
字符集編碼 定長與變長
☯,首先,這並不是圖片,這是一個unicode字元,Yin Yang,即陰陽符,碼點為U+262F。如果你的瀏覽器無法顯示,可以檢視這個連結http://www.fileformat.info/info/unicode/char/262f/index.htm。這與我們要討論的主題有何關係呢?下面我會談到。
連續式表示帶來的分隔難題
計算機的底層表示
在計算機的最底層,一切都成了0和1,你也許見過一些極客(Geek)穿著印有一串0和1的衣服招搖過市,像是數字化時代的某種圖騰。比如,這麼一串“0001100101101110001111111000…”,如果它來自某個文字檔案儲存後的結果,我們如何從這一串的0和1中從新解碼得到一個個的字元呢?顯然你需要把這一串的0和1分成一段一段的0和1,在講述編碼是如何分隔之前,我們先看看自然語言的分隔問題。
自然語言的分隔問題
大家是否意識到,我們的中文句子裡字詞之間也是連續的呢?英文裡說“hello world”,我們說“你好世界”,“我們 不 需要 在 中間 加 空格!”在古代,句與句之間甚至都沒有分開,那時還沒有標點!所以有了所謂的斷句問題。讓我們來看一個例子:
民可使由之不可使知之 ——出自《論語 第八章 泰伯篇》
這麼一串十個字要如何去分隔並解釋呢?
斷法一:
民可使由之,不可使知之。
解釋:你可以去驅使你的民眾,但不可讓他們知道為什麼(不要去教他們知識)
評論:很顯然是站在統治階級立場的一種愚民論調。
斷法二:
民可,使由之;不可,使知之。
解釋:民眾可以做的,放手讓他們去做;不會做的,教會他們如何去做(又或:不可以去做的,讓他們明白為何不可以)
評論:這看來是種不錯的主張。
顯然,以上的文字是以某種定長或變長的方式組合在一起的,但是關於它們如何分隔的資訊則被丟棄了,於是在解釋時就存在產生歧義可能了。
如何快速準確分詞在中文NLP領域還是蠻有挑戰的一件事,當然了,字符集編碼的分隔就簡單多了。
編碼的分隔
自然語言中我們可以使用空格,標點來減少歧義的發生。在計算機裡,一切都數字化了,包括所謂的空格,標點之類的分隔符。
老子說“道生一,一生二,二生三,三生萬物”,計算機則是“二生萬物”,0和1表示了一切。
在空格與標點都被數字化的情況下,我們在這一串01中如何去找出分隔來呢?顯然我們需要外部的約定。
8位(bit)一組的位元組是最基本的一個約定,也是檔案
的基本單位,檔案就是位元組的序列。位元組顯然就是最基礎的一個分隔依據。
定長(Fixed-length)的解決方案
定長僅表明段與段之間長度相同,但沒說明是多長。有了位元組這一基本單位,我們就可以說得更具體,如定長一位元組或者定長二位元組。
ASCII編碼是最早也是最簡單的一種字元編碼方案,使用定長一位元組來表示一個字元。
下面我們來看一個具體的編碼示例,為了方便,採用了十進位制,大家看起來也更直觀,原理與二進位制是一樣的。
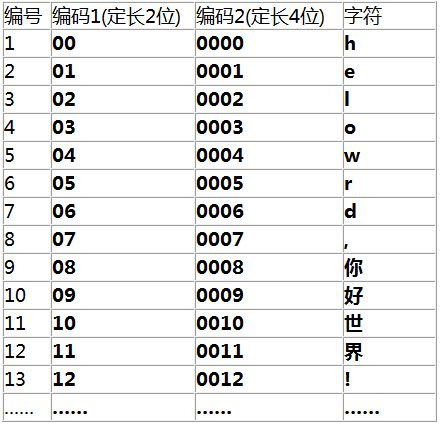
假設我們現在有個檔案,內容是00000001,假如定長2位(這裡的位指十進位制的位)是唯一的編碼方案,用它去解碼,就會得到“hhhe”(可以對比圖上的編碼,00代表h,所以前6個0轉化成3個h,後面的01則轉化成e)。
但是,如果定長2位不是唯一的編碼方案呢?如上圖中的定長4位方案,如果我們誤用定長4位去解碼,結果就只能得到“he”(0000轉化為h,0001轉化為e)!

畢竟,檔案的內容並沒有暗示它使用了何種編碼!這就好比孔夫子寫下“民可使由之不可使知之”時並沒有暗示它是5|5分隔(民可使由之|不可使知之)還是2|3|2|3分隔(民可|使由之|不可|使知之)那樣。
如何區分不同的定長(以及變長)編碼方式?
答案是:你無法區分!好吧,這麼說可能有點武斷,有人可能會說BOM(Byte Order Mark 位元組順序標識)能否算作某種區分手段呢?但也有很多情況是沒有BOM的。
總之,我想給讀者傳遞的一個資訊就是
文字檔案作為一種通用的檔案,在儲存時一般都不會帶上其所使用編碼的資訊。編碼資訊與檔案內容的分離,其實這正是亂碼的根源。
我們說無法區分即是基於這一點而言,但另一方面,各種編碼方案所形成的位元組序列也往往帶有某種特徵,綜合統計學,語言偏好等因素,還是有可能猜測出正確的編碼的,比如很多瀏覽器中都有所謂“編碼自動檢測”的功能。
本章主題主講定變長,更多討論可見亂碼探源系列。
定長多位元組方案是如何來的?
顯然,字符集的擴充是主要推動力。定長一位元組編碼空間撐死了也就28=256。
這點可憐的空間拿到中國來,它能編碼的漢字量也就小學一年級的水平。
其實變長多位元組方案更早出現,比如GB2312,採用變長主要為了相容一位元組的ASCII,漢字則用兩位元組表示(這也是迫不得已的事,一位元組壓根不夠用)。隨著計算機在全世界的推廣,各種編碼方案都出來了,彼此之間的轉換也帶來了諸多的問題。採用某種統一的標準就勢在必行了,於是乎天上一聲霹靂,Unicode粉墨登場!
前面已經談到,Unicode早期是作為定長二位元組方案出來的。它的理論編碼空間一下達到了216 =65536(即64K,這裡1K=1024=210)。
對於只用到ASCII字元的人來說,比如老美,讓他們採用Unicode,多少還是有些怨言的。怎麼說呢?比如“he”兩個字元,用ASCII只需要儲存成6865(16進位制),現在則成了00680065,前面兩個毫無作用的0怎麼看怎麼礙眼,原來假設是1KB的文字檔案現在硬生生就要變成2KB,1GB的則變成2GB!
可是更糟糕的事還在後頭,在老美眼中,16位的空間已經算是天量了!要知道一位元組裡ASCII也僅僅用了一半,
後面將會看到,這一特性為各種變長方案能相容它提供了很大便利!因為最高位都是0.
而且這一半里還有不少控制符。可隨著整理工作的深入,人們發現,16位空間還是不夠!!
說起來我們的中文可是字符集裡面的大頭。“茴字有四種寫法”,上大人孔乙己的這句名言想必大家還有點印象。據說有些新近整理的漢語字典收錄的漢字數量已經高達10萬級別!我的天!這裡很多字怕是孔乙己先生也未必認得了!
那現在該咋辦呢?如果還是定長的方案,眼瞅著就要奔著四位元組而去了。
計算機界有動不動就翻倍的優良傳統,比如從16位機一下就到32位,32位一下又到了64位。當然了,這裡面是有各種權衡的,包括硬體方面的。
那些看到把6865儲存成00680065已經很不爽的人,現在你卻對他們說,“嘿,夥計,可能你需要進一步存成0000006800000065…”。容量與效率的矛盾在這時候開始激化。
容量與效率的矛盾
首先,需要明確一下:
-
所謂容量,這裡指用幾個位元組表示一個字元,顯然用的位元組越多,編碼空間越大,能表示更多不同的字元,也即容量越大。
-
所謂效率,當表示一個字元用的位元組越多,所佔用的儲存空間也就越大,換句話說,儲存(乃至檢索)的效率降低了。
如果說效率是陰,那麼容量就是陽。(我沒還沒忘記自小學語文老師就開始教導的,寫作文要遙相呼應)

我們說定長不是問題,關鍵是定幾位。定少了不夠用,定多了太浪費。定得恰到好處?可怎樣才算恰好呢?你可能會說,至少要能容納所有字元吧?但重要的事實是並非所有的字元所有的人都用得上!哪怕用得上,也可能是偶爾用上,多數時候還是用不上!
字元之間並不是平等的。用數學的語言來說,每個字元出現的機率不是等概率的,但表示它們卻用了同樣長度的位元組。
學過《資料結構與演算法》的同學可能聽過哈夫曼編碼(Huffman Coding),又稱霍夫曼編碼,就為了解決這樣的問題。
如果你對前一篇所發的莫爾斯電碼圖還有印象,你就會發現,字母e只用了一個點(dot)來編碼。
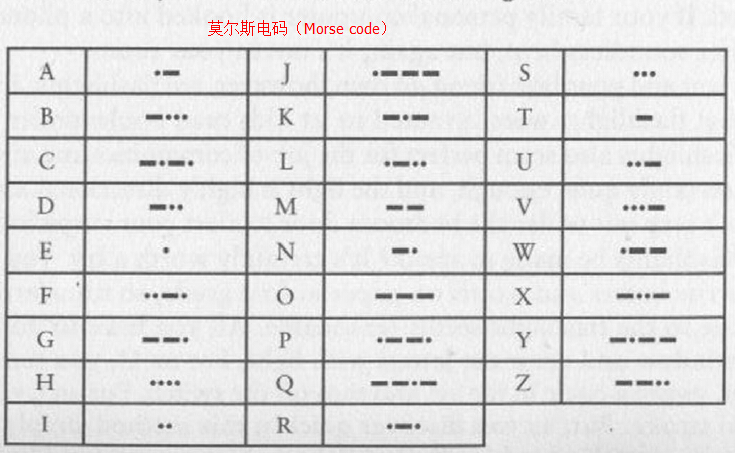
其它字母可能覺得不公平,為啥我們就要錄入那麼多個點和劃(dash)才行呢?這裡面其實是有統計規律支撐的。e出現的概率是最大的。z你能想到什麼?
zoo大概很多人能想到,厲害一點可能還能想到zebra(斑馬),Zuckerberg(扎克伯格),別翻字典!你還能想到更多不?
但含有的e的單詞則多了去了。zebra中不就有個e嗎,Zuckerberg中還兩個e呢!
在儲存圖片時,一個畫素點用幾個位來表示也是一個很值得考究的問題。你也許聽過所謂的24位真彩色,這暗示了一個畫素使用了高達3個位元組來表示。24位的空間可以表示高達1600多萬種顏色,但各種顏色的出現概率在均衡度上肯定要好於字元。
回到我們的主題,雖然很多字連我們的孔乙己先生見了都要搖頭,可還是有少部分人會用到它們,比如一些研究古漢字的學者。有些人取名還喜歡弄些偏僻字,所以很多人口登記方面的系統也有這個超大字符集的需求。
好吧,我們不能不顧這些人需求。那麼有可能在定長方案的框架下解決這一容量與效率的矛盾嗎?答案是否定的!
矛盾是事物發展的動力,下面我們將看到定長方案的簡單性使它無法緩和容量與效率的衝突,平衡這一對矛盾的努力最終推動了編碼方案從定長演變到變長,事情也由此從簡單變得複雜了。
CAP理論及擴充套件
CAP是什麼玩意?
著名的Brewer猜想說:對於現代分散式應用系統來說,資料一致性(Consistency)、系統可用性(Availability)、服務規模可分割槽性(Partitioning)三個目標(合稱CAP)不可同時滿足,最多隻能選擇兩個。
你可能要問,這貌似跟我們要討論的問題風牛馬不相及?彆著急,我們可以借鑑他的這種思想,擴充套件到我們的問題上來。
兩個維度
我們所應對的問題常常很抽象,有時藉助某些隱喻(metaphor)可以幫助我們來理解。天平就是一個很好的隱喻。
先看圖中四個天平。你叫它蹺蹺板我也沒意見,反正我沒打算吃美術這碗飯!(嗯,也許是少個了指標的緣故,希望這空指標的天平不要引發什麼異常。)

這幅圖表示的就是定長方案下容量與效率的一種約束關係。
-
容量小則效率高
-
容量大則效率低
-
容量與效率均不能讓人滿意!
-
容量與效率均較好,但這是不可能的情形!
讓我們具體解釋一下:
天平的藍色橫樑一種剛性約束的隱喻。所謂剛性,這裡簡單理解成不能變形就是了。
天平的兩端的容量與效率是它的兩個維度,或者說兩個自由度。不必去糾結物理學上的定義,簡單理解就是它們能自由上下就好了。但我們可以看到,由於受到橫樑的約束,兩個維度同時向上是不可能的!它們的相互運動呈現出彼消此長的關係。
天平可以隱喻很多,比如安全性與便利性。為什麼要我錄入驗證碼?為什麼支付寶登入與支付要用不一樣的密碼?為何輸入密碼還不夠,還要什麼手機驗證碼?這些都很不方便呀!當你覺得只有一個前門還不夠方便時你又加開了個後門,但你是否想過在方便自己的同時也“方便”了小偷呢?魚和熊掌不可兼得!
三個維度
好了,現在要再次拓展一個維度了,以使得它更像CAP理論。
還有一個維度在哪呢?我們說容量大是好,效率高是好,我們為何青睞定長方案呢?因為定長它簡單,簡單當然也是好,複雜就不好了。這就是第三個維度——簡單性(你也可以叫成複雜性,意思是一樣的)。
先深呼吸一下,讓我們再看一個圖:

首先這裡多了一個維度,天平模型不足以表達了,改用三條互成120度的直線表示這三個維度。越往裡,紅色的字代表是越差的情況;越往外,綠色的字代表是越好的情況。
圖中的約束在哪呢?就在藍色的三角形上,它有一個固定的周長,這就代表了它的約束。也許我們把它想像成一條首尾相接的固定長度的鋼絲繩更好,在圖中它只是被拉成了三角形。它可以在三個維度上運動,這讓它比天平的橫樑更靈活,但它的長度不能被拉伸,它不是橡皮繩!!
這幅圖能告訴我們什麼?
-
圖1跟圖2,當我們維持簡單性不變時,容量與效率的關係其實跟天平模型中是相似的,也是一種彼消此長的關係。
-
圖3,讓簡單性下降(換句話說就是變複雜了),才能為其它兩個維度騰出“餘量”來。即是說你要“犧牲”簡單性來調和容量與效率的矛盾。
我們能從模型得到什麼啟示呢?
一、事物的多個方面往往是相互制衡的
在前面的圖中,我們用鋼絲繩來形象隱喻這種制衡,深刻理解制衡是各種直覺與預見性的前提,當我們作出決定時,便能夠預判出可能的後果。深層次的矛盾暗示了我們有些衝突是不可避免的,同時為我們找到正確解決問題的路徑指明瞭方向。
二、制衡的局面暗示了凡事有代價,站在一個全域性上去考量,我們常常需要在各方面達成某種平衡與妥協。
舉個例子,分層會對效能有所損害,但不分層又會帶來緊耦合的問題。很多時候,架構就是關於平衡的藝術。如果我們能明白這一點,就不會為無法找到“完美”方案而苦惱。
三、複雜性從根本上是由需求所決定的。我們既要求容量大,又要求效率高,這種要求本身就不簡單,因此也無法簡單地解決。
你功能做好了,使用者說效能還不行;你效能達標了,使用者說介面還太醜。。。丫的能不能先把首付款付清了再跟哥提要求?!
為什麼談這些理論?
一方面我不想僅僅為談定變長而只談定變長,單純談理論又往往過於抽象。我想說的一點是“我們在編碼上所遇到的困境往往不過是我們在軟體開發過程中遇到的各種困境的一個縮影”。
下圖是所謂的芒德布羅集(Mandelbrot set),是分形(Fractal)理論中的一個重要概念。圖片來自wiki百科。

很多問題需要我們站在更高層面上去觀察與思考時才能發現它們的某些相似性或者說共性,這些共性被抽象出來也就形成了我們的理論。
不識廬山真面目,只緣身在此山中。——蘇軾《題西林壁》
另一方面,因為這種相似性,我們在編碼問題上得到啟示也能夠指導我們去解決其它領域的問題。我想這就是這些理論的意義所在。
調和矛盾的努力,相容考慮與變長方案的引入
通過前面分析,我們知道,定長二位元組方案無法滿足容量增長,轉向定長四位元組又會引發了效率危機,最終,Unicode編碼方案演化成了變長的UTF-16編碼方案。那麼UTF-8方案又是如何來的呢?為何不能統一成一個方案呢?搞這麼多學起來真頭痛!
我們前面提到了有一群ASCII死忠對Unicode統一使用二位元組編碼ASCII字元始終是有不滿的,現在眼見簡單的定長方案也不行了,他們中的一些大牛終於忍無可忍。既然決定拋棄定長,他們決定變得更徹底,於是這幫人揭竿而起,搗鼓出了能與ASCII相容的UTF-8方案。(注:真實歷史也許並非如此,我不是考據癖,以上敘述大家悠著看就是了,別太當真。)
如今裝個逼還分高低格,大牛不折騰,誰又知道他們是大牛呢?只是可憐了我們這些碼農,你還在苦苦研究sql,忽如一夜春風來,Nosql菊花朵朵開。(貌似應開在秋冬季?)
UTF-16用所謂的代理對(surrogate pair)來編碼U+FFFF以上的字元。在採用了變長之後,事情變得複雜了,以後我們還將繼續探討代理區,代理對,編碼單元(Code Unit)等一系列由此而來的概念。
這種變化甚至還影響到對字串長度的定義,比如,在java中,你可能認為包含一個字元的字串它的長度就是1,但現在,一個字元它的長度也可能是2!這樣的字元也無法用char來儲存了。
UTF-8因為能相容ASCII而受到廣泛歡迎,但在儲存中文方面,要用3個位元組,有的甚至要4個位元組,所以在儲存中文方面效率並不算太好,與此相對,GB2312,GBK之類用兩位元組儲存中文字元效率上會高,同時它們也都相容ASCII,所以在中英混合的情況下還是比UTF-8要好,但在國際化方面及可擴充套件空間上則不如UTF-8了。
其實GBK之後又還有GB18030標準,採用了1,2,4位元組變長方案,把Unicode字元也收錄了進來。GB18030其實是國家強制性標準,但感覺推廣並不是很給力。
目前,UTF-8方案在越來越多的地方有成為一種預設的編碼選擇的趨勢。下面是一張來自wiki百科的圖片,反映了UTF-8在web上的增長。
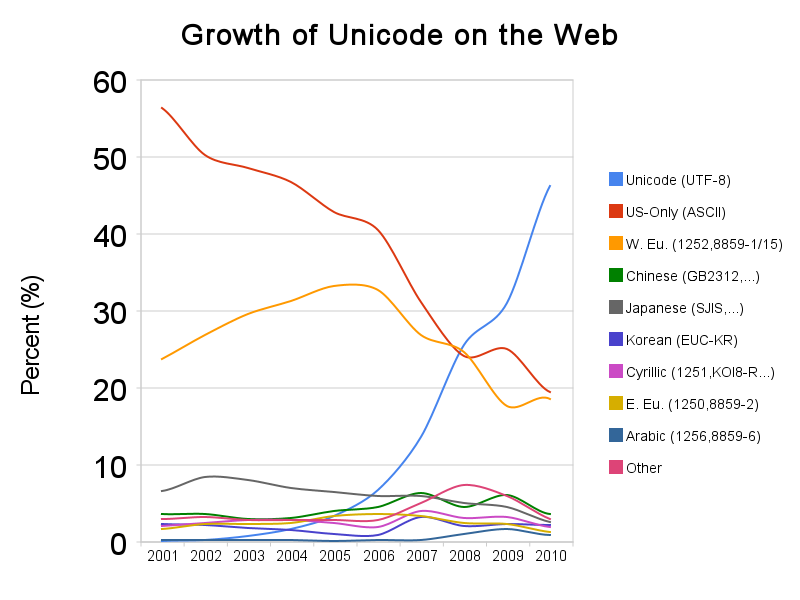
在軟體開發的各個環節強制統一採用UTF-8編碼,依舊是避免亂碼問題的最有效措施,沒有之一。技術人員也許更偏愛技術問題技術解決,但不得不承認有時行政手段更加高效!
變長(Variable-length)的編碼方案
好了,現在是時候談談變長方案的實現問題了,在這裡將通過嘗試自己設計來探討這一問題。
變長設計的核心問題自然就是如何區分不同的變長位元組,只有這樣才能在解碼時不發生歧義。
利用高位作區分
還是以前面的例子來看,我們設計了幾種變長方案
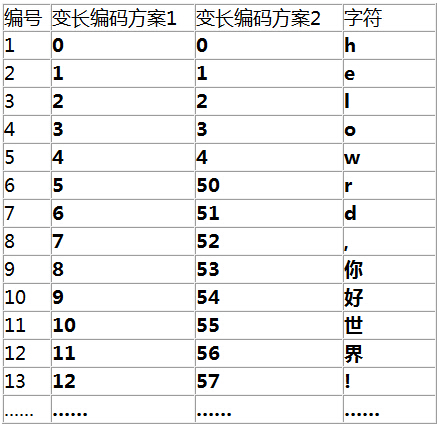
第一種方案的想法很美好,它試圖跟隨編號來自然增長,它還是可以編碼的,但在解碼時則遇到了困難。讓我們來看看。

可見,由於低位的碼位被“榨乾”了,導致單個位與多位間無法區分,所以這種方案是行不通的。
第二種方案,低位空間有所保留,5及以上的就不使用了。然後我們通過引入一條變長解碼規則:
從左向右掃描,讀到5以下數字按單個位解碼;讀到5或以上數字時,把當前數字及下一個數字兩位一起讀上來解碼。
讓我們來看個例項

這種方案避免了歧義,因此是可行的方案,但這還是非常粗糙的設計,如果我們想在這串字元中搜索“o”這個字元,它的編碼是3,這樣在匹配時也會匹配上53中的3,這種設計會讓我們在實現匹配演算法時困難重重。我們可以在跟隨位上也完全捨棄低位的編碼,比如以55,56,57,58,59,65,66…這樣的形式,但這樣也會損失更多的有效編碼位。
GB2312,GBK,UTF-8的基本思想也是如此。下面也簡單示例一下(0,1代表固定值;黑色的X代表可以為0或1,為有效編碼位):

注:GBK第二位元組最高位也可能為0.
其實關鍵就在於用高位保留位來做區分,缺點就是有效編碼空間少了,可以看到三位元組的UTF-8方式中實際有效的編碼空間只剩兩位元組。但這是變長方案無法避免的。
我們還可以看到,由於最高位不同,多位元組中不會包含一位元組的模式。對於UTF-8而言,二位元組的模式也不會包含在三位元組模式中,也不會在四位元組中;三位元組模式也不會在四位元組模式中,這樣就解決上面所說的搜尋匹配難題。你可以先想想看為什麼,下面的圖以二,三位元組為例說明了為什麼。

可以看到,由於固定位上的0和1的差別,使得二位元組既不會與三位元組的前兩位元組相同,也不會它的後兩位元組相同。其它幾種情況原理也是如此。
利用代理區作區分
讓我們再來看另一種變長方案。用所謂代理區來實現。

這裡挖出70-89間的碼位,形成橫豎10*10的編碼空間,使得能再擴充套件100個編碼空間。原來2位100個空間損失了20還剩80,再加上因此而增加的100個空間,總共是180個空間。這樣一種變長方式也就是UTF-16所採用的,具體的實現我們留待後面再詳述。
好了,關於定變長的問題,就講到這裡,下一篇將繼續探討前面提及但還未深入分析的一些問題。
相關推薦
字符集編碼 定長與變長
☯,首先,這並不是圖片,這是一個unicode字元,Yin Yang,即陰陽符,碼點為U+262F。如果你的瀏覽器無法顯示,可以檢視這個連結http://www.fileformat.info/info/unicode/char/262f/index.htm。這與我們要討論的主題有何關係呢?下面我會談到。 連
深入圖解字符集與字符集編碼(三)——定長與變長(出處:http://my.oschina.net/goldenshaw/blog/307708)
☯,首先,這並不是圖片,這是一個unicode字元,Yin Yang,即陰陽符,碼點為U+262F。如果你的瀏覽器無法顯示,可以檢視這個連結http://www.fileformat.info/info/unicode/char/262f/index.htm。這與我們要討論的主題有何關係呢?下面我會談到。
sqlserver中變長字串與定長字串
最近做一個工廠的自動化專案使用到sqlserver,查詢其中某個值的時候返回的是空值,研究了一下發現該值的型別是nchar,定長unicode編碼,網上查了下nchar和nvarchar的區別,nvarchar型別儲存時會按字長實際長度兩倍儲存,進一步通過程式驗
基於上下文的自適應變長編碼CAVLC原理與流程
CAVLC -CAVLC概念 AVLC的全稱是Context-Adaptive Varialbe-Length Coding,即基於上下文的自適應變長編碼。CAVLC的本質是變長編碼,它的特性主要體現在自適應能力上,CAVLC可以根據已編碼句法元素的情況動態的選擇編碼中使用
varint變長編碼
變長編碼,對資料進行壓縮來減少儲存空間,採用CRC進行資料正確性校驗。 傳統的integer是以32位來表示的,儲存需要4個位元組,當如果整數大小在256以內,那麼只需要用一個位元組就可以儲存這個整數,這樣就可以節省3個位元組的儲存空間。 每個位元組,我們只使用低7位,最高的一位作為
關於動態記憶體分配和陣列的選用(變長選malloc,定長選陣列)
結論在最後,可直接看最後。 工作中遇到了一個這樣的問題。 需要在 一個結構體後面 繫結一個變數,但不能對原結構體進行修改。 比如說: Struct ss{ Int a; Char b; Float c; }; 在這個結構體內部不變的情況下,需要在其後繫結一個 double
UTF8編碼-變長編碼
我相信很多很我一樣做挨踢業的人在初期都免不了遇上亂碼之類的問題,相信在很多次之後都會對編碼有些瞭解,其實編碼和很多這方面的知識一樣,你乍一看他挺繁瑣,晦澀難懂。不過只要你理解了其中的必然性,從制定者的角度去考慮一些東西,就會發現一切都順理成章。 首先要說明的是我們所
Scala陣列,定長陣列和變長陣列,增強for迴圈,until用法,陣列轉換,陣列常用演算法,陣列其它操作
1. 陣列 1.1. 定長陣列和變長陣列 package cn.toto.scala //可變陣列的長度時需要引入這個包 import scala.collection.mutable.A
WPF學習筆記(2)——動畫效果按鈕變長
anim aud tor col log 筆記 wpf style 分享 說明(2017-6-12 11:26:48): 1. 視頻教程裏是把一個按鈕點擊一下,慢慢變長: 註意幾個方面: (1)RoutedEvent="Button.Click",這裏面要用Button,是
變長數組_相乘取結果
tdi class pri -a mod main 輸出 array objc //變長數組 相乘取結果 #include <stdio.h> int main(void){ // int array_01[3][4] = {1,2,3,4,5,
C語言變長參數的認識以及宏實現
獲取 指針 tar form pos 不定 定義類 ont 認識 1.認識 變長參數是C語言的特殊參數形式。比如例如以下函數聲明: int printf(const char *format, ....); 如此的聲明表明,printf函數除了第一個參數類型為
O(n log n)求最長上升子序列與最長不下降子序列
clas 每一個 for spa pen pan close color style 考慮dp(i)表示新上升子序列第i位數值的最小值.由於dp數組是單調的,所以對於每一個數,我們可以二分出它在dp數組中的位置,然後更新就可以了,最終的答案就是dp數組中第一個出現正無窮的位
java中重載變長參數方法
變參 style eth tor 多個 col 變長參數 形參 out 一、測試代碼 package com.demo; public class Interview { public static void test(int i){ System
變長數組(variable-length array,VLA)
初始 比較 blog turn 允許 正是 += pan 代碼 處理二維數組的函數有一處可能不太容易理解,數組的行可以在函數調用的時候傳遞,但是數組的列卻只能被預置在函數內部。例如下面這樣的定義: 1 #define COLS 4 2 int sum3d(int
最長公共子串與最長公共子序列
兩個 ring 數組存儲 src str int sdf range div 一、最長公共子串(Longest Common Substring) 遍歷的時候用一個二維數組存儲相應位置的信息,如果兩個子串1與子串2相應位置相等:則看各自前一個位置是否相等,相等則該位置值B[
(一)預定義宏、__func__、_Pragma、變長參數宏定義以及__VA_ARGS__
-s 只需要 需要 成對 位置 以及 fin 編譯 一次 作為第一篇,首先要說一下C++11與C99的兼容性。 C++11將 對以下這些C99特性的支持 都納入新標準中: 1) C99中的預定義宏 2) __func__預定義標識符 3) _Pragma操作符 4) 不
設計表的時候,對變長字段長度選擇的一點思考
eight CA serve 可能 執行 滿足 ide ont val 不管是在MSSQL還是MySQL或者Oracle,變長字段的長度衡量都是要經常面對的。對於一個變長的字段,在滿足業務的情況下(其實所謂的滿足業務是一個比較模糊的東西),到底是選擇varchar(50)還
介紹C++11標準的變長參數模板
class 情況下 展開 containe printf 一個 structs .cpp 實例 轉自:https://www.cnblogs.com/zenny-chen/archive/2013/02/03/2890917.html 目前大部分主流編譯器的最新版本均
大端BigEndian、小端LittleEndian與字符集編碼
title 不同的 box clear switch 最小數 name 文件頭部 存儲 BigEndian(大端):低字節在高內存地址 LittleEndian(小端):低字節在低內存地址 也就是看低字節在高內存地址還是低內存地址,也就是看低字節在前還是高字節在
C語言變長數組不能作為全局變量聲明
結構 執行 語言 ext ati stat extern 限制 使用 C99定義的這種變長數組的使用是有限制的,不能像在C++等語言中一樣自由使用 變長數組有以下限制: 1、變長數組必須在程序塊的範圍內定義,不能在文件範圍內定義變長數組; 2、變長數組不能用static或者