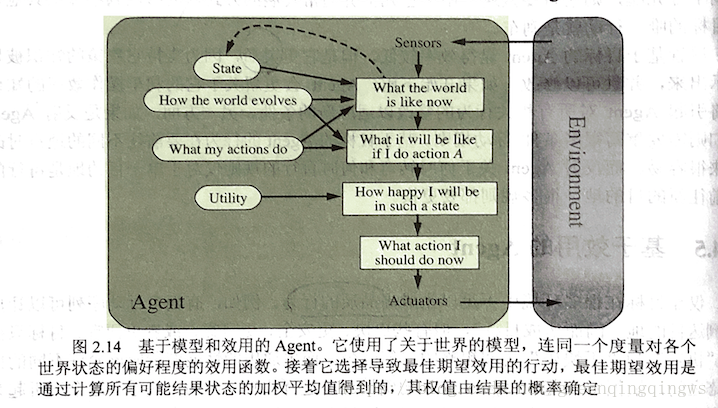
8.2.3.4 基於效用的Agent
- 定義
理性的基於效用的Agent 選擇 期望效用最大化的行動,Agent在給定每個結果的概率和效用下,期望得到的平均效用。 - 方法
Step 1:使用關於世界的模型,以及對各個世界狀態的偏好程度進行度量的效用函式。
Step 2:選擇可以取得最佳期望效用的行動。
Step 3:通過結果的概率來確定權值,最佳期望效用是通過計算所有可能結果狀態的加權平均值得到的。 - 適用情況
1、當多個目標互相沖突時,只有其中一些目標可以達到時,效用函式可以在它們之間適當的折中。
2、當Agent有幾個目標,但沒有一個有把握達到時,效用函式可以在它們之間適當的折中。 - 示意圖見書P48
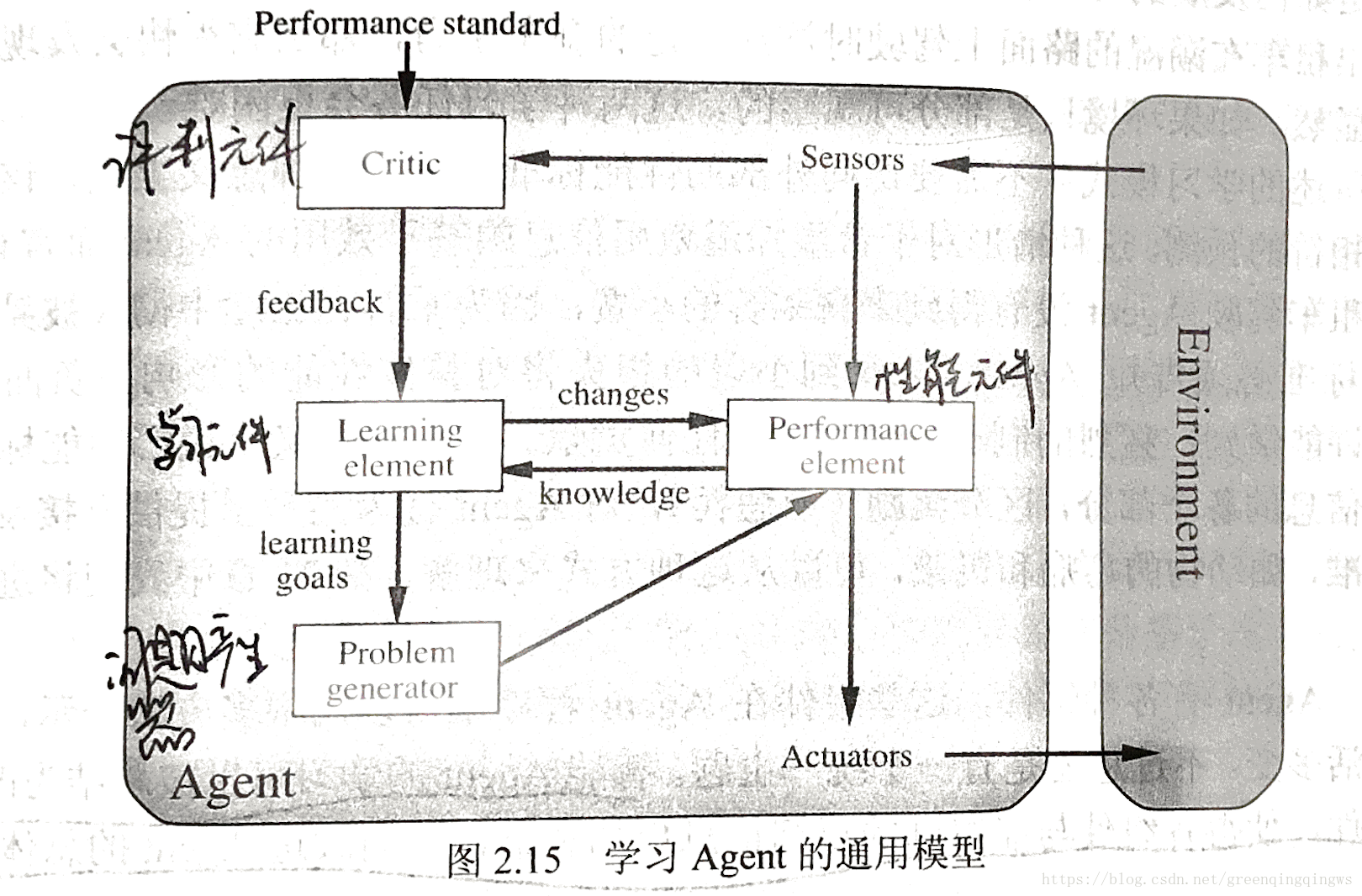
8.2.4 學習Agent的通用模型
8.2.4.1 學習元件
負責改進提高
8.2.4.2 效能元件
負責選擇外部行動,接受感知資訊並決策
8.2.4.3 評判元件
根據固定的效能指標告訴學習元件Agent的運轉情況
8.2.4.4 問題產生器
負責可以得到新的和有資訊的經驗的行動提議,建議探索性行動
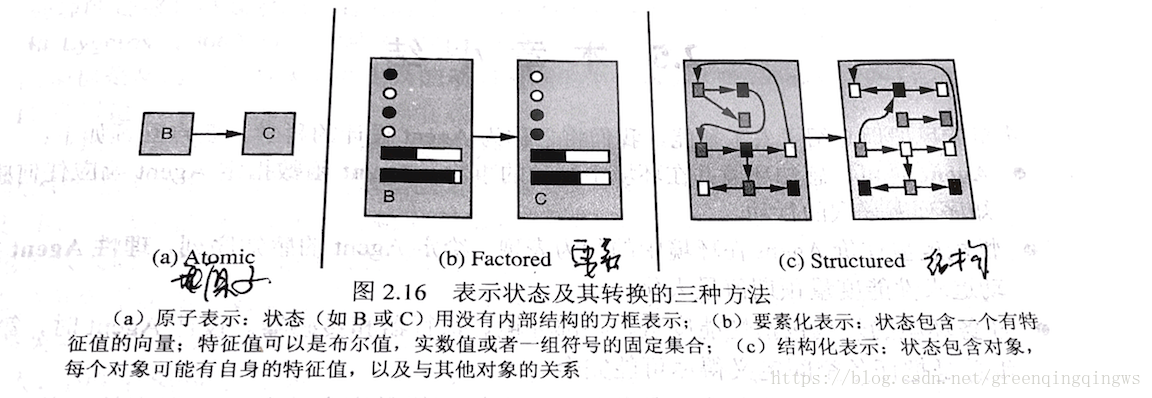
8.2.5 Agent程式的元件表示形式
8.2.5.1 原子表示
每個狀態是不可見的,沒有內部結構
8.2.5.2 要素化表示
將狀態表示為變數或者特徵的集合,每個變數或特徵都可能有值。
兩個不同的要素化表示可以共享一些特徵。
8.2.5.3 結構化表示
描述物件之間的關係
8.3 Agent函式
輸入:整個感知歷史