
字首樹(Trie)原理及Java實現
字首樹的結構
Trie樹,又叫字典樹、字首樹(Prefix Tree)、單詞查詢樹或鍵樹,是一種多叉樹結構。如下圖:
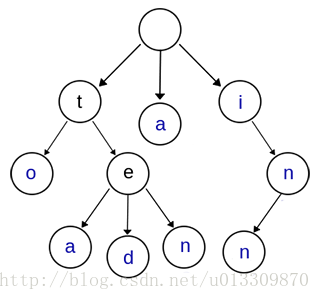
上圖是一棵Trie樹,表示了關鍵字集合{“a”, “to”, “tea”, “ted”, “ten”, “i”, “in”, “inn”} 。從上圖可以歸納出Trie樹的基本性質:
①根節點不包含字元,除根節點外的每一個子節點都包含一個字元。
②從根節點到某一個節點,路徑上經過的字元連線起來,為該節點對應的字串。
③每個節點的所有子節點包含的字元互不相同。
④從第一字元開始有連續重複的字元只佔用一個節點,比如上面的to,和ten,中重複的單詞t只佔用了一個節點。
字首樹的應用
1、字首匹配
2、字串檢索
3、詞頻統計
4、字串排序
下面看看怎樣使用字首樹來實現字首匹配的。
字首匹配
瞭解了字首樹的結構後,就可以利用字首樹的性質來解決現實中的問題。比如說查詢一個字串陣列中是否含有字首單詞,什麼是字首單詞:上面的 in,就是 inn 的字首單詞。如果有十幾萬條單詞,並且每個單詞的長度都是5-10以內,這樣必定存在大量重複的字元,因此利用字首樹來求解不僅速度快而且空間複雜度也比較好。
①定義字首樹結構
class Tries{
Boolean isTrie ;
HashMap<Character, Tries> children=new 上面的 isTrie 用來標記單詞是否遍歷完。children表示該節點的子節點。如上面的t節點的子節點有o和e兩個。
②建立字首樹
public static boolean insertNode(String str,Tries head)
{
if(str==null||str.length()==0)
return false;
//如果插入的單詞為null 或者單詞長度為0直接返回false,false代表該單詞不是字首樹中某個單詞的字首, 字首樹的建立過程就是插入字串的過程,同時在插入節點的時候可以判斷插入的字串是否是字首樹裡面某個單詞的字首,或者字首樹中的某個單詞是否是該單詞的字首。
①先將字串轉換為字元陣列,然後對每個字元進行處理,如果當前節點的子節點中包含有要處理的字元位元組複用。否則新建一個子節點。
②判斷是否是字首單詞的時候,有兩個步驟,首先要看該字串是否是其他字串的字首,還有看其他字串是否是當前字串的字首。
判斷字首單詞的完整程式碼:
public class isTrie {
public static void main(String[] args) {
Tries tries=new Tries();
String strs[]={"abc","abd","b","abdc"};
for(int i=0;i<strs.length;i++)
insertNode(strs[i], tries);
}
public static boolean insertNode(String str,Tries head)
{
if(str==null||str.length()==0)
return false;
char chs[]=str.toCharArray();
int i=0;
Tries cur=head;
while(i<chs.length)
{
if(!cur.children.containsKey(chs[i]))
{
cur.children.put(chs[i], new Tries());
}
cur=cur.children.get(chs[i]);
if(cur.count==true)
{
System.out.println(" trie tree");
return true;
}
i++;
}
cur.count=true;
if(cur.children.size()>0)
{
System.out.println(" trie tree");
return true;
}
return false;
}
}
class Tries{
boolean isTrie;
HashMap<Character, Tries> children=new HashMap<Character, Tries>();
}相關推薦
字首樹(Trie)原理及Java實現
字首樹的結構 Trie樹,又叫字典樹、字首樹(Prefix Tree)、單詞查詢樹或鍵樹,是一種多叉樹結構。如下圖: 上圖是一棵Trie樹,表示了關鍵字集合{“a”, “to”, “tea”, “ted”, “ten”, “i”, “in”, “inn”
簡單選擇排序演算法原理及java實現(超詳細)
選擇排序是一種非常簡單的排序演算法,就是在序列中依次選擇最大(或者最小)的數,並將其放到待排序的數列的起始位置。 簡單選擇排序的原理 簡單選擇排序的原理非常簡單,即在待排序的數列中尋找最大(或者最小)的一個數,與第 1 個元素進行交換,接著在剩餘的待排序的數列中繼續找最大(最小)的一個數,與第 2 個元素交
java資料結構與演算法之樹基本概念及二叉樹(BinaryTree)的設計與實現
關聯文章: 樹博文總算趕上這周釋出了,上篇我們聊完了遞迴,到現在相隔算挺久了,因為樹的內容確實不少,博主寫起來也比較費時費腦,一篇也無法涵蓋樹所有內容,所以後續還會用2篇左右的博文來分析其他內容大家就持續關注吧,而本篇主要了解的知識點如下(還是蠻多
LibieOJ 6170 字母樹 (Trie)
spa highlight get blog cnblogs uil tin for log 題目鏈接 字母樹 (以每個點為根遍歷,插入到trie中,統計答案即可)——SamZhang #include <bits/stdc++.h&g
【深度學習】線性迴歸(一)原理及python從0開始實現
文章目錄 線性迴歸 單個屬性的情況 多元線性迴歸 廣義線性模型 實驗資料集 介紹 相關連結 Python實現 環境 編碼
(轉)sslvpn及openvpn實現原理
SSL VPN即指採用SSL (Security Socket Layer)協議來實現遠端接入的一種新型VPN技術。SSL協議是基於WEB應用的安全協議,它包括:伺服器認證、客戶認證(可選)、SSL鏈路上的資料完整性和SSL鏈路上的資料保密性。 傳統的vpn,如IPsec vpn是在IP層實現的
決策樹演算法原理及JAVA實現(ID3)
package sequence.machinelearning.decisiontree.myid3; import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.io.FileWri
影象超解析度重構(一)原理及方法總結
超解析度(Super-resolution)概念理解: 百科:超解析度(Super-Resolution)通過硬體或軟體的方法提高原有影象的解析度,通過一系列低解析度的影象來得到一幅高解析度的影象過
B - Trie樹 (trie)(字典樹的拓展)
B - Trie樹 (trie) Time Limit:10000MS Memory Limit:262144KB 64bit IO Format:%lld & %llu
譜聚類(Spectral Clustering)原理及Python實現
譜聚類原理及Python實現 圖模型 無向帶權圖模型 G=<V,E> G =< V ,
視覺里程計(VisualOdometry)原理及實現
一、視覺里程計(VisualOdometry)介紹 目前,有不止一種方式可以確定移動機器人的軌跡,這裡將重點強調“視覺里程計”這種方法。在這種方法中,單個相機或者雙目相機被用到,其目的是為了重構出機器
[算法系列之二十]字典樹(Trie)
一 概述 又稱單詞查詢樹,Trie樹,是一種樹形結構,是一種雜湊樹的變種。典型應用是用於統計,排序和儲存大量的字串(但不僅限於字串),所以經常被搜尋引擎系統用於文字詞頻統計。 二 優點 利用字串的公共字首來減少查詢時間,最大限度地減少無謂的字串比較,查詢效
Hadoop2.7.3 mapreduce(一)原理及"hello world"例項
MapReduce程式設計模型 【1】先對輸入的資訊進行切片處理。 【2】每個map函式對所劃分的資料並行處理,產生不同的中間結果輸出。 【3】對map的中間結果資料進行收集整理(aggregate & shuffle)處理,交給reduce。 【4】reduce進
MLP多層感知機(人工神經網路)原理及程式碼實現
一、多層感知機(MLP)原理簡介多層感知機(MLP,Multilayer Perceptron)也叫人工神經網路(ANN,Artificial Neural Network),除了輸入輸出層,它中間可以有多個隱層,最簡單的MLP只含一個隱層,即三層的結構,如下圖:從上圖可以看
分享基於.NET動態編譯&Newtonsoft.Json封裝實現JSON轉換器(JsonConverter)原理及JSON操作技巧
看文章標題就知道,本文的主題就是關於JSON,JSON轉換器(JsonConverter)具有將C#定義的類原始碼直接轉換成對應的JSON字串,以及將JSON字串轉換成對應的C#定義的類原始碼,而JSON操作技巧則說明如何通過JPath來快速的定位JSON的屬性節點從而達到靈活讀寫JSON目的。 一、J
多執行緒(基礎)Python、Java實現
大二學習Java時第一次接觸了多執行緒的概念,但是當時並不理解,只是知道大體的概念。 如今確成為了大三狗,開設了作業系統這門課。如今回首當年,貌似又懂了什麼。 一個程式有多個程序,而一個程序裡會
【排序演算法】希爾排序原理及Java實現
1、基本思想: 希爾排序也成為“縮小增量排序”,其基本原理是,現將待排序的陣列元素分成多個子序列,使得每個子序列的元素個數相對較少,然後對各個子序列分別進行直接插入排序,待整個待排序列“基本有序”後,最後在對所有元素進行一次直接插入排序。因此,我們要採用跳躍分
【排序演算法】歸併排序原理及Java實現
1、基本思想: 歸併排序就是利用歸併的思想實現的排序方法。而且充分利用了完全二叉樹的深度是的特性,因此效率比較高。其基本原理如下:對於給定的一組記錄,利用遞迴與分治技術將資料序列劃分成為越來越小的半子表,在對半子表排序,最後再用遞迴方法將排好序的半子表合併成為
粒子群優化演算法(PSO)簡介及MATLAB實現
目錄 粒子群優化演算法概述 • 粒子群優化(PSO, particle swarm optimization)演算法是計算智慧領域,除了蟻群演算法,魚群演算法之外的一種群體智慧的優化演算法,該演算法最早由Kennedy和Eberhart在1995年提出的,
【資料結構】堆疊、佇列的原理及java實現
一、堆是一個執行時資料區,通過new等指令建立,不需要程式程式碼顯式釋放 <1>優點: 可動態分配記憶體大小,生存週期不必事先告訴編譯器,Java垃圾回收自動回收不需要的資料; <2>缺點: 執行時需動態分配記憶體,資料存取速度較