
CSDN機器學習筆記七 實戰樣本不均衡資料解決方法
信用卡檢測案例
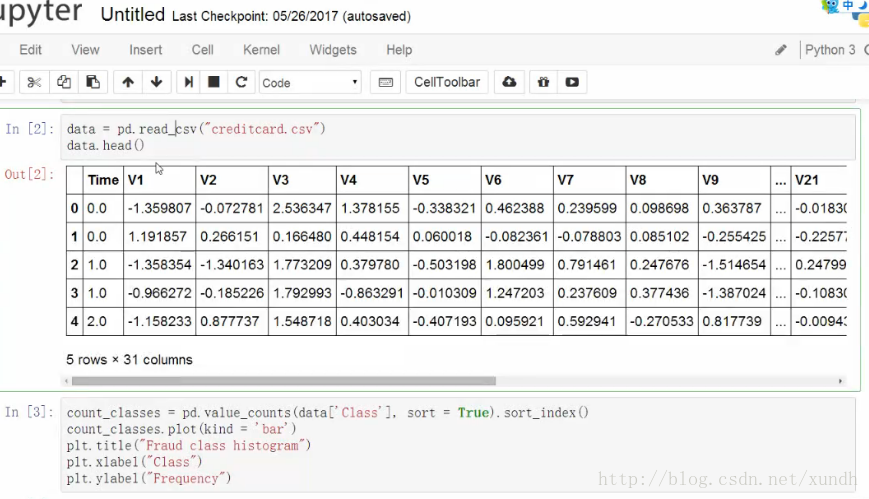
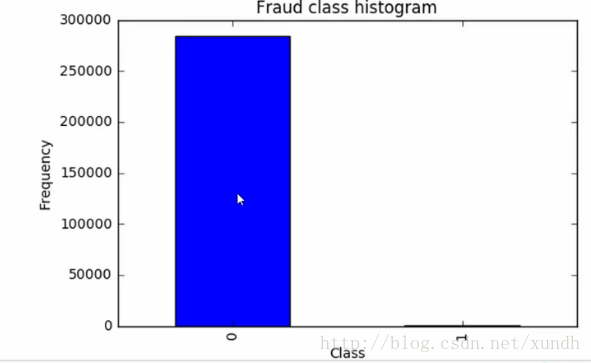
原始資料:0特別多,1特別少——樣本不均衡。
要麼讓0和1一樣多,要麼讓0和1一樣少。
1.下采樣
對於資料0和1,要變為同樣少——在0裡選擇和1一樣多資料。
from sklearn.preprocessing import StandardScaler
data['normAmount']=StandardScaler().fit_transform(data['Amount'].reshape(-1,1)
data = data.drop(['Time','Amount'],axis=1)
data.head()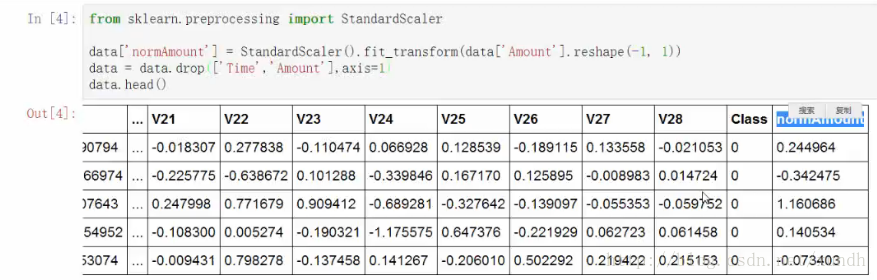
讓所有資料的取值範圍儘量相同。
- reshape(-1,1) , -1是個佔位符。

在正常index隨機選擇多少個。
under_sample_indices=np.concatenate([fraud_indices,random_normal_indices]);
通過索引定位資料
under_sample_data=data.iloc[under_sample_indices,:]
這樣就做好了下采樣資料集。
交叉驗證
假設現在拿到1筆資料,那首先我們要把資料分成2部分,一部分train(訓練),一部分test(測試)。
一般比例是train:test=0.9:0.1
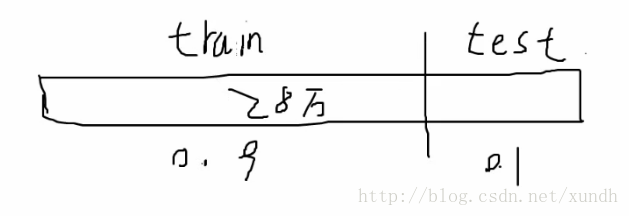
第1步 訓練集再分成3份,
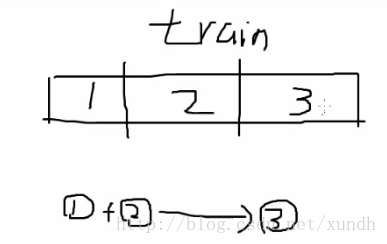
1+2訓練,3作為驗證。
即調引數是在訓練資料中拿一部分作驗證。
第2步 2+3作模型,3作驗證
第3步 1+3作模型,2作驗證
把三次的結果相加 / 3作為最終結果。
實際中可以把資料集切成更多份進行交叉驗證。
程式碼示例:
from sklearn.cross_validation import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=0);
30%作訓練集,random_state復現的結果(?)
print("Number transactions train dataset: " ,len(X_train))
X_train_ 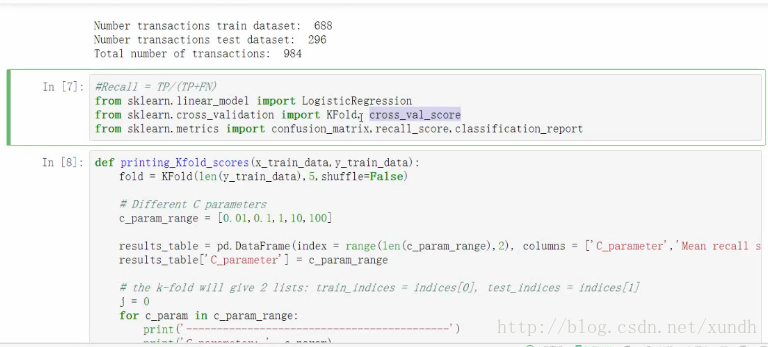
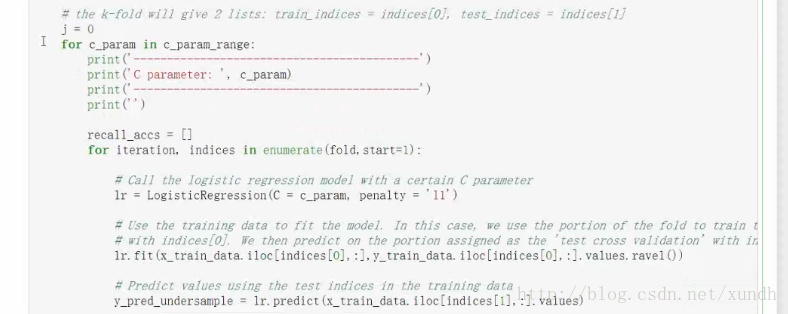
後一個for是交叉驗證。
lr = LogisticRegression(C= c_param,penalty = ‘l1’) 分類器,懲罰力度傳進來 。
lr.fit(x_train_data.iloc[indices[0],:],y_train_data.iloc[indices[0],:].values.rave1()
訓練模型
接下來預測
y_pred_undersample = lr.predict(x_train_data.iloc[indices[1],:].values)
拿測試樣本預測
recall_acc= recall_score(y_train_data.iloc[indices[1],:].values,y_pred_undersample)
recall_accs.append(recall_acc)
列印結果:
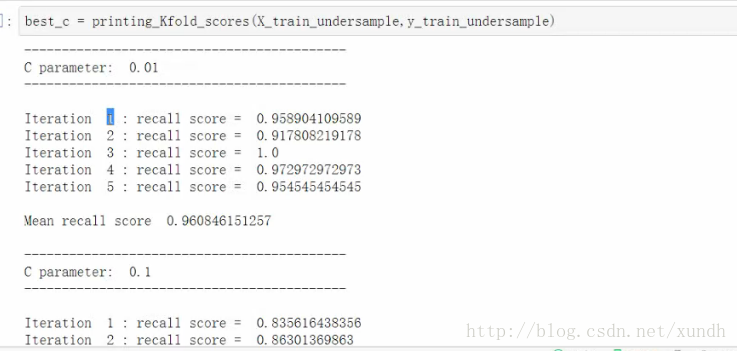
得到5次recall值,計算平均值:
Mean recall score 0.960846151257
目前是驗證級的結果。
C parameter: 0.1的時候
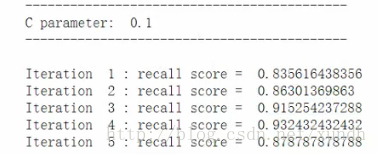
Mean recall score 0.885020…
引數會對結果有非常大的影響 。
模型評估標準
精度指標
recall指標=TP/(TP+FN)
TP:

fold=KFold(
資料分幾份。
懲罰項
X[1,1,1,1]
W1=[1,0,0,0]
W2=[1/4,1/4,1/4,1/4]
X*W1T=1
X*W2T=1
對W1,X後面的三個特徵沒有作用。
而對W2,每個特徵都會考慮進來 。
W2會更好,綜合考慮各個特徵。 要指定一個懲罰引數,對W1進行懲罰。
L2加平方項,W2
L1加絕對值,|W|。
選擇懲罰項比較小的方式。最終目標要把正則化懲罰項加上。
L1 L2前加λ懲罰係數,λ可以取不同的值。什麼樣的懲罰係數好呢?
Confusion matrix 混淆矩陣
對比真實值與預測值的結果:
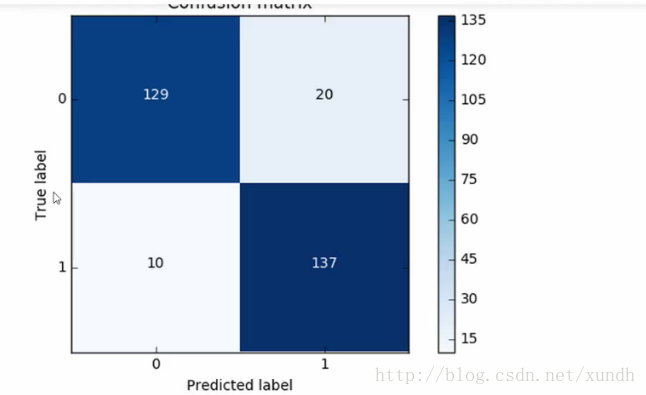
現在混淆矩陣顯示的是測試集的結果。
下週要講怎麼解決誤殺的問題。主要是下采樣策略引起的。主要是過取樣策略。
如果直接:
best_c = printing_Kfold_scores(Xtrain.y_train)
看交叉驗證的結果,recall值會很小。
2. 過取樣
邏輯迴歸:預值概念
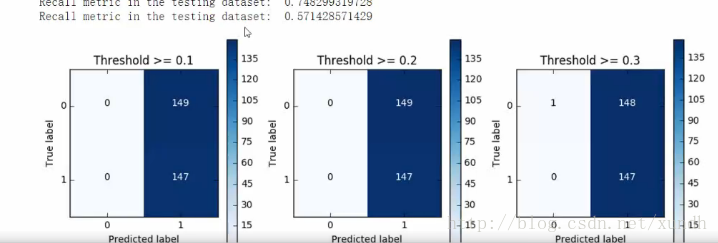
預值對recall值的影響

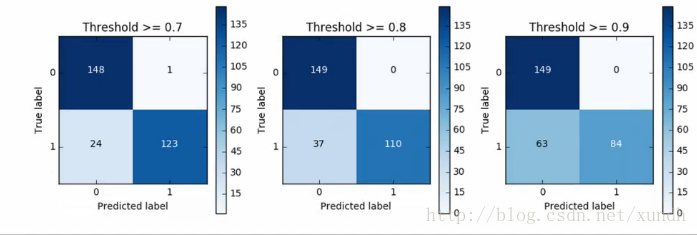
精度與recall值的權衡要視具體任務來定。
smote演算法
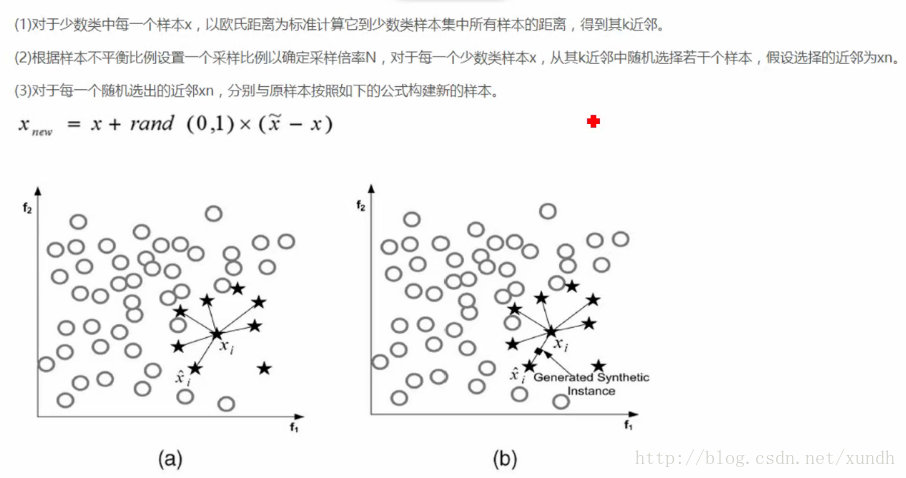
對於少數類中每一個樣本x,以歐氏距離為標準計算它到少數類樣本集中所有樣本的距離,得到其k近鄰。
安裝 pip install imblearn
演算法示例:
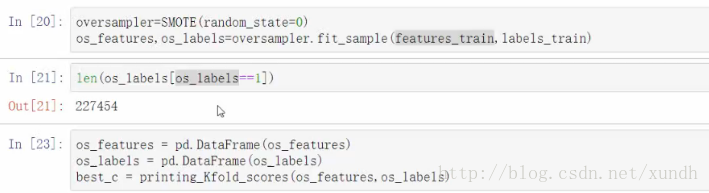
目前混淆矩陣
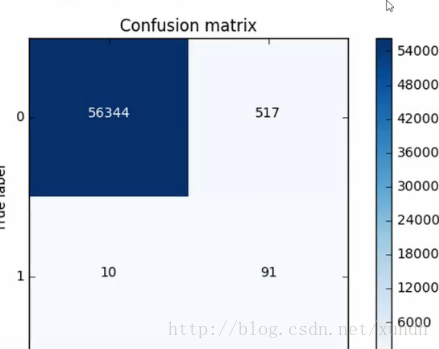
誤殺大約1%,recall稍高一些。
相關推薦
CSDN機器學習筆記七 實戰樣本不均衡資料解決方法
信用卡檢測案例 原始資料:0特別多,1特別少——樣本不均衡。 要麼讓0和1一樣多,要麼讓0和1一樣少。 1.下采樣 對於資料0和1,要變為同樣少——在0裡選擇和1一樣多資料。 from sklearn.preprocessing imp
斯坦福2014機器學習筆記七----應用機器學習的建議
訓練集 image 是的 bsp 推斷 學習曲線 正則 偏差 wid 一、綱要 糾正較大誤差的方法 模型選擇問題之目標函數階數的選擇 模型選擇問題之正則化參數λ的選擇 學習曲線 二、內容詳述 1、糾正較大誤差的方法 當我們運用訓練好了的模型來做預測時
CSDN機器學習筆記一 概述、線性迴歸
一、課程知識點 講師:唐宇迪 本次課程 1.系列課程環境配置 2.機器學習概述 3.線性迴歸演算法原理推導 4.邏輯迴歸演算法原理 5.最優化問題求解 6.案例實戰梯度下降 一、機器學習處理問題過程及常用庫 1. 機
機器學習筆記(七)貝葉斯分類器
7.貝葉斯分類器 7.1貝葉斯決策論 貝葉斯決策論(Bayesiandecision theory)是概率框架下實施決策的基本方法。對分類任務來說,在所有相關概率都已知的理想情形下,貝葉斯決策論考慮如何基於這些概率和誤判損失來選擇最優的類別標記。這其實是關係到兩個基本概念:
CSDN機器學習筆記十二 k-近鄰演算法實現手寫識別系統
本文主要內容來自《機器學習實戰》 示例:手寫識別系統 為了簡單起見,這裡構造的系統只能識別數字0到9。需要識別的數字要使用圖形處理軟體,處理成具有相同的色彩和大小:32*32 黑白影象。為了方便理解,這裡將影象轉換成文字格式。 1. 流程 收集
斯坦福CS229機器學習筆記-Lecture8- SVM支援向量機 之核方法 + 軟間隔 + SMO 演算法
作者:teeyohuang 本文系原創,供交流學習使用,轉載請註明出處,謝謝 宣告:此係列博文根據斯坦福CS229課程,吳恩達主講 所寫,為本人自學筆記,寫成部落格分享出來 博文中部分圖片和公式都來源於CS229官方notes。
深度學習樣本不均衡問題解決
在深度學習中,樣本不均衡是指不同類別的資料量差別較大,利用不均衡樣本訓練出來的模型泛化能力差並且容易發生過擬合。對不平衡樣本的處理手段主要分為兩大類:資料層面 (簡單粗暴)、演算法層面 (複雜) 。資料層面取樣(Sample)資料重取樣:上取樣或者下采樣上取樣下采樣使用情況資
go微服務框架kratos學習筆記七(kratos warden 負載均衡 balancer)
目錄 go微服務框架kratos學習筆記七(kratos warden 負載均衡 balancer) demo demo server demo client 池 dao
Quartz2.x學習筆記(四):spring注入異常解決方法
在使用Quartz與spring整合時,有時需要在Job任務類裡注入spring的bean。如下: 那麼問題來了,當你啟動專案時,會發現報了空指標異常: 查閱資料以及百度之後,終於找到一個解決
OpenGL學習筆記(三)---FreeImage顏色顯示錯亂的解決方法
一、簡介 看Nehe的教程學習OpenGL看到載入圖片時用到了FreeImage,跟著寫了下,發現圖片顏色是錯亂的。 如圖: 除錯的時候發現自己的少了一段程式碼: if ((imageType == FIT_BITMAP) && (Free
文字分類問題中資料不均衡的解決方法的探索
資料傾斜是資料探勘中的一個常見問題,它嚴重影響的資料分析的最終結果,在分類問題中其影響更是巨大的,例如在之前的文字分類專案中就遇到類別文字集合嚴重不均衡的問題,本文主要結合專案實驗,介紹一下遇到資料不均衡問題時的常見解決方法。 資料傾斜的解決方法 1.過取樣和欠
[轉載] Cassandra 負載不均衡 與 解決方法
最近在看Cassandra,但自打配起一個集群后,負載就不均衡了。 AddressStatusStateLoadOwnsToken13415454752010178837975631657016234477410.20.223.115UpNormal138.43KB32
機器學習筆記(十五):TensorFlow實戰七(經典卷積神經網路:VGG)
1 - 引言 之前我們介紹了LeNet-5和AlexNet,在AlexNet發明之後,卷積神經網路的層數開始越來越複雜,VGG-16就是一個相對前面2個經典卷積神經網路模型層數明顯更多了。 VGGNet是牛津大學計算機視覺組(Visual Geometry Group)和Google
機器學習筆記(十七):TensorFlow實戰九(經典卷積神經網路:ResNet)
1 - 引言 我們可以看到CNN經典模型的發展從 LeNet -5、AlexNet、VGG、再到Inception,模型的層數和複雜程度都有著明顯的提高,有些網路層數更是達到100多層。但是當神經網路的層數過高時,這些神經網路會變得更加難以訓練。 一個特別大的麻煩就在於訓練的時候會產
《機器學習實戰》學習筆記七:Logistics迴歸(梯度上升法)
1 Logistics迴歸概念 迴歸是指將一對資料擬合為一條直線的過程,而Logistics迴歸則是將回歸用於分類,其主要思想為:根據現有的資料對分類邊界線建立迴歸公式,依次為依據進行分類,在這裡最關鍵的一步是尋找最佳的擬合引數,這一步將會用到一些最優化的方法
(筆記)斯坦福機器學習第七講--最優間隔分類器
滿足 優化 最終 clas 定義 mar 擴展 strong play 本講內容 1.Optional margin classifier(最優間隔分類器) 2.primal/dual optimization(原始優化問題和對偶優化問題)KKT conditions(KK
機器學習筆記(十一): TensorFlow實戰三(MNIST數字識別問題)
1 - MNIST數字識別問題 前面介紹了這樣用TensorFlow訓練一個神經網路模型和主要考慮的問題及解決這些問題的常用方法。下面我們用一個實際的問題來驗證之前的解決方法。 我們使用的是MNIST手寫數字識別資料集。在很多深度學習教程中,這個資料集都會被當做一個案例。 1.1
機器學習筆記(十):TensorFlow實戰二(深層神經網路)
1 - 深度學習與深層神經網路 深度學習的精確定義為:“一類通過多層非線性變換對高複雜性資料建模演算法的集合” 因此,多層神經網路有著2個非常重要的特性 多層 非線性 1.1 - 線性模型的侷限性 線上性模型中,模型的輸出為輸入的加權和,假設一
機器學習筆記(九):Tensorflow 實戰一 (Tensorflow入門)
1 - TsensorFlow計算模型 ——計算圖 1.1- 計算圖的概念 計算圖是TensorFlow中最基本的一個概念,TensorFlow中的所有計算都會被轉化為計算圖上的節點。 在TensorFlow中,張量可以簡單地理解為多為陣列。如果說TensorFlow的第一個詞T
機器學習筆記(七):K-Means
1 - 前言 之前我們學習的演算法均為監督學習演算法,而K-means是我們所學習的第一個無監督學習演算法。所以首先讓我們瞭解一下監督學習和無監督學習的區別 1.1 - 監督學習(supervised learning) 從給定的訓練資料集中學習出一個函式(模型引數),當新的資料