
機器學習之邏輯迴歸(二)
二項邏輯迴歸模型是如下的條件概率分佈:
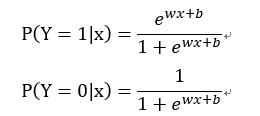
其中x∈是輸入,y∈{0,1}是輸出。
為了方便,將權值向量和輸入向量進行擴充,此時w =  ,x =
,x = 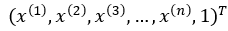 ,迴歸模型表示如下:
,迴歸模型表示如下:

引數w未知,採用統計學中的極大似然估計來由樣本估計引數w。對於0-1分佈x ~ B(1 , p),x的概率密度函式可以表示為:
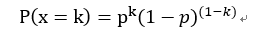
其中k = 0或1。
構造極大似然函式:
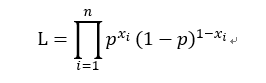
取對數得:

同理對於二項邏輯迴歸,我們令:

則其似然函式為:

其中yi取值為0或1。
取對數得:
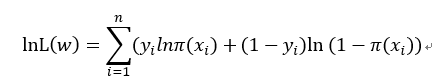
求上式的最大值等價於對上式取負號後的最小值問題,得:

問題就轉換成了以對數似然函式為目標函式的最優化問題,對於該最優化問題常使用梯度下降法或擬牛頓法。
通常把邏輯迴歸問題的代價函式定義成以上形式,對數似然函式在y=0或是y=1其影象如下如所示
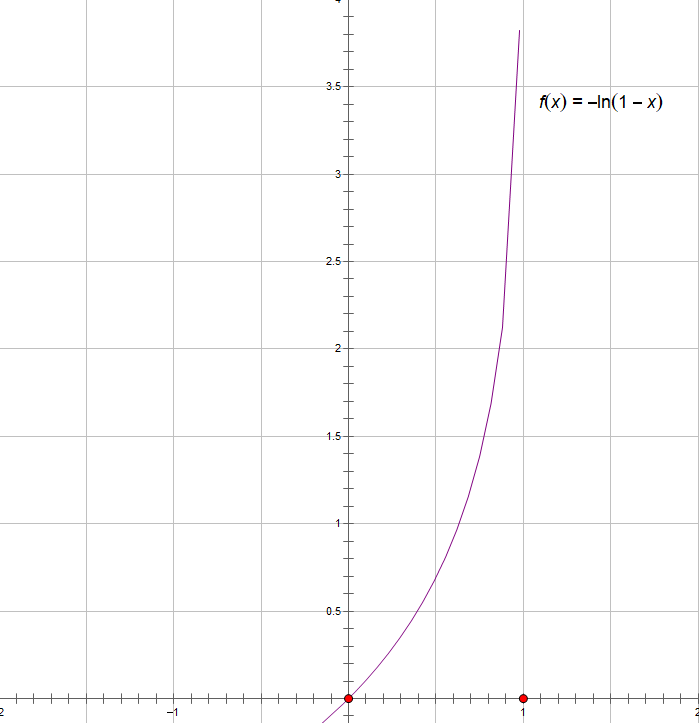

這樣可以保證代價函式是一個凸函式,使用梯度下降演算法時,可以得到全域性最優解。
相關推薦
機器學習之邏輯迴歸(二)
二項邏輯迴歸模型是如下的條件概率分佈: 其中x∈是輸入,y∈{0,1}是輸出。 為了方便,將權值向量和輸入向量進行擴充,此時w = ,x = ,迴歸模型表示如下: 引數w未知,採用統計學中的極大似然估計來由樣本估計引數w。對於0-1分佈x
機器學習之數學系列(二)邏輯迴歸反向傳播數學推導
一、簡介 在深度學習領域,我們往往採用梯度下降(或上升)法來優化訓練函式模型,梯度下降法尤其是在優化凸函式上表現極佳。模型優化涉及到反向傳播過程,反向傳播過程需要先推匯出梯度計算公式然後利用機器進行代數運算。這篇博文的工作是詳細推導了邏輯迴歸反向傳播梯度計算公式(什麼是梯度?簡單來講
機器學習之邏輯迴歸(logistic regression)
概述 邏輯斯蒂迴歸實質是對數機率迴歸(廣義的線性迴歸),是用來解決分類問題的。 其中sigmoid用來解決二分類問題,softmax解決多分類問題,sigmoid是softmax的特殊情況。 數學建模直接針對分類可能性建模。 引數學習可用極大似然估計
機器學習之邏輯迴歸(logistics regression)程式碼(牛頓法實現)
先貼一張圖解釋牛頓法原理: 然後以一道問題為例: 這個問題是《機器學習》周志華版本上的題目,給了西瓜的密度和含糖率資料,判斷西瓜的好壞。資料在程式碼裡。 下面貼一下程式碼: <span style="font-size
輕松入門機器學習之概念總結(二)
消息 目的 作者 固定 erp 效率 dev 常用 度量 歡迎大家前往雲加社區,獲取更多騰訊海量技術實踐幹貨哦~ 作者:許敏 接上篇:機器學習概念總結筆記(一) 8)邏輯回歸 logistic回歸又稱logistic回歸分析,是一種廣義的線性回歸分析模型,常用於數據挖掘
機器學習之決策樹(二)
天氣 次數 format 定義 表示 葉子節點 ast 代碼 wid 一、復習信息熵 為了解決特征選擇問題,找出最優特征,先要介紹一些信息論裏面的概念。 1、熵(entropy) python3代碼實現: def calcShannonEnt(
系統學習機器學習之特徵工程(二)--離散型特徵編碼方式:LabelEncoder、one-hot與啞變數*
轉自:https://www.cnblogs.com/lianyingteng/p/7792693.html 在機器學習問題中,我們通過訓練資料集學習得到的其實就是一組模型的引數,然後通過學習得到的引數確定模型的表示,最後用這個模型再去進行我們後續的預測分類等工作。在模型訓練過程中,我們會對訓練
【機器學習】softmax迴歸(二)
通過上篇softmax迴歸已經知道大概了,但是有個缺點,現在來仔細看看 Softmax迴歸模型引數化的特點 Softmax 迴歸有一個不尋常的特點:它有一個“冗餘”的引數集。為了便於闡述這一特點,假設我們從引數向量 中減去了向量 ,這時,每一個
機器學習之聚類(二)
在機器學習和資料探勘中,我們經常需要知道個體間差異的大小,進而評價個體的相似性和類別。最常見的是資料分析中的相關分析,資料探勘中的分類和聚類演算法,如 K 最近鄰(KNN)和 K 均值(K-Means)等等。根據資料特性的不同,可以採用不同的度量方法
系統學習機器學習之線性判別式(二)
1. 原文: 2 問題引入 假設有一個房屋銷售的資料如下: 面積(m^2) 銷售價錢(萬元) 123 250 150 320 87 160 102 220 … … 這個表類似於北京5環左右的房屋價錢
機器學習算法整理(二)邏輯回歸 python實現
alt bubuko 邏輯 style res n) regress com png 邏輯回歸(Logistic regression) 機器學習算法整理(二)邏輯回歸 python實現
機器學習之線性迴歸(Linear Regression)
線性學習中最基礎的迴歸之一,本文從線性迴歸的數學假設,公式推導,模型演算法以及實際程式碼執行幾方面對這一回歸進行全面的剖析~ 一:線性迴歸的數學假設 1.假設輸入的X和Y是線性關係,預測的y與X通過線性方程建立機器學習模型 2.輸入的Y和X之間滿足方程Y= θ
機器學習之線性迴歸(機器學習基石)
引子 在一個二元分類的問題中我們通常得到的結果是1/0,而在分類的過程中我們會先計算一個得分函式然後在減去一個門檻值後判斷它的正負若為正則結果為1若為負結果為0。 事實上從某種角度來看線性迴歸只是二元分類步驟中的一個擷取它沒有後面取正負號的操作,它的輸出結果為一個實數而非
小白學習之Code First(二)
文件中 build 默認 dbm pcre student 技術分享 使用 類名 Code First約定: 註:EDMX模板 (SSDL:存儲模型=>數據庫表 ,CSDL:概念模型=>實體,C-S模型=>存儲和概念模型之間的映射關系) System.Da
ng機器學習視頻筆記(二) ——梯度下降算法解釋以及求解θ
表示 大於 解釋 圖片 bubuko eight 閾值 自己 極小值 ng機器學習視頻筆記(二) ——梯度下降算法解釋以及求解θ (轉載請附上本文鏈接——linhxx) 一、解釋梯度算法 梯度算法公式以及簡化的代價函數圖,如上圖所示。
機器學習之數學基礎(一)-微積分,概率論和矩陣
系列 學習 python 機器學習 自然語言處理 圖片 clas 數學基礎 記錄 學習python快一年了,因為之前學習python全棧時,沒有記錄學習筆記想回顧發現沒有好的記錄,目前主攻python自然語言處理方面,把每天的學習記錄記錄下來,以供以後查看,和交流分享。~~
JavaWeb學習之Hibernate框架(二)
utils xtend auto etl SQ dial begin 可選 oct hibernateAPI詳解 Configuration 創建 加載主配置 創建sessionFactory
機器學習之K-近鄰(KNN)算法
實戰 http created 以及 dex mda 問題 可以轉化 占比 一 . K-近鄰算法(KNN)概述 最簡單最初級的分類器是將全部的訓練數據所對應的類別都記錄下來,當測試對象的屬性和某個訓練對象的屬性完全匹配時,便可以對其進行分類。但是怎麽可能所有測
28 Java學習之NIO Buffer(二)(待補充)
客戶 oca opened output write 系統方面 eba 了解 取出 一. Buffer介紹 Buffer,故名思意,緩沖區,實際上是一個容器,是一個連續數組。Channel提供從文件、網絡讀取數據的渠道,但是讀取或寫入的數據都必須經由Buffer。具體看下面
28 Java學習之NIO Buffer(二)(待補充)
一. Buffer介紹 Buffer,故名思意,緩衝區,實際上是一個容器,是一個連續陣列。Channel提供從檔案、網路讀取資料的渠道,但是讀取或寫入的資料都必須經由Buffer。具體看下面這張圖就理解了: 上面的圖描述了從一個客戶端向服務端傳送資料,然後服務端接收資料的過程。客戶端傳送資料時,必