
SSD(Single Shot MultiBoxDetector)目標檢測
借鑑YOLO:直接回歸bbox和分類概率;
借鑑Faster R-CNN:使用anchor提升識別準確度;
借鑑FPN:加入金字塔的檢測方式;
結合兩者優點,提高速度上超過YOLO,精度上與Faster R-CNN媲美;
網路結構
base network
採用VGG19提取卷積特徵,在後面新增一系列卷積層,進行多尺度檢測,低層特徵保留影象的細節資訊,用於檢測較小的目標,高層特徵用於檢測較大的目標。如下圖所示:
在base network基礎上新增輔助結構:
1. 多尺度預測:在base network後,新增一些卷積層,這些層的大小逐漸減小,可以進行多尺度預測
2. 在特徵圖上預測: 在特徵圖的每個位置預測K個box。對於每個box,預測C個類別得分,以及相對於default bounding box的4個偏移值,這樣需要(C+4)*k個預測器,在m*n的特徵圖上將產生(C+4)*k*m*n個預測值。這裡,default bounding box類似於FasterRCNN中anchors。


而SSD採用了特徵金字塔結構進行檢測,即檢測時利用了conv4-3,conv-7(FC7),conv6-2,conv7-2,conv8_2,conv9_2這些大小不同的feature maps,在多個feature maps上同時進行softmax分類和位置迴歸。
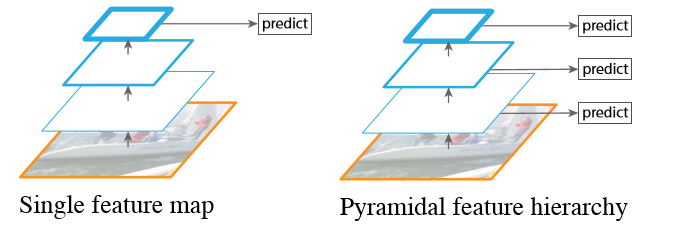
SSD在不同的特徵層中考慮不同的尺度,RPN在一個特徵層考慮不同的尺度。
anchor box
作為一些目標的候選框,後續通過softmax分類+bounding box regression獲得真實目標的位置。
生成規則:以feature map上每個點的中點為中心(offset=0.5),生成一些列同心的prior box(然後中心點的座標會乘以step,相當於從feature map位置映射回原圖位置)
長寬規則
正方形:最小正方形:min_size,最大正方形邊長:
長方形:對於每個aspect ratio,生成2個長方形,長寬分別為

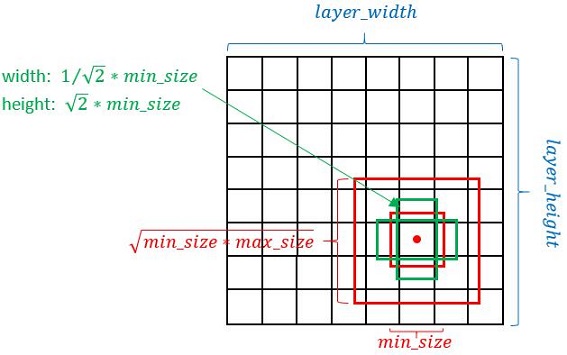
確定min_size和max_size
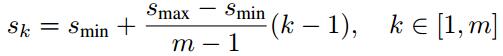
其中:m是使用feature map的數量;
第一層feature map對應的min_size=S1,max_size=S2;第二層min_size=S2,max_size=S3;其他類推。在原文中,Smin=0.2,Smax=0.9。
採用不同的aspect ratios:{1,2,3,1/2,1/3}
使用anchor box檢測
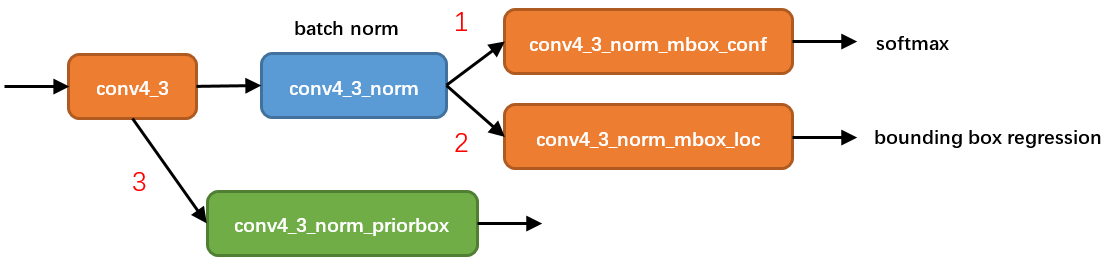
在conv4_3 feature map網路pipeline分為了3條線路:
1. 經過一次batch norm+一次卷積後,生成了[1, num_class*num_priorbox, layer_height, layer_width]大小的feature用於softmax分類目標和非目標(其中num_class是目標類別,SSD 300中num_class = 21)。
2. 經過一次batch norm+一次卷積後,生成了[1, 4*num_priorbox, layer_height, layer_width]大小的feature用於bounding box regression(即每個點一組[dxmin,dymin,dxmax,dymax]。
3. 生成了[1, 2, 4*num_priorbox]大小的prior box blob,其中2個channel分別儲存prior box的4個點座標和對應的4個variance

還有一個細節就是上面prototxt中的4個variance,這實際上是一種bounding regression中的權重。在圖4線路(2)中,網路輸出[dxmin,dymin,dxmax,dymax],即對應下面程式碼中bbox;
decode_bbox->set_xmin(
prior_bbox.xmin() + prior_variance[0] * bbox.xmin() * prior_width);
decode_bbox->set_ymin(
prior_bbox.ymin() + prior_variance[1] * bbox.ymin() * prior_height);
decode_bbox->set_xmax(
prior_bbox.xmax() + prior_variance[2] * bbox.xmax() * prior_width);
decode_bbox->set_ymax(
prior_bbox.ymax() + prior_variance[3] * bbox.ymax() * prior_height); 計算所有特徵輸出
綜合6個featuremap的結果:使用Permute,Flatten和Concat層進行計算,計算方式如下:交換維度->展開->連線
Permute
作用:交換資料維度
bottom blob = [batch_num, channel, height, width]
top blob = [batch_num, height, width, channel]
Flatten
作用:將四維展開成兩維;
bottom blob = [batch_num, height, width, channel]
top blob = [batch_num, height*width*channel]
Concat
作用:拼接
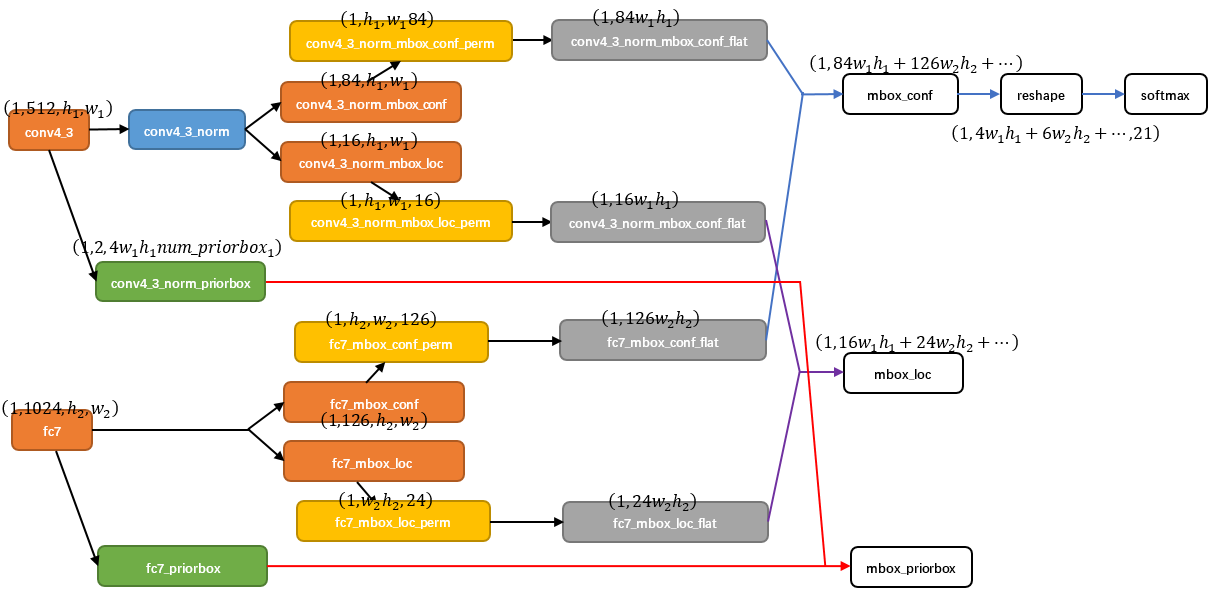
以conv4_3和fc7為例:
- 對於conv4_3 feature map,conv4_3_norm_priorbox(priorbox層)設定了每個點共有4個prior box。由於SSD 300共有21個分類,所以conv4_3_norm_mbox_conf的channel值為num_priorbox * num_class = 4 * 21 = 84;而每個prior box都要回歸出4個位置變換量,所以conv4_3_norm_mbox_loc的caffe blob channel值為4 * 4 = 16。
- fc7每個點有6個prior box,其他feature map同理。
- 經過一系列圖7展示的caffe blob shape變化後,最後拼接成mbox_conf和mbox_loc。而mbox_conf後接reshape,再進行softmax(為何在softmax前進行reshape,Faster RCNN有提及)。
- 最後這些值輸出detection_out_layer,獲得檢測結果。
訓練
- 損失函式
總損失函式:loc(位置損失)+conf(置信度損失)
loc損失函式:
其實就是計算GTbox和prebox相對於anchor的座標值,相當於歸一化,分別對座標值對應相減後求smoothL1損失。
:
置信度損失:
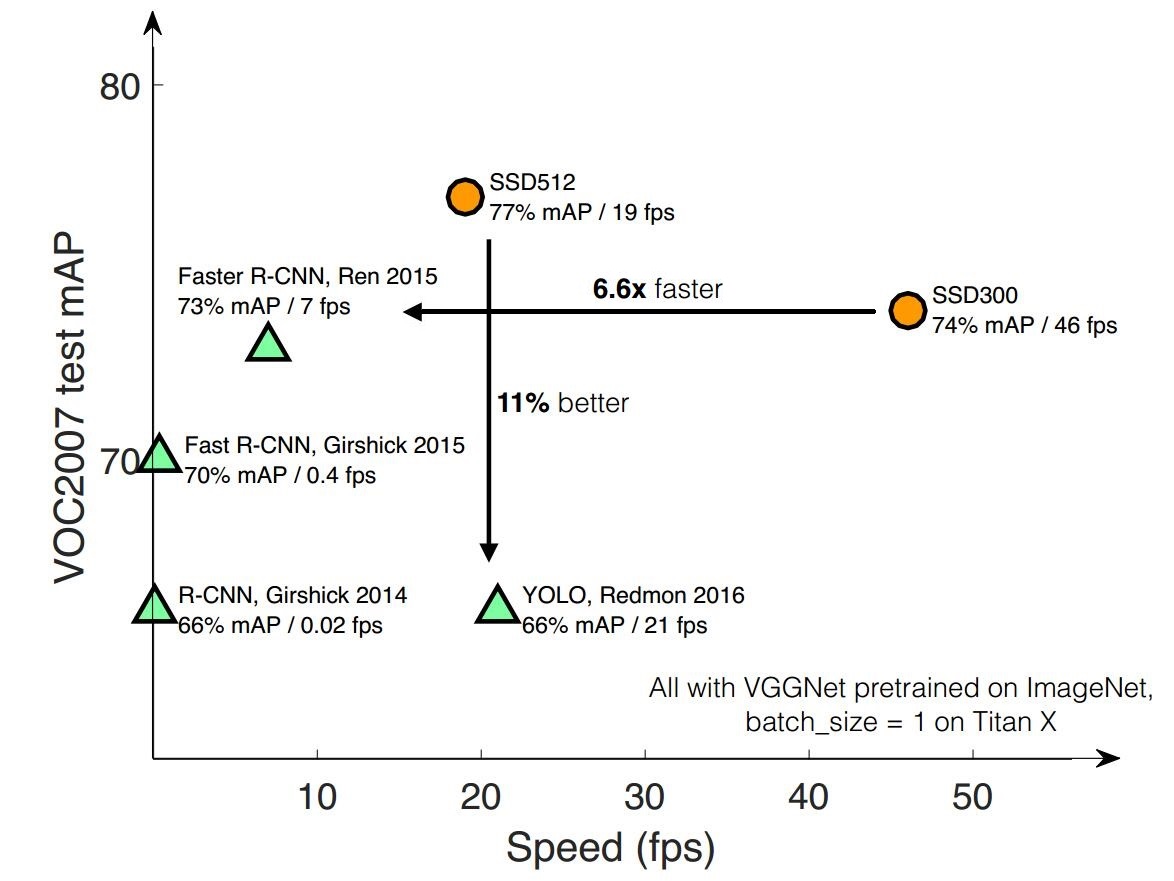
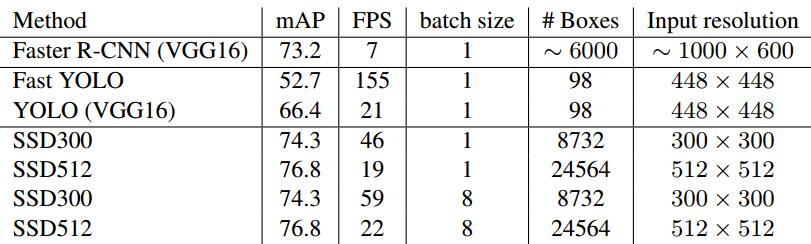
SSD對小目標檢測效果不好,在mAP高於YOLO和Faster RCNN,速度低於YOLO,如下圖所示:
- GT和anchor匹配策略:
將每個groundtruth box與具有最大jaccard overlap的defalult box進行匹配, 這樣保證每個groundtruth都有對應的default box;並且,將每個defalut box與任意ground truth配對,只要兩者的jaccard overlap大於某一閾值,本文取0.5,這樣的話,一個groundtruth box可能對應多個default box。
- Hard negative mining
值得注意的是,一般情況下negative default boxes數量>>positive default boxes數量,直接訓練會導致網路過於重視負樣本,從而loss不穩定。所以需要採取:所以SSD在訓練時會依據confidience score排序default box,挑選其中confidience高的box進行訓練,控制positive:negative=1:3
- Hard negative mining
- Data augmentation
進資料增廣,即每一張訓練影象,隨機的進行如下幾種選擇:
使用原始的影象
取樣一個 patch,與物體之間最小的 jaccard overlap 為:0.1,0.3,0.5,0.7 或 0.9
隨機的取樣一個 patch
取樣的 patch 是原始影象大小比例是[0.1,1],aspect ratio在1/2與2之間。當 groundtruth box 的 中心(center)在取樣的patch中時,保留重疊部分。在這些取樣步驟之後,每一個取樣的patch被resize到固定的大小,並且以0.5的概率隨機的 水平翻轉(horizontally flipped)。
- GT和anchor匹配策略:
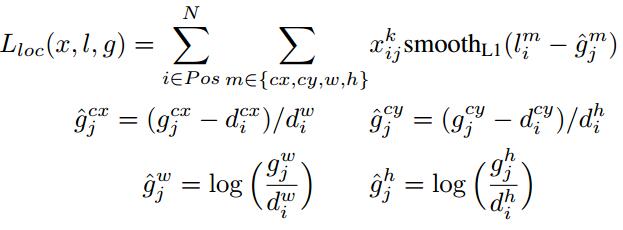
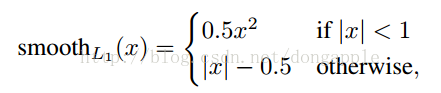
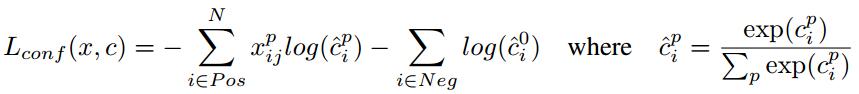
優缺點
優點:執行速度可以和YOLO媲美,檢測精度可以和Faster RCNN媲美。
缺點:
1. 需要人工設定prior box的引數(min_size,max_size和aspect_ratio)。網路中prior
box的基礎大小和形狀不能直接通過學習獲得,而是需要手工設定。而網路中每一層feature使用的prior
box大小和形狀恰好都不一樣,導致除錯過程非常依賴經驗。
2. 對小目標的recall一般。雖然採用了pyramdial feature hierarchy的思路,但是對小目標的recall依然一般,並沒有達到碾壓Faster RCNN的級別。作者認為,這是由於SSD使用conv4_3低階feature去檢測小目標,而低階特徵卷積層數少,存在特徵提取不充分的問題。
參考資料
相關推薦
SSD(Single Shot MultiBoxDetector)目標檢測
借鑑YOLO:直接回歸bbox和分類概率; 借鑑Faster R-CNN:使用anchor提升識別準確度; 借鑑FPN:加入金字塔的檢測方式; 結合兩者優點,提高速度上超過YOLO,精度上與Faster R-CNN媲美; 網路結構 base
SSD+caffe︱Single Shot MultiBox Detector 目標檢測+fine-tuning(二)
承接上一篇SSD介紹:SSD+caffe︱Single Shot MultiBox Detector 目標檢測(一) 如果自己要訓練SSD模型呢,關鍵的就是LMDB格式生成,從官方教程weiliu89/caffe來看,寥寥幾行code,但是前面的資料
SSD+caffe︱Single Shot MultiBox Detector 目標檢測(一)
作者的思路就是Faster R-CNN+YOLO,利用YOLO的思路和Faster R-CNN的anchor box的思想。 . 0 導讀 (本節來源於BOT大賽嘉賓問答環節 ) SSD 這裡的設計就是導致你可以一下子可以檢測 8 張圖,Faster
SSD(single shot multibox detector)算法及Caffe代碼詳解[轉]
作者 3.4 pdf 論文 做了 對比度調整 覆蓋 eccv 添加 這篇博客主要介紹SSD算法,該算法是最近一年比較優秀的object detection算法,主要特點在於采用了特征融合。 論文:SSD single shot multibox detector論文鏈接:h
SSD(single shot multibox detector)演算法及Caffe程式碼詳解
這篇部落格主要介紹SSD演算法,該演算法是最近一年比較優秀的object detection演算法,主要特點在於採用了特徵融合。 演算法概述: 本文提出的SSD演算法是一種直接預測bounding box的座標和類別的object detection
SSD(single shot multibox detector)演算法及Caffe程式碼詳解(轉載)
這篇部落格主要介紹SSD演算法,該演算法是最近一年比較優秀的object detection演算法,主要特點在於採用了特徵融合。 演算法概述: 本文提出的SSD演算法是一種直接預測bounding box的座標和類別的object detection演算法,沒有生
Detection:SSD(single shot multibox detecter)
ssd這篇感覺很工程,主要的工作我覺得有兩個: 1.從多層fm上提取bbox,相當於一個multi scale的操作。值得注意的是,首先越靠近bottom越底層的fm在細節表達上做得越好,高層的fm會學習出分類這種概括性的表達,原文中加上最高層的bbox甚至會比去掉這一層效
SSD(single shot multibox detector)
voc 我們 aspect reference com any detect sca 自己 SSD,全稱Single Shot MultiBox Detector,是Wei Liu在ECCV 2016上提出的一種目標檢測算法,截至目前是主要的檢測框架之一,相比Faster
SSD:Single Shot MultiBox Detector 心得 (持續更新中。。。)
對於文章程式碼的一些理解, 以此來省去用A4紙記錄的苦惱 SSD文章連結:http://arxiv.org/pdf/1512.02325v2.pdf SSD程式碼連結:https://github.c
帶你深入AI(4)- 目標檢測領域:R-CNN,faster R-CNN,yolo,SSD, yoloV2
系列文章,請多關注 Tensorflow原始碼解析1 – 核心架構和原始碼結構 自然語言處理1 – 分詞 帶你深入AI(1) - 深度學習模型訓練痛點及解決方法 帶你深入AI(2)- 深度學習啟用函式,準確率,優化方法等總結 帶你深入AI(3)- 物體分類領域:AlexNet VGG I
[目標檢測]SSD:Single Shot MultiBox Detector
基於”Proposal + Classification”的Object Detection的方法,RCNN系列(R-CNN、SPPnet、Fast R-CNN以及Faster R-CNN)取得了非常好的效果,因為這一類方法先預先回歸一次邊框,然後再進行骨幹網路
卷積神經網路(4)----目標檢測
一、分類、定位和檢測 簡單來說,分類、定位和檢測的區別如下: 分類:是什麼? 定位:在哪裡?是什麼?(單個目標) 檢測:在哪裡?分別是什麼?(多個目標) (1)目標分
卷積神經網絡(4)----目標檢測
使用 定義 fmt 應該 否則 vdh lan blog 檢測 一、分類、定位和檢測 簡單來說,分類、定位和檢測的區別如下: 分類:是什麽? 定位:在哪裏?是什麽?(單個目標) 檢測:在哪裏?分別是什麽?(多個目標) (1)目標分類
caffe目標檢測模型訓練全過程(三)目標檢測第一步
遍歷整圖查詢蝴蝶位置 2018/04/22 訓練模型對於識別背景和蝴蝶有比較好的效果,基本對不會識別錯誤,接下來,將通過整圖遍歷的原始而又野蠻的方式對一張原始圖片進行處理,進而查詢到蝴蝶的具體位置。具體思路如下圖。對原圖進行縮放成理想大小,例如, 最小邊長縮放為227*6畫素,最大邊長等比
(人臉)目標檢測指標-FDDB
介紹 評價人臉目標檢測系統的效能指標 參考下面2010年的人臉資料庫文章FDDB 的評價章節 Jain V, Learned-Miller E. Fddb: A benchmark for face detection in unconstrained settings[R]. Tech
(一)目標檢測經典模型回顧
轉載自知乎:https://zhuanlan.zhihu.com/p/34142321關於作者: @李家丞同濟大學數學系本科在讀,現為格靈深瞳演算法部實習生。-----------------------------------------------------------
YOLO演算法(Bounding Box)目標檢測
Abstract 在《基於深度學習的目標檢測思路》中,提到了可以用滑動視窗的思路來做目標檢測。除了滑動視窗,還有其他的目標檢測演算法嗎? 目標檢測介紹 傳統的目標檢測演算法,都是基於滑動視窗,訓練模型的,如下圖所示。 該方法對目標的標註,需要標註目標
深度學習(四)——目標檢測演算法YOLO的訓練和檢測過程的基本思路介紹
基礎知識掌握情況決定研究的高度,我們剛開始接觸深度學習時,一般都是看到別人的概括,這個方法很好能讓我們快速上手,但是也有一個很大的缺點, 知識理解的不透徹,導致我們對演算法優化時一頭霧水。我也是抱著知識總結的思想開始自己的深度學習知識精髓的探索,也希望能從中幫助到
卷積神經網路(3):目標檢測學習筆記[吳恩達Deep Learning]
1.目標定位 1.1 分類、定位、檢測簡介 - Image classification 影象分類,就是給你一張圖片,你判斷目標是屬於哪一類,如汽車、貓等等。 - Classification with localization 定位分類,
計算機視覺筆記及資料整理(含影象分割、目標檢測小方向學習)
前言 1、簡單聊聊: 在我腦海中我能通過這些年聽到的技術名詞來感受到技術的更新及趨勢,這種技術發展有時候我覺得連關注的腳步都趕不上。簡單回顧看看,從我能聽到的技術名詞來感受,最開始耳聞比較多「雲端計算」這玩意,後來聽到比較多的是「資料探勘」,當時想著等考上研也要