
SPSS聚類分析——一個案例演示聚類分析全過程

案例資料來源:
有20種12盎司啤酒成分和價格的資料,變數包括啤酒名稱、熱量、鈉含量、酒精含量、價格。資料來自《SPSS for Windows 統計分析》data11-03。點選下載
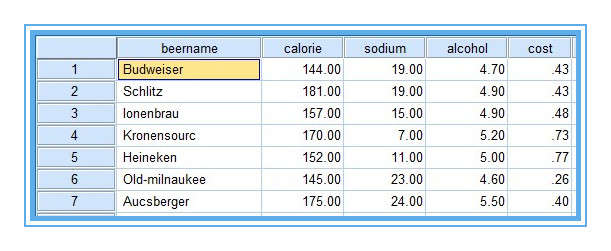
【一】問題一:選擇那些變數進行聚類?——採用“R型聚類”
1、現在我們有4個變數用來對啤酒分類,是否有必要將4個變數都納入作為分類變數呢?熱量、鈉含量、酒精含量這3個指標是要通過化驗員的辛苦努力來測定,而且還有花費不少成本,如果都納入分析的話,豈不太麻煩太浪費?所以,有必要對4個變數進行降維處理,這裡採用spss R型聚類(變數聚類),對4個變數進行降維處理。輸出“相似性矩陣”有助於我們理解降維的過程。
2、4個分類變數量綱各自不同,這一次我們先確定用相似性來測度,度量標準選用pearson係數,聚類方法選最遠元素,此時,涉及到相關,4個變數可不用標準化處理,將來的相似性矩陣裡的數字為相關係數。若果有某兩個變數的相關係數接近1或-1,說明兩個變數可互相替代。
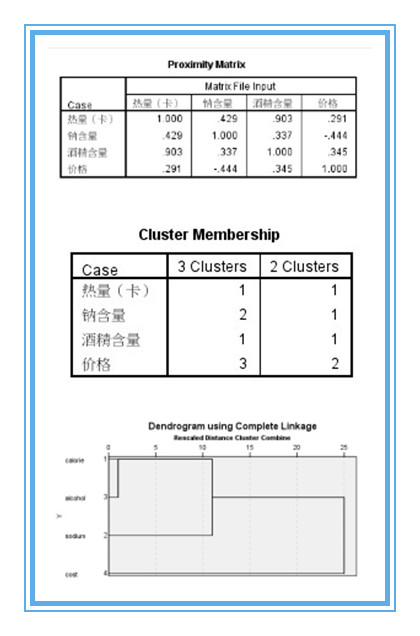
3、只輸出“樹狀圖”就可以了,個人覺得冰柱圖很複雜,看起來沒有樹狀圖清晰明瞭。從proximity matrix表中可以看出熱量和酒精含量兩個變數相關係數0.903,最大,二者選其一即可,沒有必要都作為聚類變數,導致成本增加。至於熱量和酒精含量選擇哪一個作為典型指標來代替原來的兩個變數,可以根據專業知識或測定的難易程度決定。(與因子分析不同,是完全踢掉其中一個變數以達到降維的目的。)這裡選用酒精含量,至此,確定出用於聚類的變數為:酒精含量,鈉含量,價格。
【二】問題二:20中啤酒能分為幾類?——採用“Q型聚類”
1、現在開始對20中啤酒進行聚類。開始不確定應該分為幾類,暫時用一個3-5類範圍來試探。Q型聚類要求量綱相同,所以我們需要對資料標準化,這一回用歐式距離平方進行測度。
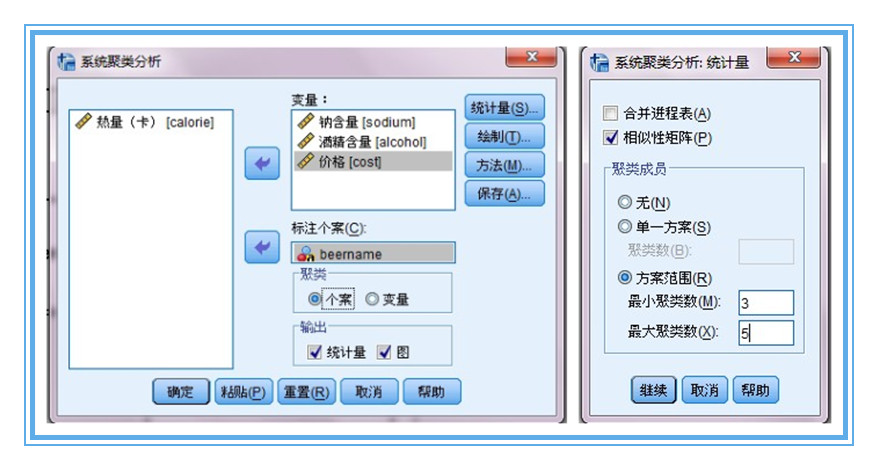
2、主要通過樹狀圖和冰柱圖來理解類別。最終是分為4類還是3類,這是個複雜的過程,需要專業知識和最初的目的來識別。我這裡試著確定分為4類。選擇“儲存”,則在資料區域內會自動生成聚類結果。
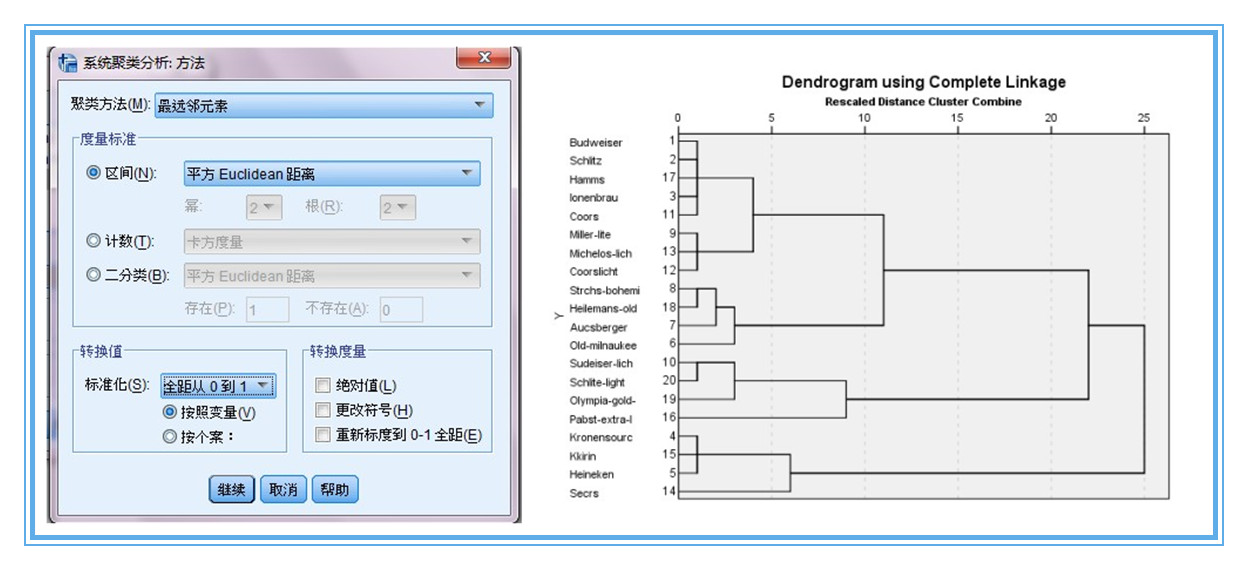
【三】問題三:用於聚類的變數對聚類過程、結果又貢獻麼,有用麼?——採用“單因素方差分析”
1、聚類分析除了對類別的確定需討論外,還有一個比較關鍵的問題就是分類變數到底對聚類有沒有作用有沒有貢獻,如果有個別變量對分類沒有作用的話,應該剔除。
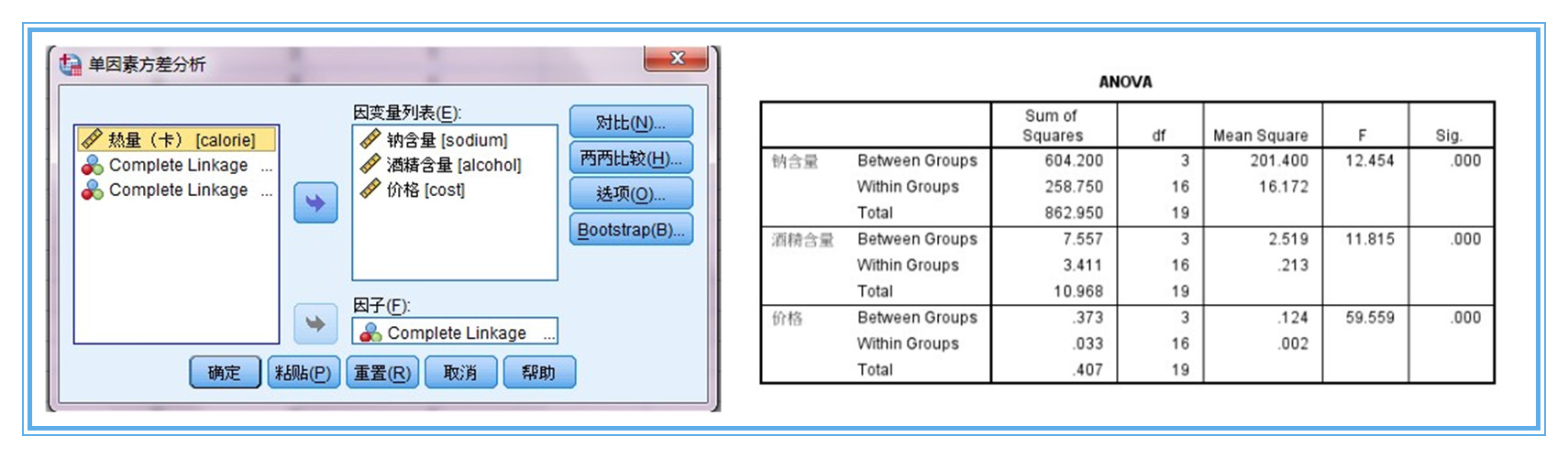
2、這個過程一般用單因素方差分析來判斷。注意此時,因子變數選擇聚為4類的結果,而將三個聚類變數作為因變數處理。方差分析結果顯示,三個聚類變數sig值均極顯著,我們用於分類的3個變數對分類有作用,可以使用,作為聚類變數是比較合理的。
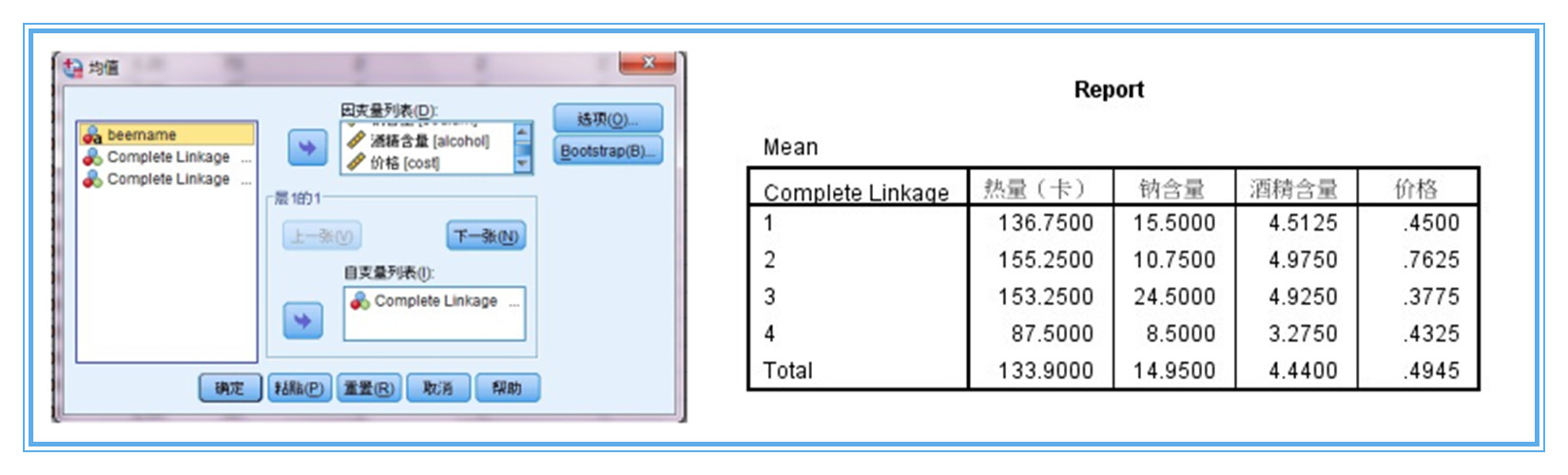
【四】問題四:聚類結果的解釋?——採用”均值比較描述統計“
1、聚類分析最後一步,也是最為困難的就是對分出的各類進行定義解釋,描述各類的特徵,即各類別特徵描述。這需要專業知識作為基礎並結合分析目的才能得出。
2、我們可以採用spss的means均值比較過程,或者excel的透視表功能對各類的各個指標進行描述。其中,report報表用於描述聚類結果。對各類指標的比較來初步定義類別,主要根據專業知識來判定。這裡到此為止。
以上過程涉及到spss層次聚類中的Q型聚類和R型聚類,單因素方差分析,means過程等,是一個很不錯的多種分析方法聯合使用的案例。資料來源和部分介紹均摘自《SPSS for Windows 統計分析》書中。
相關推薦
SPSS聚類分析——一個案例演示聚類分析全過程
案例資料來源: 有20種12盎司啤酒成分和價格的資料,變數包括啤酒名稱、熱量、鈉含量、酒精含量、價格。資料來自《SPSS for Windows 統計分析》data11-03。點選下載 【一】問題一:選擇那些變數進行聚類?——採用“R型聚類” 1、現在我們有4個變數用來對啤酒分類,是否有必要
SPSS聚類分析——一個案例演示聚類分…
本文實際為2010年5月8日完成併發布的,瀏覽量:7199,評論數:5。 案例資料來源: 有20種12盎司啤酒成分和價格的資料,變數包括啤酒名稱、熱量、鈉含量、酒精含量、價格。資料來自《SPSS for Windows 統計分析》data11-03。點選下載 【一】問題一:選擇那些變數進行聚類?——
Java多執行緒程式設計-(9)-ThreadLocal造成OOM記憶體溢位案例演示與原理分析
原文出自 : https://blog.csdn.net/xlgen157387/article/details/78298840 案例程式碼 1、首先看一下程式碼,模擬了一個執行緒數為500的執行緒池,所有執行緒共享一個ThreadLocal變數,每一個執行緒執
第四關:pandas分析實際案例-藥店銷售資料分析
import pandas as pd import numpy as np #讀取資料 filename='E:\sale.xlsx' xls=pd.ExcelFile(filename,dtype="object") salesdf=xls.parse('
K-means聚類分析-互動式GUI演示(Matlab)
K-means聚類分析-互動式GUI演示(Matlab) 學習K-means的時候總是想,這應該是一個很酷的演算法,那麼酷的演算法,就應該有比較酷的demo來演示它,於是我寫了這個程式就是為了能裝逼,哦不,可以更直觀的和K-means演算法進行互動。原創程式,希望大家可以喜歡,
一篇文章透徹解讀聚類分析及案例實操
1 聚類分析介紹 1.1 基本概念 聚類就是一種尋找資料之間一種內在結構的技術。聚類把全體資料例項組織成一些相似組,而這些相似組被稱作聚類。處於相同聚類中的資料例項彼此相同,處於不同聚類中的例項彼此不同。聚類技術通常又被稱為無監督學習,因為與監督學習不同,在聚類中那
K-means聚類演算法原理分析與實際應用案例分析(案例分析另起一篇部落格)
引言 在資料分析中,我們常常想將看上去相似或者行為形似的資料聚合在一起。例如,對一個營銷組織來說,將不同客戶根據他們的特點進行分組,從而有針對性地定製營銷活動,這很重要。又比如,對學校老師來說,將學生分組同樣能夠有所側重的進行教育活動。分類與聚類是資料探勘領域
聚類分析的Matlab 程式—系統聚類(附有案例分析)
聚類分析的Matlab 程式—系統聚類 (1)計算資料集每對元素之間的距離,對應函式為pdistw. 呼叫格式:Y=pdist(X),Y=pdist(X,’metric’), Y=pdist(X,’distfun’),Y=pdist(X,’minkowski’,p) 說
python 聚類分析實戰案例:K-means演算法(原理原始碼)
K-means演算法: 關於步驟:參考之前的部落格 關於程式碼與資料:暫時整理程式碼如下:後期會附上github地址,上傳原始資料與程式碼完整版, 各種聚類演算法的對比:參考連線 Kme
數學模型:3.非監督學習--聚類分析 和K-means聚類
rand tar 聚類分析 復制 clust tle 降維算法 generator pro 1. 聚類分析 聚類分析(cluster analysis)是一組將研究對象分為相對同質的群組(clusters)的統計分析技術 ---->> 將觀測對象的群體按照
python資料分析與挖掘之聚類kmeans演算法
聚類不指定類別進行分類 (劃分(分裂)法,層次分析法、密度分析法)、網格法、模型法 Kmeans演算法屬於分裂法 隨機選擇k各點作為聚類中心 計算各個點到這K個點的距離 將對應的點聚到與它最近的這個聚類中心 重新
14 聚類演算法 - 程式碼案例六- 譜聚類(SC)演算法案例
13 聚類演算法 - 譜聚類 需求 使用scikit的相關API建立模擬資料,然後使用譜聚類演算法進行資料聚類操作,並比較演算法在不同引數情況下的聚類效果。 相關API:https://scikit-learn.org/stable/modules/generated/sklearn.cluster.
聚類分析-實現亞洲足球聚類
Description:利用K-Means演算法實現亞洲足球的聚類; 下圖是亞洲15只球隊在2005年-2010年間大型盃賽的戰績: 下圖是0-1規格化後的資料: Analysis: 1.確定K值
聚類分析(K-means 層次聚類和基於密度DBSCAN演算法三種實現方式)
之前也做過聚類,只不過是用經典資料集,這次是拿的實際資料跑的結果,效果還可以,記錄一下實驗過程。 首先: 確保自己資料集是否都完整,不能有空值,最好也不要出現為0的值,會影響聚類的效果。 其次: 想好要用什麼演算法去做,K-means,層次聚類還是基於密
聚類分析之迭代聚類——“K-Means聚類…
魯棒是Robust,英 [rə(ʊ)'bʌst]的音譯,也就是健壯、強壯、堅定、粗野的意思。魯棒性(robustness)就是系統的健壯性。常使用如:演算法的魯棒性。 演算法雜貨鋪轉載學習 演算法雜貨鋪——分類演算法之決策樹(Decision tree) 聚類演算法實踐(一)——層次聚類、K-
Python資料探勘:利用聚類演算法進行航空公司客戶價值分析
無小意丶 個人部落格地址:無小意 知乎主頁:無小意丶 公眾號: 資料路(shuju_lu) 剛剛開始寫部落格,希望能保持關注,會繼續努力。 以資料相關為主,網際網路為輔進行文章釋出。 本文是《Python資料分析與挖掘實戰》一書的實戰部分,在整理分析後的復現。 本篇文
分析學生上網日誌——聚類DBSCAN例項練習
#分析學生開始上網時間和上網時長的模式 #單個學生上網日誌(記錄編號、學生編號、MAC地址、IP地址、開始、停止上網時間、上網時長) #1.建立工程,引入sklearn相關包 import numpy as np import sklearn.cluster as skc from skle
Mahout機器學習平臺之聚類演算法詳細剖析(含例項分析)
第一部分: 學習Mahout必須要知道的資料查詢技能: 學會查官方幫助文件: 解壓用於安裝檔案(mahout-distribution-0.6.tar.gz),找到如下位置,我將該檔案解壓到win7的G盤mahout資料夾下,路徑如下所示: G:\mahout\mahout
python機器學習案例系列教程——k均值聚類、k中心點聚類
上一篇我們學習了層次聚類。層次聚類只是迭代的把最相近的兩個聚類匹配起來。並沒有給出能給出多少的分組。今天我們來研究一個K均值聚類。就是給定分組數目的基礎上再來聚類。即將所有的樣本資料集分成K個組,每個組內儘可能相似,每個組間又儘可能不相似。 k均值聚類和k
python資料分析與挖掘實戰—聚類演算法對比
#-*-coding:utf-8-*- import numpy as np import matplotlib.pyplot as plt from sklearn import datasets