
hbase常識及habse適合什麼場景
當我們對於資料結構欄位不夠確定或雜亂無章很難按一個概念去進行抽取的資料適合用使用什麼資料庫?答案是什麼,如果我們使用的傳統資料庫,肯定留有多餘的欄位,10個不行,20個,但是這個嚴重影響了質量。並且如果面對大資料庫,pt級別的資料,這種浪費更是嚴重的,那麼我們該使用是什麼資料庫?hbase數個不錯的選擇,那麼我們對於hbase還存在下列問題:
1.Column Family代表什麼?
2.HBase通過row和column確定一份資料,這份資料的值可能有多個版本,為什麼會存在多個版本?
3.查詢的時候會顯示那個版本?
4.它們的儲存型別是什麼?
5.tableName是什麼型別?
6.RowKey 和 ColumnName是什麼型別?
7.Timestamp 是什麼型別?
8.value 是什麼型別?
團隊中使用HBase的專案多了起來,對於業務人員而言,通常並不需要從頭搭建、維護一套HBase的叢集環境,對於其架構細節也不一定要深刻理解(交由HBase叢集維護團隊負責),迫切需要的是快速理解基本技術來解決業務問題。最近在XX專案輪崗過程中,嘗試著從業務人員視角去看HBase,將一些過程記錄下來,期望對快速瞭解HBase、掌握相關技術來開展工作的業務人員有點幫助。我覺得作為一個初次接觸HBase的業務開發測試人員,他需要迫切掌握的至少包含以下幾點:
深入理解HTable,掌握如何結合業務設計高效能的HTable掌握與HBase的互動,反正是離不開資料的增刪改查,通過HBase Shell命令及Java Api都是需要的
掌握如何用MapReduce分析HBase裡的資料,HBase裡的資料總要分析的,用MapReduce是其中一種方式
掌握如何測試HBase MapReduce,總不能光寫不管正確性吧,debug是需要的吧,看看如何在本機單測debug吧
本系列將圍繞以上幾點展開,篇幅較長,如果是HBase初學者建議邊讀邊練,對於HBase比較熟練的,可以選讀下,比如關注下HBase的MapReduce及其測試方法。
從一個示例說起
傳統的關係型資料庫想必大家都不陌生,我們將以一個簡單的例子來說明使用RDBMS和HBase各自的解決方式及優缺點。
以博文為例,RDBMS的表設計如下:
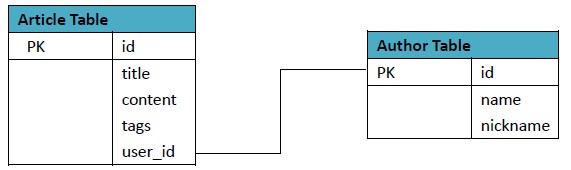
為了方便理解,我們以一些資料示例下
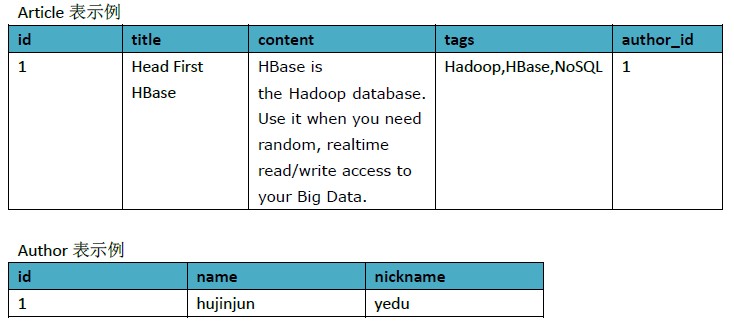
上面的例子,我們用HBase可以按以下方式設計

同樣為了方便理解,我們以一些資料示例下,同時用紅色標出了一些關鍵概念,後面會解釋
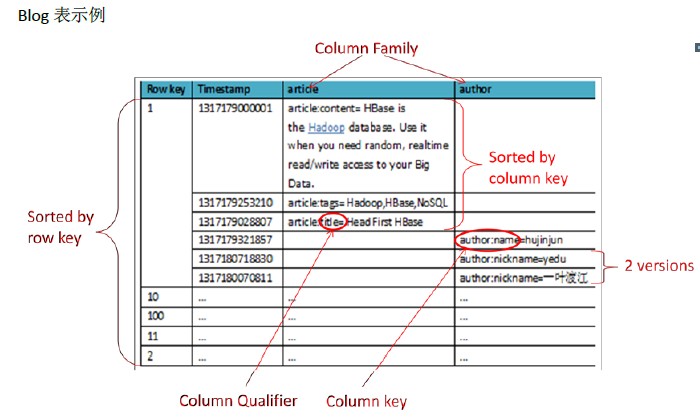
HTable一些基本概念
Row key
行主鍵, HBase不支援條件查詢和Order by等查詢,讀取記錄只能按Row key(及其range)或全表掃描,因此Row key需要根據業務來設計以利用其儲存排序特性(Table按Row key字典序排序如1,10,100,11,2)提高效能。
Column Family(列族)
在表建立時宣告,每個Column Family為一個儲存單元。在上例中設計了一個HBase表blog,該表有兩個列族:article和author。
Column(列)
HBase的每個列都屬於一個列族,以列族名為字首,如列article:title和article:content屬於article列族,author:name和author:nickname屬於author列族。
Column不用建立表時定義即可以動態新增,同一Column Family的Columns會群聚在一個儲存單元上,並依Column key排序,因此設計時應將具有相同I/O特性的Column設計在一個Column Family上以提高效能。同時這裡需要注意的是:這個列是可以增加和刪除的,這和我們的傳統資料庫很大的區別。所以他適合非結構化資料。
Timestamp
HBase通過row和column確定一份資料,這份資料的值可能有多個版本,不同版本的值按照時間倒序排序,即最新的資料排在最前面,查詢時預設返回最新版本。如上例中row key=1的author:nickname值有兩個版本,分別為1317180070811對應的“一葉渡江”和1317180718830對應的“yedu”(對應到實際業務可以理解為在某時刻修改了nickname為yedu,但舊值仍然存在)。Timestamp預設為系統當前時間(精確到毫秒),也可以在寫入資料時指定該值。
Value
每個值通過4個鍵唯一索引,tableName+RowKey+ColumnKey+Timestamp=>value,例如上例中{tableName=’blog’,RowKey=’1’,ColumnName=’author:nickname’,Timestamp=’ 1317180718830’}索引到的唯一值是“yedu”。
儲存型別
TableName 是字串
RowKey 和 ColumnName 是二進位制值(Java 型別 byte[])
Timestamp 是一個 64 位整數(Java 型別 long)
value 是一個位元組陣列(Java型別 byte[])。
儲存結構
可以簡單的將HTable的儲存結構理解為

即HTable按Row key自動排序,每個Row包含任意數量個Columns,Columns之間按Column key自動排序,每個Column包含任意數量個Values。理解該儲存結構將有助於查詢結果的迭代。
話說什麼情況需要HBase
半結構化或非結構化資料
對於資料結構欄位不夠確定或雜亂無章很難按一個概念去進行抽取的資料適合用HBase。以上面的例子為例,當業務發展需要儲存author的email,phone,address資訊時RDBMS需要停機維護,而HBase支援動態增加.
記錄非常稀疏
RDBMS的行有多少列是固定的,為null的列浪費了儲存空間。而如上文提到的,HBase為null的Column不會被儲存,這樣既節省了空間又提高了讀效能。
多版本資料
如上文提到的根據Row key和Column key定位到的Value可以有任意數量的版本值,因此對於需要儲存變動歷史記錄的資料,用HBase就非常方便了。比如上例中的author的Address是會變動的,業務上一般只需要最新的值,但有時可能需要查詢到歷史值。
超大資料量
當資料量越來越大,RDBMS資料庫撐不住了,就出現了讀寫分離策略,通過一個Master專門負責寫操作,多個Slave負責讀操作,伺服器成本倍增。隨著壓力增加,Master撐不住了,這時就要分庫了,把關聯不大的資料分開部署,一些join查詢不能用了,需要藉助中間層。隨著資料量的進一步增加,一個表的記錄越來越大,查詢就變得很慢,於是又得搞分表,比如按ID取模分成多個表以減少單個表的記錄數。經歷過這些事的人都知道過程是多麼的折騰。採用HBase就簡單了,只需要加機器即可,HBase會自動水平切分擴充套件,跟Hadoop的無縫整合保障了其資料可靠性(HDFS)和海量資料分析的高效能(MapReduce)。
相關推薦
hbase常識及habse適合什麼場景
當我們對於資料結構欄位不夠確定或雜亂無章很難按一個概念去進行抽取的資料適合用使用什麼資料庫?答案是什麼,如果我們使用的傳統資料庫,肯定留有多餘的欄位,10個不行,20個,但是這個嚴重影響了質量。並且如果面對大資料庫,pt級別的資料,這種浪費更是嚴重的,那麼我們該使用是什麼資
Hbase總結(五)-hbase常識及habse適合什麼場景
當我們對於資料結構欄位不夠確定或雜亂無章很難按一個概念去進行抽取的資料適合用使用什麼資料庫?答案是什麼,如果我們使用的傳統資料庫,肯定留有多餘的欄位,10個不行,20個,但是這個嚴重影響了質量。並且如
Hbase常識及適合場景
引言團隊中使用Hbase的專案多了起來,對於業務人員而言,通常並不需要從頭搭建、維護一套HBase的叢集環境,對於其架構細節也不一定要深刻理解(交由HBase叢集維護團隊負責),迫切需要的是快速理解基本技術來解決業務問題。最近在XX專案輪崗過程中,嘗試著從業務人員視角去看HBase,將一些過程記錄下來,期望對
Hbase適合場景
當資料量越來越大,RDBMS資料庫撐不住了,就出現了讀寫分離策略,通過一個Master專門負責寫操作,多個Slave負責讀操作,伺服器成本倍增。隨著壓力增加,Master撐不住了,這時就要分庫了,把關聯不大的資料分開部署,一些join查詢不能用了,需要藉助中間層。隨著資料量的進一步增加,一個表的記錄越來越大,
老男孩教育每日一題-第83天-binlog是什麽?記錄的什麽?有幾種工作模式及企業應用場景
mysql binlog 每日一題 參考答案含義binlog:是用於記錄所有更新了數據的操作語句,語句以事件的形式保存,它描述數據的更改過程作用:用於實時備份數據,數據庫的主從復制log_bin 打開記錄binlog功能binlog的查看mysqlbinlog /home/mysql/binlog
Java設計模式(三) Visitor(訪問者)模式及多分派場景應用
public mod 項目 getname total college hide word dsm 基本概念 Visitor 封裝一些作用於數據結構中的各元素的操作,不同的操作能夠借助新的visitor實現。減少了操作間的耦合性 訪問者能夠將數
配置nginx虛擬主機別名及別名企業場景應用說明
linuxnginx虛擬主機的別名配置1 虛擬主機別名介紹及配置 所謂虛擬主機別名,就是為了虛擬主機設置除了主域名以外的一個或多個域名名字,這樣能實現用戶訪問的多個域名對應同一個虛擬主機網站的功能。 以www.etiantian.org域名的虛擬主機為例,為其增加一個別名etiantian.
Future模式理解及FutureTask應用場景
返回 重點 urn sys exce 阻塞 for 來看 all 一、 Future模式理解 先說一下為什麽要用future模式:兩個任務沒有必然的前後關系,如果在一個線程中串行執行,就有些浪費時間,不如讓兩個線程去並行執行這兩個任務,執行完了到主線程去匯報就可以了。(讓任
Android:圖解四種啟動模式 及 實際應用場景解說
類型 placed data val add The avi 能夠 per 在一個項目中會包括著多個Activity,系統中使用任務棧來存儲創建的Activity實例,任務棧是一種“後進先出”的棧結構。舉個栗子,若我們多次啟動同一個Activity。系統會創建多個實例依次放
HBase概念及表格設計
HBase概念及表格設計 1. 概述(扯淡~) HBase是一幫傢伙看了Google釋出的一片名為“BigTable”的論文以後,猶如醍醐灌頂,進而“山寨”出來的一套系統。 由此可見: 1. 幾乎所有的HBase中的理念,都可以從BigTable論文中得到解釋。原文是英語的,而且
Unity3d 簡單的小球沿貝塞爾曲線運動(適合場景漫遊使用)
轉載收藏:https://www.cnblogs.com/yanghui0702/p/yanghui20171122.html 簡單的小球沿貝塞爾曲線運動,適合場景漫遊使用 貝塞爾曲線:(貝塞爾曲線的基本想法部分摘自http://blog.csdn.net/u010019717/art
Charles小常識及抓取手機資料
一.Charles小常識 注意: (1)瀏覽網頁時花瓶儘量不要開啟,可能會出現網頁重置現象 (2)安裝Python包時,切記要將花瓶關閉,否則會報錯 1.花瓶的埠是8888 2. 可以改為0.0.0.0/0可以抓取所有IP下的所有埠 3.可以按照以下做
HBase核心及能力
本期分享專家: 正研 ——阿里巴巴技術專家 本期分享主題:HBase多模式 本期分享主題:HBase核心及能力 視訊地址:https://yunqivedio.alicdn.com/od/i43cD1542260050827.mp4 PPT地址:https://yq.aliyu
Hbase架構及工作原理、資料及物理模型、Hbase優化
一、HBase 簡介 1.HBase 概述 HBase 是一個構建在HDFS之上的,分散式的、面向列的開源資料庫 HBase 是 Google BigTable的開源實現,它主要用於儲存海量資料 個人理解:
[Hbase]Hbase章1 Hbase框架及基本概念
Hbase框架介紹 HBase是一個分散式的、面向列的開源資料庫。 不同點: l 和一般的關係資料庫不同,hbase是一個適合於非結構化資料儲存的資料庫。 l Hbase是基於列而不是基於行的模式。 在分散式的生產環境中,HBase 需要執行在 HDFS 之上
Volley---適合場景:適合資料量小、頻率高的請求,為什麼?
一、簡介 Volley請求網路 是基於請求佇列的,只要把請求放入請求佇列就可以了。 Voller底層封裝的是HttpUrlConnection,支援圖片載入,網路請求排序,優先順序處理,快取,與Activity生命週期聯動。擴充套件性好,支援httpclient,HttpUrlConne
HBase簡介及叢集安裝
一、Hbase概述 Apache HBase™是Hadoop資料庫,是一個分散式,可擴充套件的大資料儲存。 當您需要對大資料進行隨機,實時讀/寫訪問時,請使用Apache HBase™。該專案的目標是託 管非常大的表 - 數十億行X百萬列 - 在商品硬體叢集上。Apache HB
HBase入門--HBase概念及表格設計
HBase概念及表格設計 1. 概述(扯淡~) HBase是一幫傢伙看了Google釋出的一片名為“BigTable”的論文以後,猶如醍醐灌頂,進而“山寨”出來的一套系統。 由此可見: 1. 幾乎所有的HBase中的理念,都可以從BigTable論文中得到解
訊息中介軟體MQ(三)JMS常識及簡單案例
1JMS概念 JMS即Java訊息服務(Java Message Service)應用程式介面,是一個Java平臺中關於面向訊息中介軟體(MOM)的API,用於在兩個應用程式之間,或分散式系統中傳送訊息,進行非同步通訊。Java訊息服務是一個與具體平臺無關的AP
HBase安裝及偽分散式配置教程
HBase安裝是在我的另一篇部落格hadoop在centos系統未分散式安裝的基礎上進行的,HBase下載地址:HBase,不建議選擇最新版本的,容易出現相容性問題。 HBase安裝步驟 解壓到/usr/local 路徑下 sudo tar -zxf ~