
Google開源OCR專案Tesseract訓練(自己訓練的記錄,未成功)
影象處理開發資料、影象處理開發需求、影象處理接私活掙零花錢,可以搜尋公眾號"qxsf321",並關注!
影象處理開發資料、影象處理開發需求、影象處理接私活掙零花錢,可以搜尋公眾號"qxsf321",並關注!
影象處理開發資料、影象處理開發需求、影象處理接私活掙零花錢,可以搜尋公眾號"qxsf321",並關注!
一、
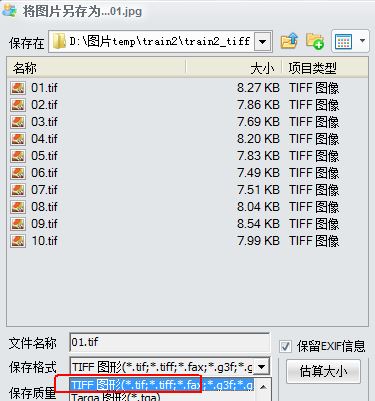
準備若干張待訓練圖片(我這裡準備了10張),並全部轉化為tif格式,我這裡使用的轉換軟體是iSee,下載連結:http://pan.baidu.com/s/1pLrPmDd,具體使用方法如下圖所示:
二、下載jTessBoxEditor-1.0(下載連結 http://pan.baidu.com/s/1geRbgQ3
注意:要執行jTessBoxEditor-1.0,需要安裝Java Runtime Environment,版本為6.0以上,這裡給大家“Java Runtime Environment-6.0.450.exe”的下載連結:http://pan.baidu.com/s/1nuQOUpV
相關操作截圖如下:
三、把orderNo04.tif複製到Tesseract的安裝目錄Tesseract-OCR下。
四、在CMD視窗下執行下面的語句:
tesseract.exe orderNo04.tif orderNo04 batch.nochop makebox
上面語句執行後生成了orderNo04.box檔案,裡面儲存了tesseract.exe的識別結果,包括每個識別區域的座標,區域大小及識別出來的字元等...
若要用已經訓練好的資料庫來生成box檔案,比如用中文識別資料庫chi_tra.traineddata,就執行下面的語句:
tesseract.exe orderNo04.tif orderNo04 -l chi_tra batch.nochop makebox
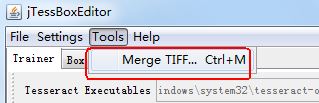
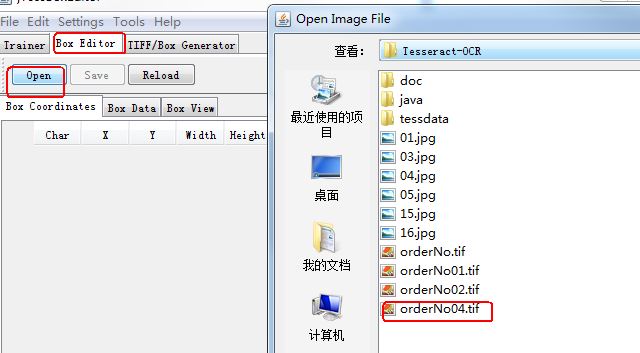
五、利用jTessBoxEditor-1.0編輯box檔案,如下圖所示:
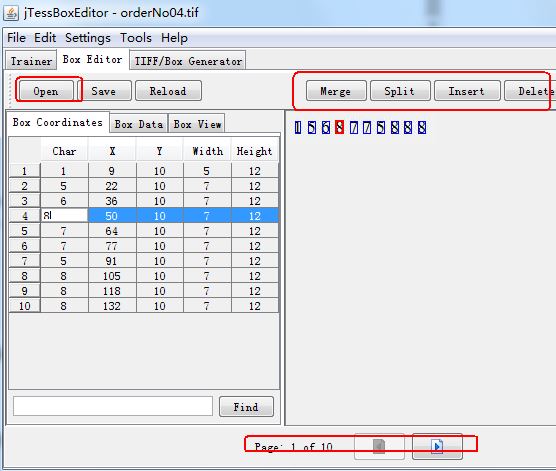
六、修改完成後,執行下面的語句:
tesseract.exe orderNo4.tif orderNo04 nobatch box.train
我就卡在這一部了,不管作何種嘗試,就報下面的錯誤:
Cannot open input file: orderNo4.tif

明明orderNo4.tif是在資料夾Tesseract-OCR下面的,卻說不能開啟這個語言檔案,真是夠了!這個問題搞了兩天,也搞不定,只好作罷,暫時放在這裡,但願以後能解決吧!
相關推薦
Google開源OCR專案Tesseract訓練(自己訓練的記錄,未成功)
影象處理開發資料、影象處理開發需求、影象處理接私活掙零花錢,可以搜尋公眾號"qxsf321",並關注! 影象處理開發資料、影象處理開發需求、影象處理接私活掙零花錢,可以搜尋公眾號"qxsf321",並關注! 影象處理開發資料、影象處理開發需求、影象處理接私活掙零花錢,可以搜尋
OCR開源庫Tesseract漢字識別訓練
先用中文做個示例: 1. 拿到一張chi.pingfang.exp0.jpg: 2. 將它轉化為tif:http://image.online-convert.com/convert-to-ti
Tesseract-OCR的簡單使用與訓練
轉自 Tesseract,一款由HP實驗室開發由Google維護的開源OCR(Optical Character Recognition , 光學字元識別)引擎,與Microsoft Office Document Imaging(MODI)相比,我們可以不斷的訓練的庫,使影象轉換文字的能力
halcon OCR識別,訓練自己的OCR
看halcon助手有OCR識別,就想著試一下,結果一直識別不出來,不知道怎麼訓練自己的OCR庫,經過一天搜尋資料,終於知道怎麼訓練自己的OCR庫,並在影象中進行識別 害怕以後忘了,上傳上來以備以後不時之需 dev_set_draw (‘margin’) *載入影象 read_image
tensorflow專案學習(1)——訓練自己的資料集並進行物體檢測(object detection)
Tensorflow Object Detection 前言 本文主要介紹如何利用官方庫tensorflow/models/research/objection 並通過faster rcnn resnet 101(以及其他)深度學習框架
ocr tesseract 3.4訓練記錄
安裝tesseract brew uninstall tesseract brew install --with-training-tools tesseract 構建字符集 合併為tif tools-Merge Tiff 儲存為num.myfont.exp0
目標檢測(Google object_detection) API 上訓練自己的資料集
應公司要求,利用谷歌最近開源的Google object_detection API對公司收集的資料集進行訓練,並檢測訓練效果。通過一兩天的研究以及維持四天的訓練(GTX 1060 6GB),終於成功的在自己資料集上訓練的任務。測試效果感覺還行,雖沒有達到谷歌官方公佈的
在谷歌目標檢測(Google object_detection) API 上訓練自己的資料集
知乎連結:https://zhuanlan.zhihu.com/p/28218410應公司要求,利用谷歌最近開源的Google object_detection API對公司收集的資料集進行訓練,並檢測訓練效果。通過一兩天的研究以及維持四天的訓練(GTX 1060 6GB)
嘗試用google colab訓練自己的神經網路(二)
接下來我們要讀取資料了,首先掛載google drive:# Install the PyDrive wrapper & import libraries. # This only needs to be done once per notebook. !pip in
Tesseract-OCR-v5.0中文識別,訓練自定義字型檔,提高圖片的識別效果
1,下載安裝Tesseract-OCR 安裝,連結地址https://digi.bib.uni-mannheim.de/tesseract/ 2,安裝成功 tesseract -v 注意:安裝後,要新增系統環境變數 3,cmd指定目錄到 cd C:\Work\BlogsTest\Te
FastRCNN 訓練自己數據集 (1編譯配置)
backend key article tail back art model plot osc http://www.cnblogs.com/louyihang-loves-baiyan/p/4885659.html 按照博客的教程配置,但自己在服務器上配置時,USE_C
tensorflowxun訓練自己的數據集之從tfrecords讀取數據
str 兩個 圖片文件 lines 註意 file ans span 數據集 當訓練數據量較小時,采用直接讀取文件的方式,當訓練數據量非常大時,直接讀取文件的方式太耗內存,這時應采用高效的讀取方法,讀取tfrecords文件,這其實是一種二進制文件。tensorflow
目標檢測算法SSD在window環境下GPU配置訓練自己的數據集
等等 過程 采集 span 數據轉換 都是 too bsp nvidia 由於最近想試一下牛掰的目標檢測算法SSD。於是乎,自己做了幾千張數據(實際只有幾百張,利用數據擴充算法比如鏡像,噪聲,切割,旋轉等擴充到了幾千張,其實還是很不夠)。於是在網上找了相關的介紹,自己處理數
【Tensorflow系列】使用Inception_resnet_v2訓練自己的數據集並用Tensorboard監控
process blog exc 系統參數 ota 可視化 自己實現 print loss 【寫在前面】 用Tensorflow(TF)已實現好的卷積神經網絡(CNN)模型來訓練自己的數據集,驗證目前較成熟模型在不同數據集上的準確度,如Inception_V3, VGG16
可變卷積Deforable ConvNet 遷移訓練自己的數據集 MXNet框架 GPU版
pascal classes sdn 獲取數據 ide 實驗 one sets div 【引言】 最近在用可變卷積的rfcn 模型遷移訓練自己的數據集, MSRA官方使用的MXNet框架 環境搭建及配置:http://www.cnblogs.com/andre-ma/p/8
YOLOv3訓練自己的數據集(還在學習中)
tail x64 自己 bubuko lov link win10 info 問題 其他比較好的參考鏈接: YOLOv3官網鏈接GitHub:https://github.com/AlexeyAB/darkne Yolov3+windows10+VS2015部署安裝:htt
windows10 conda2 使用caffe訓練訓練自己的數據
caffe lex cond www mom nal shuff sna nor 首先得到了https://blog.csdn.net/gybheroin/article/details/72581318系列博客的幫助。表示感激。 關於安裝caffe已在之前的博客介紹,自用
yoloV3一步步訓練自己的數據
圖片 cto file 目錄 好的 下載 ima 配置 自動 YOLOV3的主頁: https://pjreddie.com/darknet/yolo/ 運行主頁上的代碼得到: 首先使用一個開源的神經網絡框架Darknet,使用C和CUDA,有CPU和GPU兩種模式。
YOLOv3訓練自己的數據
roo 所有 打開終端 target label ext make rename read 1.下載官網的YOLOv3,打開終端輸入:git clone https://github.com/pjreddie/darknet下載完成之後,輸入:cd darknet,然後再輸
[2] SSD配置+訓練VOC0712+訓練自己的資料集
GitHub https://github.com/weiliu89/caffe/tree/ssd http://blog.csdn.net/u010733679/article/details/52125597 一、安裝配置 sudo apt-get install -y