
kmp演算法易懂
來自http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html
並進行自己的簡單整理,還加了程式碼實現。
因為作者實在太弱,以至自己找了一堆解釋才弄明白,所以按照比較好懂的方式講一講
進入正題。
字串匹配是計算機的基本任務之一。
舉例來說,有一個字串"BBC ABCDAB ABCDABCDABDE"(記為str1),我想知道,裡面是否包含另一個字串"ABCDABD"(記為str2)?
容易想到普通暴搜:
1.

首先,字串"BBC ABCDAB ABCDABCDABDE"的第一個字元與搜尋詞"ABCDABD"的第一個字元,進行比較。因為B與A不匹配,所以搜尋詞後移一位。
2.

因為B與A不匹配,搜尋詞再往後移。
3.

就這樣,直到字串有一個字元,與搜尋詞的第一個字元相同為止。
4.

接著比較字串和搜尋詞的下一個字元,還是相同。
5.

直到字串有一個字元,與搜尋詞對應的字元不相同為止。
6.

這時,暴搜的反應是,將搜尋詞整個後移一位,再從頭逐個比較。這樣做雖然可行,但是效率很差,因為你要把"搜尋位置"移到已經比較過的位置,重比一遍。
7.
一個基本事實是,當空格與D不匹配時,你其實知道前面六個字元是"ABCDAB"。KMP演算法的想法是,設法利用這個已知資訊,不要把"搜尋位置"移回已經比較過的位置,繼續把它向後移,這樣就提高了效率。
在講kmp之前,先引入一個概念--部分匹配值(陣列next)。
首先,要了解兩個概念:"字首"和"字尾"。 "字首"指除了最後一個字元以外,一個字串的全部頭部組合;"字尾"指除了第一個字元以外,一個字串的全部尾部組合。
1.
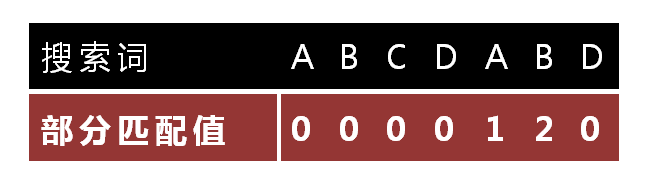
"部分匹配值"就是"字首"和"字尾"的最長的共有元素的長度。以"ABCDABD"為例,
- "A"的字首和字尾都為空集,共有元素的長度為0;
- "AB"的字首為[A],字尾為[B],共有元素的長度為0;
- "ABC"的字首為[A, AB],字尾為[BC, C],共有元素的長度0;
- "ABCD"的字首為[A, AB, ABC],字尾為[BCD, CD, D],共有元素的長度為0;
- "ABCDA"的字首為[A, AB, ABC, ABCD],字尾為[BCDA, CDA, DA, A],共有元素為"A",長度為1;
- "ABCDAB"的字首為[A, AB, ABC, ABCD, ABCDA],字尾為[BCDAB, CDAB, DAB, AB, B],共有元素為"AB",長度為2;
- "ABCDABD"的字首為[A, AB, ABC, ABCD, ABCDA, ABCDAB],字尾為[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的長度為0。
2.

"部分匹配"的實質是,有時候,字串頭部和尾部會有重複。比如,"ABCDAB"之中有兩個"AB",那麼它的"部分匹配值"就是2("AB"的長度)。搜尋詞移動的時候,第一個"AB"向後移動4位(字串長度-部分匹配值),就可以來到第二個"AB"的位置。
現在來講kmp
1.
這裡是一張匹配表。
2.
已知空格與D不匹配時,前面六個字元"ABCDAB"是匹配的。查表可知,最後一個匹配字元B對應的"部分匹配值"為2,因此按照下面的公式算出向後移動的位數:
移動位數 = 已匹配的字元數 - 對應的部分匹配值
因為 6 - 2 等於4,所以將搜尋詞向後移動4位。
3.

因為空格與C不匹配,搜尋詞還要繼續往後移。這時,已匹配的字元數為2("AB"),對應的"部分匹配值"為0。所以,移動位數 = 2 - 0,結果為 2,於是將搜尋詞向後移2位。
4.
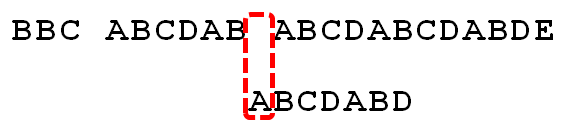
因為空格與A不匹配,繼續後移一位。
5.
逐位比較,直到發現C與D不匹配。於是,移動位數 = 6 - 2,繼續將搜尋詞向後移動4位。
6.

逐位比較,直到搜尋詞的最後一位,發現完全匹配,於是搜尋完成。如果還要繼續搜尋(即找出全部匹配),移動位數 = 7 - 0,再將搜尋詞向後移動7位,這裡就不再重複了。
最後是程式碼
我們來一部分一部分分開看
先是最重要的next(部分匹配值)
for(int i=2;i<=len2;i++)//處理next { while(i1&&str2[i1+1]!=str2[i]) //如果str2[i1+1]!=str2[i]那麼這串連續的相等斷了,所以我們無法繼承之前的情況 { i1=next[i1]; //記得next的含義嗎,順著next我們可以找到能夠讓我們繼續匹配的值,但i1不能為0並且如果我們找到了str2[i1+1]==str2[i]的地方,那麼我們就可以從這裡開始繼承 } if(str2[i1+1]==str2[i]) { i1++;//相等就比下一個,同時這也是計數+1 } next[i]=i1;//把算出的值告訴next }
其實我覺得kmp十分重要的一點就是理解求next和最後答案的聯絡
所謂next,其實就是自己(str2)和自己(str2)的一個部分匹配值
而最後答案與自己(str2)和別人(str1)的匹配有關
兩者的實質是一樣的,所以如果向下翻,看最後總程式碼的話,可以發現,兩個for迴圈不過就是複製貼上了一下,然後進行稍微改動(建議明白整個演算法後,自行思考改動原因)
當你明白了這點,求str1和str2的匹配就不成問題了
所以我們就可以直接看總程式碼了
#include<iostream> #include<cstdio> #include<cstring> using namespace std; char str1[1000005],str2[1000005]; int len1,len2,i1; int next[1000005]; int main() { scanf("%s %s",str1+1,str2+1); len1=strlen(str1+1); len2=strlen(str2+1); for(int i=2;i<=len2;i++)//處理next { while(i1&&str2[i1+1]!=str2[i]) { i1=next[i1]; } if(str2[i1+1]==str2[i]) { i1++; } next[i]=i1; } i1=0;//別忘初始化 for(int i=1;i<=len1;i++)//怎麼樣,是不是和求next差不多? { while(i1&&str2[i1+1]!=str1[i]) { i1=next[i1]; } if(str2[i1+1]==str1[i]) { i1++; } if(i1==len2) { printf("%d\n",i-len2+1);//輸出str2在str1中出現的位置 i1=next[i1]; } } for(int i=1;i<=len2;i++) printf("%d ",next[i]); }
kmp到這裡就結束了,歡迎指正錯誤和提問