
[算法系列之二十]字典樹(Trie)
一 概述
又稱單詞查詢樹,Trie樹,是一種樹形結構,是一種雜湊樹的變種。典型應用是用於統計,排序和儲存大量的字串(但不僅限於字串),所以經常被搜尋引擎系統用於文字詞頻統計。
二 優點
利用字串的公共字首來減少查詢時間,最大限度地減少無謂的字串比較,查詢效率比雜湊表高。
三 性質
(1)根節點不包含字元,除根節點外每一個節點都只包含一個字元;
(2)從根節點到某一節點,路徑上經過的字元連線起來,為該節點對應的字串;
(3)每個節點的所有子節點包含的字元都不相同。
單詞列表為”apps”,”apply”,”apple”,”append”,”back”,”backen”以及”basic”對應的字母樹可以是如下圖所示。
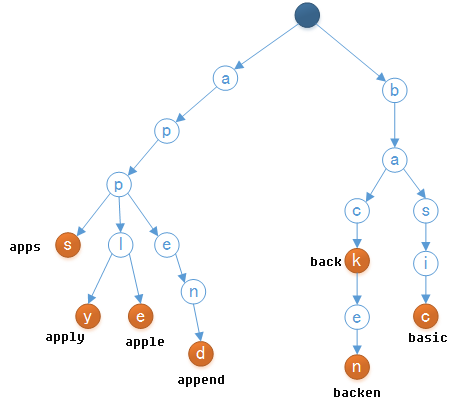
例如,儲存”apple”和 “apply”時,由於它們的前四個字母是相同的,所以希望它們共享這些字母,而只對剩下的部分進行分開儲存。可以很明顯地發現,字母樹很好地利用了串的公共字首,節約了儲存空間。
四 應用
(1)串的快速檢索
給出N個單片語成的熟詞表,以及一篇全用小寫英文書寫的文章,請你按最早出現的順序寫出所有不在熟詞表中的生詞。
在這道題中,我們可以用陣列列舉,用雜湊,用字典樹,先把熟詞建一棵樹,然後讀入文章進行比較,這種方法效率是比較高的。
(2)“串”排序
給定N個互不相同的僅由一個單詞構成的英文名,讓你將他們按字典序從小到大輸出用字典樹進行排序,採用陣列的方式建立字典樹,這棵樹的每個結點的所有兒子很顯然地按照其字母大小排序。對這棵樹進行先序遍歷即可。
(3)最長公共字首
對所有串建立字典樹,對於兩個串的最長公共字首的長度即他們所在的結點的公共祖先個數,於是,問題就轉化為當時公共祖先問題。
五 實現
字典樹的插入(Insert)、刪除( Delete)和查詢(Find )都非常簡單,用一個一重迴圈即可,即第 i 次迴圈找到前 i 個字母所對應的子樹,然後進行相應的操作。實現這棵字典樹,我們用最常見的陣列儲存即可,當然也可以開動態的指標型別。至於結點對兒子的指向,一般有三種方法:
(1)對每個結點開一個字母集大小的陣列,對應的下標是兒子所表示的字母,內容則是這個兒子對應在大陣列上的位置,即標號;
(2)對每個結點掛一個連結串列,按一定順序記錄每個兒子是誰;
(3)使用左兒子右兄弟表示法記錄這棵樹。
三種方法,各有千秋。第一種易實現,但實際的空間要求較大;第二種,
較易實現,空間要求相對較小,但比較費時;第三種,空間要求最小,但相對費時且不易寫。但總的來說,幾種實現方式都是比較簡單的,只要在做題時加以合理選擇即可。
/*---------------------------------------------
* 日期:2015-02-21
* 作者:SJF0115
* 題目: 20.字典樹
* 來源:算法系列
* 部落格:
-----------------------------------------------*/
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
#define MAX 26
struct TrieNode{
// 以該節點為結尾的單詞個數
int count;
TrieNode *next[MAX];
TrieNode(int x):count(x){
for(int i = 0;i < MAX;++i){
next[i] = NULL;
}//for
}
};
// 插入
void Insert(TrieNode* &root,string str){
int size = str.size();
int val;
TrieNode *p = root;
// 一個一個字元插入
for(int i = 0;i < size;++i){
val = str[i] - 'a';
// 之前沒有該字元
if(p->next[val] == NULL){
p->next[val] = new TrieNode(0);
}//if
p = p->next[val];
}//for
// 以該字元為結尾
p->count++;
}
// 刪除
void Delete(TrieNode* &root,string str){
int size = str.size();
int val;
TrieNode *p = root;
// 一個一個字元插入
for(int i = 0;i < size;++i){
val = str[i] - 'a';
// 刪除的字串不在字典中
if(p->next[val] == NULL){
return;
}//if
p = p->next[val];
}//for
// 以該字元為結尾
p->count--;
}
// 查詢
bool Search(TrieNode* root,string str){
if(root == NULL){
return false;
}//if
int size = str.size();
TrieNode *p = root;
int val;
for(int i = 0;i < size;++i){
val = str[i] - 'a';
// 無法轉移到下一個字元
if(p->next[val] == NULL){
return false;
}//if
// 繼續下一個字元
p = p->next[val];
}//for
return p->count > 0;
}
// 列印字典
void PrintDic(TrieNode* root,vector<vector<char> > &words,vector<char> &word){
if(root == NULL){
return;
}//if
if(root->count > 0){
words.push_back(word);
}//if
for(int i = 0;i < 26;++i){
if(root->next[i]){
word.push_back('a'+i);
PrintDic(root->next[i],words,word);
word.pop_back();
}//if
}//for
}
int main() {
TrieNode* root = new TrieNode(0);
// 插入
string strs[] = {"ok","applition","app","apple","apply"};
for(int i = 0;i < 5;++i){
Insert(root,strs[i]);
}//for
string str("apple");
cout<<"刪除單詞["<<str<<"]之前查詢結果:"<<endl;
// 查詢
if(Search(root,str)){
cout<<"單詞["<<str<<"]在字典中"<<endl;
}//if
else{
cout<<"單詞["<<str<<"]不在字典中"<<endl;
}
cout<<"刪除單詞["<<str<<"]"<<endl;
// 刪除
Delete(root,str);
cout<<"刪除單詞["<<str<<"]之後查詢結果:"<<endl;
// 查詢
if(Search(root,str)){
cout<<"單詞["<<str<<"]在字典中"<<endl;
}//if
else{
cout<<"單詞["<<str<<"]不在字典中"<<endl;
}
// 字典列表
cout<<"字典列表:"<<endl;
vector<vector<char> > words;
vector<char> word;
PrintDic(root,words,word);
for(int i = 0;i < words.size();++i){
for(int j = 0;j < words[i].size();++j){
cout<<words[i][j];
}//for
cout<<endl;
}//for
return 0;
}
六 引用
演算法合集之《淺析字母樹在資訊學競賽中的應用》
有問題歡迎指正,謝謝。。。。。。。