
pca 和lda區別
這學期選了門模式識別的課。發現最常見的一種情況就是,書上寫的老師ppt上寫的都看不懂,然後繞了一大圈去自己查資料理解,回頭看看發現,Ah-ha,原來本質的原理那麼簡單,自己一開始只不過被那些看似formidable的細節嚇到了。所以在這裡把自己所學的一些點記錄下來,供備忘,也供參考。
1. K-Nearest Neighbor
K-NN可以說是一種最直接的用來分類未知資料的方法。基本通過下面這張圖跟文字說明就可以明白K-NN是幹什麼的
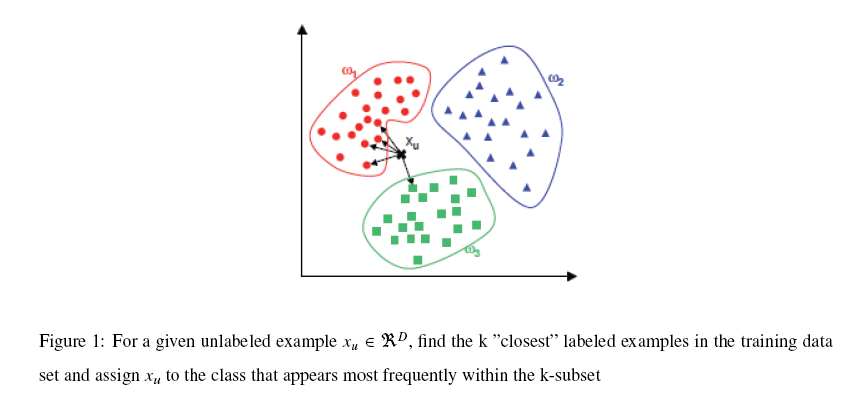
簡單來說,K-NN可以看成:有那麼一堆你已經知道分類的資料,然後當一個新資料進入的時候,就開始跟訓練資料裡的每個點求距離,然後挑離這個訓練資料最近的K個點看看這幾個點屬於什麼型別,然後用少數服從多數的原則,給新資料歸類。一個比較好的介紹k-NN的課件可以見下面連結,圖文並茂,我當時一看就懂了
實際上K-NN本身的運算量是相當大的,因為資料的維數往往不止2維,而且訓練資料庫越大,所求的樣本間距離就越多。就拿我們course project的人臉檢測來說,輸入向量的維數是1024維(32x32的圖,當然我覺得這種方法比較silly),訓練資料有上千個,所以每次求距離(這裡用的是歐式距離,就是我們最常用的平方和開根號求距法) 這樣每個點的歸類都要花上上百萬次的計算。所以現在比較常用的一種方法就是kd-tree。也就是把整個輸入空間劃分成很多很多小子區域,然後根據臨近的原則把它們組織為樹形結構。然後搜尋最近K個點的時候就不用全盤比較而只要比較臨近幾個子區域的訓練資料就行了。kd-tree的一個比較好的課件可以見下面連結:
 那麼如何求出這個長軸和短軸呢?於是線性代數就來了:我們求出這堆資料的協方差矩陣(關於什麼是協方差矩陣,詳見本節最後附的連結),然後再求出這個協方差矩陣的特徵值和特徵向量,對應最大特徵值的那個特徵向量的方向就是長軸(也就是主元)的方向,次大特徵值的就是第二主元的方向,以此類推。
關於PCA,推薦兩個不錯的tutorial:
(1) A tutorial on Principle Component Analysis從最基本的數學原理到應用都有,讓我在被老師的講課弄暈之後瞬間開悟的tutorial:
(2) 裡面有一個很生動的實現PCA的例子,還有告訴你PCA跟SVD是什麼關係的,對程式設計實現的幫助很大(當然大多數情況下都不用自己編了):
那麼如何求出這個長軸和短軸呢?於是線性代數就來了:我們求出這堆資料的協方差矩陣(關於什麼是協方差矩陣,詳見本節最後附的連結),然後再求出這個協方差矩陣的特徵值和特徵向量,對應最大特徵值的那個特徵向量的方向就是長軸(也就是主元)的方向,次大特徵值的就是第二主元的方向,以此類推。
關於PCA,推薦兩個不錯的tutorial:
(1) A tutorial on Principle Component Analysis從最基本的數學原理到應用都有,讓我在被老師的講課弄暈之後瞬間開悟的tutorial:
(2) 裡面有一個很生動的實現PCA的例子,還有告訴你PCA跟SVD是什麼關係的,對程式設計實現的幫助很大(當然大多數情況下都不用自己編了):
4. Linear Discriminant Analysis
LDA,基本和PCA是一對雙生子,它們之間的區別就是PCA是一種unsupervised的對映方法而LDA是一種supervised對映方法,這一點可以從下圖中一個2D的例子簡單看出

圖的左邊是PCA,它所作的只是將整組資料整體對映到最方便表示這組資料的座標軸上,對映時沒有利用任何資料內部的分類資訊。因此,雖然做了PCA後,整組資料在表示上更加方便(降低了維數並將資訊損失降到最低),但在分類上也許會變得更加困難;圖的右邊是LDA,可以明顯看出,在增加了分類資訊之後,兩組輸入對映到了另外一個座標軸上,有了這樣一個對映,兩組資料之間的就變得更易區分了(在低維上就可以區分,減少了很大的運算量)。
PCA 是無監督的,它所作的只是將整組資料整體對映到最方便表示這組資料的座標軸上,對映時沒有利用任何資料內部的分類資訊
用主要的特徵代替其他相關的非主要的特徵,所有特徵之間的相關度越高越好
但是分類任務的特徵可能是相互獨立的
LDA是有監督的,使得類別內的點距離越近越好(集中),類別間的點越遠越好。
在實際應用中,最常用的一種LDA方法叫作Fisher Linear Discriminant,其簡要原理就是求取一個線性變換,是的樣本資料中“between classes scatter matrix”(不同類資料間的協方差矩陣)和“within classes scatter matrix”(同一類資料內部的各個資料間協方差矩陣)之比的達到最大。關於Fisher LDA更具體的內容可以見下面課件,寫的很不錯~
5. Non-negative Matrix Factorization
NMF,中文譯為非負矩陣分解。一篇比較不錯的NMF中文介紹文可以見下面一篇博文的連結,《非負矩陣分解:數學的奇妙力量》
這篇博文很大概地介紹了一下NMF的來龍去脈(當然裡面那幅圖是錯的。。。),當然如果你想更深入地瞭解NMF的話,可以參考Lee和Seung當年發表在Nature上面的NMF原文,"Learning the parts of objects by non-negative matrix factorization"
讀了這篇論文,基本其他任何介紹NMF基本方法的材料都是浮雲了。
NMF,簡而言之,就是給定一個非負矩陣V,我們尋找另外兩個非負矩陣W和H來分解它,使得後W和H的乘積是V。論文中所提到的最簡單的方法,就是根據最小化||V-WH||的要求,通過Gradient Discent推匯出一個update rule,然後再對其中的每個元素進行迭代,最後得到最小值,具體的update rule見下圖,注意其中Wia等帶下標的符號表示的是矩陣裡的元素,而非代表整個矩陣,當年在這個上面繞了好久。。
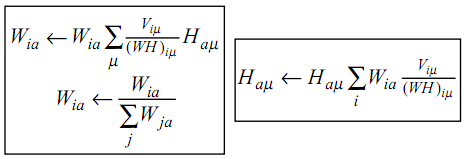
相比於PCA、LDA,NMF有個明顯的好處就是它的非負,因為為在很多情況下帶有負號的運算算起來都不這麼方便,但是它也有一個問題就是NMF分解出來的結果不像PCA和LDA一樣是恆定的。
6. Gaussian Mixture Model
GMM高斯混合模型粗看上去跟上文所提的貝葉斯分類器有點類似,但兩者的方法有很大的不同。在貝葉斯分類器中,我們已經事先知道了訓練資料(training set)的分類資訊,因此只要根據對應的均值和協方差矩陣擬合一個高斯分佈即可。而在GMM中,我們除了資料的資訊,對資料的分類一無所知,因此,在運算時我們不僅需要估算每個資料的分類,還要估算這些估算後資料分類的均值和協方差矩陣。。。也就是說如果有1000個訓練資料10租分類的話,需要求的未知數是1000+10+10(用未知數表示未必確切,確切的說是1000個1x10標誌向量,10個與訓練資料同維的平均向量,10個與訓練資料同維的方陣)。。。反正想想都是很頭大的事情。。。那麼這個問題是怎麼解決的呢?
這裡用的是一種叫EM迭代的方法。
當然 Matlab裡一般也會自帶GMM工具箱,其用法可以參考下面連結:
LDA:
LDA的全稱是Linear Discriminant Analysis(線性判別分析),是一種supervised learning。有些資料上也稱為是Fisher’s Linear Discriminant,因為它被Ronald Fisher發明自1936年,Discriminant這次詞我個人的理解是,一個模型,不需要去通過概率的方法來訓練、預測資料,比如說各種貝葉斯方法,就需要獲取資料的先驗、後驗概率等等。LDA是在目前機器學習、資料探勘領域經典且熱門的一個演算法,據我所知,百度的商務搜尋部裡面就用了不少這方面的演算法。
LDA的原理是,將帶上標籤的資料(點),通過投影的方法,投影到維度更低的空間中,使得投影后的點,會形成按類別區分,一簇一簇的情況,相同類別的點,將會在投影后的空間中更接近。要說明白LDA,首先得弄明白線性分類器(Linear Classifier):因為LDA是一種線性分類器。對於K-分類的一個分類問題,會有K個線性函式:
![]()
當滿足條件:對於所有的j,都有Yk > Yj,的時候,我們就說x屬於類別k。對於每一個分類,都有一個公式去算一個分值,在所有的公式得到的分值中,找一個最大的,就是所屬的分類了。
上式實際上就是一種投影,是將一個高維的點投影到一條高維的直線上,LDA最求的目標是,給出一個標註了類別的資料集,投影到了一條直線之後,能夠使得點儘量的按類別區分開,當k=2即二分類問題的時候,如下圖所示:

紅色的方形的點為0類的原始點、藍色的方形點為1類的原始點,經過原點的那條線就是投影的直線,從圖上可以清楚的看到,紅色的點和藍色的點被原點明顯的分開了,這個資料只是隨便畫的,如果在高維的情況下,看起來會更好一點。下面我來推導一下二分類LDA問題的公式:
假設用來區分二分類的直線(投影函式)為:
![]()
LDA分類的一個目標是使得不同類別之間的距離越遠越好,同一類別之中的距離越近越好,所以我們需要定義幾個關鍵的值。
類別i的原始中心點為:(Di表示屬於類別i的點)
類別i投影后的中心點為:
![]()
衡量類別i投影后,類別點之間的分散程度(方差)為:

最終我們可以得到一個下面的公式,表示LDA投影到w後的損失函式:

我們分類的目標是,使得類別內的點距離越近越好(集中),類別間的點越遠越好。分母表示每一個類別內的方差之和,方差越大表示一個類別內的點越分散,分子為兩個類別各自的中心點的距離的平方,我們最大化J(w)就可以求出最優的w了。想要求出最優的w,可以使用拉格朗日乘子法,但是現在我們得到的J(w)裡面,w是不能被單獨提出來的,我們就得想辦法將w單獨提出來。
我們定義一個投影前的各類別分散程度的矩陣,這個矩陣看起來有一點麻煩,其實意思是,如果某一個分類的輸入點集Di裡面的點距離這個分類的中心店mi越近,則Si裡面元素的值就越小,如果分類的點都緊緊地圍繞著mi,則Si裡面的元素值越更接近0.

帶入Si,將J(w)分母化為:

![]()
同樣的將J(w)分子化為:
![]()
這樣損失函式可以化成下面的形式:

這樣就可以用最喜歡的拉格朗日乘子法了,但是還有一個問題,如果分子、分母是都可以取任意值的,那就會使得有無窮解,我們將分母限制為長度為1(這是用拉格朗日乘子法一個很重要的技巧,在下面將說的PCA裡面也會用到,如果忘記了,請複習一下高數),並作為拉格朗日乘子法的限制條件,帶入得到:

這樣的式子就是一個求特徵值的問題了。
對於N(N>2)分類的問題,我就直接寫出下面的結論了:

這同樣是一個求特徵值的問題,我們求出的第i大的特徵向量,就是對應的Wi了。
這裡想多談談特徵值,特徵值在純數學、量子力學、固體力學、計算機等等領域都有廣泛的應用,特徵值表示的是矩陣的性質,當我們取到矩陣的前N個最大的特徵值的時候,我們可以說提取到的矩陣主要的成分(這個和之後的PCA相關,但是不是完全一樣的概念)。在機器學習領域,不少的地方都要用到特徵值的計算,比如說影象識別、pagerank、LDA、還有之後將會提到的PCA等等。
下圖是影象識別中廣泛用到的特徵臉(eigen face),提取出特徵臉有兩個目的,首先是為了壓縮資料,對於一張圖片,只需要儲存其最重要的部分就是了,然後是為了使得程式更容易處理,在提取主要特徵的時候,很多的噪聲都被過濾掉了。跟下面將談到的PCA的作用非常相關。

特徵值的求法有很多,求一個D * D的矩陣的時間複雜度是O(D^3), 也有一些求Top M的方法,比如說power method,它的時間複雜度是O(D^2 * M), 總體來說,求特徵值是一個很費時間的操作,如果是單機環境下,是很侷限的。
PCA:
主成分分析(PCA)與LDA有著非常近似的意思,LDA的輸入資料是帶標籤的,而PCA的輸入資料是不帶標籤的,所以PCA是一種unsupervised learning。LDA通常來說是作為一個獨立的演算法存在,給定了訓練資料後,將會得到一系列的判別函式(discriminate function),之後對於新的輸入,就可以進行預測了。而PCA更像是一個預處理的方法,它可以將原本的資料降低維度,而使得降低了維度的資料之間的方差最大(也可以說投影誤差最小,具體在之後的推導裡面會談到)。
方差這個東西是個很有趣的,有些時候我們會考慮減少方差(比如說訓練模型的時候,我們會考慮到方差-偏差的均衡),有的時候我們會盡量的增大方差。方差就像是一種信仰(強哥的話),不一定會有很嚴密的證明,從實踐來說,通過儘量增大投影方差的PCA演算法,確實可以提高我們的演算法質量。
說了這麼多,推推公式可以幫助我們理解。我下面將用兩種思路來推匯出一個同樣的表示式。首先是最大化投影后的方差,其次是最小化投影后的損失(投影產生的損失最小)。
最大化方差法:
假設我們還是將一個空間中的點投影到一個向量中去。首先,給出原空間的中心點:
 假設u1為投影向量,投影之後的方差為:
假設u1為投影向量,投影之後的方差為:
 上面這個式子如果看懂了之前推導LDA的過程,應該比較容易理解,如果線性代數裡面的內容忘記了,可以再溫習一下,優化上式等號右邊的內容,還是用拉格朗日乘子法:
上面這個式子如果看懂了之前推導LDA的過程,應該比較容易理解,如果線性代數裡面的內容忘記了,可以再溫習一下,優化上式等號右邊的內容,還是用拉格朗日乘子法:
![]() 將上式求導,使之為0,得到:
將上式求導,使之為0,得到:
![]() 這是一個標準的特徵值表示式了,λ對應的特徵值,u對應的特徵向量。上式的左邊取得最大值的條件就是λ1最大,也就是取得最大的特徵值的時候。假設我們是要將一個D維的資料空間投影到M維的資料空間中(M < D), 那我們取前M個特徵向量構成的投影矩陣就是能夠使得方差最大的矩陣了。
這是一個標準的特徵值表示式了,λ對應的特徵值,u對應的特徵向量。上式的左邊取得最大值的條件就是λ1最大,也就是取得最大的特徵值的時候。假設我們是要將一個D維的資料空間投影到M維的資料空間中(M < D), 那我們取前M個特徵向量構成的投影矩陣就是能夠使得方差最大的矩陣了。
最小化損失法:
假設輸入資料x是在D維空間中的點,那麼,我們可以用D個正交的D維向量去完全的表示這個空間(這個空間中所有的向量都可以用這D個向量的線性組合得到)。在D維空間中,有無窮多種可能找這D個正交的D維向量,哪個組合是最合適的呢?
假設我們已經找到了這D個向量,可以得到:
 我們可以用近似法來表示投影后的點:
我們可以用近似法來表示投影后的點:
 上式表示,得到的新的x是由前M 個基的線性組合加上後D - M個基的線性組合,注意這裡的z是對於每個x都不同的,而b對於每個x是相同的,這樣我們就可以用M個數來表示空間中的一個點,也就是使得資料降維了。但是這樣降維後的資料,必然會產生一些扭曲,我們用J描述這種扭曲,我們的目標是,使得J最小:
上式表示,得到的新的x是由前M 個基的線性組合加上後D - M個基的線性組合,注意這裡的z是對於每個x都不同的,而b對於每個x是相同的,這樣我們就可以用M個數來表示空間中的一個點,也就是使得資料降維了。但是這樣降維後的資料,必然會產生一些扭曲,我們用J描述這種扭曲,我們的目標是,使得J最小:
 上式的意思很直觀,就是對於每一個點,將降維後的點與原始的點之間的距離的平方和加起來,求平均值,我們就要使得這個平均值最小。我們令:
上式的意思很直觀,就是對於每一個點,將降維後的點與原始的點之間的距離的平方和加起來,求平均值,我們就要使得這個平均值最小。我們令:
 將上面得到的z與b帶入降維的表示式:
將上面得到的z與b帶入降維的表示式:
 將上式帶入J的表示式得到:
將上式帶入J的表示式得到:
 再用上拉普拉斯乘子法(此處略),可以得到,取得我們想要的投影基的表示式為:
再用上拉普拉斯乘子法(此處略),可以得到,取得我們想要的投影基的表示式為:
![]() 這裡又是一個特徵值的表示式,我們想要的前M個向量其實就是這裡最大的M個特徵值所對應的特徵向量。證明這個還可以看看,我們J可以化為:
這裡又是一個特徵值的表示式,我們想要的前M個向量其實就是這裡最大的M個特徵值所對應的特徵向量。證明這個還可以看看,我們J可以化為:
 也就是當誤差J是由最小的D - M個特徵值組成的時候,J取得最小值。跟上面的意思相同。
也就是當誤差J是由最小的D - M個特徵值組成的時候,J取得最小值。跟上面的意思相同。
下圖是PCA的投影的一個表示,黑色的點是原始的點,帶箭頭的虛線是投影的向量,Pc1表示特徵值最大的特徵向量,pc2表示特徵值次大的特徵向量,兩者是彼此正交的,因為這原本是一個2維的空間,所以最多有兩個投影的向量,如果空間維度更高,則投影的向量會更多。

總結:
本次主要講了兩種方法,PCA與LDA,兩者的思想和計算方法非常類似,但是一個是作為獨立的演算法存在,另一個更多的用於資料的預處理的工作。另外對於PCA和LDA還有核方法,本次的篇幅比較大了,先不說了,以後有時間再談:
相關推薦
pca 和lda區別
這學期選了門模式識別的課。發現最常見的一種情況就是,書上寫的老師ppt上寫的都看不懂,然後繞了一大圈去自己查資料理解,回頭看看發現,Ah-ha,原來本質的原理那麼簡單,自己一開始只不過被那些看似formidable的細節嚇到了。所以在這裡把自己所學的一些點記錄下來,供
PCA和LDA的對比
分布 inf image 訓練樣本 log 正交 有監督 html 冗余 PCA和LDA都是經典的降維算法。PCA是無監督的,也就是訓練樣本不需要標簽;LDA是有監督的,也就是訓練樣本需要標簽。PCA是去除掉原始數據中冗余的維度,而LDA是尋找一個維度,使得原始數據在該維度
基於PCA和LDA的人臉識別
一、系統設計 1.1研究背景及意義 隨著資訊科技的不斷髮展,人們對方便快捷的身份驗證和識別系統的要求不斷提高。人臉識別技術因具有直接、友好、快捷、方便、易為使用者所接受等特點,成為了身份驗證的最理想依據,也早已成為了模式識別領域研究的熱點。眾多科研人員通過多年潛心研究,也做出了許多的成果,但
PCA和SVD區別和聯絡
前言: PCA(principal component analysis)和SVD(Singular value decomposition)是兩種常用的降維方法,在機器學習等領域有廣泛的應用。本文主要介紹這兩種方法之間的區別和聯絡。 一、PCA
特徵選擇和特徵提取區別 、PCA VS LDA
1.特徵提取 V.S 特徵選擇 特徵提取和特徵選擇是DimensionalityReduction(降維)的兩種方法,針對於the curse of dimensionality(維災難),都可以達到降維的目的。但是這兩個有所不同。 特徵提取(Feature
GET和POST區別總結
get 、post 、區別一、GET和POST區別的普遍看法:HTTP 定義了與服務器交互的不同方法,最常用的有4種,Get、Post、Put、Delete,如果我換一下順序就好記了,Put(增),Delete(刪),Post(改),Get(查),即增刪改查,下面簡單敘述一下:1)Get, 它用於獲取信息,註
JS中const、var和let區別
方法 pre 命令 con 使用 它的 comm 作用 影響 在JavaScript中有三種聲明變量的方式:var、let、const。 1.const 聲明創建一個只讀的常量。這不意味著常量指向的值不可變,而是變量標識符的值只能賦值一次,必須初始化。 const b
equals 和== 的區別
strong 都是 什麽 brush -s 新的 equals方法 實現 繼承 首先 看比較的對象是否為字符串,若為(String)字符串用equals 比較, 比較的是他們的值。相同返回 true ,不相同返回false. package one; p
mybatis中的#和$的區別
背景 插入 trac sql註入 -m .com article 參數 -s 1. #將傳入的數據都當成一個字符串,會對自動傳入的數據加一個雙引號。如:order by #user_id#,如果傳入的值是111,那麽解析成sql時的值為order by "111", 如果傳
hibernate中hql語句中list和iterate區別
每次 hibernate 寫入 所有 讀取 條件 iter 查詢 hql 1.使用list()方法獲取查詢結果,每次發出一條語句,獲取全部數據。2.使用iterate()方法獲取查詢結果,先發出一條SQL語句用來查詢滿足條件數據的id,然後依次按照這些id查詢記錄,也就是要
java中ArrayList和LinkedList區別
插入 list 新的 查找 arr tro 基於 列表 時間復雜度 ArrayList和LinkedList最主要的區別是基於不同數據結構 ArrayList是基於動態數組的數據結構,LinkedList基於鏈表的數據結構,針對這點,從時間復雜度和空間復雜度來看主要區別:
mysql中replicate_wild_do_table和replicate_do_db區別
lan rep cati mil 多人 pan think lte 避免 使用replicate_do_db和replicate_ignore_db時有一個隱患,跨庫更新時會出錯。 如在Master(主)服務器上設置 replicate_do_db=test(my.conf
2000行之宏中#和##的區別
ret fun color bsp nbsp urn div def include #include<stdio.h> #define Fun(a,b) a##b int main() { x=‘H‘; y=‘W‘; printf("
HTML提交方式post和get區別(實驗)
des url action 通過 性別 清除數據 map pass pack HTML提交方式post和get區別(實驗) 一、post和get區別 get提交,提交的信息都顯示在地址欄中。 post提交,提交的信息不顯示地址欄中,顯示在消息體中。 二、客戶端代碼
stringbuffer 和 stringbuilder區別
uil build 線程 區別 單線程 線程安全 多線程操作 buffer 少量數據 stringbuffer 和 stringbuilder速度 小於 線程安全 線程非安全 單線程操作
水晶頭鍍金30U和50區別
style 價格 -1 font 質量 穩定性 tex 穩定 size U是厚度單位,1μm≈40u。一般來說鍍金越厚,越耐插播,耐酸堿腐蝕,觸點壽命越長,傳輸穩定性越好,價格越貴。但是事實上,鍍金層的質量,或者說鍍金對水晶頭質量的影響,跟工藝的關系更密切。水晶頭鍍金30U
MyBatis Mapper.xml文件中 $和#的區別
優先 註入 sql註入 jdb 防止 自動 || myba 由於 1.優先使用#{paramName,jdbcType=VARCHAR} 寫法,除了可以防止sql註入以外,它還能在參數裏含有單引號的時候自動轉義, 而${paramName}由於是類似於拼接sql的寫法,不具
require(),include(),require_once()和include_once()區別
流程 code 一個 str 定義 檔案 目標 失敗 錯誤處理 require 的使用方法如 require("MyRequireFile.php"); 。這個函數通常放在 PHP 程序的最前面,PHP 程序在執行前,就會先讀入 require 所指定引入的文件,使它變成
Zepto和Jquery區別
-- error exce cal lba 滑動 set 忽略 瀏覽器 ---恢復內容開始--- 《zepto移動端事件》 1、$("#xx").tap(function(){ //tap在屏幕點擊時觸發 alert("sssss"); }) 2、$("d
Antelope 和Barracuda區別
iter strong 大小 實驗 時也 uda cuda int innodb Antelope和Barracuda均為innodb存儲引擎的文件格式,Antelope為默認格式,非壓縮;Barracuda為壓縮格式;兩者主要的不同在於對大數據量的存儲時所占用的空間差異