
02.SQLServer效能優化之---水平分庫擴充套件
上次共享的第一份大資料,這次正好來演示一下水平分庫
1.模擬部分資料
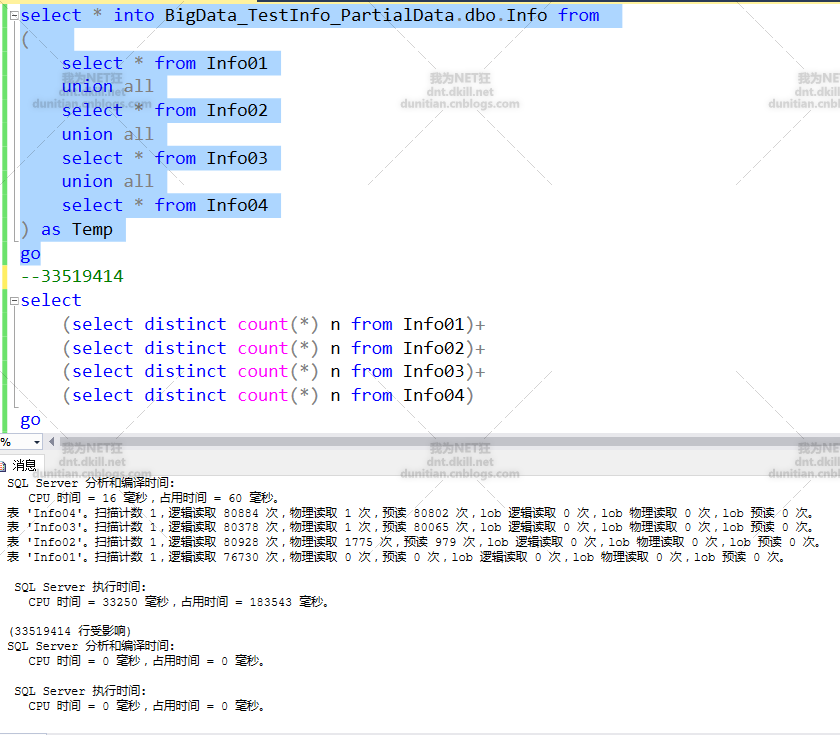
2.建立索引後,發現可以根據日期來分組
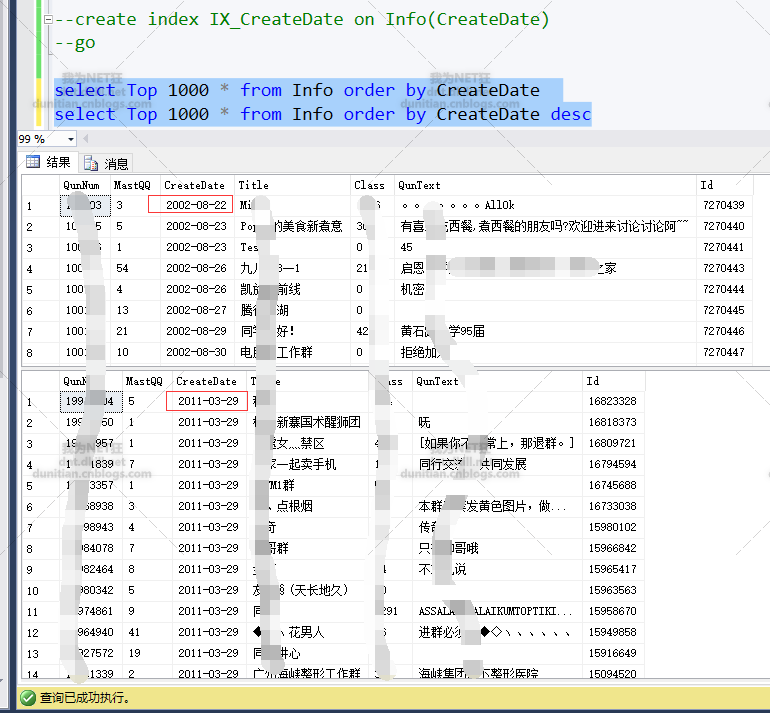
按資料量大致分一下
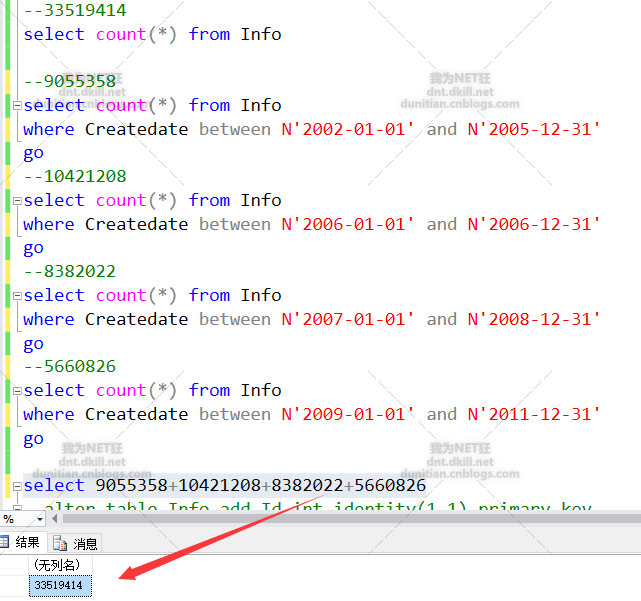
步入正軌
---------------------------------------------------------------------
GUI方法:
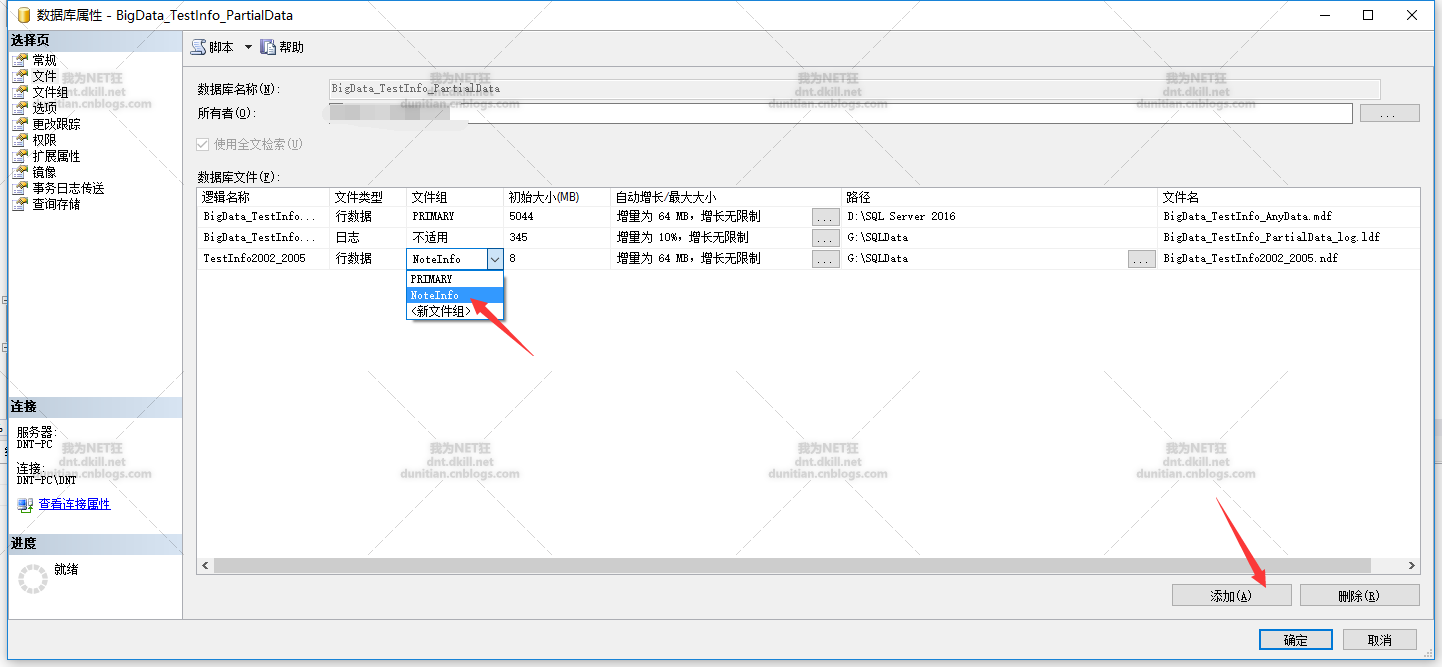
3.0建立檔案組

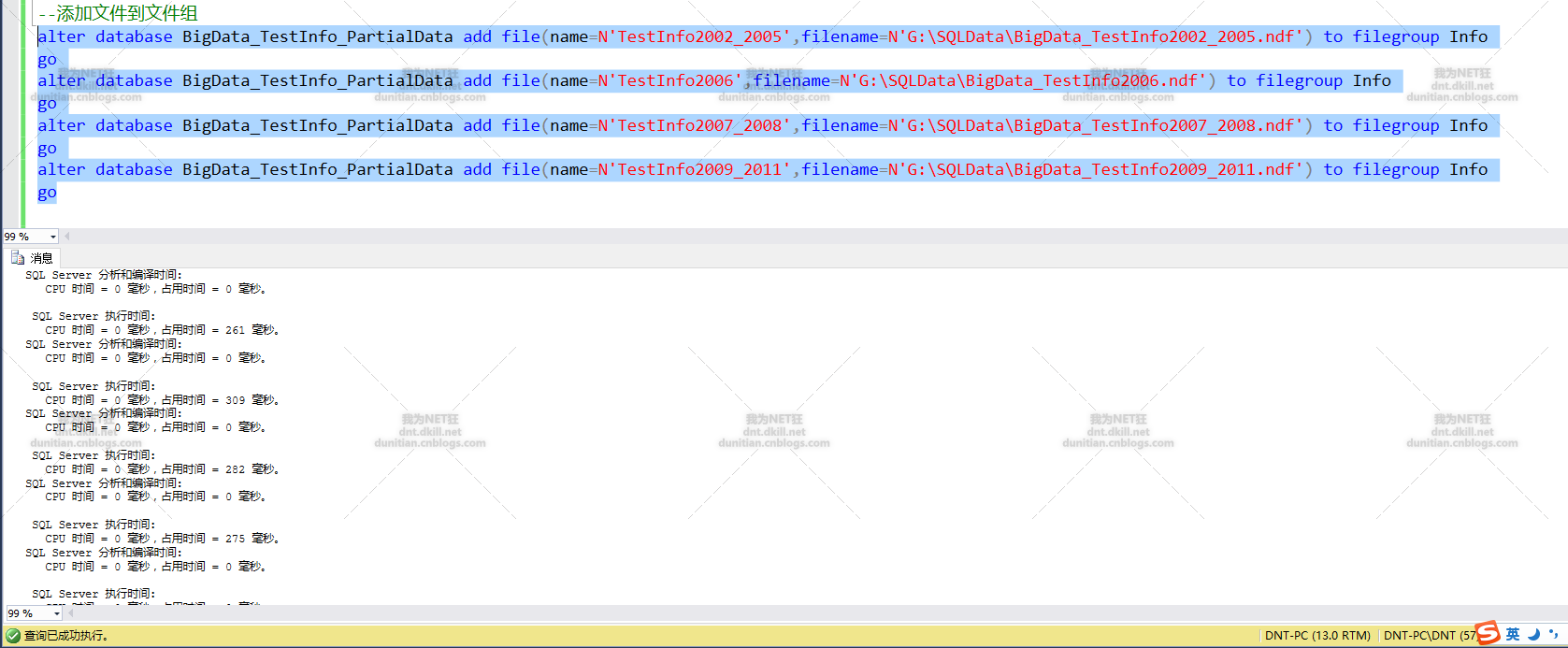
新增檔案到檔案組
命令操作:
alter database BigData_TestInfo_PartialData add filegroup Info
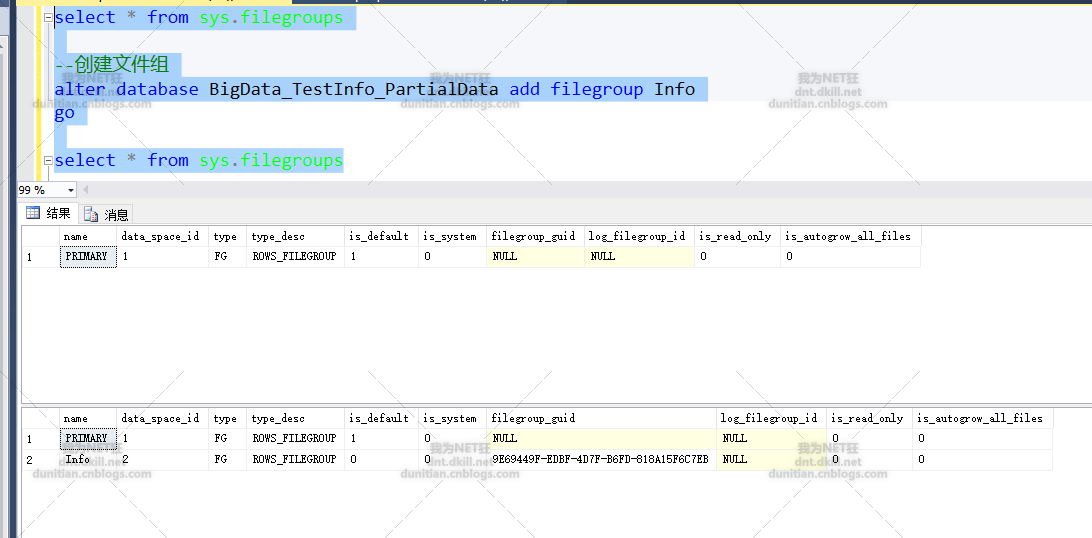
alter database BigData_TestInfo_PartialData add file(name=N'TestInfo2006',filename=N'G:\SQLData\BigData_TestInfo2006.ndf') to filegroup Info
注意:BigData_TestInfo2006.ndf是資料庫自己建立的,不需要自己手動建立(有些同志手動建立了,然後報錯。。。。呃,有點哭笑不得了)
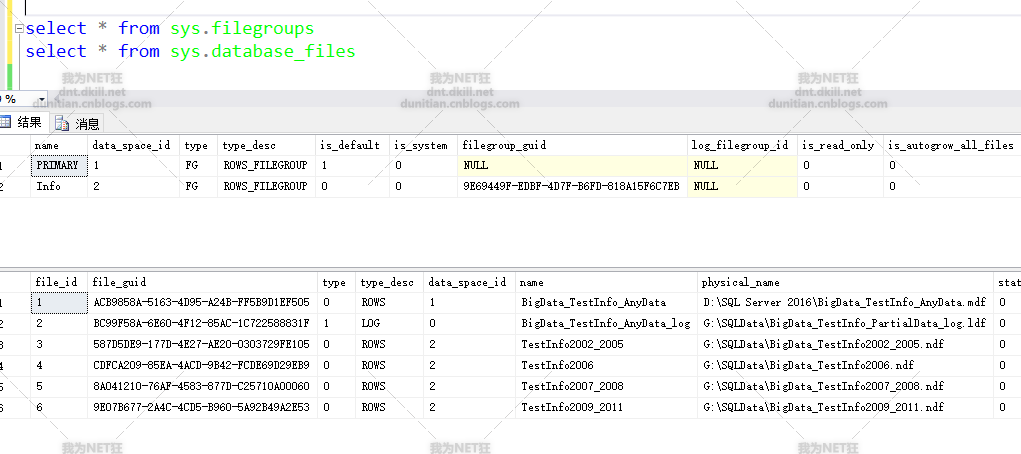
查詢看看:select * from sys.filegroups
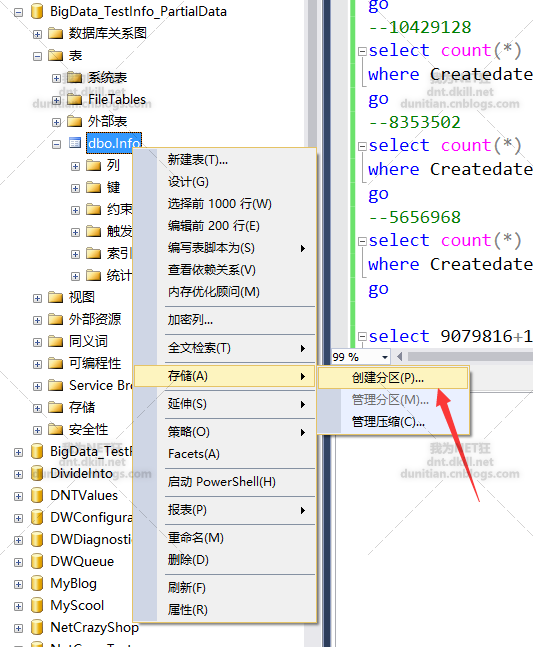
水平分割槽走起:一般就幾步,1.建立分割槽函式 2.建立分割槽方案 3.建立分割槽表
GUI方法
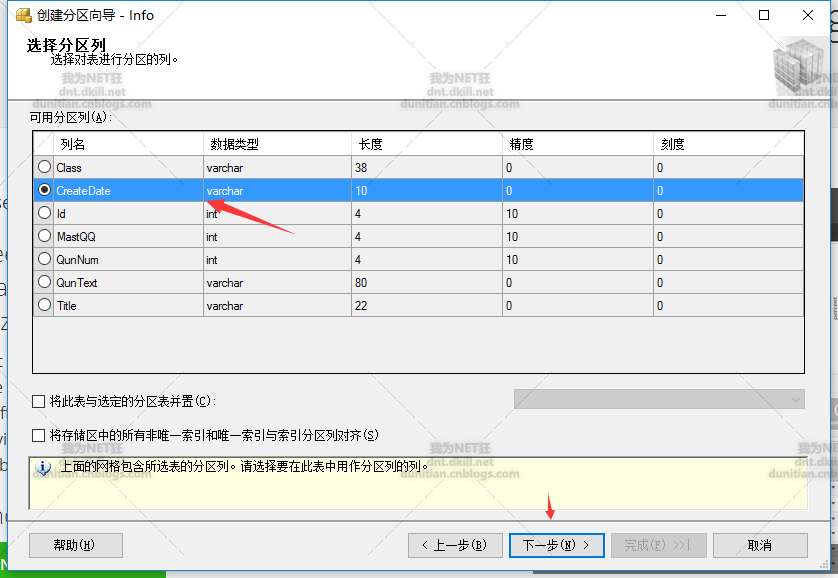
分割槽函式
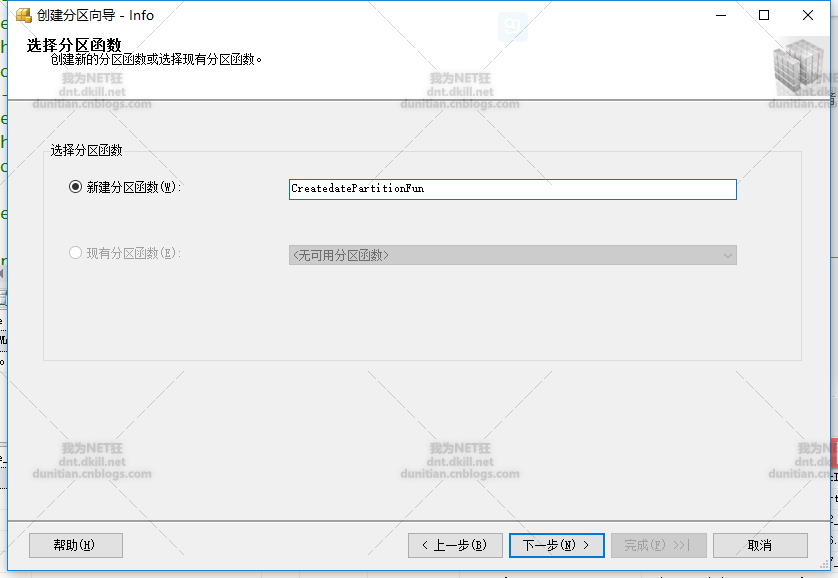
分割槽方案
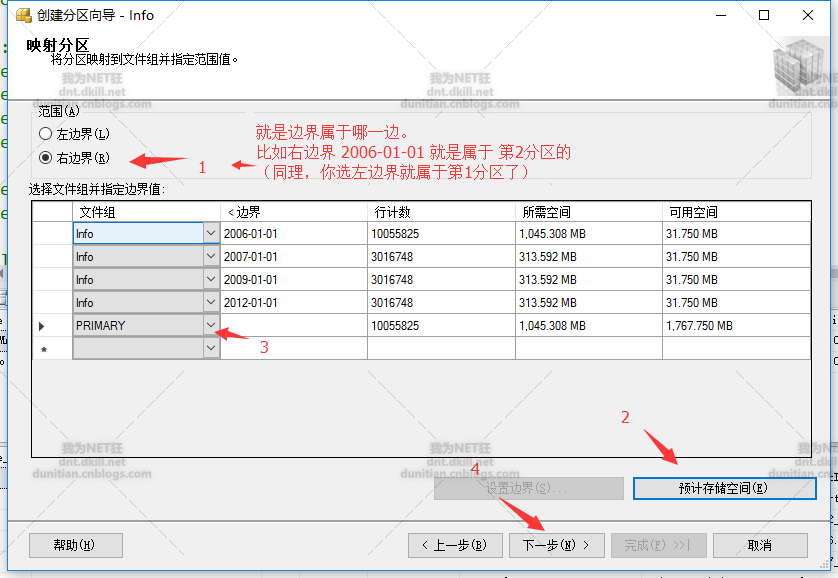
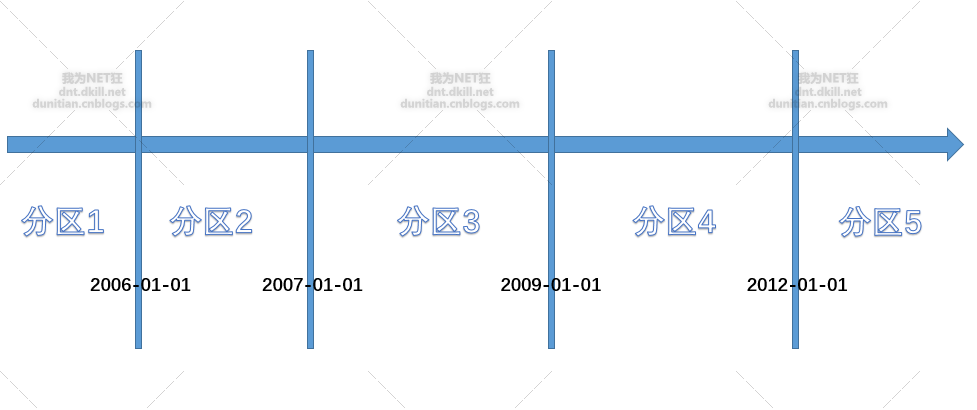
上一張圖有些人可能不懂,用PPT畫張概念圖:
建立指令碼
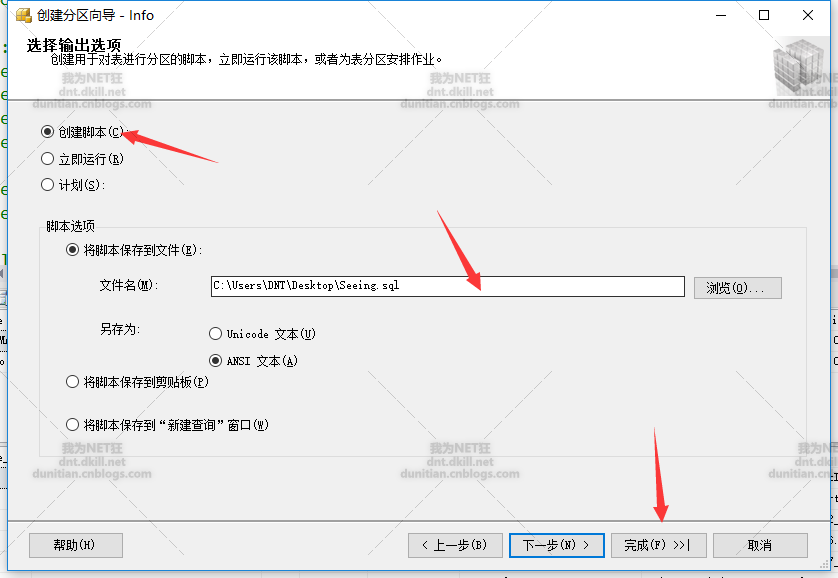
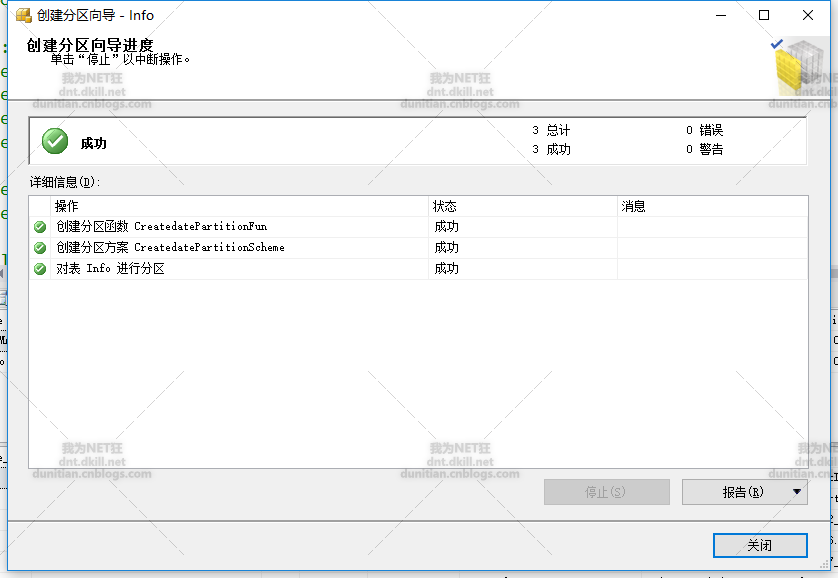
系統生成指令碼:
use [BigData_TestInfo_PartialData] go begin transaction create partition function [CreatedatePartitionFun](varchar(10)) as range right for values(N'2006-01-01', N'2007-01-01', N'2009-01-01', N'2012-01-01') create partition scheme [CreatedatePartitionScheme] as partition [CreatedatePartitionFun] TO ([Info], [Info], [Info], [Info], [primary]) alter table [dbo].[Info] drop constraint [PK__Info__3214EC07B2FE10C8] alter table [dbo].[Info] add primary key nonclustered ( [Id] asc )with (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] set ansi_padding on create clustered index [ClusteredIndex_on_CreatedatePartitionScheme_636193166313125124] on [dbo].[Info] ( [CreateDate] )with (SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF) ON [CreatedatePartitionScheme]([CreateDate]) drop index [ClusteredIndex_on_CreatedatePartitionScheme_636193166313125124] on [dbo].[Info] commit transaction go
命令方式建立(根據上面生成的命令逆推)
建立分割槽函式和架構(方案)
create partition function CreatedatePartitionFun(varchar(10)) as range right for values(N'2006-01-01', N'2007-01-01', N'2009-01-01', N'2012-01-01')

create partition scheme CreatedatePartitionScheme as partition [CreatedatePartitionFun] TO ([Info], [Info], [Info], [Info], [primary])
建立分割槽表
尚未建立表的情況

已經建立了表(基本上都是這種情況)
主要就兩步,把主鍵變為非聚集索引+建立分割槽聚集索引
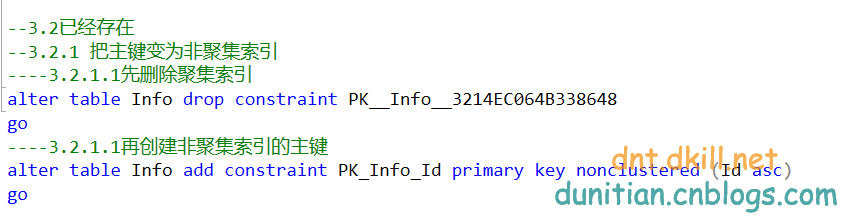
alter table Info drop constraint PK__Info__3214EC064B338648
alter table Info add constraint PK_Info_Id primary key nonclustered (Id asc)
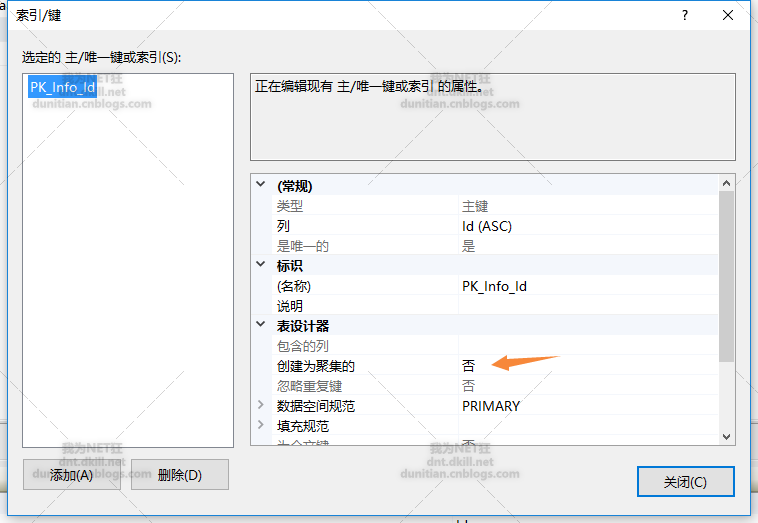

create clustered index IX_Info_CreateDate on Info(CreateDate) on CreatedatePartitionScheme(CreateDate)
測試:基本上是均勻分散在各個檔案中,生產環境的時候可以把這些檔案放各個磁碟

參考文章:
相關推薦
02.SQLServer效能優化之---水平分庫擴充套件
上次共享的第一份大資料,這次正好來演示一下水平分庫 1.模擬部分資料 2.建立索引後,發現可以根據日期來分組 按資料量大致分一下 步入正軌 ------------------------------------------------------------------
06.SQLServer效能優化之---資料庫級日記監控
不清楚的最好看一下,一會要用到。 常規的效能監視有多種,對於我們這些不是DBA的人來說基本上夠用了 第一個是整體的一個監視器 第二個是Profiler,這個挺好的,一般我們都是開發的時候用。真在生產環境下監視就太浪費伺服器效能了(小專案無所謂) 換環境了,以後繼續更
03.SQLServer效能優化之---儲存優化系列
以下內容皆為個人摸索,沒有人專門指導(公司不給力啊!DBA和大牛都木有。。。),所以難免出錯,如有錯誤歡迎指正,小子勇於接受批評~(*^__^*) ~ 水平分庫分表和垂直分庫分表,大家都經常談,我說下我的理解,看圖: 垂直分表就不用說了,基本上會SQLServer的都會。 垂直分庫就是根
01.SQLServer效能優化之----強大的檔案組----分盤儲存
declare @i int=1 while(@i<10) begin set @i=@i+1 insert into Test(DataStatus) values(1),(2),(1),(2),(1),(2),(1),(2),(1),(2),(1),(2),(1),(2)
SQLServer效能優化之---資料庫級日記監控
上節回顧:https://www.cnblogs.com/dotnetcrazy/p/11029323.html 4.6.6.SQLServer監控 指令碼示意:https://github.com/lotapp/BaseCode/tree/master/database/SQL/SQLServer PS:
MYSQL效能優化之資料庫的分庫分表
資料庫中的資料量不一定是可控的,在未進行分庫分表的情況下,隨著時間和業務的發展,庫中的表會越來越多,表中的資料量也會越來越大,相應地,資料操作,增刪改查的開銷也會越來越大;另外,由於無法進行分散式
菜鳥要做架構師——java效能優化之for迴圈
完成同樣的功能,用不同的程式碼來實現,效能上可能會有比較大的差別,所以對於一些效能敏感的模組來說,對程式碼進行一定的優化還是很有必要的。今天就來說一下java程式碼優化的事情,今天主要聊一下對於for(while等同理)迴圈的優化。 作為三大結構之一的迴圈,在我們編寫程式碼的時候會經常用到。
效能優化之記憶體優化
效能優化之記憶體優化 計算 APP 獲得的最大記憶體分配值 Runtime rt=Runtime.getRuntime(); long maxMemory=rt.maxMemory(); Log.i("maxMemory:",Long.toString(max
Sql Sever效能優化之指定索引
背景:生產環境SQL語句查詢過慢(資料總量在350萬左右),日誌中心一直報警 解決過程:分析無果後,求助於公司的DBA,DBA分析後建議在語句中指定索引 解決:在SQL語句中指定索引,效果相當明顯,親測有效 優化前SQL: SELECT ROW_NUMBER() OVER ( ORDER BY
Android——效能優化之SparseArray
相信大家都用過HashMap用來存放鍵值對,最近在專案中使用HashMap的時候發現,有時候 IDE 會提示我這裡的HashMap可以用SparseArray或者SparseIntArray等等來代替。 SparseArray(稀疏陣列).它是Android內部特有的api,標準的jdk是沒有這
Android效能優化之較精確的獲取影象顯示到螢幕上的時間
轉載自:http://blog.desmondyao.com/android-show-time/ 這兩天我的包工頭歪龍木·靈魂架構師·王半仙·Yrom給我派了一個活:統計App冷啟動時間。這個任務看上去不難,但是要求統計出來的時間要準,要特別準。 意思就是,我必須要按Activity繪製到
KVM總結-KVM效能優化之磁碟IO優化
前面講了KVM CPU(http://blog.csdn.net/dylloveyou/article/details/71169463)、記憶體(http://blog.csdn.net/dylloveyou/article/details/71338378)的優化,下面接著第三塊的內容,KVM磁
MySQL(三) —— MySQL效能優化之 索引優化
MySQL索引優化 如何選擇合適的列建立索引? 在where從句、group by 從句、order by 從句、on 從句中出現的列 索引欄位越小越好 離散度大的列放在聯合索引的前面 如何判斷列的離散度? 去重查詢看列的唯一值,唯一值越多則離散度越大。 mysql&
MySQL(二) —— MySQL效能優化之 SQL語句優化
SQL語句優化 MySQL優化的目的 1、避免出現頁面訪問錯誤:或由於資料庫連線超時 timeout 產生頁面5xx錯誤;或由於慢查詢造成頁面無法載入;或由於阻 塞造成資料無法提交;
精讀《手寫 SQL 編譯器 - 效能優化之快取》
1 引言 重回 “手寫 SQL 編輯器” 系列。這次介紹如何利用快取優化編譯器執行效能。 可以利用 Frist 集 與 Match 節點快取 這兩種方式優化。 本文會用到一些圖做解釋,下面介紹圖形規則: First 集優化,是指在初始化時,將整體文法的 First 集找到,因此在節點
【MySQL資料庫】效能優化之索引及優化(一)
一、Mysql效能優化之影響效能的因素 1.商業需求的影響 不合理的需求造成的資源投入產出,這裡就用一個看上去很簡單的功能分析。需求:一個論壇帖子的總量統計,附加要求:實時更新。從功能上看來是非常容易實現的,執行一條select count(*)from表名就可以得到結果,但是如果我們採
百萬併發下的 Nginx 效能優化之道,值得看!!!
Nginx 很火,火到無論是創業公司,還是 BAT 等一線網際網路公司,都會使用Nginx。因為它就像一個萬能藥,在任何存在效能需求的場合總能找見它的身影。它可以輕鬆在百萬併發連線下實現高吞吐量的 Web 服務,同時諸多應用場景下的問題都可以通過種種 Nginx 模組得以解決,而我們所需的工
網站效能優化之雪碧圖製作
雪碧圖製作及使用 製作目的:由於網站上有需要小的icon且每次載入的時候都會有許多類似的請求,影響了網站的效能。所以將小圖示合併成一張雪碧圖,從而減少圖片的請求數,優化網站效能。 製作方法: 1、刀耕火種法 利用photoshop把一張張小圖合成一張雪碧圖(工作效率太低不建議使
效能優化之載入
效能優化之載入 一、預載入 原理:預載入即提前載入,就是為了讓需要載入的內容在觸發載入之前載入好,觸發載入時只是簡單的展示,這樣會使使用者操作起來更加流暢。但缺點是增加了首次請求的請求數; 使用場景:如選單背景圖切換時提前載入背景圖,減少切換時出現短暫空白現象; 使用方法:預