
動手實戰聯合使用Spark Streaming、Broadcast、Accumulator計數器實現線上黑名單過濾和計數
本博文主要包括:
1、Spark Streaming與Broadcast、Accumulator聯合
2、線上黑名單過濾和計數實戰
一、Spark Streaming與Broadcast、Accumulator聯合:
在企業實戰中,廣播本身廣播到叢集的時候,聯合上計數器的話就有很大殺傷力,這時候你可以自定義,例如自定義廣播中的內容,可以實現非常複雜的內容。
之所以廣播和計數器特別重要,一方面鑑於廣播和計數器本身的特性,另一方面廣播和計數器可以說實現非常複雜的操作。線上黑名單過濾實戰中,將黑名單放在廣播中,有Accumulator你可以計數黑名單。
二、線上黑名單過濾和計數實戰:
1、程式碼如下:
import org.apache.spark.Accumulator;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache 2、在命令端輸入資料
nc -lk 99993、觀察結果
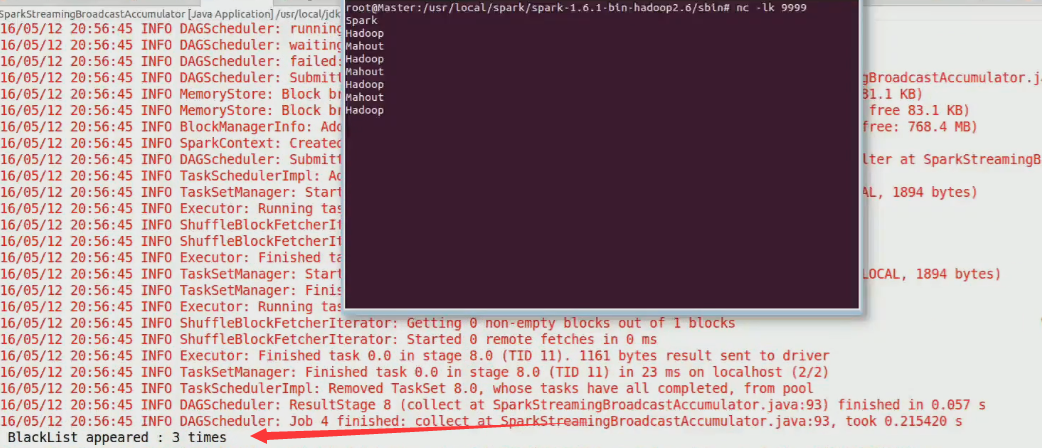
相關推薦
動手實戰聯合使用Spark Streaming、Broadcast、Accumulator計數器實現線上黑名單過濾和計數
本博文主要包括: 1、Spark Streaming與Broadcast、Accumulator聯合 2、線上黑名單過濾和計數實戰 一、Spark Streaming與Broadcast、Accumulator聯合: 在企業實戰中,廣播本身廣播到叢集的時
spark(三):blockManager、broadcast、cache、checkpoint
表示 廣播 心跳 ask fff 1.5 exec edi 所在 blockManager Driver和executor上分別都會啟動blockManager,其中driver上擁有所有executor上的blockManager的引用;所有executor上的blo
Spark Streaming高吞吐、高可靠的一些優化
> 分享一些Spark Streaming在使用中關於高吞吐和高可靠的優化。 [toc] 作為Spark的流式處理框架,Spark Streaming基於微批RDDs實現,需要7*24小時執行。在實踐中,我們需要通過不斷的優化來保證它的高可靠,高吞吐。 本文從高吞吐和高可靠兩個角度來簡單介紹一下
【慕課網實戰】Spark Streaming實時流處理項目實戰筆記三之銘文升級版
聚集 配置文件 ssi path fig rect 擴展 str 控制臺 銘文一級: Flume概述Flume is a distributed, reliable, and available service for efficiently collecting(收集),
【慕課網實戰】Spark Streaming實時流處理項目實戰筆記五之銘文升級版
環境變量 local server 節點數 replicas conn 配置環境 park 所有 銘文一級: 單節點單broker的部署及使用 $KAFKA_HOME/config/server.propertiesbroker.id=0listenershost.name
【慕課網實戰】Spark Streaming實時流處理項目實戰筆記九之銘文升級版
file sin ssi 右上角 result map tap 核心 內容 銘文一級: 核心概念:StreamingContext def this(sparkContext: SparkContext, batchDuration: Duration) = { th
【慕課網實戰】Spark Streaming實時流處理項目實戰筆記十之銘文升級版
state 分鐘 mooc 系統數據 使用 連接 var style stream 銘文一級: 第八章:Spark Streaming進階與案例實戰 updateStateByKey算子需求:統計到目前為止累積出現的單詞的個數(需要保持住以前的狀態) java.lang.I
【慕課網實戰】Spark Streaming實時流處理項目實戰筆記十五之銘文升級版
spa for 序列 html art mat div pre paths 銘文一級:[木有筆記] 銘文二級: 第12章 Spark Streaming項目實戰 行為日誌分析: 1.訪問量的統計 2.網站黏性 3.推薦 Python實時產生數據 訪問URL->IP
【慕課網實戰】Spark Streaming實時流處理項目實戰筆記十六之銘文升級版
.so zook orm 3.1 date nta highlight org 結果 銘文一級: linux crontab 網站:http://tool.lu/crontab 每一分鐘執行一次的crontab表達式: */1 * * * * crontab -e */1
【慕課網實戰】Spark Streaming實時流處理項目實戰筆記十七之銘文升級版
eid 實時 root 現在 ava == oop urn 啟動 銘文一級: 功能1:今天到現在為止 實戰課程 的訪問量 yyyyMMdd courseid 使用數據庫來進行存儲我們的統計結果 Spark Streaming把統計結果寫入到數據庫裏面 可視化前端根據:yyy
【慕課網實戰】Spark Streaming實時流處理項目實戰筆記二十之銘文升級版
.get frame 結果 取數據 lena echarts object 原理 四種 銘文一級: Spring Boot整合Echarts動態獲取HBase的數據1) 動態的傳遞進去當天的時間 a) 在代碼中寫死 b) 讓你查詢昨天的、前天的咋辦? 在頁面中放一個時間插
【慕課網實戰】Spark Streaming實時流處理項目實戰筆記二十一之銘文升級版
win7 小時 其他 har safari 北京 web 連接 rim 銘文一級: DataV功能說明1)點擊量分省排名/運營商訪問占比 Spark SQL項目實戰課程: 通過IP就能解析到省份、城市、運營商 2)瀏覽器訪問占比/操作系統占比 Hadoop項目:userAg
大資料分析技術與實戰之 Spark Streaming
Spark是基於記憶體的大資料綜合處理引擎,具有優秀的作業排程機制和快速的分散式計算能力,使其能夠更加高效地進行迭代計算,因此Spark能夠在一定程度上實現大資料的流式處理。 隨著資訊科技的迅猛發展,資料量呈現出爆炸式增長趨勢,資料的種類與變化速度也遠遠超出人們的想象,因此人們對大資料處理提出了
大資料分析技術與實戰之Spark Streaming(內含福利)
↑ 點選上方藍字關注我們,和小夥伴一起聊技術! 隨著資訊科技的迅猛發展,資料量呈現出爆炸式增長趨勢,資料的種類與變化速度也遠遠超出人們的想象,因此人們對大資料處理提出了更高的要求,越來越多的領域迫切需要大資料技術來解決領域內的關鍵問題。在一些特定的領域中(例如金融、災害預警等),時間就是金錢、時間可能就
實戰|使用Spark Streaming寫入Hudi
1. 專案背景 傳統數倉的組織架構是針對離線資料的OLAP(聯機事務分析)需求設計的,常用的匯入資料方式為採用sqoop或spark定時作業逐批將業務庫資料匯入數倉。隨著資料分析對實時性要求的不斷提高,按小時、甚至分鐘級的資料同步越來越普遍。由此展開了基於spark/flink流處理機制的(準)實時同步系統的
七、springBoot 簡單優雅是實現檔案上傳和下載
前言 好久沒有更新spring Boot 這個專案了。最近看了一下docker 的知識,後期打算將spring boot 和docker 結合起來。剛好最近有一個上傳檔案的工作呢,剛好就想起這個腳手架,將檔案上傳和下載整理進來。 配置 在application.properties 中增加上傳檔案存放的路徑配
SparkStreaming 實現廣告計費系統中線上黑名單過濾實戰
本博文內容主要包括以下內容: 1、線上黑名單過濾實現解析 2、SparkStreaming實現線上黑名單過濾 一、線上黑名單過濾實現解析: 流式處理是現代資料處理的主流,各種電子商務網站,搜尋引擎等網站等,都需要做流式比如,通過使用者的點選和購買來推斷
大數據Hadoop Streaming編程實戰之C++、Php、Python
大數據編程 PHP語言 Python編程 C語言的應用 Streaming框架允許任何程序語言實現的程序在HadoopMapReduce中使用,方便已有程序向Hadoop平臺移植。因此可以說對於hadoop的擴展性意義重大。接下來我們分別使用C++、Php、Python語言實現HadoopWo
讓 Spark Streaming 程式在 YARN 叢集上長時間執行(二)—— 日誌、監控、Metrics
前段時間看到了外國朋友寫的一篇文章,覺得還不錯,於是就把他翻譯一下,供大家參考和學習。 如果沒看過第一篇文章,建議先去看一下上一篇文章哈,這裡是接著上一篇文章來寫的哈~ 日誌 訪問 Spark 應用程式日誌的最簡單方法是配置 Log4j 控
實時流計算、Spark Streaming、Kafka、Redis、Exactly-once、實時去重
http://lxw1234.com/archives/2018/02/901.htm在實時流式計算中,最重要的是在任何情況下,訊息不重複、不丟失,即Exactly-once。本文以Kafka–>Spark Streaming–>Redis為例,一方面說明一下如何