
SparkStreaming 實現廣告計費系統中線上黑名單過濾實戰
本博文內容主要包括以下內容:
1、線上黑名單過濾實現解析
2、SparkStreaming實現線上黑名單過濾
一、線上黑名單過濾實現解析:
流式處理是現代資料處理的主流,各種電子商務網站,搜尋引擎等網站等,都需要做流式比如,通過使用者的點選和購買來推斷出使用者的興趣愛好,後臺能實時計算,這是比較重要的,給使用者推薦最好的商品等,推薦更新的資訊,給使用者更好的服務。Spark Streaming就是Spark Core上的一個應用程式。Spark Streaming中資料是不斷的流進來,流進來的資料不斷的生成Job,不斷的提交給叢集去處理,要是想更清晰的看到資料流進來,更清晰的看到資料被處理,只要把Batch Interval修改的足夠大,就可以看到了,對於想理解內部的執行過程,排除錯誤等,都是很有必要的。
廣告計費系統,是電商必不可少的一個功能點。為了防止惡意的廣告點選(假設商戶A和B同時在某電商做了廣告,A和B為競爭對手,那麼如果A使用點選機器人進行對B的廣告的惡意點選,那麼B的廣告費用將很快被用完),必須對廣告點選進行黑名單過濾。黑名單的過濾可以是ID,可以是IP等等,黑名單就是過濾的條件,利用SparkStreaming的流處理特性,可實現實時黑名單的過濾實現。可以使用leftouter join 對目標資料和黑名單資料進行關聯,將命中黑名單的資料過濾掉。
二、SparkStreaming實現線上黑名單過濾 :
1、實現程式碼如下:
/**
* 背景描述:在廣告點選計費系統中,我們線上過濾掉黑名單的點選,進而保護廣告商的利益,只進行有效的廣告點選計費
* 或者在防刷評分(或者流量)系統,過濾掉無效的投票或者評分或者流量;
* 實現技術:使用transform Api直接基於RDD程式設計,進行join操作
*
*/ 2、將程式碼打包
3、將打好的包放入叢集中,並且寫好指令碼,指令碼內容如下:
/usr/local/spark/bin/spark-submit --class com.dt.spark.sparkstreaming.OnlineBlackListFilter --master spark://Master:7077 /root/Documents/WordCount.jar4、啟動叢集、此時記得啟動history服務以及新開闢一個視窗執行 nc -lk 9999作為資料的輸入端:
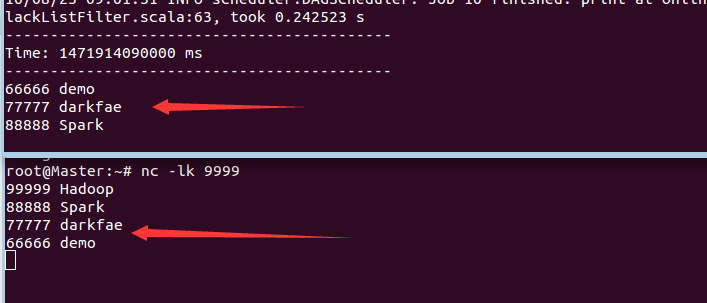
5、此時執行指令碼,觀察結果
6、進入18080埠觀察執行過程
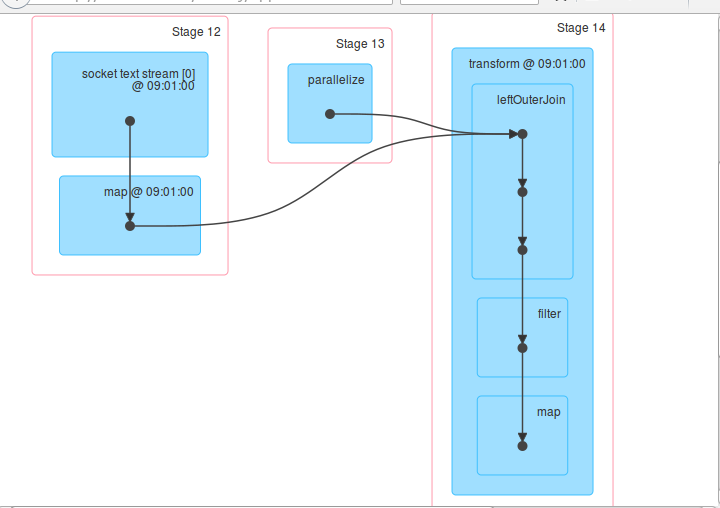
上述圖片說明我們的業務邏輯是正確的。
博文內容源自DT大資料夢工廠Spark課程總結的筆記。相關課程內容視訊可以參考:
百度網盤連結:http://pan.baidu.com/s/1slvODe1(如果連結失效或需要後續的更多資源,請聯絡QQ460507491或者微訊號:DT1219477246 獲取上述資料)。