
大資料技術-資料採集-Flume.logstash等
隨著大資料越來越被重視,資料採集的挑戰變的尤為突出。今天為大家介紹幾款資料採集平臺:
- Apache Flume
- Fluentd
- Logstash
- Chukwa
- Scribe
- Splunk Forwarder
大資料平臺與資料採集
任何完整的大資料平臺,一般包括以下的幾個過程:
資料採集-->資料儲存-->資料處理-->資料展現(視覺化,報表和監控)
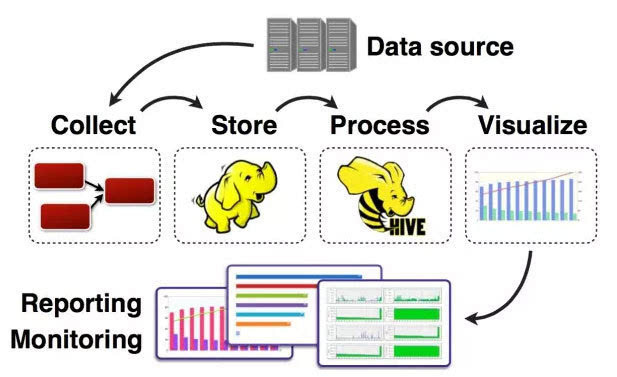
其中,資料採集是所有資料系統必不可少的,隨著大資料越來越被重視,資料採集的挑戰也變的尤為突出。這其中包括:
- 資料來源多種多樣
- 資料量大
- 變化快
- 如何保證資料採集的可靠性的效能
- 如何避免重複資料
- 如何保證資料的質量
我們今天就來看看當前可用的六款資料採集的產品,重點關注它們是如何做到高可靠,高效能和高擴充套件。
1、Apache Flume
官網:https://flume.apache.org/
Flume 是Apache旗下的一款開源、高可靠、高擴充套件、容易管理、支援客戶擴充套件的資料採集系統。 Flume使用JRuby來構建,所以依賴Java執行環境。
Flume最初是由Cloudera的工程師設計用於合併日誌資料的系統,後來逐漸發展用於處理流資料事件。

Flume設計成一個分散式的管道架構,可以看作在資料來源和目的地之間有一個Agent的網路,支援資料路由。

每一個agent都由Source,Channel和Sink組成。
Source
Source負責接收輸入資料,並將資料寫入管道。Flume的Source支援HTTP,JMS,RPC,NetCat,Exec,Spooling Directory。其中Spooling支援監視一個目錄或者檔案,解析其中新生成的事件。
Channel
Channel 儲存,快取從source到Sink的中間資料。可使用不同的配置來做Channel,例如記憶體,檔案,JDBC等。使用記憶體效能高但不持久,有可能丟資料。使用檔案更可靠,但效能不如記憶體。
Sink
Sink負責從管道中讀出資料併發給下一個Agent或者最終的目的地。Sink支援的不同目的地種類包括:HDFS,HBASE,Solr,ElasticSearch,File,Logger或者其它的Flume Agent。
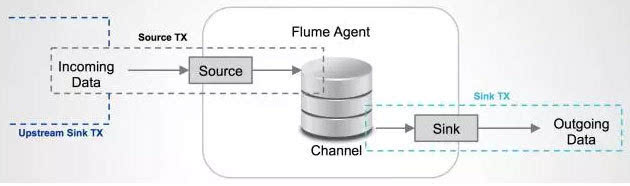
Flume在source和sink端都使用了transaction機制保證在資料傳輸中沒有資料丟失。
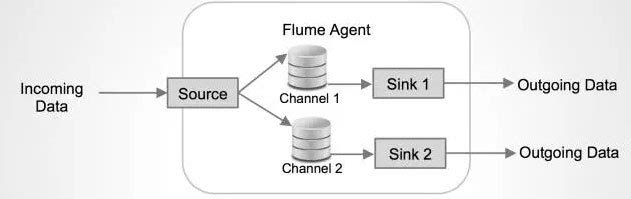
Source上的資料可以複製到不同的通道上。每一個Channel也可以連線不同數量的Sink。這樣連線不同配置的Agent就可以組成一個複雜的資料收集網路。通過對agent的配置,可以組成一個路由複雜的資料傳輸網路。
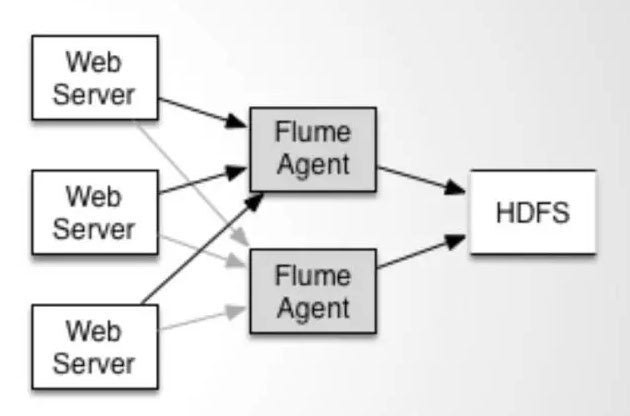
配置如上圖所示的agent結構,Flume支援設定sink的Failover和Load Balance,這樣就可以保證即使有一個agent失效的情況下,整個系統仍能正常收集資料。

Flume中傳輸的內容定義為事件(Event),事件由Headers(包含元資料,Meta Data)和Payload組成。
Flume提供SDK,可以支援使用者定製開發:
Flume客戶端負責在事件產生的源頭把事件傳送給Flume的Agent。客戶端通常和產生資料來源的應用在同一個程序空間。常見的Flume 客戶端有Avro,log4J,syslog和HTTP Post。另外ExecSource支援指定一個本地程序的輸出作為Flume的輸入。當然很有可能,以上的這些客戶端都不能滿足需求,使用者可以定製的客戶端,和已有的FLume的Source進行通訊,或者定製實現一種新的Source型別。
同時,使用者可以使用Flume的SDK定製Source和Sink。似乎不支援定製的Channel。
2、Fluentd
官網:http://docs.fluentd.org/articles/quickstart
Fluentd是另一個開源的資料收集框架。Fluentd使用C/Ruby開發,使用JSON檔案來統一日誌資料。它的可插拔架構,支援各種不同種類和格式的資料來源和資料輸出。最後它也同時提供了高可靠和很好的擴充套件性。Treasure Data, Inc 對該產品提供支援和維護。
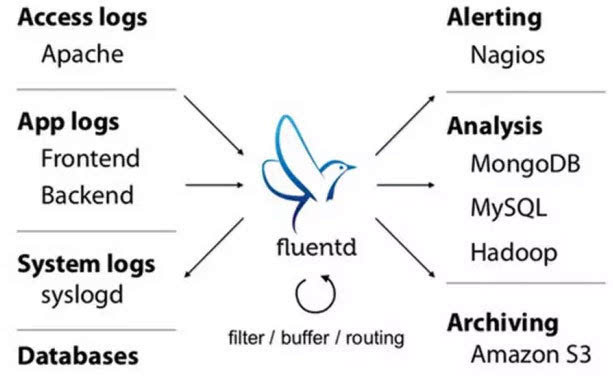
Fluentd的部署和Flume非常相似:
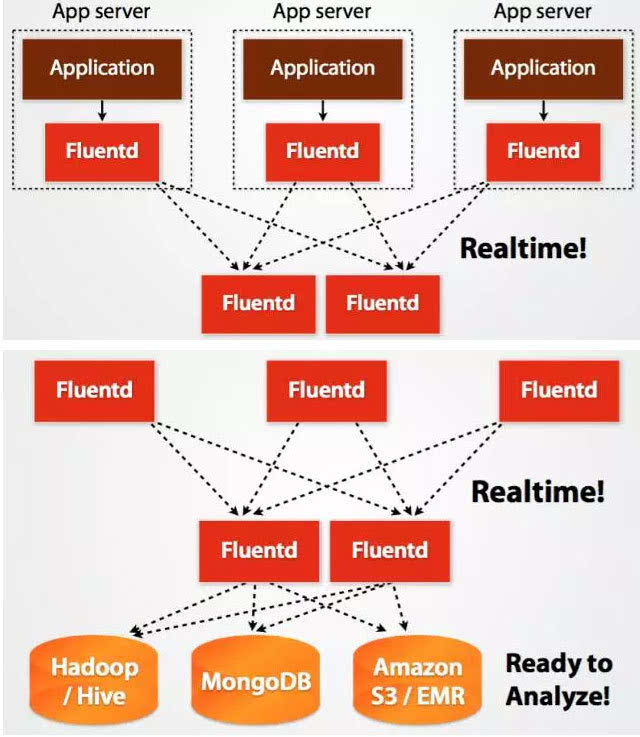
Fluentd的架構設計和Flume如出一轍:
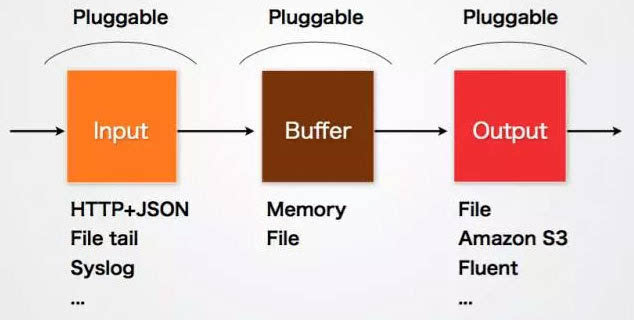
Fluentd的Input/Buffer/Output非常類似於Flume的Source/Channel/Sink。
Input
Input負責接收資料或者主動抓取資料。支援syslog,http,file tail等。
Buffer
Buffer負責資料獲取的效能和可靠性,也有檔案或記憶體等不同型別的Buffer可以配置。
Output
Output負責輸出資料到目的地例如檔案,AWS S3或者其它的Fluentd。
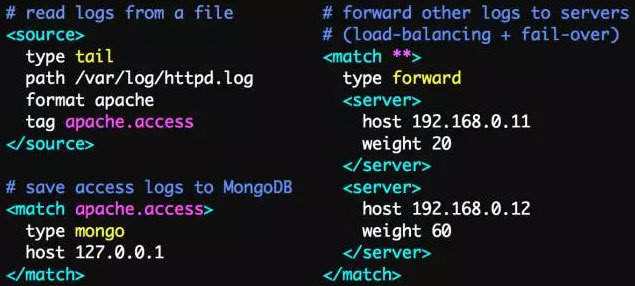
Fluentd的配置非常方便,如下圖:
Fluentd的技術棧如下圖:
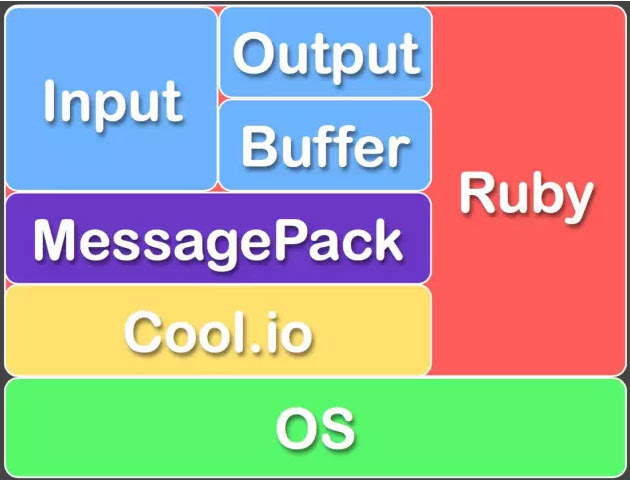
FLuentd和其外掛都是由Ruby開發,MessgaePack提供了JSON的序列化和非同步的並行通訊RPC機制。
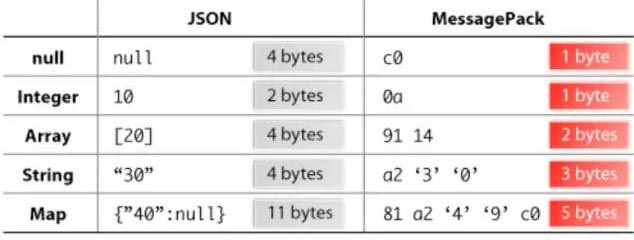
Cool.io是基於libev的事件驅動框架。
FLuentd的擴充套件性非常好,客戶可以自己定製(Ruby)Input/Buffer/Output。
Fluentd從各方面看都很像Flume,區別是使用Ruby開發,Footprint會小一些,但是也帶來了跨平臺的問題,並不能支援Windows平臺。另外採用JSON統一資料/日誌格式是它的另一個特點。相對去Flumed,配置也相對簡單一些。
3、Logstash
https://github.com/elastic/logstash
Logstash是著名的開源資料棧ELK (ElasticSearch, Logstash, Kibana)中的那個L。
Logstash用JRuby開發,所有執行時依賴JVM。
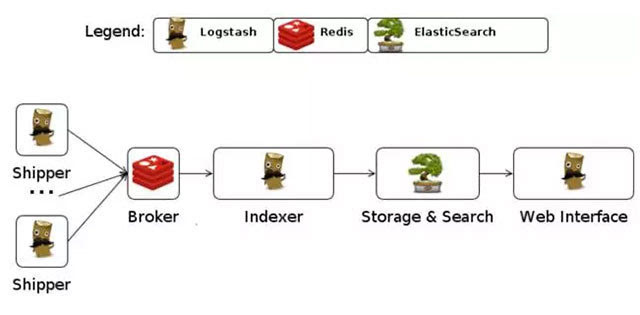
Logstash的部署架構如下圖,當然這只是一種部署的選項。
一個典型的Logstash的配置如下,包括了Input,filter的Output的設定。

幾乎在大部分的情況下ELK作為一個棧是被同時使用的。所有當你的資料系統使用ElasticSearch的情況下,logstash是首選。
4、Chukwa
官網:https://chukwa.apache.org/
Apache Chukwa是apache旗下另一個開源的資料收集平臺,它遠沒有其他幾個有名。Chukwa基於Hadoop的HDFS和Map Reduce來構建(顯而易見,它用Java來實現),提供擴充套件性和可靠性。Chukwa同時提供對資料的展示,分析和監視。很奇怪的是它的上一次 github的更新事7年前。可見該專案應該已經不活躍了。
Chukwa的部署架構如下:

Chukwa的主要單元有:Agent,Collector,DataSink,ArchiveBuilder,Demux等等,看上去相當複雜。由於該專案已經不活躍,我們就不細看了。
5、Scribe
程式碼託管:https://github.com/facebookarchive/scribe
Scribe是Facebook開發的資料(日誌)收集系統。已經多年不維護,同樣的,就不多說了。
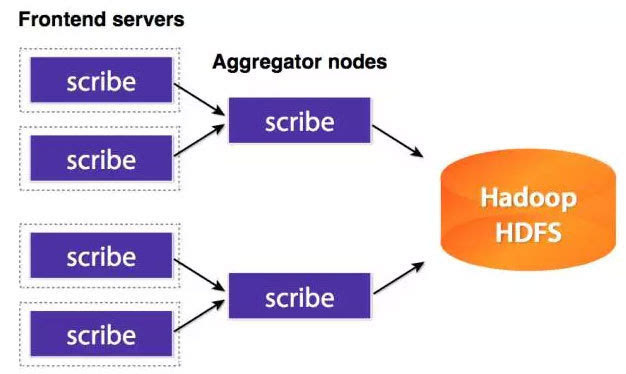
6、Splunk Forwarder
官網:http://www.splunk.com/
以上的所有系統都是開源的。在商業化的大資料平臺產品中,Splunk提供完整的資料採金,資料儲存,資料分析和處理,以及資料展現的能力。
Splunk是一個分散式的機器資料平臺,主要有三個角色:
- Search Head負責資料的搜尋和處理,提供搜尋時的資訊抽取。
- Indexer負責資料的儲存和索引
- Forwarder,負責資料的收集,清洗,變形,併發送給Indexer
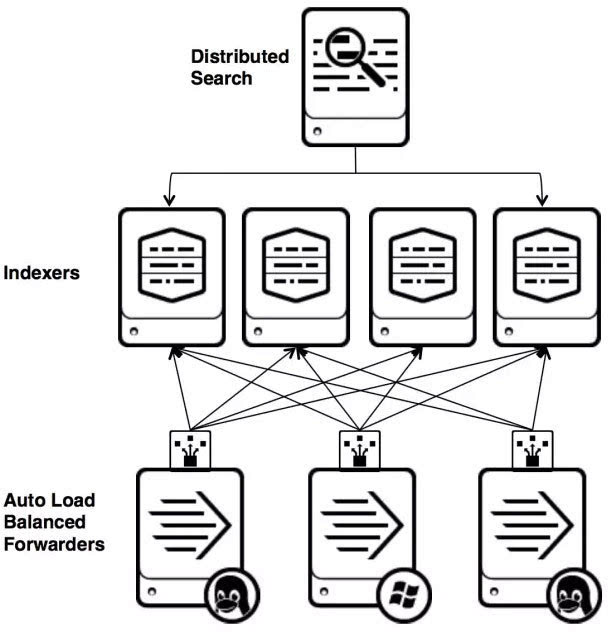
Splunk內建了對Syslog,TCP/UDP,Spooling的支援,同時,使用者可以通過開發 Input和Modular Input的方式來獲取特定的資料。在Splunk提供的軟體倉庫裡有很多成熟的資料採集應用,例如AWS,資料庫(DBConnect)等等,可以方便的從雲或者是資料庫中獲取資料進入Splunk的資料平臺做分析。
這裡要注意的是,Search Head和Indexer都支援Cluster的配置,也就是高可用,高擴充套件的,但是Splunk現在還沒有針對Farwarder的Cluster的功能。也就是說如果有一臺Farwarder的機器出了故障,資料收集也會隨之中斷,並不能把正在執行的資料採集任務Failover到其它的 Farwarder上。
總結
我們簡單討論了幾種流行的資料收集平臺,它們大都提供高可靠和高擴充套件的資料收集。大多平臺都抽象出了輸入,輸出和中間的緩衝的架構。利用分散式的網路連線,大多數平臺都能實現一定程度的擴充套件性和高可靠性。
其中Flume,Fluentd是兩個被使用較多的產品。如果你用ElasticSearch,Logstash也許是首選,因為ELK棧提供了很好的整合。Chukwa和Scribe由於專案的不活躍,不推薦使用。
Splunk作為一個優秀的商業產品,它的資料採集還存在一定的限制,相信Splunk很快會開發出更好的資料收集的解決方案。
摘於:http://developer.51cto.com/art/201601/504888.htm
相關推薦
大資料技術-資料採集-Flume.logstash等
隨著大資料越來越被重視,資料採集的挑戰變的尤為突出。今天為大家介紹幾款資料採集平臺: Apache Flume Fluentd Logstash Chukwa Scribe Splunk Forwarder大資料平臺與資料採集 任何完整的大資料平臺,一般包括以下的幾個過程
大資料技術--kafka和flume的對比
來源:http://blog.csdn.net/crazyhacking/article/details/45746191 摘要: (1)kafka和flume都是日誌系統。kafka是分散式訊息中介軟體,自帶儲存,提供push和pull存取資料功能。flume分為ag
大資料技術 | 資料視覺化的五大趨勢
隨著科技的不斷進步與新裝置的不斷湧現,資料視覺化領域目前正處在飛速地發展之中。 ProPublica的調查記者兼開發者Lena Groeger,以及金融時報的資料視覺化記者Jane Pong在全球深度報道大會上分享了他們對當前資料視覺化趨勢的一些看法。 1.定製資料 Pong
大資料技術學習筆記之網站流量日誌分析專案:Flume日誌採集系統1
一、網站日誌流量專案 -》專案開發階段: -》可行性分析 -》需求分析
大資料技術應用(一) 應用Flume+HBase採集和儲存日誌資料
前言 大資料時代,誰掌握了足夠的資料,誰就有可能掌握未來,而其中的資料採集就是將來的流動資產積累。 幾乎任何規模企業,每時每刻也都在產生大量的資料,但這些資料如何歸集、提煉始終是一個困擾。而大資料技
大資料技術學習筆記之網站流量日誌分析專案:資料採集層的實現3
一、資料採集業務 -》資料來源 -》網站:使用者訪問日誌、使用者行為日誌、伺服器執行日誌 -》業務:
Flume+Kafka雙劍合璧玩轉大資料平臺日誌採集
概述 大資料平臺每天會產生大量的日誌,處理這些日誌需要特定的日誌系統。 一般而言,這些系統需要具有以下特徵: 構建應用系統和分析系統的橋樑,並將它們之間的關聯解耦; 支援近實時的線上分析系統和類似於Hadoop之類的離線分析系統; 具有高可擴充套件性。即:當資料量增加時,可以通過增加節點
大資料_資料採集引擎(Sqoop和Flume)
一、資料採集引擎 1、準備實驗環境: 準備Oracle資料庫 使用者:sh 表:sales 訂單表(92萬) 2、Sqoop:採集關係型資料庫中的資料 用在離線計算的
學習大資料技術,Hive實踐分享之儲存和壓縮的坑
在學習大資料技術的過程中,HIVE是非常重要的技術之一,但我們在專案上經常會遇到一些儲存和壓縮的坑,本文通過科多大資料的武老師整理,分享給大家。 大家都知道,由於叢集資源有限,我們一般都會針對資料檔案的「儲存結構」和「壓縮形式」進行配置優化。在我實際檢視以後,發現叢集的檔案儲存格式為Parque
一文讀懂大資料技術驅動的銀行客戶畫像
2018年上半年我國GDP增速6.8%,在貿易戰和去槓桿的影響下,雖然金融市場震盪明顯,但銀行受到網際網路、移動計算到雲端計算、大資料、物聯網、人工智慧等技術變革的影響,仍舊保持了較好盈利。在採取了業務轉型與創新、同業業務從線下向線上轉移、資產結構的進一步優化等諸多調整措施的過程中,“手機銀行、P2
]大資料技術在綜合管廊環境監測中的應用
地下綜合管廊整體建於地下,內部相對封閉,一旦發生災害,會對廊內裝置和搶修人員安全造成極大威脅。綜合管廊分佈了數目眾多、各式各樣的感測器來監測管廊內部情況。由此產生了海量的由感測器產生而又不適於關係模式的非結構化資料。 如何有效地管理這些非結構化資料,迫切需要利用大資料技術,高效
大資料學習路線圖 讓你精準掌握大資料技術學習
大資料指不用隨機分析法這樣捷徑,而採用所有資料進行分析處理的方法。網際網路時代每個企業每天都要產生龐大的資料,對資料進行儲存,對有效的資料進行挖掘分析並應用需要依賴於大資料開發,大資料開發課程採用真實商業資料來源並融合雲端計算+機器學習,讓學員有實力入職一線網際網路企業。大資料學習群1429
大資料要學習哪些技術呢?大資料技術的分類與選擇路線
大資料的處理過程可以分為大資料採集、儲存、結構化處理、隱私保護、挖掘、結果展示(釋出)等,各種領域的大資料應用一般都會涉及到這些基本過程,但不同應用可能會有所側重。對於網際網路大資料而言,由於其具有獨特完整的大資料特點,除了共性技術外,採集技術、結構化處理技術、隱私保護也非常突出。 有很
大資料重新定義未來,2018 中國大資料技術大會(BDTC)豪華盛宴搶先看!
隨著資訊科技的迅猛發展,資料的重要性和價值已毋庸置疑,資料正在改變競爭格局,成為重要的生產因素,更被定義為“21世紀的新石油”。在資訊高速傳播的今天,資料已經滲透到每一個行業和業務職能領域,指數級的速度增長將我們帶入大資料時代。作為年度技術趨勢與行業應用的風向標,2018 中國大資料技術大會(BDT
大資料學習路線 讓你精準掌握大資料技術學習
大資料指不用隨機分析法這樣捷徑,而採用所有資料進行分析處理的方法。網際網路時代每個企業每天都要產生龐大的資料,對資料進行儲存,對有效的資料進行挖掘分析並應用需要依賴於大資料開發,大資料開發課程採用真實商業資料來源並融合雲端計算+機器學習,讓學員有實力入職一線網際網路企業。 今天小編的技術分享詳細學習大資料的
小白自學大資料技術,學習路線很重要
身邊有很多朋友想學習大資料技術,但是苦於一沒基礎,二沒時間,三不知道如何入手,看著大資料行業發展如火如荼,大資料技術崗位各種薪資高、發展好。那何不利用自己的業餘時間,趕緊學起來。為方便大家學習,參考科多大資料的培養體系,整理了一些大家自學的技術和順序,趕緊學起來 大資料處理技術怎麼學習呢?首先我
大資料技術體系1(清華:大資料技術體系)
【1】採集與整合 【2】儲存與管理 【3】分析與挖掘 【4】視覺化 【5】計算範型 【6】隱私與安全 01資料質量-無法迴避的挑戰 傳統資料質量僅通過EFL方式執行,即抽取、轉換、載入,包括解析、模式分析等。 沒有完全覆蓋資料質量的基本性質 挑戰
一篇文章詳解大資料技術和應用場景
什麼是大資料 說起大資料,估計大家都覺得只聽過概念,但是具體是什麼東西,怎麼定義,沒有一個標準的東西,因為在我們的印象中好像很多公司都叫大資料公司,業務形態則有幾百種,感覺不是很好理解,所以我建議還是從字面上來理解大資料,在維克托邁爾-舍恩伯格及肯尼斯庫克耶編寫的《大資料時代》提到了大資料的4個特徵:
大資料技術 分散式儲存 HDFS原理
大資料基礎知識 一、什麼是大資料 短時間內快速產生的海量的多種多樣的有價值的資料。 大資料的技術: 1、分散式儲存: 2、分散式計算: 1)分散式批處理: 當資料積累一定的時間後(假設一個月),進行統一的處理。 2)分散式流處理 分散式流處理是一個實時
大資料之效能調優方面(資料傾斜、shuffle、JVM等方面)
一、對於資料傾斜的發生一般都是一個key對應的資料過大,而導致Task執行過慢,或者記憶體溢位(OOM),一般是發生在shuffle的時候,比如reduceByKey,groupByKey,sortByKey等,容易產生資料傾斜。 那麼針對資料傾斜我們如何解決呢?我們可以首先觀看log日誌,以為log日誌報