
【彩票】彩票預測演算法(一):離散型馬爾可夫鏈模型C#實現
前言:彩票是一個坑,千萬不要往裡面跳。任何預測彩票的方法都不可能100%,都只能說比你盲目去買要多那麼一些機會而已。
已經3個月沒寫部落格了,因為業餘時間一直在研究彩票,發現還是有很多樂趣,偶爾買買,娛樂一下。本文的目的是向大家分享一個經典的數學預測演算法的思路以及程式碼。對於這個馬爾可夫鏈模型,我本人以前也只是聽說過,研究不深,如有錯誤,還請賜教,互相學習。
1.馬爾可夫鏈預測模型介紹
馬爾可夫鏈是一個能夠用數學方法就能解釋自然變化的一般規律模型,它是由著名的俄國數學家馬爾科夫在1910年左右提出的。馬爾科夫過程已經是現在概率論中隨機過程理論的一個重要方面。經過了一百年左右的發展,馬爾可夫過程已經滲透到各個領域併發揮了重要的作用,如在我們熟知的經濟、通訊領域,除此之外在地質災害、醫療衛生事業、生物學等自然科學領域也發揮了非常重要的作用。
人們在對實際問題的研究中會發現隨著時間的持續發展變化會產生很多現象。還有一些現象或過程可以表述如下:在“現在”是已知的情況下,這種變化過程的“未來”與“過去”是毫無聯絡的。也就是說這種過程的未來所出現的情況不依賴於過去的發展變化,我們就把具有上述性質的過程稱之為馬爾可夫過程。馬爾可夫過程可以描述現實生活中的很多現象。例如,我們熟知的液體中的顆粒所做的布朗運動、在商業活動中所要研究的每天銷售情況、在數字通訊中的語音訊號、視訊訊號等。馬爾可夫鏈在其他領域的應用還有很多,如在銀行的不良資產的管理、機車管理、企業管理、生態環境演變、城市用水量模擬、資訊處理等科學研究和生產生活中都有廣泛應用。
2.馬爾可夫鏈的數學概念和性質
定義1:

定義2:

上面是2個最簡單的馬爾可夫鏈的數學定義,看不懂沒關係,簡單解釋一下:
1.從狀態k到k+1與時間k無關,也就是說這個隨機過程與時間k無關,而從k到k+1狀態,有一個轉移概率,馬爾可夫鏈的核心其實也就是這個轉移概率;
2.根據馬爾可夫鏈的思想,一步轉移概率Pij很容易得到,但是預測的時候,往往要根據最近K期的資料來進行,所以要計算K步轉移概率;
3.任意步的轉移概率可以根據C-K方程來計算,CK方程是一種計算轉移概率的基本方法,簡單的演算法就是:通過一步轉移概率矩陣P獨自相乘m次,就可以得到m步轉移概率。
4.馬爾可夫鏈的思想,就是根據歷史的資料,統計得到轉移概率,然後根據滯時權重對每個狀態進行預測,概率最高的是最可能出現的。
5.對於離散型馬爾可夫鏈序列變數,一般計算之前需要對變數進行“馬氏性”檢驗,統計量就是卡方分佈。
6.馬爾可夫鏈的研究還有很多其他的方面,比如狀態分類,極限概率,平穩分佈等等,這些太高階,沒時間去搞很懂,這些對預測過程的精度是有一定影響的。
3.離散型馬爾可夫鏈變數預測步驟
3.1 狀態分類
對於離散型變數來說,首先要把目標的資料進行歸類,對模型來說,一般狀態都是有限的,比如說雙色球,可以把16個籃球號碼分為8個狀態,2個一組。當然一些經濟和實際生活資料的狀態分類,就要根據實際情況了。
3.2 計算轉移概率矩陣
轉移概率矩陣是可以根據歷史資料的頻率f(i,j)統計得到。f(i,j)是狀態i到狀態j轉移的次數;然後概率轉移矩陣
p(i,j) = f(i,j)/f(i.) ;頻數除以當前行的和值即為概率
3.3 "馬氏性"檢驗
對於離散型的變數,需要利用歷史資料進行“馬氏性”檢驗。檢驗公式為:

然後根據顯著性水平(程式中固定取0.05) ,查表求m自由度時的閥值,若 ,則滿足 馬氏性,可以進行下一步的預測,否則沒有多大的意義。
3.4 計算自相關係數和各種步長的權重
若滿足馬氏性,就可以對下一個狀態進行預測了,預測根據滯時k,有權重調整,權重W(k)是根據自相關係數R(k)計算得到的,公式如下:
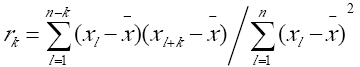
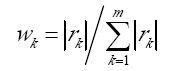
k為滯時期,我程式測試裡面選的5,L是總的歷史資料次數,X是歷史資料序列。
3.5 計算不同滯時期的轉移概率矩陣
根據C-K方程提供的演算法,計算k步的轉移概率矩陣 Pi(k) ,又一次轉移概率矩陣自乘 k次得到。
3.6 預測下一個狀態
下一個狀態的預測概率通過相同狀態的各個預測概率加權和得到,計算用到公式:
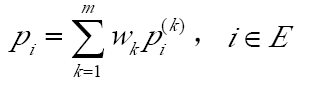
最後一步的時候要注意,要根據最後k期的歷史資料所在狀態值和步長的權值相乘。滯時期為1的資料,是最後1期資料(最新的資料),這個迴圈的時候要注意,很容易掉進坑裡。
4.離散型馬爾可夫鏈模型程式碼
本文使用C#實現了簡單的離散型馬爾可夫鏈模型,在驗證馬氏性的時候,由於需要查表求值,所以暫時固定了自由度25,顯著性水平0.05,模型核心程式碼:
1 /// <summary>離散型馬爾可夫鏈預測模型</summary> 2 public class DiscreteMarkov 3 { 4 #region 屬性 5 /// <summary>樣本點狀態時間序列,按照時間升序</summary> 6 public List<int> StateList { get; set; } 7 /// <summary>狀態總數,對應模型的m</summary> 8 public int Count { get; set; } 9 /// <summary>概率轉移矩陣Pij</summary> 10 public List<DenseMatrix> ProbMatrix { get; set; } 11 /// <summary>各階的自相關係數</summary> 12 public double[] Rk { get; set; } 13 /// <summary>各階的權重/summary> 14 public double[] Wk { get; set; } 15 /// <summary>頻數矩陣/summary> 16 public int[][] CountStatic { get; set; } 17 /// <summary>目標序列是否滿足"馬氏性"/summary> 18 public Boolean IsMarkov { get; set; } 19 /// <summary>滯時期,K/summary> 20 public int LagPeriod { get; set; } 21 22 /// <summary>預測概率</summary> 23 public double[] PredictValue { get; set; } 24 #endregion 25 26 #region 建構函式 27 public DiscreteMarkov(List<int> data, int count,int K = 5) 28 { 29 this.StateList = data; 30 this.LagPeriod = K; 31 this.Count = count; 32 this.CountStatic = StaticCount(data, count); 33 this.ProbMatrix = new List<DenseMatrix>(); 34 var t0 = DenseMatrix.OfArray(StaticProbability(this.CountStatic).ConvertToArray<double>()); 35 ProbMatrix.Add(t0); 36 37 for (int i = 1; i < K; i++) //根據CK方程,計算各步的狀態轉移矩陣 38 { 39 var temp = ProbMatrix[i - 1] * t0; 40 ProbMatrix.Add(temp); 41 } 42 if (ValidateMarkov()) 43 { 44 CorrCoefficient(); 45 TimeWeight(); 46 PredictProb(); 47 } 48 else 49 { 50 Console.WriteLine("馬氏性 檢驗失敗,無法進行下一步預測"); 51 } 52 } 53 #endregion 54 55 #region 驗證 56 /// <summary>驗證是否滿足馬氏性,預設的顯著性水平是0.05,自由度25</summary> 57 /// <returns></returns> 58 public Boolean ValidateMarkov() 59 { 60 //計算列和 61 int[] cp1 = new int[Count]; 62 int allcount = CountStatic.Select(n => n.Sum()).Sum();//總數 63 64 for (int i = 0; i < Count; i++) 65 { 66 for (int j = 0; j < Count; j++) cp1[i] += CountStatic[j][i]; 67 } 68 double[] cp = cp1.Select(n => (double)n / (double)allcount).ToArray(); 69 70 //計算伽馬平方統計量 71 double gm = 0; 72 for (int i = 0; i < Count; i++) 73 { 74 for (int j = 0; j < Count; j++) 75 { 76 if (CountStatic[i][j] != 0) 77 gm += 2 * CountStatic[i][j] * Math.Abs(Math.Log(ProbMatrix[0][i,j] / cp[j], Math.E)); 78 } 79 } 80 //查表求a = 0.05時,伽馬分佈的臨界值F(m-1)^2,如果實際的gm值大於差別求得的值,則滿足 81 //查表要自己做表,這裡只演示0.05的情況 卡方分佈 82 return gm >= 37.65; 83 } 84 85 /// <summary>計算相關係數</summary> 86 public void CorrCoefficient() 87 { 88 double mean = (double)StateList.Sum() /(double) StateList.Count;//均值 89 90 double p = StateList.Select(n => (n - mean)*(n-mean)).Sum(); 91 92 Rk = new double[LagPeriod]; 93 94 for (int i = 0; i < LagPeriod; i++) 95 { 96 double s1 = 0; 97 for (int L = 0; L < StateList.Count - LagPeriod ; L++) 98 { 99 s1 += (StateList[L] - mean) * (StateList[L + i] - mean); 100 } 101 Rk[i] = s1 / p; 102 } 103 } 104 105 /// <summary>計算滯時的步長</summary> 106 public void TimeWeight() 107 { 108 double sum = Rk.Select(n=>Math.Abs(n)).Sum(); 109 Wk = Rk.Select(n => Math.Abs(n) / sum).ToArray(); 110 } 111 112 /// <summary>預測狀態概率</summary> 113 public void PredictProb() 114 { 115 PredictValue = new double[Count]; 116 //這裡很關鍵,權重和滯時的關係要顛倒,迴圈計算的時候要注意 117 //另外,要根據最近幾期的出現數,確定概率的狀態,必須取出最後幾期的資料 118 119 //1.先取最後K期資料 120 var last = StateList.GetRange(StateList.Count - LagPeriod, LagPeriod); 121 //2.注意last資料是升序,最後一位對於的滯時期 是k =1 122 for (int i = 0; i < Count; i++) 123 { 124 for (int j = 0; j < LagPeriod; j++) 125 { 126 //滯時期j的資料狀態 127 var state = last[last.Count - 1 - j] - 1; 128 PredictValue[i] += Wk[j] * ProbMatrix[j][state ,i]; 129 } 130 } 131 } 132 #endregion 133 134 #region 靜態 輔助方法 135 /// <summary>統計頻數矩陣</summary> 136 /// <param name="data">升序資料</param> 137 public static int[][] StaticCount(List<int> data, int statusCount) 138 { 139 int[][] res = new int[statusCount][]; 140 141 for (int i = 0; i < statusCount; i++) res[i] = new int[statusCount]; 142 143 for (int i = 0; i < data.Count - 1; i++) res[data[i]-1][data[i + 1]-1]++; 144 145 return res; 146 } 147 /// <summary>根據頻數,計算轉移概率矩陣</summary> 148 /// <param name="data">頻率矩陣</param> 149 public static double[][] StaticProbability(int[][] data) 150 { 151 double[][] res = new double[data.Length][]; 152 for (int i = 0; i < data.Length; i++) 153 { 154 int sum = data[i].Sum(); 155 res[i] = data[i].Select(n => (double)n / (double)sum).ToArray(); 156 } 157 return res; 158 } 159 #endregion 160 }
呼叫方法很簡單,如下程式碼:這裡使用的是論文文獻中的資料,單個號碼的隨機概率為16.6%,程式預測的概率可以到25-30%的樣子,應該還有調整的空間。
1 //歷史狀態資料 2 List<int> data = new List<int>(){ 3 6,4,4,5,2,4,6,1,2,6, 5,6,4,4,6 , 5,3,6,5,2 , 5,3,3,4,4, 4 4,1,1,1,1,3,5,6,5,5, 5,5,4,6,5 , 4,1,3,1,3 , 1,3,1,2,5, 5 2,2,5,5,1,4,4,2,6,1, 5,4,6,3,2, 2,6,4,4,4, 4,3,1,5,3, 6 1,2,6,5,3,6,3,6,4,6, 2,4,4,6,3, 3,6,2,6,1, 3,2,2,6,6, 7 4,4,3,1,4,1,2,6,4,4, 1,2};//,6,4,3,6,2,5,5,5 8 9 var result = new DiscreteMarkov(data, 6,5);
5.實際案例
哈哈,請關注部落格,年後將根據此演算法,對高頻彩快3和11選5進行實證分析。因為這個過程有點複雜,不是一下子可以搞定的。
本文的相關文字資料,公式和資料來源根據這篇文獻:“馬爾可夫鏈預測模型及一些應用”,2012.3 溫海彬
最後,彩票風險很大,購彩需謹慎。你的熱情和推薦,是我的動力哦。
補充一下,其中有一個擴充套件方法,進行陣列轉換的,忘記貼上去了:
1 public static T[,] ConvertToArray<T>(this T[][] data) 2 { 3 T[,] res = new T[data.Length, data[0].Length]; 4 for (int i = 0; i < data.Length; i++) 5 { 6 for (int j = 0; j < data[i].Length; j++) res[i, j] = data[i][j]; 7 } 8 return res; 9 }
相關推薦
【彩票】彩票預測演算法(一):離散型馬爾可夫鏈模型C#實現
前言:彩票是一個坑,千萬不要往裡面跳。任何預測彩票的方法都不可能100%,都只能說比你盲目去買要多那麼一些機會而已。 已經3個月沒寫部落格了,因為業餘時間一直在研究彩票,發現還是有很多樂趣,偶爾買買,娛樂一下。本文的目的是向大家分享一個經典的數學預測演算法的思路以及程式碼。對於這個馬爾可夫鏈模型,我本人
【隨機過程】馬爾可夫鏈(1)
【隨機過程】馬爾可夫鏈 標籤(空格分隔): 【訊號處理】 說明:馬爾科夫鏈是一個離散的馬爾科夫過程,本文主要對基本的研究思路和應用進行梳理,通過具體的例項來總結是一個非常好的嘗試。 馬爾科夫鏈的一個應用案例:排隊論 比如客戶服務排隊,
一份數學小白也能讀懂的「馬爾可夫鏈蒙特卡洛方法」入門指南
作品 -c ecc 般的 eight 哪裏 疊加 值範圍 gallery 作者 | Ben Shaver 翻譯 | 劉暢 編輯 | Donna 大多數時候,貝葉斯統計在結果在最好的情況下是魔法,在最糟糕時是一種完全主觀的廢話。在用到貝葉斯方法的理論體系中,馬爾可
【原創】Junit4詳解一:Junit總體介紹
1 package abstractions.domain; 2 3 import static org.hamcrest.Matchers.is; 4 import static org.junit.Assert.assertThat; 5 6
【MVC】.Net實踐(一)—建立mvc框架的專案和實體模型
一、 建立MVC框架的專案 (1)像新增平常專案一樣新增一個web應用程式,檔案—>新建—>專案 (3)接著選擇MVC (4)這樣就建好一個MVC框架的專案了 二、連線資料庫 建立
【演算法】 隱馬爾可夫模型 HMM
隱馬爾可夫模型 (Hidden Markov Model,HMM) 以下來源於_作者 :skyme 地址:http://www.cnblogs.com/skyme/p/4651331.html 隱馬爾可夫模型(Hidden Markov Model,HMM)是統計模型,它用來描述一
隱馬爾可夫模型學習筆記(一):前後向演算法介紹與推導
學習隱馬爾可夫模型(HMM),主要就是學習三個問題:概率計算問題,學習問題和預測問題。概率計算問題主要是講前向演算法和後向演算法,這兩個演算法可以說是隱馬爾可夫的重中之重,接下來會依次介紹以下內容。 隱馬爾可夫模型介紹 模型的假設 直接計演算法,前向演算法,後向演
【NLP】揭祕馬爾可夫模型神祕面紗系列文章(一)
作者:白寧超 2016年7月10日20:34:20 摘要:最早接觸馬爾可夫模型的定義源於吳軍先生《數學之美》一書,起初覺得深奧難懂且無什麼用場。直到學習自然語言處理時,才真正使用到隱馬爾可夫模型,並體會到此模型的妙用之處。馬爾可夫模型在處理序列分類時具體強大的功能,諸如解決:詞類標註、語音識別、句
【RL系列】馬爾可夫決策過程——狀態價值評價與動作價值評價的統一
ice .html .net bsp cor python-r and text 系列 請先閱讀上兩篇文章: 【RL系列】馬爾可夫決策過程中狀態價值函數的一般形式 【RL系列】馬爾可夫決策過程與動態編程 狀態價值函數,顧名思義,就是用於狀態價值評價(SVE)的。典型的問
【HDOJ6229】Wandering Robots(馬爾科夫鏈,set)
聯通 tin queue 開放 答案 轉移 first gcd 格子 題意:給定一個n*n的地圖,上面有k個障礙點不能走,有一個機器人從(0,0)出發,每次等概率的不動或者往上下左右沒有障礙的地方走動,問走無限步後停在圖的右下部的概率 n<=1e4,k<=1e3
【統計學習方法-李航-筆記總結】十、隱馬爾可夫模型
本文是李航老師《統計學習方法》第十章的筆記,歡迎大佬巨佬們交流。 主要參考部落格: https://www.cnblogs.com/YongSun/p/4767667.html https://www.cnblogs.com/naonaoling/p/5701634.html htt
【LeetCode】11. Container With Most Water(盛最多水的容器)-C++實現的三種方法
本題是Bloomberg的面試題。 問題描述: 一、第一種方法-暴力解法 當我們在面試時想不到解題的方法時,不妨使用暴力解法,雙重遍歷陣列。 當 i = 0 時,使用指標 j 遍歷陣列,找到第一輪的最大值 area: 當i = 2 ,使用指標 j 遍歷
【機器學習筆記18】隱馬爾可夫模型
【參考資料】 【1】《統計學習方法》 隱馬爾可夫模型(HMM)定義 隱馬爾可夫模型: 隱馬爾可夫模型是關於時序的模型,描述一個由隱藏的馬爾可夫鏈生成的不可觀測的狀態序列,再由各個狀態生成的觀測值所構成的一個觀測序列。 形式化定義HMM為λ=(A,B,π)\la
hmm前後向演算法 隱馬爾科夫模型HMM(三)鮑姆-韋爾奇演算法求解HMM引數 隱馬爾科夫模型HMM(四)維特比演算法解碼隱藏狀態序列 隱馬爾科夫模型HMM(一)HMM模型
跟醫生就醫推導過程是一樣的 隱馬爾科夫模型HMM(一)HMM模型 隱馬爾科夫模型HMM(二)前向後向演算法評估觀察序列概率 隱馬爾科夫模型HMM(三)鮑姆-韋爾奇演算法求解HMM引數 隱馬爾科夫模型HMM(四)維特比演算法解碼隱藏狀態序列 在隱馬爾科夫模型HMM(一)
機器學習筆記(一):關於隱含馬爾科夫模型
這篇文章是我在看完吳軍老師的數學之美一書中關於隱馬爾科夫模型之後所寫,旨在記錄一下自己對隱馬爾科夫模型的認識, 隱馬爾科夫模型我在很早之前就有所接觸,在學習語音識別的時候,會涉及到隱馬爾科夫模型,當時是完全不懂,現在雖然還是一知半解,因為沒有再次去使用,接下來的主攻方向是機器視覺,對隱馬爾可
【NLP】揭祕馬爾可夫模型神祕面紗系列文章(二)
作者:白寧超 2016年7月11日15:31:11 摘要:最早接觸馬爾可夫模型的定義源於吳軍先生《數學之美》一書,起初覺得深奧難懂且無什麼用場。直到學習自然語言處理時,才真正使用到隱馬爾可夫模型,並體會到此模型的妙用之處。馬爾可夫模型在處理序列分類時具體強大的功能,諸如解決:詞類標註、語音識別、句
【NLP】揭祕馬爾可夫模型神祕面紗系列文章(三)
作者:白寧超 2016年7月11日22:54:57 摘要:最早接觸馬爾可夫模型的定義源於吳軍先生《數學之美》一書,起初覺得深奧難懂且無什麼用場。直到學習自然語言處理時,才真正使用到隱馬爾可夫模型,並體會到此模型的妙用之處。馬爾可夫模型在處理序列分類時具體強大的功能,諸如解決:詞類標註、語音識別、句
【NLP】揭祕馬爾可夫模型神祕面紗系列文章(五)
作者:白寧超 2016年7月12日14:28:10 摘要:最早接觸馬爾可夫模型的定義源於吳軍先生《數學之美》一書,起初覺得深奧難懂且無什麼用場。直到學習自然語言處理時,才真正使用到隱馬爾可夫模型,並體會到此模型的妙用之處。馬爾可夫模型在處理序列分類時具體強大的功能,諸如解決:詞類標註、語音識別、句
【NLP】揭祕馬爾可夫模型神祕面紗系列文章(四)
作者:白寧超 2016年7月12日14:08:28 摘要:最早接觸馬爾可夫模型的定義源於吳軍先生《數學之美》一書,起初覺得深奧難懂且無什麼用場。直到學習自然語言處理時,才真正使用到隱馬爾可夫模型,並體會到此模型的妙用之處。馬爾可夫模型在處理序列分類時具體強大的功能,諸如解決:詞類標註、語音識別、句
【中文分詞】隱馬爾可夫模型HMM
Nianwen Xue在《Chinese Word Segmentation as Character Tagging》中將中文分詞視作為序列標註問題(sequence tagging problem),由此引入監督學習演算法來解決分詞問題。 1. HMM 首先,我們將簡要地介紹HMM(主要參考了李航老師的《