
SSD(single shot multibox detector)演算法及Caffe程式碼詳解(轉載)
這篇部落格主要介紹SSD演算法,該演算法是最近一年比較優秀的object detection演算法,主要特點在於採用了特徵融合。
演算法概述:
本文提出的SSD演算法是一種直接預測bounding box的座標和類別的object detection演算法,沒有生成proposal的過程。針對不同大小的物體檢測,傳統的做法是將影象轉換成不同的大小,然後分別處理,最後將結果綜合起來,而本文的ssd利用不同卷積層的feature map進行綜合也能達到同樣的效果。演算法的主網路結構是VGG16,將兩個全連線層改成卷積層再增加4個卷積層構造網路結構。對其中5個不同的卷積層的輸出分別用兩個3*3的卷積核進行卷積,一個輸出分類用的confidence,每個default box生成21個confidence(這是針對VOC資料集包含20個object類別而言的);一個輸出迴歸用的localization,每個default box生成4個座標值(x,y,w,h)
演算法的結果:對於300*300的輸入,SSD可以在VOC2007 test上有74.3%的mAP,速度是59 FPS(Nvidia Titan X),對於512*512的輸入, SSD可以有76.9%的mAP。相比之下Faster RCNN是73.2%的mAP和7FPS,YOLO是63.4%的mAP和45FPS。即便對於解析度較低的輸入也能取得較高的準確率。可見作者並非像傳統的做法一樣以犧牲準確率的方式來提高檢測速度。作者認為自己的演算法之所以在速度上有明顯的提升,得益於去掉了bounding box proposal以及後續的pixel或feature的resampling步驟。
演算法詳解:
SSD演算法在訓練的時候只需要一張輸入影象及其每個object的ground truth boxes。
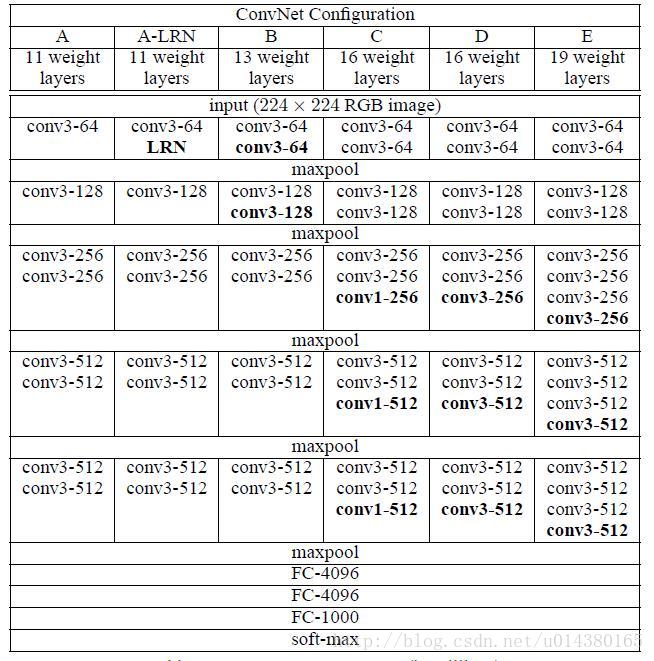
基本的網路結構是基於VGG16,在ImageNet資料集上預訓練完以後用兩個新的卷積層代替fc6和fc7,另外對pool5也做了一點小改動,還增加了4個卷積層構成本文的網路。VGG的結構如下圖所示:
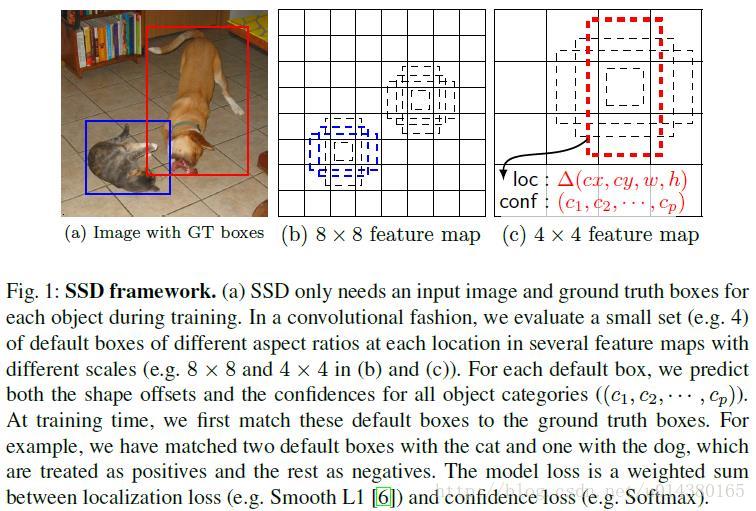
文章的一個核心是作者同時採用lower和upper的feature maps做檢測。如下圖Fig1,有8*8和4*4兩種大小的feature maps,而feature map cell就是其中的每一個小格。另外有一個概念:default box,是指在feature map的每個小格(cell)上都有一系列固定大小的box
所以這裡用到的default box和Faster RCNN中的anchor很像,在Faster RCNN中anchor只用在最後一個卷積層,但是在本文中,default box是應用在多個不同層的feature map上。
下圖還有一個重要的資訊是:在訓練階段,演算法在一開始會先將這些default box和ground truth box進行匹配,比如藍色的兩個虛線框和貓的ground truth box匹配上了,一個紅色的虛線框和狗的ground truth box匹配上了。所以一個ground truth可能對應多個default box。在預測階段,直接預測每個default box的偏移以及對每個類別相應的得分,最後通過NMS得到最終的結果。
Fig1(c)說明對於每個default box,同時預測它的座標offset和所有類的confidence。
關於ground truth和default box的匹配細則可以參考下圖:

那麼default box的scale(大小)和aspect ratio(橫縱比)要怎麼定呢?假設我們用m個feature maps做預測,那麼對於每個featuer map而言其default box的scale是按以下公式計算的: 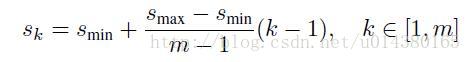
這裡smin是0.2,表示最底層的scale是0.2,;smax是0.9,表示最高層的scale是0.9。
至於aspect ratio,用ar表示為下式:注意這裡一共有5種aspect ratio 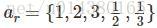
因此每個default box的寬的計算公式為: 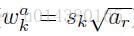
高的計算公式為:(很容易理解寬和高的乘積是scale的平方) 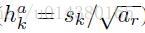
另外當aspect ratio為1時,作者還增加一種scale的default box:
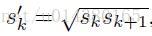
因此,對於每個feature map cell而言,一共有6種default box。
可以看出這種default box在不同的feature層有不同的scale,在同一個feature層又有不同的aspect ratio,因此基本上可以覆蓋輸入影象中的各種形狀和大小的object!
顯然,當default box和grount truth匹配上了,那麼這個default box就是positive example(正樣本),如果匹配不上,就是negative example(負樣本),顯然這樣產生的負樣本的數量要遠遠多於正樣本。於是作者將負樣本按照confidence loss進行排序,然後選擇排名靠前的一些負樣本作為訓練,使得最後負樣本和正樣本的比例在3:1左右。
下圖是SSD演算法和YOLO演算法的結構圖對比。YOLO演算法的輸入是448*448*3,輸出是7*7*30,這7*7個grid cell一共預測98個bounding box。SSD演算法是在原來VGG16的後面添加了幾個卷積層來預測offset和confidence(相比之下YOLO演算法是採用全連線層),演算法的輸入是300*300*3,採用conv4_3,conv7,conv8_2,conv9_2,conv10_2和conv11_2的輸出來預測location和confidence。
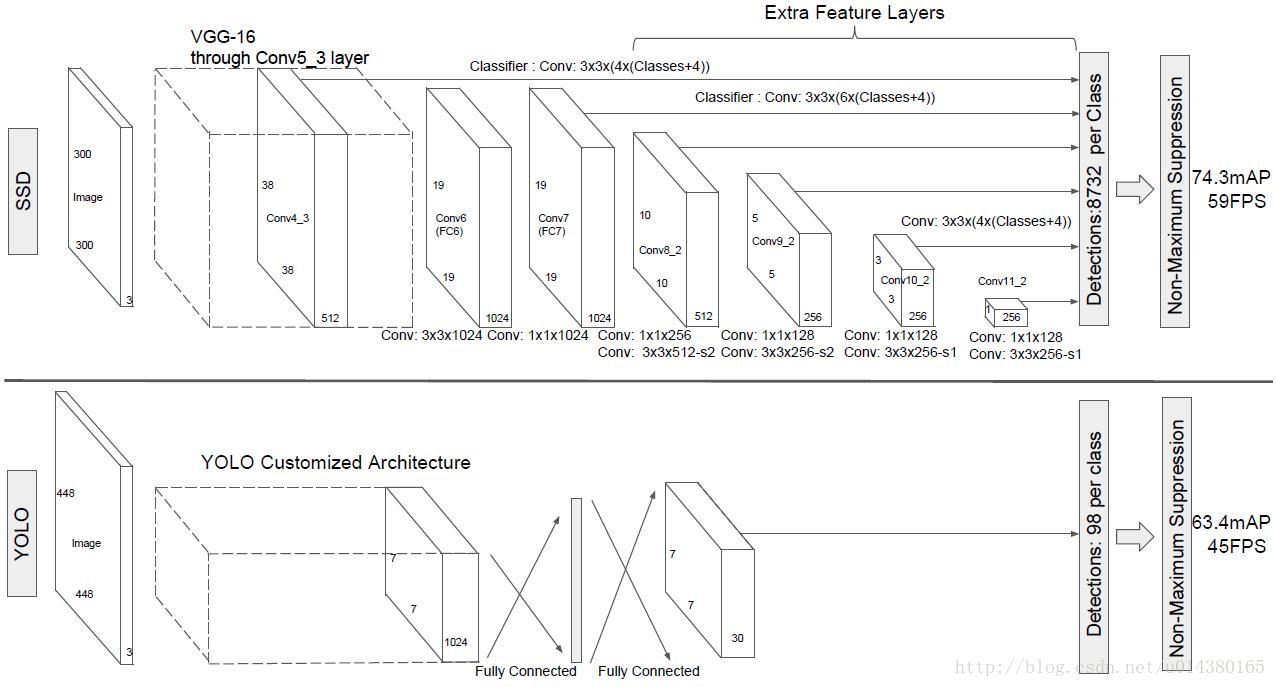
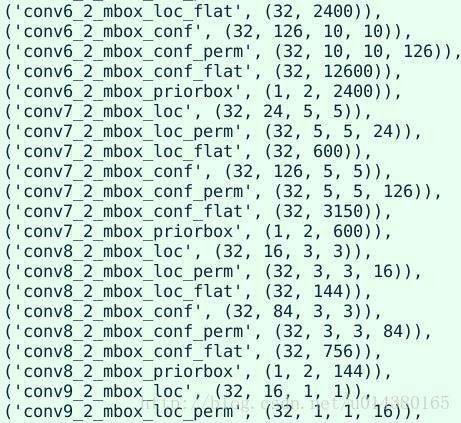
詳細講一下SSD的結構,可以參看Caffe程式碼。SSD的結構為conv1_1,conv1_2,conv2_1,conv2_2,conv3_1,conv3_2,conv3_3,conv4_1,conv4_2,conv4_3,conv5_1,conv5_2,conv5_3(512),fc6:3*3*1024的卷積(原來VGG16中的fc6是全連線層,這裡變成卷積層,下面的fc7層同理),fc7:1*1*1024的卷積,conv6_1,conv6_2(對應上圖的conv8_2),……,conv9_1,conv9_2,loss。然後針對conv4_3(4),fc7(6),conv6_2(6),conv7_2(6),conv8_2(4),conv9_2(4)的每一個再分別採用兩個3*3大小的卷積核進行卷積,這兩個卷積核是並列的(括號裡的數字代表default box的數量,可以參考Caffe程式碼,所以上圖中SSD結構的倒數第二列的數字8732表示的是所有default box的數量,是這麼來的38*38*4+19*19*6+10*10*6+5*5*6+3*3*4+1*1*4=8732),這兩個3*3的卷積核一個是用來做localization的(迴歸用,如果default box是6個,那麼就有6*4=24個這樣的卷積核,卷積後map的大小和卷積前一樣,因為pad=1,下同),另一個是用來做confidence的(分類用,如果default box是6個,VOC的object類別有20個,那麼就有6*(20+1)=126個這樣的卷積核)。如下圖是conv6_2的localizaiton的3*3卷積核操作,卷積核個數是24(6*4=24,由於pad=1,所以卷積結果的map大小不變,下同):這裡的permute層就是交換的作用,比如你卷積後的維度是32*24*19*19,那麼經過交換層後就變成32*19*19*24,順序變了而已。而flatten層的作用就是將32*19*19*24變成32*8664,32是batchsize的大小。
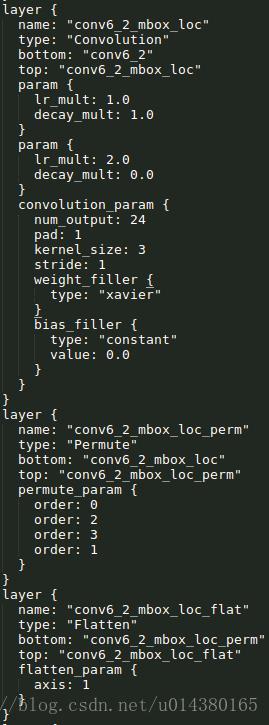
confidence的3*3卷積核操作如下,注意卷積核個數是126(6*21=126):

然後是一個生成default box的操作,根據最小尺寸,最大尺寸以及橫縱比來生成,step表示該層的一個畫素點相當於最開始輸入影象的1/32,簡單講就是感受野,原始碼裡面是通過將原始的input image的大小除以該層feature map的大小來得到的。variance目測是一個尺度變換,本文的四個座標採用的是中心座標加上長寬,計算loss的時候可能需要對中心座標的loss和長寬的loss做一個權衡,所以有了這個variance。如果採用的是box的四大頂點座標這種方式,預設variance都是0.1,即相互之間沒有權重差異。經過上述3個操作後,對這一層feature的處理就結束了。

稍微看下幾個層的輸出維度,注意看priorbox的維度,以conv8_2_mbox_priorbox為例,是(1,2,144),這個144表示生成的default box的所有座標,所以和前面迴歸的座標個數是一樣的:3*3*4*4。2是和variance相關的。
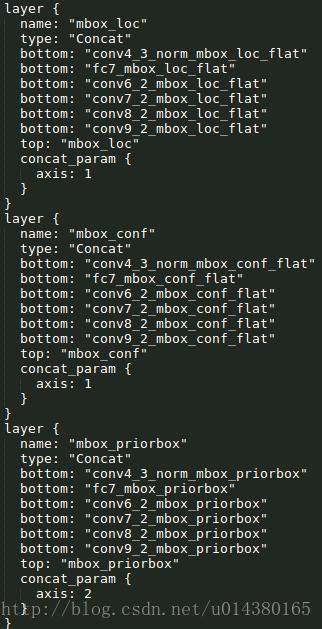
對前面所列的5個卷積層輸出都執行上述的操作後,就將得到的結果合併:採用Concat,類似googleNet的Inception操作,是通道合併而不是數值相加。
這是幾個通道合併後的維度:

最後就是作者自定義的損失函式層,這裡的overlap_threshold表示default box和ground truth的重合度超過這個閾值則為正樣本:

損失函式方面:和Faster RCNN的基本一樣,由分類和迴歸兩部分組成,可以參考Faster RCNN,這裡不細講。總之,迴歸部分的loss是希望預測的box和default box的差距儘可能跟ground truth和default box的差距接近,這樣預測的box就能儘量和ground truth一樣。
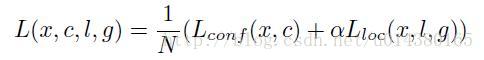
這裡稍微列了下幾種object detection演算法的default boxes數量以及為什麼要有這麼多的box:

實驗結果:
資料集增加對於mAP的提升確實相當明顯!
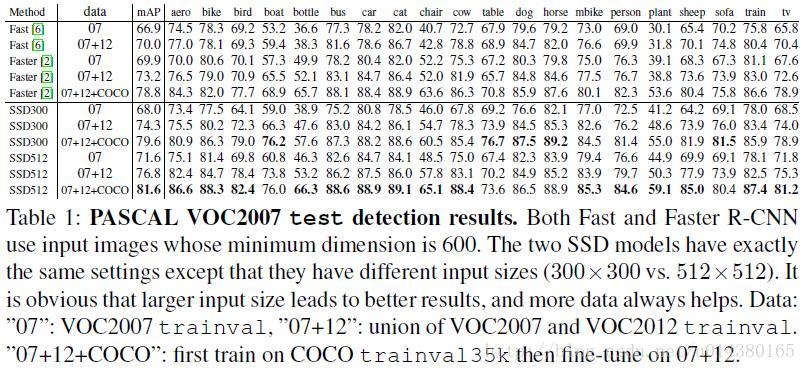
通過對比各種設計方法說明增加資料集對mAP的增加是最明顯的。
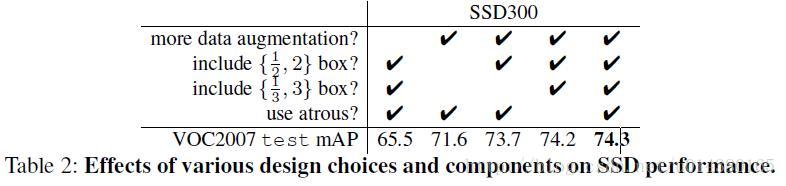
在Fast RCNN和Faster RCNN中,資料集增加的辦法主要是採用原有的資料及其水平翻轉的結果作為訓練集。
這個圖說明使用多層特徵的有效性。融合不同層的特徵是一種重要的方法,在這裡主要解決了大小不同的object的檢測問題。

通過實驗對比YOLO和Faster RCNN,說明SSD速度快且準確率更高。

總結:
這種演算法對於不同橫縱比的object的檢測都有效,這是因為演算法對於每個feature map cell都使用多種橫縱比的default boxes,這也是本文演算法的核心。另外本文的default box做法是很類似Faster RCNN中的anchor的做法的。最後本文也強調了增加資料集的作用,包括隨機裁剪,旋轉,對比度調整等等。
文中作者提到該演算法對於小的object的detection比大的object要差。作者認為原因在於這些小的object在網路的頂層所佔的資訊量太少,所以增加輸入影象的尺寸對於小的object的檢測有幫助。另外增加資料集對於小的object的檢測也有幫助,原因在於隨機裁剪後的影象相當於“放大”原影象,所以這樣的裁剪操作不僅增加了影象數量,也放大了影象。