
聚類分析-實現亞洲足球聚類
Description:利用K-Means演算法實現亞洲足球的聚類;
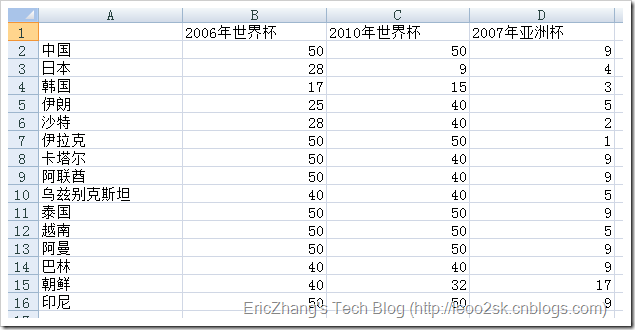
下圖是亞洲15只球隊在2005年-2010年間大型盃賽的戰績:
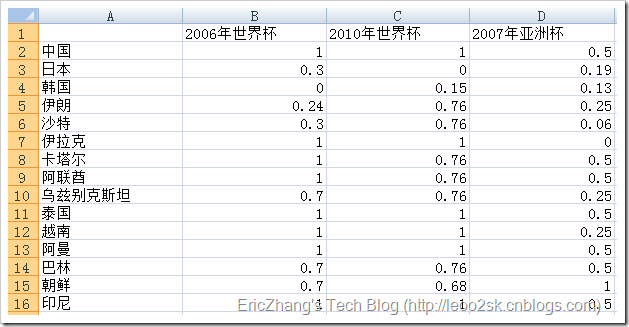
下圖是0-1規格化後的資料:
Analysis:
1.確定K值及K個初始類簇中心點的選取(詳見Blog底部連結)
設 K = 3,即將這15支球隊分成3個集團;
現抽取日本、巴林、泰國的值作為3個簇的種子,即初始化3個簇的中心為A:{0.3, 0, 0.19}、B:{0.7, 0.76, 0.5}、C:{1, 1, 0.5};
2.從左到右依次表示各支球隊到當前中心點的歐氏距離,將每支球隊分到離自己最近的簇,以中國為例:
D(中國,
A) = sqrt( pow( ( 1 - 0.3 ), 2 ), pow( ( 1 - 0 ), 2 ), pow( ( 1 - 0.19 ), 2 ) ) = 1.59 ;
D(中國, B) = 0.15 ;
D(中國, C) = 0 ;
3.根據歐式距離得第一次聚類結果:
A:日本,韓國,伊朗,沙特;
B:烏茲別克,巴林,朝鮮;
C:中國,伊拉克,卡達,阿聯酋,泰國,越南,阿曼,印尼;
4.根據第一次聚類結果,調整各個簇的中心點:
*A簇的新中心點為:
{ ( 0.3 + 0 + 0.24 + 0.3 ) / 4 = 0.21,
( 0 + 0.15 + 0.76 + 0.76 ) / 4 = 0.4175,
( 0.19 + 0.13 + 0.25 + 0.06 ) / 4 = 0.1575 }
中心點(0.21, 0.4175, 0.1575);
*B簇的新中心點為{0.7, 0.7333, 0.4167};
*C簇的新中心點為{1, 0.94, 0.40625};
5.用調整後的中心點再次進行聚類,得到:
第二次迭代後的結果為:中國C,日本A,韓國A,伊朗A,沙特A,伊拉克C,卡達C,阿聯酋C,烏茲別克B,泰國C,越南C,阿曼C,巴林B,朝鮮B,印尼C;
結果無變化,說明結果已收斂,於是給出最終聚類結果:
亞洲一流:日本,韓國,伊朗,沙特;
亞洲二流:烏茲別克,巴林,朝鮮;
亞洲三流:中國,伊拉克,卡達,阿聯酋,泰國,越南,阿曼,印尼
K值及K個初始類簇中心點的選取:
<a href='http://www.cnblogs.com/kemaswill/archive/2013/01/26/2877434.html'>http://www.cnblogs.com/kemaswill/archive/2013/01/26/2877434.html</a>