
聚類演算法之K-means演算法
關注微信公眾號【Microstrong】,我寫過四年Android程式碼,瞭解前端、熟悉後臺,現在研究方向是機器學習、深度學習!一起來學習,一起來進步,一起來交流吧!

本文同步更新在我的微信公眾號裡,地址:https://mp.weixin.qq.com/s?__biz=MzI5NDMzMjY1MA==&mid=2247483987&idx=1&sn=6df96c39e5c1c055a6823c09afea354e&chksm=ec6533d6db12bac05efa7229f4812ae773f80d2970f023506c96fb0bab8e7949df5bb207a7a8&scene=0#rd
目錄:
(1) 理解相似度度量的各種方法與相互聯絡(熟悉閔可夫斯基距離,其他作為了解)
(1) 掌握K-means聚類的思路和使用條件
(一) 聚類的定義
聚類就是對大量未知標註的資料集,按資料的內在相似性將資料集劃分為多個類別,使類別內的資料相似度較大而類別間的資料相似度較小。聚類是無監督學習。
(二) 相似度、距離計算方法總結
相似度跟距離是相反的概念。如果兩個樣本Xi與Xj ,它們的距離比較大,那麼它們的相似度是比較小的。總之,我們有了相似度就能度量距離,有了距離就能度量相似度。
(1)閔可夫斯基距離
給定樣本Xi = (Xi1;Xi2;Xi3;……Xin)與Xj

歐式距離:
當p=2時,閔可夫斯基距離即為歐式距離:

此時,上式也是Xi-Xj的L2範數,表示為:||xi-xj||2。
那麼L2範數如何計算呢?我給大家演示一下,假如我們有兩個樣本X = (X1;X2;X3)與Y=(Y1;Y2;Y3),兩個樣本分別有三個特徵,我們來計算一下這兩個樣本的歐式距離:

曼哈頓距離:
當p=1時,閔可夫斯基距離即為曼哈頓距離:

此時,上式也是Xi-Xj的L1範數||xi-xj||1。
那麼L1範數如何計算呢?我給大家演示一下,假如我們有兩個樣本X = (X1;X2;X3)與Y=(Y1

(2)傑卡德相似係數(Jaccard)
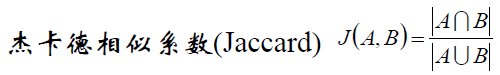
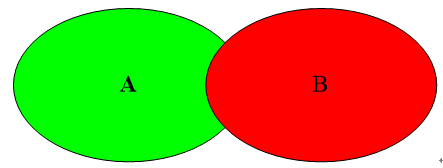
傑卡德相似係數可以這麼理解:情景一:A代表對某個使用者的推薦購物列表,B表示使用者自己心目中喜歡的商品列表,現在我們要計算A集合和B集合的相似度,就用到了傑卡德相似係數。情景二:A表示的是A使用者喜歡電影的列表,B表示B使用者喜歡電影的列表。假如前一段時間《前任3》很火,A和B的列表裡面都有,這個不能說明問題。但是同時發現A和B的列表裡面還有其他比較冷門的電影,那麼我們可以發現A和B的相似性突然增大了。傑卡德相似係數還可以用在降低熱門商品,提高冷門商品的推薦上。
(3) 餘弦相似度(cosine similarity)
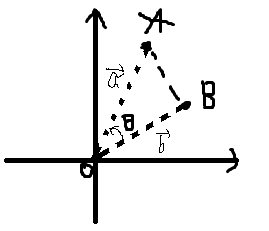
理解:求A點和B點的相似度,我們可以直接求A點到B點的距離。也可以求A點到原點和B點到原點的Cosθ的值。
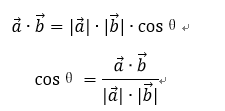
(4) Pearson相似係數
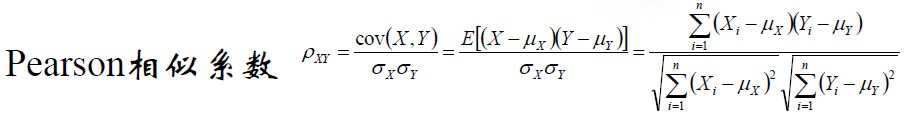
餘弦相似度與Pearson相似係數關係:
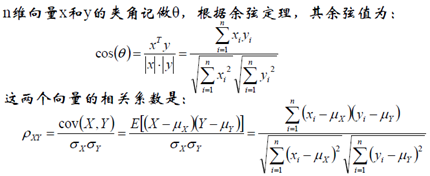
相關係數即X、y座標向量各自平移到原點後的夾角餘弦!這即解釋了為何文件間求距離使用夾角餘弦——因為這一物理量表徵了文件去均值化後的隨機向量間相關係數。
(5)相對熵(K-L距離)
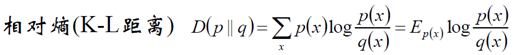
(6) Hellinger距離
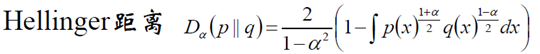
當α=0時候,我們做如下計算:
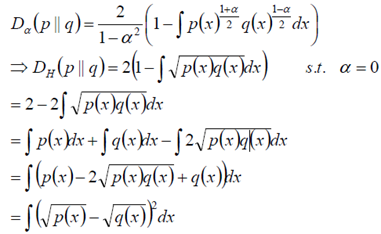
該距離滿足三角不等式,是對稱、非負距離。
(三)K-means演算法
(1)聚類的基本思想
給定一個有N個物件的資料集,構造資料的K個簇,K<=n。滿足下列條件:
1. 每個簇至少包含一個物件。
2. 每一個物件屬於且僅屬於一個簇。
3. 將滿足上述條件的k個簇稱作一個合理劃分。
基本思想:對於給定的類別數目K,首先給出初始劃分,通過迭代改變樣本和簇的隸屬關係,使得每一次改進之後的劃分方案都較前一次好。
(2) K-means的基本演算法

學習完K-means演算法之後,我們來思考幾個問題?
1. K-means是能夠得到全域性最小值麼?
對k個初始質心的選擇比較敏感,容易陷入區域性最小值。
2. K-means一定收斂麼?
K-Means演算法一定收斂。資料集比較大時,收斂會比較慢。想了解詳細細節參考部落格:http://blog.csdn.net/u010161630/article/details/52585764
3. K-means的k個初始均值向量如何選擇呢?
對k個初始質心的選擇比較敏感,容易陷入區域性最小值。
改進:有人提出了另一個成為二分k均值(bisecting k-means)演算法,它對初始的k個質心的選擇就不太敏感。
4. K-means的k如何指定呢?
K值的選擇是使用者制定的,不同的k得到的結果會有挺大的不同。
改進:對k的選擇可以先用一些演算法分析資料的分佈,如重心和密度等,然後選擇合適的k。
(3)K-means的實現程式碼
from numpy import *
import xlrd
import matplotlib.pyplot as plt
# 計算歐氏距離
def euclDistance(vector1, vector2):
'''
:param vector1: 第j個均值向量
:param vector2: 第i個樣本
:return: 距離值
'''
return sqrt(sum(power(vector2 - vector1, 2)))
# init centroids with random samples
def initCentroids(dataSet, k):
'''
:param dataSet: 資料集
:param k: 需要聚類的個數
:return: 返回k個均值向量
'''
numSamples, dim = dataSet.shape
centroids = zeros((k, dim))
for i in range(k):
index = int(random.uniform(0, numSamples))
centroids[i, :] = dataSet[index, :]
return centroids
# k-means cluster
def kmeans(dataSet, k):
'''
:param dataSet: 資料集
:param k: 需要聚類的個數
:return:
'''
# 樣本的個數
numSamples = dataSet.shape[0]
# 第一列儲存該樣本所屬的叢集
# 第二列儲存此樣本與其質心之間的誤差
clusterAssment = mat(zeros((numSamples, 2)))
clusterChanged = True
## step 1:從資料集中隨機選擇k個樣本作為初始均值向量
centroids = initCentroids(dataSet, k)
while clusterChanged:
clusterChanged = False
## 迴圈每一個樣本
for i in range(numSamples):
minDist = 100000.0 #存放最短的距離
minIndex = 0 # 第i個樣本的簇標記
## 迴圈每一個均值向量
## step 2: 找到第i個樣本的最近的均值向量
for j in range(k):
distance = euclDistance(centroids[j, :], dataSet[i, :])
if distance < minDist:
minDist = distance
minIndex = j
## step 3: 更新第i個樣本的簇標記和誤差
if clusterAssment[i, 0] != minIndex:
clusterChanged = True
clusterAssment[i, :] = minIndex, minDist ** 2
## step 4: 更新均值向量
for j in range(k):
pointsInCluster = dataSet[nonzero(clusterAssment[:, 0].A == j)[0]]
centroids[j, :] = mean(pointsInCluster, axis=0)
print ('Congratulations, cluster complete!')
return centroids, clusterAssment
# show your cluster only available with 2-D data
def showCluster(dataSet, k, centroids, clusterAssment):
numSamples, dim = dataSet.shape
if dim != 2:
print ("Sorry! I can not draw because the dimension of your data is not 2!")
return 1
mark = ['or', 'ob', 'og', 'ok', '^r', '+r', 'sr', 'dr', '<r', 'pr']
if k > len(mark):
print ("Sorry! Your k is too large! please contact Zouxy")
return 1
# draw all samples
for i in range(numSamples):
markIndex = int(clusterAssment[i, 0])
plt.plot(dataSet[i, 0], dataSet[i, 1], mark[markIndex])
mark = ['Dr', 'Db', 'Dg', 'Dk', '^b', '+b', 'sb', 'db', '<b', 'pb']
# draw the centroids
for i in range(k):
plt.plot(centroids[i, 0], centroids[i, 1], mark[i], markersize=12)
plt.show()
def main():
## step 1: load data
print ("step 1: load data...")
dataSet = []
data = xlrd.open_workbook('C:/Users/Microstrong/Desktop/watermelon4.0.xlsx')
table = data.sheets()[0]
for line in range(0,table.nrows):
lineArr = table.row_values(line)
dataSet.append([float(lineArr[0]), float(lineArr[1])])
## step 2: clustering...
print ("step 2: clustering...")
dataSet = mat(dataSet)
k = 3
centroids, clusterAssment = kmeans(dataSet, k)
## step 3: show the result
print ("step 3: show the result...")
showCluster(dataSet, k, centroids, clusterAssment)
if __name__ == '__main__':
main()具體的程式碼和資料集在我的gitHub中,資料集是周志華《機器學習》西瓜資料集4.0,地址:https://github.com/Microstrong0305/machine_learning/tree/master/K-means
(4)K-means演算法的缺點和改進
1. K-means將簇中所有點的均值作為新質心,若簇中含有異常點,將導致均值偏離嚴重。即對噪聲和孤立點資料比較敏感。
舉個例子:
陣列[1, 2, 3, 4, 100]的均值為22,顯然距離“大多數”資料1、2、3、4比較遠,若是改成求陣列的中位數3,在該例項中更為穩妥。這種聚類方式即K-Mediods聚類(K-中值聚類)。
2. 初值的選擇,對聚類結果有影響嗎?如何避免呢?
k-means是初值敏感的
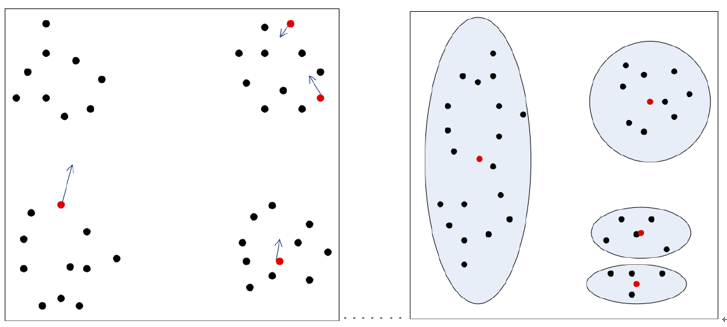
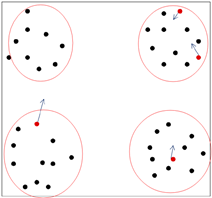
圖(1)K-means初值選擇不合理情況
假如左圖中紅色的點為初始的均值向量,那麼聚類之後的結果可能為右圖中的結果。那麼聚類的結果肯定不是我們想要的結果。我們想要的結果肯定是圖(2)所示的結果。造成聚類結果不理想的原因是我們的均值向量初始化的時候沒有做好。那麼如何解決這種問題呢?
圖(2)理想的聚類結果
優化選初值的辦法:K-means++演算法
假如有50個樣本,做4個簇的聚類,u1的選擇肯定是從50個樣本中隨機選擇一個。那麼u2該如何選擇呢?我們用50個樣本中的每一個樣本對u1作距離計算,得到50個距離陣列。把這50個距離作為權重,我們算出權重概率,把權重概率高的那個距離對應的樣本初始為u2。那麼u2選擇完之後,我們如何選擇u3呢?我們再來把50個樣本對u1和u2做距離計算,如果樣本到u1的距離大於到u2的距離,更新距離數組裡對應的值;如果樣本到u1的距離小於到u2的距離,那麼距離數組裡對應的值保持不變。我們根據更新後的距離陣列來做權重概率,找出權重概率最高點的作為u3。那麼u4如何選擇呢?我們用u3、u2、u1分別對50個樣本作距離計算,找出最小距離值然後更新距離陣列,找到權重概率最大對應的點就是u4了。
思考一個問題:為什麼要更新距離陣列呢?
u3選擇時更新距離陣列是為了選擇u3的點要保證離u1和u2都要遠。u4是同樣的道理。
(5)K-means聚類演算法總結
1. 優點:
a.是解決聚類問題的一種經典演算法,簡單、快捷
b.對處理打資料集,該演算法保持可伸縮性和高效性
c.當簇近似為高斯分佈時,它的效果更好。
2. 缺點:
d.在簇的平均值可被定義的情況下才能使用,可能不適用於某些應用
e.必須事先給出K(要生成的簇的數目),而且對初值敏感,對於不同的初始值,可能會導致不同的結果。
f.不適合於發現非凸形狀的簇或者大小差別很大的簇
j.對噪聲和孤立點資料敏感
3.作用:可以作為其他聚類方法的基礎演算法,如譜聚類
相關推薦
深入淺出聚類演算法之k-means演算法
k-means是一個十分簡單的聚類演算法,它的思路非常簡明清晰,所以經常拿來當做教學。下面就來講述一下這個模型的細節操作。 內容 模型原理 模型收斂過程 模型聚類個數 模型侷限 1. 模型原理 將某一些資料分為不同的類別,在相同的類別中資料之
聚類演算法之K-means演算法與聚類演算法衡量指標
聚類就是按照某個特定標準(如距離準則)把一個數據集分割成不同的類或簇,使得同一個簇內的資料物件的相似性儘可能大,同時不在同一個簇中的資料物件的差異性也儘可能地大。即聚類後同一類的資料儘可能聚集到一起
聚類演算法之K-means演算法
關注微信公眾號【Microstrong】,我寫過四年Android程式碼,瞭解前端、熟悉後臺,現在研究方向是機器學習、深度學習!一起來學習,一起來進步,一起來交流吧! 本文同步更新在我的微信公眾號裡,地址:https://mp.weixin.qq.com/s?__b
聚類方法之k-mean演算法
演算法思想: K-mean演算法又稱K均值演算法,屬於原型聚類中的一種基於距離度量的聚類演算法。其思想是: 1.隨機選取資料集中的k個初始點作為質心,遍歷整個資料集,對於每個樣本,將其歸類到距離其最近的質心所對應的簇。 2.接著計算每個簇的均值,作為當前簇
資料探勘十大經典演算法之K-means 演算法
K-means演算法(非監督性學習) 1.演算法思想 k-means演算法是一種簡單的迭代型聚類演算法,採用距離作為相似性指標,從而發現給定資料集中的K個類,且每個類的中心是根據類中所有值的均值得到,每個類
「AI科技」機器學習演算法之K-means演算法原理及缺點改進思路
https://www.toutiao.com/a6641916717624721933/ 2019-01-03 08:00:00 K-means演算法是使用得最為廣泛的一個演算法,本文將介紹K-means 聚類演算法、原理、特點及改進思路。 K-means聚類演算法簡
大資料之資料探勘理論筆記 聚類問題之K-means
大資料之資料探勘理論筆記 聚類問題之K-means 推薦參考博文: http://www.cnblogs.com/leoo2sk/archive/2010/09/20/k-means.html 推薦參考博文: http://blog.csdn.net/cyxlzzs
聚類之K-means演算法
聚類是一種無監督學習,讓相似的作為一類,不相似的當然不能歸為一類.非常符合我們日常的認知行為.據悉,大多數聚類問題都是NP完全問題,即不存在能夠找到全域性最優解的有效解法.我們常常是將可能的聚類情況定義一個代價函式,問題就轉化為尋找一個代價最小的劃分,變成了
聚類演算法之k-medoids演算法
上一次我們瞭解了一個最基本的 clustering 辦法 k-means ,這次要說的 k-medoids 演算法,其實從名字上就可以看出來,和 k-means 肯定是非常相似的。事實也確實如此,k-medoids 可以算是 k-means 的一個變種。 k-medoids
使用Orange進行資料探勘之聚類分析(2)------K-means
一、基本k均值演算法 1 根據使用者指定的引數K,首先選擇K個初始化質心; 2 然後每個點指派到最近的質心,指派到一個質心的點形成一個簇。 3 更新每個簇的質心 4重複步驟2、3,直到簇不在發生變化。 虛擬碼描述如下: 選擇K個點作為初始質心 repeat 將每個質
無監督學習之K-means演算法通俗教程
概述什麼是聚類分析聚類分析是在資料中發現數據物件之間的關係,將資料進行分組,組內的相似性越大,組間的差別越大,則聚類效果越好。不同的簇型別聚類旨在發現有用的物件簇,在現實中我們用到很多的簇的型別,使用不同的簇型別劃分資料的結果是不同的,如下的幾種簇型別。明顯分離的可以看到(a
機器學習演算法之K-means-spark
1 聚類 簡單回顧一下: 首先,隨機在點群中選取K個點,作為劃分聚落的種子點; 然後,求點群中所有的點到這K個點的距離; 接下來,將離種子點近的點都移動到種子點附近; 最後,不斷重複第二和第三步,直到沒有點需要移動了。 以上只是一個概念的解釋,我想這
機器學習經典演算法之K-Means
一、簡介 K-Means 是一種非監督學習,解決的是聚類問題。K 代表的是 K 類,Means 代表的是中心,你可以理解這個演算法的本質是確定 K 類的中心點,當你找到了這些中心點,也就完成了聚類。 /*請尊重作者勞動成果,轉載請標明原文連結:*/ /* https://www.cnblogs.com/jpc
數學模型:3.非監督學習--聚類分析 和K-means聚類
rand tar 聚類分析 復制 clust tle 降維算法 generator pro 1. 聚類分析 聚類分析(cluster analysis)是一組將研究對象分為相對同質的群組(clusters)的統計分析技術 ---->> 將觀測對象的群體按照
ml課程:聚類概述及K-means講解(含程式碼實現)
以下是我的學習筆記,以及總結,如有錯誤之處請不吝賜教。 本文主要介紹聚類以及K均值演算法的推倒過程,最後有相關程式碼案例。 說到聚類就不得不先說說機器學習的分類。 機器學習主要分為三類: 監督學習:分類、迴歸... 無監督學習:聚類、降維... 強化學習。
機器學習十大經典演算法之K-近鄰演算法(學習筆記)
演算法概述 K-近鄰演算法(k-Nearest Neighbor,KNN)是機器學習演算法中最簡單最容易理解的演算法。該演算法的思路是:給定一個訓練資料集,對新的輸入例項,在訓練資料集中找到與該例項最鄰近的K個例項, 這K個例項的多數屬於某個類,就把該輸入例項分
資料探勘領域十大經典演算法之—K-鄰近演算法/kNN(超詳細附程式碼)
簡介 又叫K-鄰近演算法,是監督學習中的一種分類演算法。目的是根據已知類別的樣本點集求出待分類的資料點類別。 基本思想 kNN的思想很簡單:在訓練集中選取離輸入的資料點最近的k個鄰居,根據這個k個鄰居中出現次數最多的類別(最大表決規則),作為該資料
k均值演算法,k-means演算法原理
一 經典的k-均值聚類 思路: 1 隨機建立k個質心(k必須指定,二維的很容易確定,視覺化資料分佈,直觀確定即可); 2 遍歷資料集的每個例項,計算其到每個質心的相似度,這裡也就是歐氏距離;把每個例項都分配到距離最近的質心的那一類,用一個二維陣列資料結構儲
基於R語言的聚類分析(k-means,層次聚類)
今天給大家展示基於R語言的聚類,在此之前呢,首先談談聚類分析,以及常見的聚類模型,說起聚類我們都知道,就是按照一定的相似性度量方式,把接近的一些個體聚在一起。這裡主要是相似性度量,不同的資料型別,我們需要用不同的度量方式。除此之外,聚類的思想也很重要,要是按照聚
【文字聚類】用k-means對文字進行聚類
# -*- coding: utf-8 -*- """ Created on Thu Nov 16 10:08:52 2017 @author: li-pc """ import jieba fr