
HBase phoenix二級索引
1. 為什麼需要用二級索引?
對於HBase而言,如果想精確地定位到某行記錄,唯一的辦法是通過rowkey來查詢。如果不通過rowkey來查詢資料,就必須逐行地比較每一列的值,即全表掃瞄。對於較大的表,全表掃描的代價是不可接受的。但是,很多情況下,需要從多個角度查詢資料。例如,在定位某個人的時候,可以通過姓名、身份證號、學籍號等不同的角度來查詢,要想把這麼多角度的資料都放到rowkey中幾乎不可能(業務的靈活性不允許,對rowkey長度的要求也不允許)。所以,需要secondary index(二級索引)來完成這件事。secondary index的原理很簡單,但是如果自己維護的話則會麻煩一些。現在,Phoenix已經提供了對HBase secondary index的支援。
2. Phoenix Global Indexing And Local Indexing
2.1 Global Indexing
Global indexing,全域性索引,適用於讀多寫少的業務場景。使用Global indexing在寫資料的時候開銷很大,因為所有對資料表的更新操作(DELETE, UPSERT VALUES and UPSERT SELECT),都會引起索引表的更新,而索引表是分佈在不同的資料節點上的,跨節點的資料傳輸帶來了較大的效能消耗。在讀資料的時候Phoenix會選擇索引表來降低查詢消耗的時間。在預設情況下如果想查詢的欄位不是索引欄位的話索引表不會被使用,也就是說不會帶來查詢速度的提升。
2.2 Local Indexing
Local indexing,本地索引,適用於寫操作頻繁以及空間受限制的場景。與Global indexing一樣,Phoenix會自動判定在進行查詢的時候是否使用索引。使用Local indexing時,索引資料和資料表的資料存放在相同的伺服器中,這樣避免了在寫操作的時候往不同伺服器的索引表中寫索引帶來的額外開銷。使用Local indexing的時候即使查詢的欄位不是索引欄位索引表也會被使用,這會帶來查詢速度的提升,這點跟Global indexing不同。對於Local Indexing,一個數據表的所有索引資料都儲存在一個單一的獨立的可共享的表中。
3. Immutable index And Mutable index
3.1 immutable index
immutable index,不可變索引,適用於資料只增加不更新並且按照時間先後順序儲存(time-series data)的場景,如儲存日誌資料或者事件資料等。不可變索引的儲存方式是write one,append only。當在Phoenix使用create table語句時指定IMMUTABLE_ROWS = true表示該表上建立的索引將被設定為不可變索引。Phoenix預設情況下如果在create table時不指定IMMUTABLE_ROW = true時,表示該表為mutable。不可變索引分為Global immutable index和Local immutable index兩種。
3.2 mutable index
mutable index,可變索引,適用於資料有增刪改的場景。Phoenix預設情況建立的索引都是可變索引,除非在create table的時候顯式地指定IMMUTABLE_ROWS = true。可變索引同樣分為Global immutable index和Local immutable index兩種。
4.配置HBase支援Phoenix二級索引
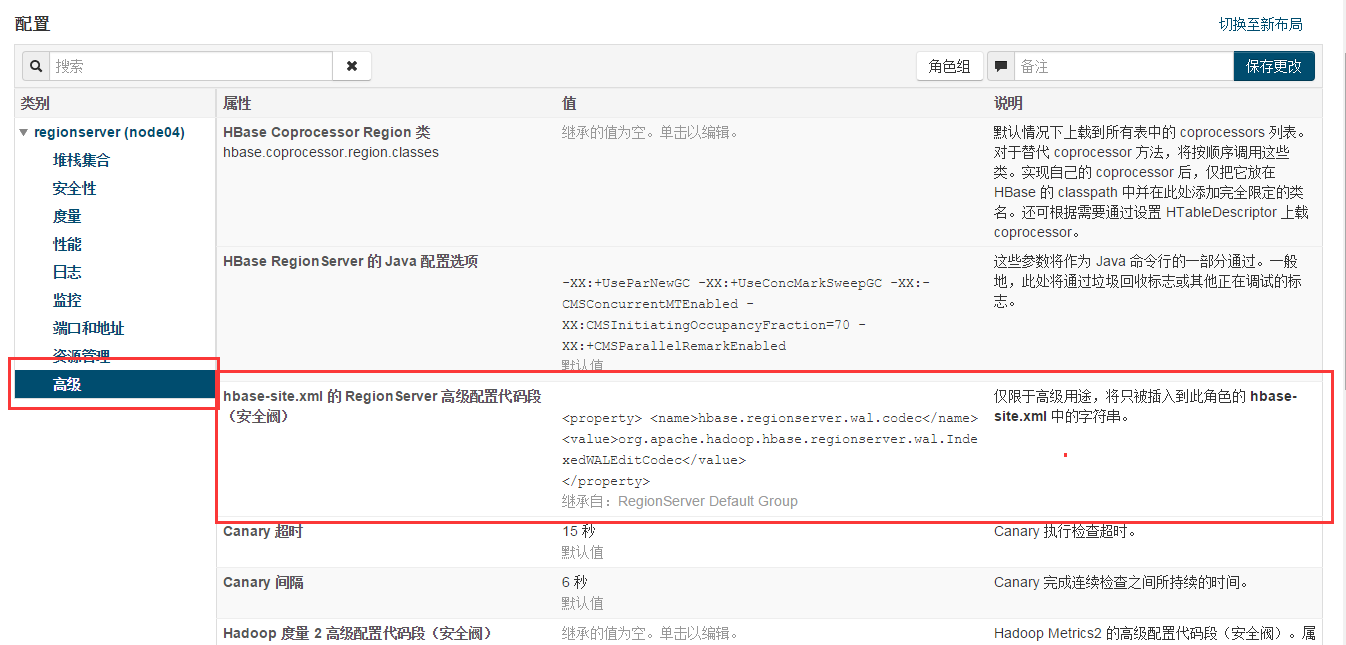
如果要啟用phoenix的二級索引功能,需要對HMaster以及每一個RegionServer上的hbase-site.xml進行額外的配置。首先,在每一個RegionServer的hbase-site.xml里加入如下屬性:
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
<property>
<name>hbase.region.server.rpc.scheduler.factory.class</name>
<value>org.apache.hadoop.hbase.ipc.PhoenixRpcSchedulerFactory</value>
<description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description>
</property>
<property>
<name>hbase.rpc.controllerfactory.class</name>
<value>org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactory</value>
<description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description>
</property>
<property>
<name>hbase.coprocessor.regionserver.classes</name>
<value>org.apache.hadoop.hbase.regionserver.LocalIndexMerger</value>
</property>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
如果沒有在每個regionserver上的hbase-site.xml裡面配置如上屬性,那麼使用create index語句建立二級索引將會丟擲如下異常:
Error: ERROR 1029 (42Y88): Mutable secondary indexes must have the hbase.regionserver.wal.codec property set to org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec in the hbase-sites.xml of every region server tableName=TEST_INDEXES (state=42Y88,code=1029)- 1
- 1
然後在每一個master的hbase-site.xml里加入如下屬性:
<property>
<name>hbase.master.loadbalancer.class</name>
<value>org.apache.phoenix.hbase.index.balancer.IndexLoadBalancer</value>
</property>
<property>
<name>hbase.coprocessor.master.classes</name>
<value>org.apache.phoenix.hbase.index.master.IndexMasterObserver</value>
</property>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
完成上述修改後重啟hbase叢集使配置生效。
【特別注意】
如果使用的是CDH部署的HBase,需要在Cloudera Manager管理頁面裡面的HBase“配置”頁面裡的hbase-site.xml項增加上述配置,並在管理頁面裡面重啟HBase才能使得配置生效。
5. 測試案例
5.1 測試案例1
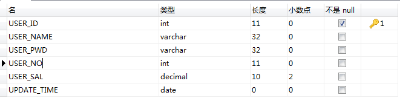
HBase 1000w資料
users_test表
【Global Indexing】
在沒有建立二級索引之前查詢特定USER_NAME的使用者資訊耗時大約16s左右。

在USER_NAME列上面建立二級索引:
create index USERS_TEST_IDX0 on "users_test ("info".USER_NAME)- 1
- 1
建立二級索引後查詢特定USER_NAME的使用者名稱稱耗時為ms級別

【說明】 可以通過explain命令來檢視查詢是否用到二級索引

【注意】 如果在select條件裡面選擇了其他的列,如USER_NO,因為該列沒有存在於索引表,因此查詢不會走索引表。

如果想在select USER_NAME,USER_NO查詢仍然走索引,必須建立如下索引:
- 方式一,採取INCLUDE(index cover,即索引覆蓋)的方式:
create index USERS_TEST_IDX1 on "users_test"("info".USER_NAME) INCLUDE("info".USER_NO)- 1
- 1
索引覆蓋其實就是將INCLUDE裡面包含的列都儲存到索引表裡面,當檢索的時候就可以從索引表裡直接帶回這些列值。要特別注意索引列和索引覆蓋列的區別,索引列在索引表裡面是以rowkey的形式存在,多個索引列以某個約定的位元組分割然後一起儲存在rowkey裡面,也就是說當索引列有很多個的時候,rowkey的長度也相應會變長,大小取決於索引列值的大小。而索引覆蓋列,是儲存在索引表的列族中。
- 方式二,採取多列索引:
create index USERS_TEST_IDX2 on "users_test"("info".USER_NAME, "info".USER_NO) - 1
- 1
【說明】
多列索引在滿足字首式的情況才會用到,如建立了A,B,C順序的多列索引,當在where條件指定A條件、A B條件或者A B C條件均會走索引,但是 B C條件則無法走索引。
【Local Indexing】
在users_test表建立local index型別的二級索引:
create local index USERS_TEST_LOCAL_IDX ON "users_test"("info".USER_NAME)- 1
- 1
與Global Indexing不同的是,如果select子句裡面帶有除了索引列(USER_NAME)以外的列,仍然可以走索引表。


【說明】
建立Local Indexing時候指定的索引名稱會與實際建立在Hbase裡面的表名稱不一致,這應該是Phoenix做了對映的關係,而且對於同一個Hbase裡面的table建立多個Local Indexing,索引表在Hbse list命令查詢的時候也只有一個。
5.2 測試案例2
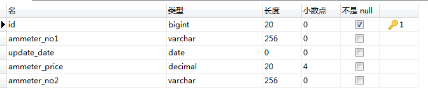
HBase 1e資料
ammeter_test表

【Global Indexing】
create index AMMETER_TEST_IDX
on AMMETER_TEST ("info"."ammeter_no1", "info"."ammeter_no2") include("info"."ammeter_price");- 1
- 2
- 1
- 2
(1) 條件查詢包含rowkey
> explain select * from AMMETER_TEST where "info"."ammeter_no1" = '11000000005281' AND "ammeter_no2" = '11000000001004' and ROW = '11000002310462'
> select * from AMMETER_TEST where "info"."ammeter_no1" = '11000000005281' AND "ammeter_no2" = '11000000001004' and ROW = '11000002310462'- 1
- 2
- 1
- 2


(2) 條件查詢不包含rowkey但滿足二級索引查詢條件
> explain select ROW,"ammeter_price" from AMMETER_TEST where "info"."ammeter_no1" = '11000000005281' and "ammeter_no2" = '11000000001004'
> select ROW,"ammeter_price" from AMMETER_TEST where "info"."ammeter_no1" = '11000000005281' and "ammeter_no2" = '11000000001004' LIMIT 5- 1
- 2
- 1
- 2


【分析】
- 對於包含rowkey的條件查詢,Phoenix會啟用伺服器端過濾器快速篩選匹配的行並返回,億級資料也能達到毫秒級別響應。
- 對於沒有包含rowkey的條件查詢,如果條件滿足Phoenix二級索引查詢,Phoenix會查二級索引表並快速返回記錄。
6. 同步建立索引與非同步建立索引
前面所講的建立索引為同步建立索引,當執行create index的時候,索引表會直接與源資料表進行同步。但是,有時候我們的源表資料量很大,同步建立索引會丟擲異常。異常資訊大致如下所示:
15/12/11 14:20:08 WARN client.ScannerCallable: Ignore, probably already closed
org.apache.hadoop.hbase.UnknownScannerException: org.apache.hadoop.hbase.UnknownScannerException: Name: 37, already closed?
at org.apache.hadoop.hbase.regionserver.RSRpcServices.scan(RSRpcServices.java:2092)
at org.apache.hadoop.hbase.protobuf.generated.ClientProtos$ClientService$2.callBlockingMethod(ClientProtos.java:31443)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:2035)
at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:107)
at org.apache.hadoop.hbase.ipc.RpcExecutor.consumerLoop(RpcExecutor.java:130)
at org.apache.hadoop.hbase.ipc.RpcExecutor$1.run(RpcExecutor.java:107)
at java.lang.Thread.run(Thread.java:745)
at sun.reflect.GeneratedConstructorAccessor13.newInstance(Unknown Source)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:526)
at org.apache.hadoop.ipc.RemoteException.instantiateException(RemoteException.java:106)
at org.apache.hadoop.ipc.RemoteException.unwrapRemoteException(RemoteException.java:95)
at org.apache.hadoop.hbase.protobuf.ProtobufUtil.getRemoteException(ProtobufUtil.java:313)
at org.apache.hadoop.hbase.client.ScannerCallable.close(ScannerCallable.java:329)
at org.apache.hadoop.hbase.client.ScannerCallable.call(ScannerCallable.java:184)
at org.apache.hadoop.hbase.client.ScannerCallableWithReplicas.call(ScannerCallableWithReplicas.java:136)
at org.apache.hadoop.hbase.client.ScannerCallableWithReplicas.call(ScannerCallableWithReplicas.java:56)
at org.apache.hadoop.hbase.client.RpcRetryingCaller.callWithoutRetries(RpcRetryingCaller.java:200)
at org.apache.hadoop.hbase.client.ClientScanner.call(ClientScanner.java:288)
at org.apache.hadoop.hbase.client.ClientScanner.close(ClientScanner.java:507)
at org.apache.phoenix.iterate.ScanningResultIterator.close(ScanningResultIterator.java:49)
at org.apache.phoenix.iterate.TableResultIterator.close(TableResultIterator.java:95)
at org.apache.phoenix.jdbc.PhoenixResultSet.close(PhoenixResultSet.java:162)
at org.apache.phoenix.compile.UpsertCompiler.upsertSelect(UpsertCompiler.java:199)
at org.apache.phoenix.compile.UpsertCompiler.access$000(UpsertCompiler.java:114)
at org.apache.phoenix.compile.UpsertCompiler$UpsertingParallelIteratorFactory.mutate(UpsertCompiler.java:229)
at org.apache.phoenix.compile.MutatingParallelIteratorFactory.newIterator(MutatingParallelIteratorFactory.java:62)
at org.apache.phoenix.iterate.ParallelIterators$1.call(ParallelIterators.java:109)
at org.apache.phoenix.iterate.ParallelIterators$1.call(ParallelIterators.java:100)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at org.apache.phoenix.job.JobManager$InstrumentedJobFutureTask.run(JobManager.java:183)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: org.apache.hadoop.hbase.ipc.RemoteWithExtrasException(org.apache.hadoop.hbase.UnknownScannerException): org.apache.hadoop.hbase.UnknownScannerException: Name: 37, already closed?
at org.apache.hadoop.hbase.regionserver.RSRpcServices.scan(RSRpcServices.java:2092)
at org.apache.hadoop.hbase.protobuf.generated.ClientProtos$ClientService$2.callBlockingMethod(ClientProtos.java:31443)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:2035)
at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:107)
at org.apache.hadoop.hbase.ipc.RpcExecutor.consumerLoop(RpcExecutor.java:130)
at org.apache.hadoop.hbase.ipc.RpcExecutor$1.run(RpcExecutor.java:107)
at java.lang.Thread.run(Thread.java:745)
at org.apache.hadoop.hbase.ipc.RpcClientImpl.call(RpcClientImpl.java:1199)
at org.apache.hadoop.hbase.ipc.AbstractRpcClient.callBlockingMethod(AbstractRpcClient.java:216)
at org.apache.hadoop.hbase.ipc.AbstractRpcClient$BlockingRpcChannelImplementation.callBlockingMethod(AbstractRpcClient.java:300)
at org.apache.hadoop.hbase.protobuf.generated.ClientProtos$ClientService$BlockingStub.scan(ClientProtos.java:31889)
at org.apache.hadoop.hbase.client.ScannerCallable.close(ScannerCallable.java:327)
... 20 more- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
這個時候,我們可以採用非同步建立索引,方式如下:
CREATE INDEX async_index ON my_schema.my_table (v) ASYNC- 1
- 1
通過create index的時候指定 ASYNC 關鍵字來指定非同步建立索引。執行這個命令之後並不會引起索引表與源表的直接同步。這個時候查詢並不會使用這個索引表。那麼索引資料的匯入還需要採用phoenix提供的索引同步工具類 IndexTool ,
這是一個mapreduce工具類,使用方式如下:
${HBASE_HOME}/bin/hbase org.apache.phoenix.mapreduce.index.IndexTool
--schema MY_SCHEMA --data-table MY_TABLE --index-table ASYNC_IDX
--output-path ASYNC_IDX_HFILES- 1
- 2
- 3
- 1
- 2
- 3
當mapreduce任務執行結束,這個索引表才會變成可用。
7. 參考
相關推薦
HBase phoenix二級索引
1. 為什麼需要用二級索引? 對於HBase而言,如果想精確地定位到某行記錄,唯一的辦法是通過rowkey來查詢。如果不通過rowkey來查詢資料,就必須逐行地比較每一列的值,即全表掃瞄。對於較大的表,全表掃描的代價是不可接受的。但是,很多情況下,需要從多個角度查詢資料
HBase建立二級索引的一些解決方式
ack sca for done pseudo 100% hide shm range HBase的一級索引就是rowkey,我們僅僅能通過rowkey進行檢索。假設我們相對hbase裏面列族的列列進行一些組合查詢。就須要採用HBase的二級索引方案來進
HBase的二級索引
strong clean 查詢 問題 mvn clean 流程 zxvf oop sem HBase的二級索引,以及phoenix的安裝(需再做一次) 一:HBase的二級索引 1.講解 uid+ts 11111_20161126111111:查詢某一u
Phoenix二級索引(Secondary Indexing)的使用(轉:https://www.cnblogs.com/MOBIN/p/5467284.html)
摘要 HBase只提供了一個基於字典排序的主鍵索引,在查詢中你只能通過行鍵查詢或掃描全表來獲取資料,使用Phoenix提供的二級索引,可以避免在查詢資料時全表掃描,提高查過效能,提升查詢效率 測試環境: 資料約370萬 資料格式:(資料來自搜狗實驗室) 三節點叢集(一主兩從,hadoo
Phoenix二級索引原理及Bulkload注意問題
前言 最近在Hbase的使用過程中遇到了很多問題,通過各種查資料測試最終得到解決。趁此機會也對Hbase預分割槽及索引的原理作了一些較深入的學習,以便更好的使用Hbase及對資料庫效能調優。 下面對Hbase的索引觸發原理及Bulkload匯入資料需注意的問題作了簡要總結,希望能對大
Phoenix二級索引(Secondary Indexing)的使用
2017年02月22日 08:35:04 xuguokun1986 閱讀數:499 摘要 HBase只提供了一個基於字典排序的主鍵索引,在查詢中你只能通過行鍵查詢或掃描全表來獲取資料,使用Phoenix提供的二級索引,可以避免在查詢資料時全表掃描,提高查
利用Solr建立HBase的二級索引
public void insertSolr(Put put) { CloudSolrServer cloudSolrServer; final String zkHost = "IP:2181,IP:2181,IP:2181"; final int zkConnectTimeout = 1;
Phoenix二級索引,配置,測試
1. 為什麼需要用二級索引?對於HBase而言,如果想精確地定位到某行記錄,唯一的辦法是通過rowkey來查詢。如果不通過rowkey來查詢資料,就必須逐行地比較每一列的值,即全表掃瞄。對於較大的表,全表掃描的代價是不可接受的。但是,很多情況下,需要從多個角度查詢資料。例如,
phoenix二級索引源碼閱讀
ldr ima cati 多個 regions efault nan HERE byte Phoenix二級索引建立源碼 Phoenix二級索引建立在hbase的coprocess功能,建立索引的時候使用是 二級索引建立過程,索引rowkey的構建是一個數據
hbase表對映Phoenix檢視, 基於檢視的二級索引是否實時更新
1. hbase shell 建立表 create 'MY_TABLE', 'CF1','CF2' 新增資料 put 'MY_TABLE','1' ,'CF1:V1', 'uwo1' put 'MY_TABLE','1' ,'CF2:V2', '1' put 'MY_
hbase二級索引構建
tables required family create tab ice converts length strong 參考學習hbase源代碼中的二級索引構建代碼 IndexBuilder.java /** * * Licensed to the Apache
Hbase二級索引+CDH+Lily
1.更改表結構,允許複製 已存在的表 disable 'tableName' alter 'tableName',{NAME =>'fn', REPLICATION_SCOPE =>1} enable 'tableName' 不存在的表 create ‘table‘,{N
[Phoenix基礎]-- 二級索引應該使用local Index還是global Index?
版本:phoenix 4.12.0 說明: 1、一個global index表對應著一個hbase 表,local index是在主表上新增一列儲存索引資料。 2、適用場景 global index :適用於多讀的場景,但是存在同步索引時帶來網路開銷較大的問題。 local
phoenix建立二級索引索要修改的配置
如果不進行任何配置,直接在phoenix上建立二級索引 ,比如 create index A_INDEX on "t_tablename"("from_account","to_account","quantity","status") include("fro
hbase協處理器與二級索引
一、協處理器—Coprocessor 1、 起源 Hbase 作為列族資料庫最經常被人詬病的特性包括:無法輕易建立“二級索引”,難以執 行求和、計數、排序等操作。比如,在舊版本的(<0.92)Hbase 中,統計資料表的總行數,需 要使用 Counte
HBase利用observer(協處理器)建立二級索引
一、協處理器—Coprocessor 1、 起源 Hbase 作為列族資料庫最經常被人詬病的特性包括:無法輕易建立“二級索引”,難以執 行求和、計數、排序等操作。比如,在舊版本的(<0.92)Hbase 中,統
華為hbase二級索引(secondary index)細節分析 2013-06-03 | 相關總結
華為在HBTC 2012上由其高階技術經理Anoop Sam John透露了其二級索引方案,這在業界引起極大的反響,甚至有人認為,如果華為早點公佈這個方案,hbase的某些問題早就解決了。其核心思想是保證索引表和主表在同一個region server上。 下面來對其方案做
solr-hbase二級索引及查詢解決方案(一)
最近要搞一個查詢功能,是把hbase中的資料方便的查詢出來.之前根據rowkey的查詢方式,儘管有針對性設計過rowkey,有字首查詢,字尾查詢,以及正則查詢,但是實際上不夠用. 參考了網路上的設計,建立二級索引是比較好的思路.於是就以solr儲存hbase
Hbase二級索引方案Solr key value index
概述 在Hbase中,表的RowKey 按照字典排序, Region按照RowKey設定split point進行shard,通過這種方式實現的全域性、分散式索引. 成為了其成功的最大的砝碼。 然而單一的通過RowKey檢索資料的方式,不再滿足更多的需求,查詢成為Hb
基於Solr的Hbase二級索引
關於Hbase二級索引 HBase 是一個列存資料庫,每行資料只有一個主鍵RowKey,無法依據指定列的資料進行檢索。查詢時需要通過RowKey進行檢索,然後檢視指定列的資料是什麼,效率低下。在實際應用中,我們經常需要根據指定列進行檢索,或者幾個列進行組合檢索,這就提出