
Overfitting機器學習中過度擬合問題
過度擬合:機器從樣本資料中過度的學習了太多的區域性特徵,在測試集中會出現識別率低的情況。
1.過度擬合(從知乎上看到的)
(1)對於機器來說,在使用學習演算法學習資料的特徵的時候,樣本資料的特徵可以分為區域性特徵和全域性特徵,全域性特徵就是任何你想學習的那個概念所對應的資料都具備的特徵,而區域性特徵則是你用來訓練機器的樣本里頭的資料專有的特徵.
(2)在學習演算法的作用下,機器在學習過程中是無法區別區域性特徵和全域性特徵的,於是機器在完成學習後,除了學習到了資料的全域性特徵,也可能習得一部分區域性特徵,而習得的區域性特徵比重越多,那麼新樣本中不具有這些區域性特徵但具有所有全域性特徵的樣本也越多,於是機器無法正確識別符合概念定義的“正確”樣本的機率也會上升,也就是所謂的“泛化性”變差,這是過擬合會造成的最大問題.
(3)所謂過擬合,就是指把學習進行的太徹底,把樣本資料的所有特徵幾乎都習得了,於是機器學到了過多的區域性特徵,過多的由於噪聲帶來的假特徵,造成模型的“泛化性”和識別正確率幾乎達到谷點,於是你用你的機器識別新的樣本的時候會發現就沒幾個是正確識別的.
(4)解決過擬合的方法,其基本原理就是限制機器的學習,使機器學習特徵時學得不那麼徹底,因此這樣就可以降低機器學到區域性特徵和錯誤特徵的機率,使得識別正確率得到優化.
打個形象的比方,給一群天鵝讓機器來學習天鵝的特徵,經過訓練後,知道了天鵝是有翅膀的,天鵝的嘴巴是長長的彎曲的,天鵝的脖子是長長的有點曲度,天鵝的整個體型像一個“2”且略大於鴨子.這時候你的機器已經基本能區別天鵝和其他動物了。
然後,很不巧你的天鵝全是白色的,於是機器經過學習後,會認為天鵝的羽毛都是白的,以後看到羽毛是黑的天鵝就會認為那不是天鵝.
來分析一下上面這個例子:(1)中的規律都是對的,所有的天鵝都有的特徵,是全域性特徵;然而,(2)中的規律:天鵝的羽毛是白的.這實際上並不是所有天鵝都有的特徵,只是區域性樣本的特徵。機器在學習全域性特徵的同時,又學習了局部特徵,這才導致了不能識別黑天鵝的情況.
2。如何解決Overfitting?
增加訓練資料集的量是減少overfitting的途徑之一,減小神經網路的規模, 但是更深層更大的網路潛在有更強的學習能力
即使對於固定的神經網路和固定的訓練集, 仍然可以減少overfitting
1.可以通過Regularization減少overfitting
2.可以通過dropout
正則化(regularization)
下面簡單介紹
1.最常見的一種Regularization:L2 Regularization

在cross-entropy的基礎上增加一項:權重之和(對於神經網路裡面所有權重W相加)
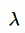 :regularization引數
:regularization引數
n :訓練集例項的個數
對於二次Cost:
regularization 二次Cost:
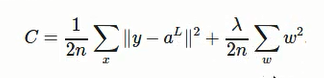
綜上:可以概括表示為
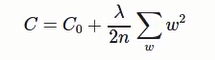
regularization的cost偏向神經網路學習比較小的權重W
:調整兩項的相對重要程度, 較小的λ傾向於讓第一項Co最小化. 較大的λ傾向與最小化增大的項(權重之和).

根據梯度下降演算法,更新法則為:

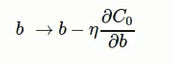

加入regularization不僅減小了overfitting, 還對避免陷入區域性最小點 (local minimum), 更容易重現實驗結果
2.為什麼regularization可以減少overfitting?
因為在神經網路中,Regularized網路更鼓勵小的權重, 小的權重的情況下, x一些隨機的變化不會對神經網路的模型造成太大影響, 所以更小可能受到資料區域性噪音的影響.
Un-regularized神經網路, 權重更大, 容易通過神經網路模型比較大的改變來適應資料,更容易學習到區域性資料的噪音
而Regularized更傾向於學到更簡單一些的模型
但是簡單的模型不一定總是更好,要從大量資料實驗中獲得,目前新增regularization可以更好的泛化更多的從實驗中得來,理論的支援還在研究之中
3. L1 Regularization
L1 Regularization cost函式為:
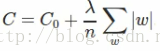
對C關於w求偏導得:
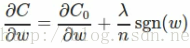
sgn(w)表示為符號函式,w為正,結果為1,w為負結果為-1。
權重的更新法則為:
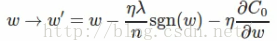
與L2 Regularization對比: 兩者都是減小權重,但方式不同:
L1減少一個常量(η,λ,n根據輸入都是固定的,sgn(w)為1或-1,故為常量)
而L2減少的是權重的一個固定的比例;如果權重本身很大的話,L2減少的比L1減少的多
若權重小,則L1減少的更多。多以L1傾向於集中在少部分重要的連線上(w小)
這裡要注意的是:sgn(w)在w=0時不可導,故要事先令sgn(w)在w=0時的導數為0
Dropout
Dropout的目的也是用來減少overfitting(過擬合)。而和L1,L2Regularization不同的是,Dropout不是針對cost函式,而是改變神經網路本身的結構。下面開始簡單的假設Dropout。
假設有一個神經網路:
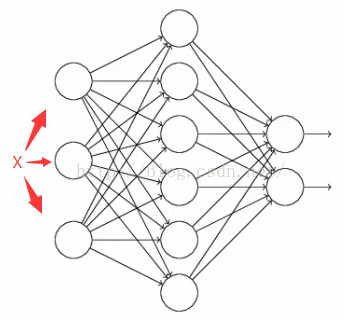
按照之前的方法,根據輸入X,先正向更新神經網路,得到輸出值,然後反向根據backpropagation演算法來更新權重和偏向。而Dropout不同的是,
1)在開始,隨機刪除掉隱藏層一半的神經元,如圖,虛線部分為開始時隨機刪除的神經元:
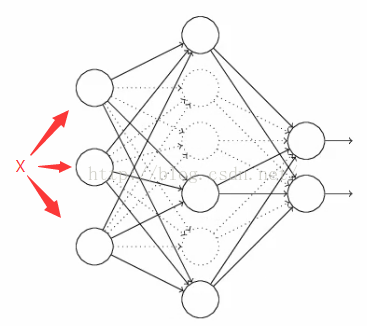
2)然後,在刪除後的剩下一半的神經元上正向和反向更新權重和偏向;
3)再恢復之前刪除的神經元,再重新隨機刪除一半的神經元,進行正向和反向更新w和b;
4)重複上述過程。
最後,學習出來的神經網路中的每個神經元都是在只有一半的神經元的基礎上學習的,因為更新次數減半,那麼學習的權重會偏大,所以當所有神經元被回覆後(上述步驟2)),把得到的隱藏層的權重減半。
對於Dropout為什麼可以減少overfitting的原因如下:
一般情況下,對於同一組訓練資料,利用不同的神經網路訓練之後,求其輸出的平均值可以減少overfitting
Dropout就是利用這個原理,每次丟掉一半的一隱藏層神經元,相當於在不同的神經網路上進行訓練,這樣就減少了神經元之間的依賴性
即每個神經元不能依賴於某幾個其他的神經元(指層與層之間相連線的神經元)
使神經網路更加能學習到與其他神經元之間的更加健壯robust的特徵。
在Dropout的作者文章中,測試手寫數字的準確率達到了98.7%!所以Dropout不僅減少overfitting,還能提高準確率
下面給出Dropout的Python程式碼:
注意:由於Dropout在訓練的時候是用了一部分的神經元去做訓練,在在測試階段由於我們是用整個網路去訓練,因此我們需要注意在訓練的時候為每個存活下來的神經元做同取樣比例的放大(除以p),注意,這隻在訓練時候做,用以保證訓練得到的權重在組合之後不會太大;另外一種選擇就是把測試結果根據取樣比例縮小(乘於p)
def dropout_forward(x, dropout_param):
"""
Performs the forward pass for (inverted) dropout.
Inputs:
- x: Input data, of any shape
- dropout_param: A dictionary with the following keys:
- p: Dropout parameter. We drop each neuron output with probability p.
- mode: 'test' or 'train'. If the mode is train, then perform dropout;
if the mode is test, then just return the input.
- seed: Seed for the random number generator. Passing seed makes this
function deterministic, which is needed for gradient checking but not in
real networks.
Outputs:
- out: Array of the same shape as x.
- cache: A tuple (dropout_param, mask). In training mode, mask is the dropout
mask that was used to multiply the input; in test mode, mask is None.
"""
p, mode = dropout_param['p'], dropout_param['mode']
if 'seed' in dropout_param:
np.random.seed(dropout_param['seed'])
mask = None
out = None
if mode == 'train':
mask = (np.random.rand(*x.shape) < p)/p
out = x*mask
pass
elif mode == 'test':
out = x*(np.random.rand(*x.shape) < p)/p
pass
cache = (dropout_param, mask)
out = out.astype(x.dtype, copy=False)
return out, cache
def dropout_backward(dout, cache):
"""
Perform the backward pass for (inverted) dropout.
Inputs:
- dout: Upstream derivatives, of any shape
- cache: (dropout_param, mask) from dropout_forward.
"""
dropout_param, mask = cache
mode = dropout_param['mode']
dx = None
if mode == 'train':
dx = dout * mask
pass
elif mode == 'test':
dx = dout
return dx
相關推薦
Overfitting機器學習中過度擬合問題
過度擬合:機器從樣本資料中過度的學習了太多的區域性特徵,在測試集中會出現識別率低的情況。 1.過度擬合(從知乎上看到的) (1)對於機器來說,在使用學習演算法學習資料的特徵的時候,樣本資料的特徵可以分為區域性特徵和全域性特徵,全域性特徵就是任何你想學習的那個概念所對應
機器學習中過擬合原因和防止過擬合的方法
過擬合原因: 由於訓練資料包含抽樣誤差,訓練時,複雜的模型將抽樣誤差也考慮在內,將抽樣誤差也進行了很好的擬合,如 1、比如資料不夠, 2、訓練太多擬合了資料中的噪聲或沒有代表性的特徵也就是模型太複雜 所以防止過擬合的方法: 1.獲取更多的資料 1).從
吳恩達機器學習之過擬合問題
一、過擬合問題:———什麼是過度擬合問題? 1.1兩個例子: 例子一: 模型假設函式 的形式: 一次函式 二次函式 高階多項式 模型擬合效果:
機器學習:欠擬合和過擬合
1. 什麼是欠擬合和過擬合 先看三張圖片,這三張圖片是線性迴歸模型 擬合的函式和訓練集的關係 第一張圖片擬合的函式和訓練集誤差較大,我們稱這種情況為 欠擬合 第二張圖片擬合的函式和訓練集誤差較小,我們稱這種情況為 合適擬合 第三張圖片擬合的函式
機器學習之過擬合欠擬合
機器學習之過擬合,欠擬合 過擬合現象是指當我們能夠提高訓練集上的表現時,然而測試集的表現很差,例如在深度學習中經常訓練集達到99以上而資料集卻在50,60左右明顯過擬合,此時就要想辦法阻止過擬合,過擬合也成為過配。 過擬合發生的本質原因,是由於監督學習問題的不適定:在高中數學我們知道,從n個
機器學習基礎--過擬合和欠擬合
過擬合和欠擬合 1)欠擬合:機器學習模型無法得到較低訓練誤差。 2)過擬合:機器學習模型的訓練誤差遠小於其在測試資料集上的誤差。 我們要儘可能同時避免欠擬合和過擬合的出現。雖然有很多因素可能導致這兩種擬合問題,在這裡我們重點討論兩個因素:模型的選擇和
【機器學習】過擬合、欠擬合與正則化
過擬合(over-fitting) 在演算法對模型引數的學習過程中,如果模型過於強大,比如說,樣本空間分佈在一條直線的附近,那麼我們的模型最好是一條直線, h
機器學習迴歸演算法擬合多項式
code:import numpy as np from sklearn.linear_model import LinearRegression, RidgeCV, LassoCV, ElasticNetCV from sklearn.preprocessing impor
機器學習防止過擬合之L1範數(正則)與LASSO
機器學習過擬合問題 對於機器學習問題,我們最常遇到的一個問題便是過擬合。在對已知的資料集合進行學習的時候,我們選擇適應度最好的模型最為最終的結果。雖然我們選擇的模型能夠很好的解釋訓練資料集合,但卻不一定能夠很好的解釋測試資料或者其他資料,也就是說這個模型過於精
機器學習防止過擬合---正則化
機器學習中,過擬合是一件比較頭疼的事情,明明模型在訓練樣本上表現的很好,但在測試樣本上卻表現的較差,泛化能力不好。比如強大的神經網路就常常被過擬合問題困擾。 為了避免過擬合,最常用的一種方法是使用正則化,L1正則化和L2正則化可以看做是損失函式的懲罰項,就是對損失函式中的某些引數做一些限制。
機器學習之——欠擬合與過擬合
我從網上找了很多的資料,但是也沒有很明確的定義,大體上的意思就是: 欠擬合:模型擬合不夠,在訓練集(training set)上表現效果差,沒有充分利用資料,預測的準確率比我們設計的模型遠遠低很多,擬
機器學習之過擬合的解決方法
過擬合 過擬合,是指模型在訓練集上表現的很好,但是在交叉驗證集合測試集上表現一般,也就是說模型對未知樣本的預測表現一般,泛化(generalization)能力較差。 一般防止過擬合的方法有early stopping、資料集擴增(Data augmen
深度學習中過擬合與防止過擬合的方法
1.什麼是過擬合? 過擬合(overfitting)是指在模型引數擬合過程中的問題,由於訓練資料包含抽樣誤差,訓練時,複雜的模型將抽樣誤差也考慮在內,將抽樣誤差也進行了很好的擬合。 具體表現就是最終模型在訓練集上效果好;在測試集上效果差。模型泛化能力弱。 2.過擬合產
深度學習中“過擬合”的產生原因和解決方法
過擬合定義:模型在訓練集上的表現很好,但在測試集和新資料上的表現很差。 訓練集上的表現 測試集上的表現 結論 不好 不好 欠擬合 好 不好 過擬合 好 好 適度擬合 原因 訓練資料集太小,過擬合出現的原因: 模型複雜度過
深度學習中過擬合、欠擬合問題及解決方案
在進行資料探勘或者機器學習模型建立的時候,因為在統計學習中,假設資料滿足獨立同分布(i.i.d,independently and identically distributed),即當前已產生的資料可以對未來的資料進行推測與模擬,因此都是使用歷史資料建立模型,即使用已經產生的資料去訓練,然後使用該模型去
機器學習中:過擬合(overfitting)和欠擬合(underfitting)
Underfitting is easy to check as long as you know what the cost function measures. The definition of the cost function in linear regression is half the me
機器學習中防止過擬合方法
從數據 tro 輸出 效果 沒有 imagenet neu 效率 公式 過擬合 ??在進行數據挖掘或者機器學習模型建立的時候,因為在統計學習中,假設數據滿足獨立同分布,即當前已產生的數據可以對未來的數據進行推測與模擬,因此都是使用歷史數據建立模型,即使用已經產生的數據去訓練
機器學習中的過擬合和欠擬合現象,以及通過正則化的方式解決。
過擬合: 過擬合(over-fitting)是所建的機器學習模型或者是深度學習模型在訓練樣本中表現得過於優越,導致在驗證資料集以及測試資料集中表現不佳的現象。就像上圖中右邊的情況。 過擬合的模型太過具體從而缺少泛化能力,過度的擬合了訓練集中的資料。出現的原因是模型將其中的不重要的變
機器學習中擬合與過擬合
擬合的基礎概念。首先任何函式都可以用多項式f(x)的方式去趨近,因此我們令f(x) = w0x0+w1x1+...+wnxn.首先,用一個例子來理解什麼是過擬合,假設我們要根據特徵分類{男人X,女人O}
機器學習問題中過擬合出現的原因及解決方案
如果一味的追求模型的預測能力,所選的模型複雜度就會過高,這種現象稱為過擬合。模型表現出來的就是訓練模型時誤差很小,但在測試的時候誤差很大。 一、產生的原因: 1.樣本資料問題 樣本資料太少 樣本抽樣不符合業務場景 樣本中的噪音資料影響 2.模型問題 模型複雜度高,引