
KMP演算法初探
關於字串的演算法,很早就知道KMP演算法,但是一直沒有理解,正好這個假期沒多少事,可以好好琢磨一下這個演算法。下面結合一道題目來說明KMP演算法要解決的問題。
【題目】
給定兩個字串str和match,長度分別為N和M。實現一個演算法,如果字串str中含有字串match,則返回match在str中的開始位置,不含有則返回-1。
【舉例】
str=“acbc”,match=“bc”。返回2。
str=“acbc”,match=“bcc”。返回-1。
【要求】
如果match的長度大於str長度(M>N),str必然不會含有match,可直接返回-1。但如果N>=M,要求演算法複雜度O(N)。
這個題目很好理解,就是字串的匹配,首先可以想到的就是從頭開始比較兩個字元是否相等,不相等就從N的下一個字元開始比較就可以了,這個思路沒有錯,它就是最樸素的BF(Brute-Force,最基本的字串匹配演算法)。
一:BF演算法簡介

如上圖所示,原始串S=abcabcabdabba,模式串為abcabd。(下標從0開始)從s[0]開始依次比較S[i] 和T[i]是否相等,直到T[5]時發現不相等,這時候說明發生了失配,在BF演算法中,發生失配時,T必須回溯到最開始,S下標+1,然後繼續匹配,如下圖所示:

這次立即發生了失配,所以繼續回溯,直到S開始下表增加到3,匹配成功。
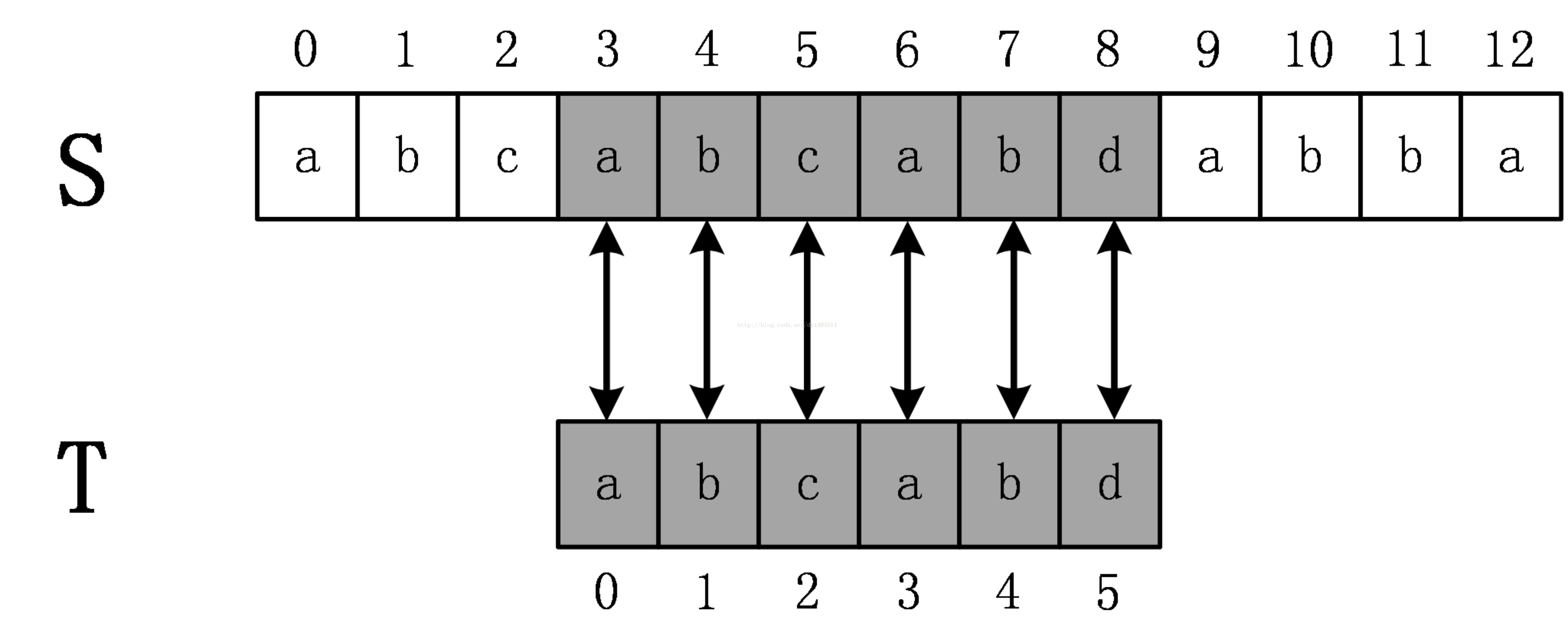
容易得到,BF演算法的時間複雜度是O(n*m)的,其中n為原始串的長度,m為模式串的長度。
二:KMP演算法
前面提到了樸素匹配演算法,它的優點就是簡單明瞭,缺點當然就是時間消耗很大。KMP演算法是對BF演算法的改進,它的主要思想就是:在匹配匹配過程中發生失配時,並不簡單的從原始串下一個字元開始重新匹配,而是根據一些匹配過程中得到的資訊跳過不必要的匹配,從而達到一個較高的匹配效率。
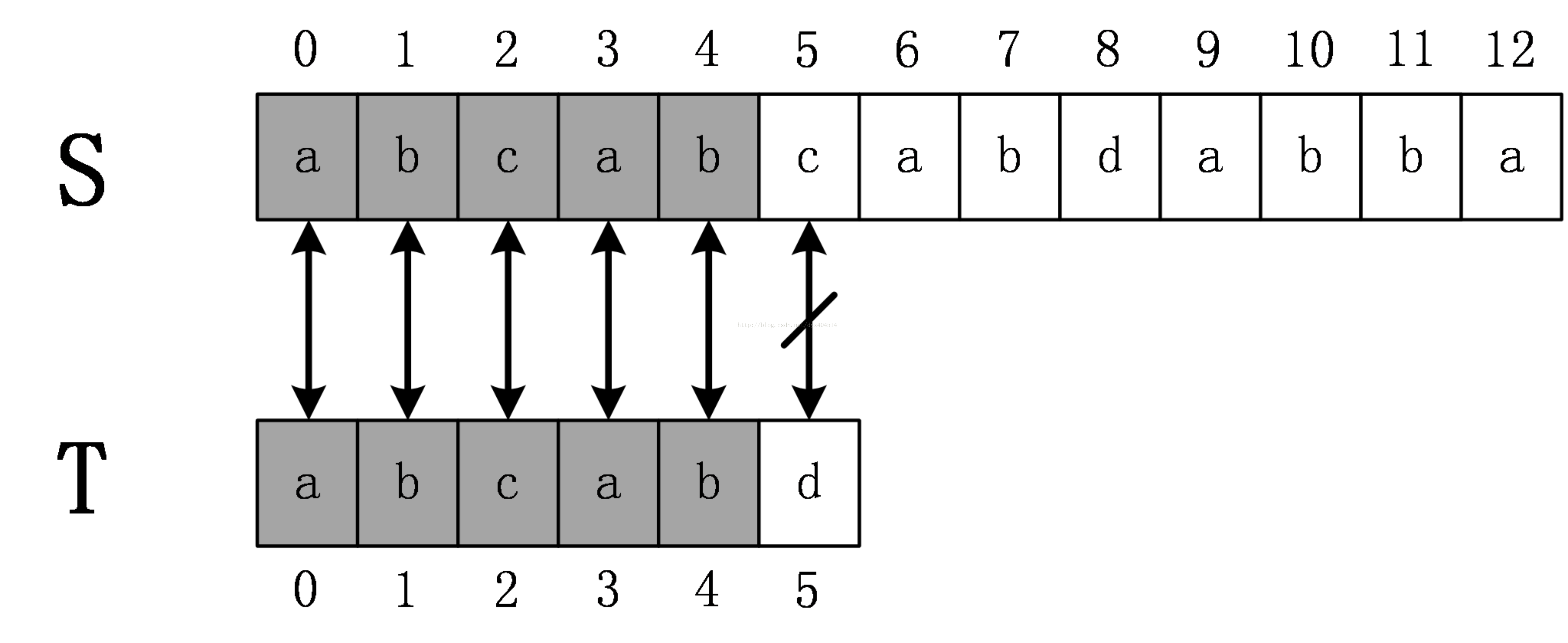
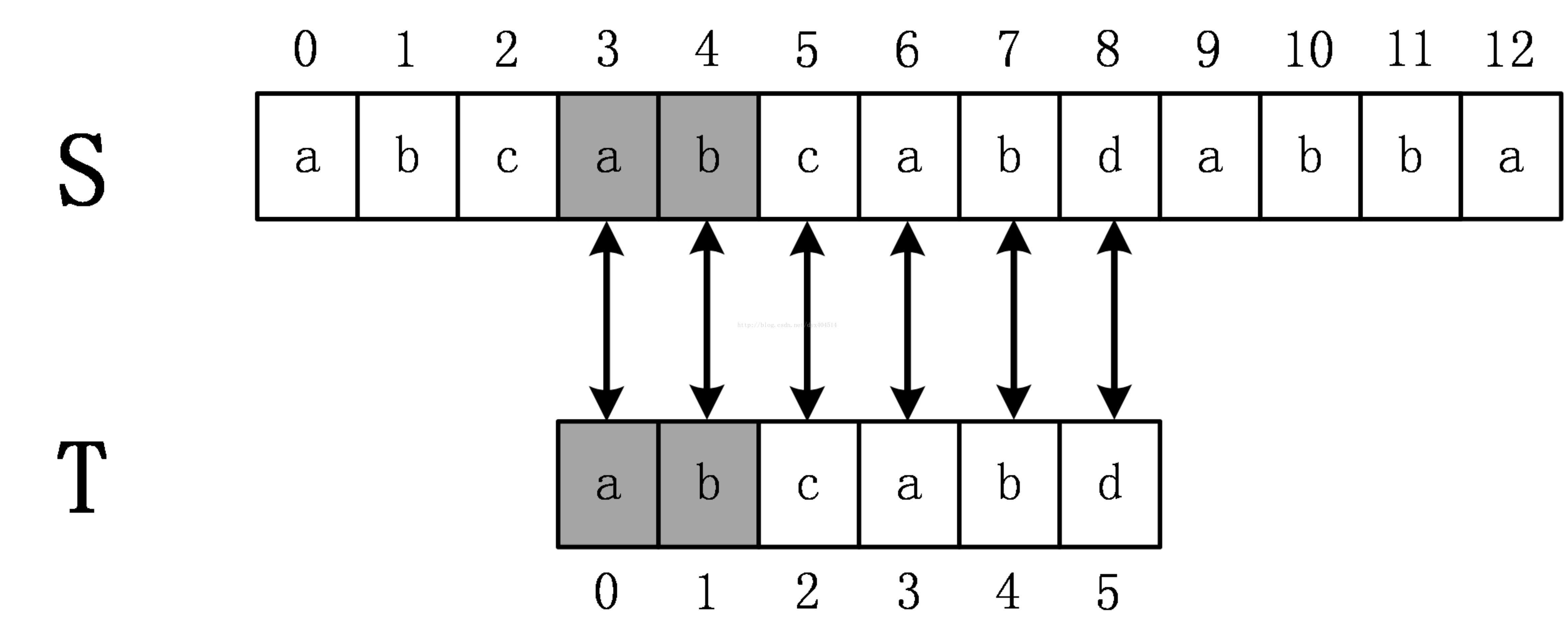
還是前面的例子,原始串S=abcabcabdabba,模式串為abcabd。當第一次匹配到T[5]!=S[5]時,KMP演算法將T向右移動3位,這個位數是怎麼計算的呢?這就需要用到KMP演算法中非常重要的一個東西:next陣列(也叫fail陣列,字首陣列),其實質是對模式串進行預處理。next陣列的具體計算我們後面再說,現在直接給出失配字元d的前一個字元的next陣列值,是2,模式串移動的位數的計算公式為:移動位數 = 已匹配的字元數 - 對應的部分匹配值。該例中移動位數為5-2=3。移動後的匹配過程如下,若出現不匹配,繼續迴圈這個過程,直到完全匹配。
下面介紹next陣列,next陣列的值表示該字元的字首和字尾的最長共有元素的長度。
首先,要了解兩個概念:"字首"和"字尾"。 "字首"指除了最後一個字元以外,一個字串的全部頭部組合;"字尾"指除了第一個字元以外,一個字串的全部尾部組合。

以"ABCDABD"為例,求"字首"和"字尾"的最長的共有元素的長度:
接下來介紹next陣列的計算:- "A"的字首和字尾都為空集,共有元素的長度為0;
- "AB"的字首為[A],字尾為[B],共有元素的長度為0;
- "ABC"的字首為[A, AB],字尾為[BC, C],共有元素的長度0;
- "ABCD"的字首為[A, AB, ABC],字尾為[BCD, CD, D],共有元素的長度為0;
- "ABCDA"的字首為[A, AB, ABC, ABCD],字尾為[BCDA, CDA, DA, A],共有元素為"A",長度為1;
- "ABCDAB"的字首為[A, AB, ABC, ABCD, ABCDA],字尾為[BCDAB, CDAB, DAB, AB, B],共有元素為"AB",長度為2;
- "ABCDABD"的字首為[A, AB, ABC, ABCD, ABCDA, ABCDAB],字尾為[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的長度為0。
設模式串T[0,m-1],長度為m,由next陣列的定義,可知next[0]=next[1]=0,(因為這裡的串的字尾,字首不包括該串本身)。
接下來,假設我們從左到右依次計算next陣列,在某一時刻,已經得到了next[0]~next[i],現在要計算next[i+1],設j=next[i],由於知道了next[i],所以我們知道T[0,j-1]=T[i-j,i-1],現在比較T[j]和T[i],如果相等,由next陣列的定義,可以直接得出next[i+1]=j+1。
如果不相等,那麼我們知道next[i+1]<j+1,所以要將j減小到一個合適的位置po,使得po滿足:
1)T[0,po-1]=T[i-po,i-1]。
2)T[po]=T[i]。
3)po是滿足條件(1),(2)的最大值。
4)0<=po<j(顯然成立)。
如何求得這個po值呢?事實上,並不能直接求出po值,只能一步一步接近這個po,尋找當前位置j的下一個可能位置。如果只要滿足條件(1),那麼j就是一個,那麼下一個滿足條件(1)的位置是什麼呢?,由next陣列的定義,容易得到是next[j]=k,這時候只要判斷一下T[k]是否等於T[i],即可判斷是否滿足條件(2),如果還不相等,繼續減小到next[k]再判斷,直到找到一個位置P,使得P同時滿足條件(1)和條件(2)。我們可以得到P一定是滿足條件(1),(2)的最大值,因為如果存在一個位置x使得滿足條件(1),(2),(4)並且x>po,那麼在回溯到P之前就能找到位置x,否則和next陣列的定義不符。在得到位置po之後,容易得到next[i+1]=po+1。那麼next[i+1]就計算完畢,由數學歸納法,可知我們可以求的所有的next[i]。(0<=i<m)
注意:在回溯過程中可能有一種情況,就是找不到合適的po滿足上述4個條件,這說明T[0,i]的最長前後綴串長度為0,直接將next[i+1]賦值為0,即可。】
public int[] getNextArray(char[] ms) {
if (ms.length == 1) {
return new int[] { 0 };
}
int[] next = new int[ms.length];
next[0]=next[1]=0;//初始化
for(int i=1;i<len;i++)
{
int j=next[i];
while(j&&str[i]!=str[j])//一直回溯j直到str[i]==str[j]或j減小到0
j=next[j];
next[i+1]=str[i]==str[j]?j+1:0;//更新next[i+1]
}
return next;
}有了next陣列,我們就可以通過next陣列跳過不必要的檢測,加快字串匹配的速度了。那麼為什麼通過next陣列可以保證匹配不會漏掉可匹配的位置呢?
首先,假設發生失配時T的下標在i,那麼表示T[0,i-1]與原始串S[l,r]匹配,設next[i]=j,根據KMP演算法,可以知道要將T回溯到下標j再繼續進行匹配,根據next[i]的定義,可以得到T[0,j-1]和S[r-j+1,r]匹配,同時可知對於任何j<y<i,T[0,y]不和S[r-y,r]匹配,這樣就可以保證匹配過程中不會漏掉可匹配的位置。
同next陣列的計算,在一般情況下,可能回溯到next[i]後再次發生失配,這時只要繼續回溯到next[j],如果不行再繼續回溯,最後回溯到next[0],如果還不匹配,這時說明原始串的當前位置和T的開始位置不同,只要將原始串的當前位置+1,繼續匹配即可。
下面給出KMP演算法匹配過程的程式碼:
public int getIndexOf(String s, String m) {
if (s == null || m == null || m.length() < 1 || s.length() < m.length()) {
return -1;
}
char[] ss = s.toCharArray();
char[] ms = m.toCharArray();
int si = 0;
int mi = 0;
int[] next = getNextArray(ms);
while (si < ss.length && mi < ms.length) {
if (ss[si] == ms[mi]) {
si++;
mi++;
} else if (next[mi] == -1) {
si++;
} else {
mi = next[mi];
}
}
return mi == ms.length ? si - mi : -1;
} 前面說到,KMP演算法的時間複雜度是線性的,但這從程式碼中並不容易得到,很多讀者可能會想,如果每次匹配都要回溯很多次,是不是會使演算法的時間複雜度退化到非線性呢?
其實不然,我們對程式碼中的幾個變數進行討論,首先是kmp函式,顯然決定kmp函式時間複雜度的變數只有兩個,i和j,其中i只增加了len次,是O(len)的,下面討論j,因為由next陣列的定義我們知道next[j]<j,所以在回溯的時候j至少減去了1,並且j保證是個非負數。另外,由程式碼可知j最多增加了len次,且每次只增加了1。簡單來說,j每次增加只能增加1,每次減小至少減去1,並且保證j是個非負數,那麼可知j減小的次數一定不能超過增加的次數。所以,回溯的次數不會超過len。綜上所述,kmp函式的時間複雜度為O(len)。同理,對於計算next陣列同樣用類似的方法證明它的時間複雜度為O(len),這裡不再贅述。對於長度為n的原始串S,和長度為m的模式串T,KMP演算法的時間複雜度為O(n+m)。
參考文章:
1、字串匹配的KMP演算法:http://kb.cnblogs.com/page/176818/
2、KMP演算法總結:http://blog.csdn.net/dyx404514/article/details/41314009
3、KMP演算法解析:http://www.ituring.com.cn/article/59881
4、KMP演算法學習與總結:http://www.cnblogs.com/goagent/archive/2013/05/16/3068442.html (含next陣列求解優化)
相關推薦
KMP演算法初探
關於字串的演算法,很早就知道KMP演算法,但是一直沒有理解,正好這個假期沒多少事,可以好好琢磨一下這個演算法。下面結合一道題目來說明KMP演算法要解決的問題。 【題目】 給定兩個字串str和match,長度分別為N和M。實現一個演算法,如果字串str中含有字串match,
從簡單的演算法初探過程彙編 棧幀指標
從簡單的演算法初探過程彙編 棧幀指標 作者:zcabcd123 從簡單的演算法初探過程彙編 轉載自 搗亂小子 趁年輕,用程式碼實現夢想 — daoluan.net 不忽視彙編 較於我們日常接觸的高階語
KMP演算法之next函式解釋(大量的反證法 和數學歸納法來襲)
先放get_nextval()函式的程式碼 void get_nextval(const char str[],int *net) { net[0]=-1; int j=0,k=-1,len; len=strlen(str); while(j<len)
一文讀懂 KMP 演算法
來源:阮一峰http://www.ruanyifeng.com/blog/2013/05/Knuth–Morris–Pratt_algorithm.html 字串匹配是計算機的基本任務之一。舉例來說,有一個字串"BBC ABCDAB ABCDABCDABDE",我想知道,裡面是否包
KMP演算法與其應用
KMP字串匹配 題目連結:https://www.luogu.org/problemnew/show/P3375 1.nxt陣列: nxt[x]:以x位結尾的字串為字尾能匹配到的最長字首。 求法見程式碼: nxt[1]=0;int j=0; for(int i=2;i<
KMP演算法淺顯理解
說明:轉載 KMP演算法看懂了覺得特別簡單,思路很簡單,看不懂之前,查各種資料,看的稀裡糊塗,即使網上最簡單的解釋,依然看的稀裡糊塗。 我花了半天時間,爭取用最短的篇幅大致搞明白這玩意到底是啥。 這裡不扯概念,只講演算法過程和程式碼理解: KMP演算法求解什麼型別問題 字串匹配。給
hihoCoder week3 KMP演算法
題目連結 https://hihocoder.com/contest/hiho3/problems kmp演算法 #include <bits/stdc++.h> using namespace std; const int N = 1e6 + 10; cha
KMP演算法(字串)
純模板題:HDU1686 #include<cstdio> #include<cstdlib> #include<cstring> #define INF 1000005 int next[INF]; char a[INF],b[INF]; void
KMP演算法最淺顯理解
說明 KMP演算法看懂了覺得特別簡單,思路很簡單,看不懂之前,查各種資料,看的稀裡糊塗,即使網上最簡單的解釋,依然看的稀裡糊塗。 我花了半天時間,爭取用最短的篇幅大致搞明白這玩意到底是啥。 這裡不扯概念,只講演算法過程和程式碼理解: KMP演算法求解什麼型別問題
有一個文字串S和一個模式串P,要查詢P在S中的位置——KMP演算法
關鍵是求解NEXT陣列 Next陣列就是當前字元之前的字串中,有多大長度的相同字首與字尾 public class KMP { /** * KMP演算法的實現 */ /** * 求解NEXT陣列 */ private static void getNex
leetcode 214 Shortest Palindrome kmp演算法 字首字尾字串匹配
0 leetcode 214. Shortest Palindrome 本題的描述是一個串前方加上一些字串,使其成為一個迴文串。 形式類似於(新增部分)(迴文部分)(其餘部分),所以我們的目標就是將其迴文部分求出來,或者把他的長度求出來。 如果用暴力解法,那麼問題就變成
KMP 演算法(1):如何理解 KMP
http://www.61mon.com/index.php/archives/183/ 系列文章目錄 KMP 演算法(1):如何理解 KMPKMP 演算法(2):其細微之處 一:背景TOC 給定一個主字串(以 S 代替)和模式串(以 P 代替),要
KMP演算法模板 - 構建next最長字首陣列 與 kmp核心演算法
#include <iostream> #include <string> using namespace std; //構建next最長字首陣列 int* getNextArray(const string &sub) { if(sub.length() ==
【KMP演算法改進】C++
mark明天來和順便描述一下原本kmp, kmp和bf演算法 在文字串 i=0時匹配就成功的話基本相同,且bf不用計算next陣列,、 然而bf演算法,如果匹配失敗,會從i=1,i=2,逐個逐個的匹配,浪費時間 kmp演算法,在發現匹配失敗的時候,文字串匹配失敗位置前面的字串是匹配好
菜鷄日記——KMP演算法及其優化與應用
一、什麼是KMP演算法 KMP演算法,全稱Knuth-Morris-Pratt演算法,由三位科學家的名字組合命名,是一種效能高效的字串匹配演算法。假設有主串S與模式串T,KMP演算法可以線上性的時間內匹配出S中的T,甚至還能處理由多個模式串組成的字典的匹配問題。 二、KMP演算法原理及實現
python資料結構之KMP演算法的實現
我相信網上已經有很多關於KMP演算法的講解,大致都是關於部分匹配表的實現思路和作用,還有就是目標串的下標不變,僅改變模式串的下標來進行匹配,確實用KMP演算法,當目標串很大模式串很小時,其效率很高的,但都是相對而言。至於對於部分匹配表的作用以及實現思路,建議看一下這篇文章寫的是比較易懂的
字元匹配KMP演算法
KMP是三位大牛:D.E.Knuth、J.H.Morris和V.R.Pratt同時發現的。其中第一位就是《計算機程式設計藝術》的作者!! KMP演算法要解決的問題就是在字串(也叫主串)中的模式(pattern)定位問題。就是我們平時常說的關鍵字搜尋。模式串就是關鍵字(接下來稱它為T),如果它
有關串的模式匹配問題中的kmp演算法(俗稱 看毛片演算法)
========前言====== 最近準備考研,於是重新拾起資料結構這本書(嚴老師的) 對於之前的看毛片演算法想用自己的方式重新總結一下 ========沒有這方面基礎的先看 這個網址 (該網址為百度百科 本人只分享跟連結 若有其他影響本人概不負責)
kmp演算法易懂
來自http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html 並進行自己的簡單整理,還加了程式碼實現。 因為作者實在太弱,以至自己找了一堆解釋才弄明白,所以按照比較好懂的方式講一講 &
用於字串匹配的KMP演算法
KMP演算法的理解分為兩個部分: 1.如何利用next陣列(最大前後綴長度)匹配字元。 藉助next陣列,原字串的i可以不回移,如果當前字元失配則前模式串的j即可。因為雖然當前s[i]和t[j]失配,但是我們知道j之前的字元是匹配的,只要確定t[0]~t[j-1]的最長前後綴,就可以通過移動