
YOLO演算法(Bounding Box)目標檢測
阿新 • • 發佈:2019-01-01
Abstract
在《基於深度學習的目標檢測思路》中,提到了可以用滑動視窗的思路來做目標檢測。除了滑動視窗,還有其他的目標檢測演算法嗎?
目標檢測介紹
傳統的目標檢測演算法,都是基於滑動視窗,訓練模型的,如下圖所示。

該方法對目標的標註,需要標註目標的位置、大小、型別等資訊,標註成本是很高的。但是,做目標檢測是少不了這個標註工作的。
這種傳統的滑動視窗目標檢測方法,最大的缺點是: 視窗大小不固定,需要動態改變視窗做多次訓練、預測操作,這對模型的訓練是非常耗時的。
有沒有辦法針對一幅影象,只做一次訓練呢?這就是YOLO演算法要解決的問題。
YOLO演算法
YOLO演算法的做法,是用一個MxN的網格覆蓋在原圖上,並對各個小網格的內容進行標註。如下圖所示,我們這裡假設影象是100x100x3的彩色影象,網格是3x3的,但實際使用過程中,網格會更密。
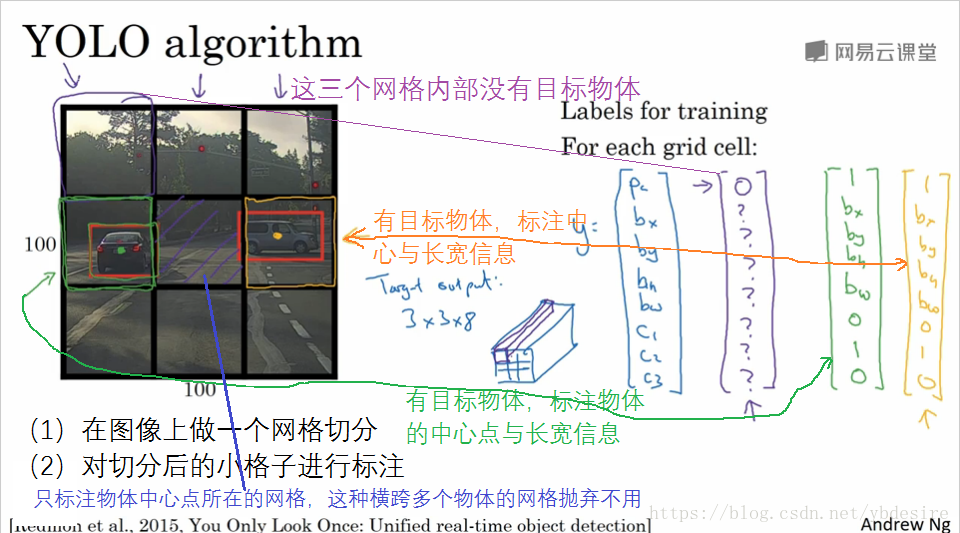
網格覆蓋原圖後,就對每個小網格的內容進行標註,需要標註如下資訊
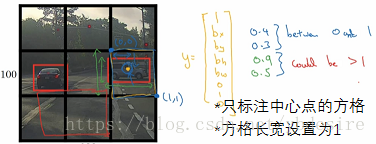
- pc:小網格內是否有目標物體的中心點,注意是根據中心點進行標註,橫跨多個網格的物體也只標註有中心點存在的網格。
- bx,by,bh,bw:目標物體中心點在網格中的x-y座標,以及目標物體的長、寬。一般將小網格長寬取1後進行標註,這樣位置座標都被轉化為0~1之間的數值。
- c1,c2,c3:類別,這裡假設分三類。
可見,每個小網格需要標註8個Y值。如圖3x3的網格,需要標註3x3x8個輸出值。標註中有一個小技巧,就是儘量將Y值轉化為0~1之間的數值。
最終訓練模型時,一幅影象,只需要訓練一次:
- 輸入:100x100x3
- 輸出:3x3x8
所以YOLO演算法的效率很高,可以做到實時檢測。
YOLO演算法例項
參考
本文圖片取自AndrewNG的Deep Learning課程,在此表示感謝!