
『 論文閱讀』Understanding deep learning requires rethinking generalization
ABSTRACT
雖然其規模巨大,但成功的深層人工神經網路可以獲得訓練和測試集非常小的效能差異。
傳統知識認為這種小的泛化誤差歸功於模型的效能,或者是由於在訓練的時候加入了正則化技術。
通過廣泛的系統實驗,我們展示了這些傳統方法如何不能解釋,而為什麼大型神經網路能在實踐中推廣。具體來說,實驗建立了用隨機梯度方法訓練的影象分類的最先進的卷積網路,能容易地擬合訓練資料的隨機標記。這種現象在質量上不受顯式正則化的影響,即使我們用完全非結構化的隨機噪聲替換真實影象,也會發生這種現象。 我們用理論結構證實了這些實驗結果,表明簡單的深度兩個神經網路一旦引數數量超過了實際資料點的數量,就已經具有完美的有限樣本表達能力。
論文通過與傳統模型的比較來解釋我們的實驗結果。
1 INTRODUCTION
如何區分泛化性好的與那些不好的神經網路呢?解決這個問題不僅可以有助於神經網路的解釋性,還可以產生更原生和可靠的模型架構設計。
統計學習理論提出了一些能夠控制泛化誤差的不同複雜度方法。包括VC維度(Vapnik,1998),Rademacher複雜性(Bartlett&Mendelson,2003)和均勻穩定性(Mukherjee等,2002; Bousquet&Elisseeff,2002; Poggio等,2004)。當引數數量大時,理論認為需要某種正則化確保小的泛化誤差,正則化也有可能是隱含的,例如早期停止訓練。
1.1 CONTRIBUTIONS
在這項工作中,我們通過表明它不能區分具有完全不同的泛化效能的神經網路,從而使傳統的泛化觀點轉化為問題。
1.1.1 Randomization tests.
論文方法論的核心是非引數統計學中眾所周知的隨機化測試的變體(Edgington&Onghena,2007)。
第一組實驗: 用資料的副本訓練了幾個標準體系結構,其中真正的標籤被隨機標籤替代。中心發現可以歸結為:
Deep neural networks easily fit random labels.
更準確地說,當對真實資料進行完全隨機標記的訓練時,神經網路實現了0個訓練誤差。當然測試錯誤和隨機預測差不多。
通過標籤隨機化,強制使模型的泛化誤差大大地增加,而不改變模型,包括其大小、超引數和優化器。
論文在CIFAR10和ImageNet分類基準上訓練的幾種不同的標準體系。簡單說明如下觀點。
- 神經網路的有效容量足以記住整個資料集。
- 即使對隨機標籤進行優化仍然很容易。 事實上,與真實標籤上的培訓相比,培訓時間只增加一個小的常數。
- 隨機標籤只是一個數據轉換,使學習問題的所有其他屬性不變。
擴充套件實驗:通過完全隨機的畫素(例如,高斯噪聲)來代替真實影象,並觀察到卷積神經網路繼續適應零訓練誤差的資料。表明卷積神經網路可以適應隨機噪聲。並在無噪聲和完全噪聲的情況下平滑地內插。隨著噪聲水平的提高,我們觀察到廣義誤差的穩定惡化。 這表明神經網路能夠捕獲資料中的剩餘訊號,同時使用暴力來適應噪聲部分。
1.1.2 The role of explicit regularization.
論文表明,正則化的顯式形式,如weight decay, dropout, and data augmentation,沒有充分解釋神經網路的泛化誤差。
顯式正則化可以提高泛化效能,但既不必要也不足以控制泛化誤差。
Explicit regularization may improve generalization performance, but is neither necessary nor by itself sufficient for controlling generalization error.
1.1.3 有限的樣本表達 Finite sample expressivity.
論文用理論結構補充實驗觀察結果,表明一般大型神經網路可以表達訓練資料的任何標籤。展示了一個非常簡單的兩層ReLU網路,其中p = 2n + d引數可以表示任何尺寸為n的樣品的任何標籤。也可以使用一個深度k網路,其中每層只有O(n/k)個引數。
1.1.4 The role of implicit regularization.
在神經網路中,幾乎總是選擇執行隨機梯度下降輸出的模型。分析線性模型中,SGD如何作為隱式正則化器。對於線性模型,SGD總是收斂到一個小規模的解決方案。 因此,演算法本身將解決方案隱含地規範化。
2 EFFECTIVE CAPACITY OF NEURAL NETWORKS
目標是瞭解前饋神經網路的有效模型能力。非引數隨機化測試的方法:採用候選架構,並對真實資料和真實標籤替換為隨機標籤的資料的副本進行訓練。對於後者,例項和類標籤之間不再有任何關係。因此,學習是不可能的。令人驚訝的是,多標準化結構的訓練過程的幾個屬性在很大程度上不受標籤變形的影響。
影象分類資料集:CIFAR10資料集(Krizhevsky&Hinton,2009)和ImageNet(Russakovsky等,2015)ILSVRC 2012資料集。
architecture:Inception V3 (Szegedy et al., 2016) architecture on ImageNet. Alexnet (Krizhevsky et al., 2012), and MLPs on CIFAR10
使用隨機標籤和畫素 FITTING RANDOM LABELS AND PIXELS
實驗使用一下幾種情況:
- 真正的標籤:原始資料集沒有修改。
- 部分損壞的標籤:獨立的概率p,每個影象的標籤被破壞為一個統一的隨機類。
- 隨機標籤:所有標籤都被替換為隨機標籤。
- 混洗畫素:選擇畫素的隨機排列,然後將相同的排列應用於訓練和測試集中的所有影象。
- 隨機畫素:獨立地對每個影象應用不同的隨機排列。
- 高斯:高斯分佈(與原始影象資料集具有匹配均值和方差)用於為每個影象生成隨機畫素。
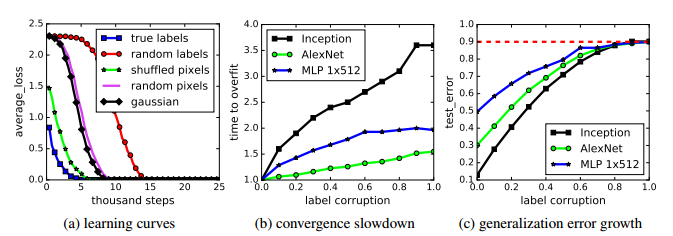
在CIFAR10上安裝隨機標籤和隨機畫素。 (a)顯示了各種實驗設定的訓練損失與培訓步驟的衰減。 (b)顯示了不同標籤損壞率的相對收斂時間,隨著標籤噪聲水平的增加,收斂時間的減慢。 (c)顯示不同標籤損壞下的測試錯誤(也是訓練誤差為0的泛化誤差)。
令人驚訝的是,儘管隨機標籤完全破壞了影象和標籤之間的關係,隨機梯度下降具有不變的超引數設定可以優化權重以適合隨機標籤。 我們通過混洗影象畫素進一步破壞影象的結構,甚至從高斯分佈中完全重新取樣隨機畫素。但是我們測試的網路仍然能夠適應。
3 THE ROLE OF REGULARIZATION
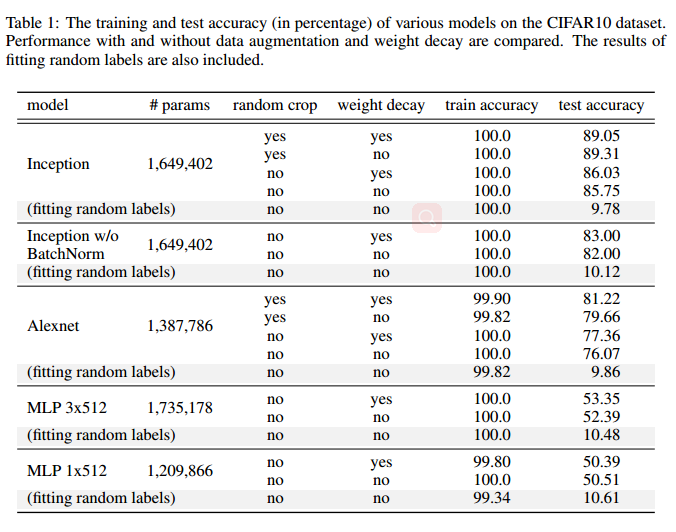
實驗中大多數隨機化測試都是在明確的正規化關閉的情況下執行的。
正如我們將看到的,在深度學習中,明確的正規化似乎發揮了不同的作用。 如附錄中表2的底行所示,即使出現dropout and weight decay,InceptionV3仍然能夠非常適合隨機訓練集。 雖然沒有明確的正則化,weight decay開啟情況下,在CIFAR10上,Inception和MLP都完全適合隨機訓練集。 然而,AlexNetweight decay開啟無法收斂於隨機標籤。 為了調查正規化在深度學習中的作用,我們明確比較了深層網路學習與非正規化學習的行為。
使用了以下regularizers:
- Data augmentation:通過域特定的轉換增加訓練集。對於影象資料,常用的變換包括隨機裁剪,亮度隨機擾動,飽和度,色調和對比度。
- Weight decay: equivalent to a L2 regularizer
- Dropout:以給定的dropout概率隨機遮蔽各層的每個元素的輸出。 ImageNet的Inception V3僅在我們的實驗中使用了退出。
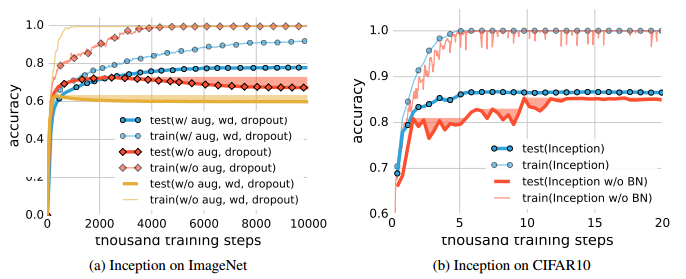
Figure 2:隱性正則化對泛化效能的影響。 aug是資料增加,wd是重量衰減,BN是批量歸一化。 陰影區域是累積最佳測試精度,作為提前停止的潛在效能增益的指標。 (a)當其他正則化不在時,提前停止可能有可能改善泛化。 (b)早期停止對CIFAR10不一定有幫助,但是批處理正則化穩定了訓練過程並改進了泛化。
IMPLICIT REGULARIZATIONS
Early stopping早期停止被顯示為隱含地規範了一些凸出的學習問題。
批量歸一化(Batch normalization,Ioffe&Szegedy,2015)即在每個小批量內歸一化層響應。
圖2b比較了CIFAR10上的Inception的兩個變體的學習曲線,所有的顯式正則符都被關閉。歸一化運營商有助於穩定學習動態,但對泛化績效的影響只有3〜4%。
總而言之,我們對顯式和隱性正則化者的觀察一致地表明,正確的regularizers可以有助於提高泛化效能。然而,regularizers不太可能是泛華的根本原因,因為網路在所有正規者被刪除之後繼續表現良好。
4 FINITE-SAMPLE EXPRESSIVITY
Theorem 1. There exists a two-layer neural network with ReLU activations and 2n+d weights that
can represent any function on a sample of size n in d dimensions.
存在具有ReLU啟用和2n + d權重的雙層神經網路,其可以表示d維中尺寸為n的樣本上的任何函式。
6 CONCLUSION
- 幾個成功的神經網路架構的有效容量足夠大,原則上足以記憶訓練資料。
- 傳統方法使用模型複雜度量度解決了大型人造神經網路的泛化能力。論文認為還沒有發現一個精確的正式措施,在這些措施下,這些巨大的模式是簡單的。
- 即使最終的模型不具有泛化性,優化仍然是經驗上的容易的。這表明優化在經驗上容易的原因肯定與真正的泛化原因不同。
來源
- Zhang C, Bengio S, Hardt M, et al. Understanding deep learning requires rethinking generalization[J]. 2016.
相關推薦
『 論文閱讀』Understanding deep learning requires rethinking generalization
ABSTRACT 雖然其規模巨大,但成功的深層人工神經網路可以獲得訓練和測試集非常小的效能差異。 傳統知識認為這種小的泛化誤差歸功於模型的效能,或者是由於在訓練的時候加入了正則化技術。 通過廣泛的系統實驗,我們展示了這些傳統方法如何不能解釋,而為
『 論文閱讀』A Multi-View Deep Learning Approach for Cross Domain User Modeling in Recommendation Systems
AbstractMULTI-VIEW-DNN聯合了多個域做的豐富特徵,使用multi-view DNN模型構建推薦,包括app、新聞、電影和TV,相比於最好的演算法,老使用者提升49%,新使用者提升110%。並且可以輕鬆的涵蓋大量使用者,解決冷啟動問題。主要做user embedding的過程,通多使用者在多
【論文閱讀筆記】Deep Learning based Recommender System: A Survey and New Perspectives
【論文閱讀筆記】Deep Learning based Recommender System: A Survey and New Perspectives 2017年12月04日 17:44:15 cskywit 閱讀數:1116更多 個人分類: 機器學習
『 論文閱讀』LightGBM原理-LightGBM: A Highly Efficient Gradient Boosting Decision Tree
17年8月LightGBM就開源了,那時候就開始嘗試上手,不過更多還是在調參層面,在作者12月論文發表之後看了卻一直沒有總結,這幾天想著一定要翻譯下,自己也梳理下GBDT相關的演算法。 Abstract Gradient Boosting Decision Tr
『 論文閱讀』Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling
來自於論文:《Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling》 基於attention的encoder-decoder網
論文閱讀 | DeepDrawing: A Deep Learning Approach to Graph Drawing
作者:Yong Wang, Zhihua Jin, Qianwen Wang, Weiwei Cui, Tengfei Ma and Huamin Qu 本文發表於VIS2019, 來自於香港科技大學的視覺化小組(屈華民教授領導)的研究 1. 簡介 圖資料廣泛用於各個領域,例如生物資訊學,金融和社交網路分析。
論文筆記-Wide & Deep Learning for Recommender Systems
wiki body pos ear recommend sys con 損失函數 wrapper 本文提出的W&D是針對rank環節的模型。 網絡結構: 本文提出的W&D是針對rank環節的模型。 網絡結構: wide是簡單的線性模型,但
論文閱讀計劃2(Deep Joint Rain Detection and Removal from a Single Image)
rem 領域 深度學習 conf mage 圖片 多任務 RoCE deep Deep Joint Rain Detection and Removal from a Single Image[1] 簡介:多任務全卷積從單張圖片中去除雨跡。本文在現有的模型上,開發了一種多
論文閱讀14:Reinforcement learning approach towards effective content recommendation in MOOC environments
參考論文:Reinforcement learning approach towards effective content recommendation in MOOC environments #論文筆記:Reinforcement learning approach to
【論文閱讀】Between-class Learning for Image Classification
文章:Between-class Learning for Image Classification 連結:https://arxiv.org/pdf/1711.10284.pdf CVPR2018 作者嘗試了將在音訊上的方法用在影象上的,並提出了一種將影象作為波形處理的混合方法(作者認為圖形波長融
論文閱讀:Disentangled Representation Learning GAN for Pose-Invariant Face Recognition
ICCV2017的文章,主要使用multi-task的GAN網路來提取pose-invariant特徵,同時生成指定pose的人臉。 下載連結: 作者: Motivation: 對於大pose的人臉識別,現在大家都是兩種方案:1 先轉正再人臉識別。2 直接學習
論文閱讀之獻給新手的深度學習綜述——Recent Advances in Deep Learning: An Overview
這篇綜述論文列舉出了近年來深度學習的重要研究成果,從方法、架構,以及正則化、優化技術方面進行概述。本人認為,這篇綜述對於剛入門的深度學習新手是一份不錯的參考資料,在形成基本學術界圖景、指導文獻查詢等方面都能提供幫助。 論文地址:https://arxiv.org/pdf/1807.08169v1
《End-to-End Learning of Motion Representation for Video Understanding》論文閱讀
CVPR 2018 | 騰訊AI Lab、MIT等機構提出TVNet:可端到端學習視訊的運動表徵 動機 儘管端到端的特徵學習已經取得了重要的進展,但是人工設計的光流特徵仍然被廣泛用於各類視訊分析任務中。為了彌補這個不足而提出; 以前的方法:
【論文閱讀】韓鬆《Efficient Methods And Hardware For Deep Learning》節選《Learning both Weights and Connections 》
Pruning Deep Neural Networks 本節內容主要來自NIPS 2015論文《Learning both Weights and Connections for Efficient Neural Networks》。 這部分主要介紹如何剪枝網路
part-aligned系列論文:1707.Deep Representation Learning with Part Loss for Person ReID 論文閱讀筆記
Deep Representation Learning with Part Loss for Person ReID 本論文為了更好的提升reid模型在未見過的行人影象判別能力,正對現有大部分只有全域性特徵表達(轉化為分類,一般minimize the em
論文閱讀-《BlitzNet: A Real-Time Deep Network for Scene Understanding》
ICCV 2017 1.Motivation: 為了做到實時的目標檢測和語義分割 2.Framework 採用的是Resnet50+SSD, ssd這種one-stage的檢測器天生適合和分割一塊做。上取樣過程用到的block如下圖所示,除了
A Review on Deep Learning Techniques Applied to Semantic Segmentation 論文閱讀
為了以後的學習方便,把幾篇計算機視覺的論文放上來,僅為自己的學習方便。期間有參考了很多部落格和文獻,但是我寫的仍然很粗糙,存在很多的疑問。這篇文章是第一篇有關語義分割的總結,可能大學畢設會用到,暫時先簡單總結一下自己的所得。 大學快要畢業了,開始準備畢設,分割方向逃不了了。提示:排版對手機端
Wide & Deep Learning for Recommender Systems 論文閱讀總結
Wide & Deep Learning for Recommender Systems 論文閱讀總結 文章目錄 Wide & Deep Learning for Recommender Systems 論文閱讀總結 Abstract
【論文閱讀】Rethinking Spatiotemporal Feature Learning For Video Understanding
【論文閱讀】Rethinking Spatiotemporal Feature Learning For Video Understanding 這是一篇google的論文,它和之前介紹的一篇facebook的論文的研究內容非常相似連結地址,兩篇論文放到ArXiv上只相差了一個月,但是個
論文閱讀——《Crafting a Toolchain for Image Restoration by Deep Reinforcement Learning》
對於同一張圖片的不同區域,需要的denoise的網路是一樣的嗎?有些區域可能很簡單的網路就可以實現很好的效果,但有些區域需要比較複雜的網路才可以得到不錯的效果。 對於不同的圖片,也是如此,有些圖片需要複雜的網路,有些圖片不需要複雜的網路。 如何的自適應地去應對不同的condition?