
資料結構之陣列(C語言實現)
陣列是大家很熟悉的一種資料型別,而且在我們的程式設計中也應用非常廣泛。這裡以抽象資料型別的形式討論陣列的定義和實現。
一、陣列的定義
假設n維陣列中含有第i維的長度為b(i),則陣列的總長度為b(0) *b(1)*...*b(n-1),每個元素都受著n個關係的約束。在每個關係中元素a(j1,j2,...,jn) (0<=jn<=b(i)-2)都有一個直接後繼元素。因此,就單個關係而言,這n個關係仍然是線性關係。和線性表一樣,所有的資料元素都屬於同一資料型別。陣列的每個資料元素都對應於一組下標(j1,j2,......,jn).特殊地,當n=1,n維陣列就退化為定長的線性表;反之,n維陣列可以看成是線性表的推廣。 陣列一旦被定義,它的維數和維界就不再改變。因此除了結構的初始化和銷燬之外,陣列只有存取元素和修改元素值的操作。
二、陣列的順序表示和實現
1.存在的主序問題
由於我們的記憶體時一維的線性結構,而陣列是個多維的結構,則用一組連續儲存單元存放陣列元素時就有個次序約定問題。因為我們是用C語言實現,所以我們預設都是使用行主序(pascal語言使用列主序)。
2.儲存位置計算
對於陣列,一旦規定了它的維數和各維的長度,便可為它分配儲存空間。反之,只要給出一組下標就可求出相應陣列元素的儲存位置。下面以行序為主序的儲存結構進行說明。 假設每個資料元素佔L個儲存單元,則二維陣列A任一元素a(i, j)的儲存位置可由下式確定: LOC(i, j) = LOC(0, 0)+(b2*i+j) *L 其中LOC(0, 0)是元素a(0, 0)的儲存位置,即二維陣列A的起始儲存位置,也稱為基地址。 現將二維陣列推廣到一般情況,得到n維陣列的資料元素儲存位置的計算公式:
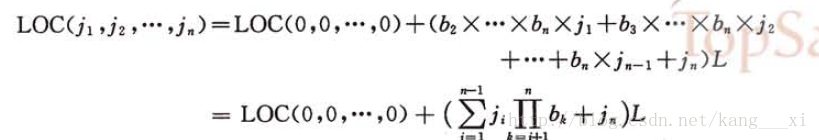
上式稱為n維陣列的映像函式。容易看出,陣列元素的儲存位置是其下標的線性函式,一旦確定了陣列的各維的長度,c(i)就是常數。由於計算各個元素儲存位置的時間相等,所以存取陣列中任一元素的時間也相等。我們稱具有這一特點的儲存結構為隨機儲存結構。
3.補充知識
後面要進行程式碼實現,在此之前先要了解可變引數的使用方法。 VA_LIST 是在C語言中解決變參問題的一組巨集。它有以下幾個成員: (1).va_list型變數: #ifdef _M_ALPHA typedef struct { char *a0; /* pointer to first homed integer argument */ int offset; /* byte offset of next parameter */ } va_list; #else typedef char * va_list; #endif (2)._INTSIZEOF巨集,獲取型別佔用的空間長度,最小佔用長度為int的整數倍: #define _INTSIZEOF(n) ( (sizeof(n) + sizeof(int) - 1) & ~(sizeof(int) - 1) ) (3).VA_START 巨集,獲取可變引數列表的第一個引數的地址(ap是型別為va_list的指標,v是可變引數最左邊的引數): #define va_start(ap,v) ( ap=(va_list)&v + _INTSIZEOF(v)) (4).VA_ARG巨集,獲取可變引數的當前引數,返回指定型別並將指標指向下一引數(t引數描述了當前引數的型別):
#define va_arg(ap,t) ( (t )((ap += _INTSIZEOF(t)) - _INTSIZEOF(t)) )
(5).VA_END巨集,清空va_list可變引數列表:
#define va_end(ap) ( ap = (va_list)0 )
VA_LIST的用法:
(1)首先在函式裡定義一具VA_LIST型的變數,這個變數是指向引數的指標;
(2)然後用VA_START巨集初始化變數剛定義的VA_LIST變數;
(3)然後用VA_ARG返回可變的引數,VA_ARG的第二個引數是你要返回的引數的型別(如果函式有多個可變引數的,依次呼叫VA_ARG獲取各個引數);
(4)最後用VA_END巨集結束可變引數的獲取。
4.程式碼實現
下面給出陣列的順序儲存和實現:
#include <stdio.h>
#include <stdlib.h>
#include <stdarg.h> //標準標頭檔案,提供巨集va_start、va_arg和va_end用於存取變長引數表
#define MAX_ARRAY_DIM 8 //假設陣列維數最大值為8
typedef struct
{
int *base; //陣列元素基址
int dim; //陣列維數
int *bound; //陣列維界基址,即用於儲存每一維的長度
int *constants;//陣列映像函式的各個常量係數
}Array;
//初始化陣列,初始化維度,每一維的長度,和給陣列分配記憶體
void InitArray(Array *A, int dim, ...)
{
if (dim < 1 || dim > MAX_ARRAY_DIM)
return;
A->dim = dim; //初始化陣列的維數
A->bound = (int*)malloc(dim * sizeof(int));
int elemtotal = 1;
va_list ap;
va_start(ap, dim);
for (int i = 0; i < dim; ++i) //存放陣列每一維的長度
{
A->bound[i] = va_arg(ap, int);
elemtotal *= A->bound[i]; //統計陣列的元素個數
}
va_end(ap);
A->base = (int*)malloc(sizeof(int) * elemtotal);
A->constants = (int*)malloc(dim * sizeof(int));
A->constants[dim - 1] = 1; //最後的一維是一維陣列,其引數固定為1
for (int i = dim - 2; i >= 0; --i)
{
A->constants[i] = A->bound[i + 1] * A->constants[i + 1];
}
}
//釋放陣列動態分配的記憶體空間,以免發生記憶體洩露
void DestroyArray(Array *A)
{
if (!A->base)
return;
free(A->base);
A->base = NULL;
if (!A->bound)
{
return;
}
free(A->bound);
A->bound = NULL;
if (!A->constants)
{
return;
}
free(A->constants);
A->constants = NULL;
}
//ap引數中存放著要存取的元素的下標,off為陣列映像函式的常量引數
bool Locate(Array *A, va_list ap, int *off)
{
*off = 0;
for (int i = 0; i < A->dim; ++i)
{
int ind = va_arg(ap, int); //依次取出每一維的下標
if (ind < 0 || ind > A->bound[i])
return false;
(*off) += A->constants[i] * ind;//計算待存取的元素和陣列基址的距離
}
return true;
}
//A是n維陣列,e是元素變數,隨後是n個下標值
//若下標不越界,則將e賦值為所指定的A的元素
void Value(Array *A, int *e, ...)
{
va_list ap;
va_start(ap, e);
int off;
if (!Locate(A, ap, &off))
{
return;
}
*e = *(A->base + off);
}
//A是n維陣列,e是元素變數,隨後是n個下標值
//若下標不越界,則將e賦給指定的A的元素
void Assign(Array *A, int e, ...)
{
va_list ap;
va_start(ap, e);
int off;
if (!Locate(A, ap, &off))
{
return;
}
*(A->base + off) = e;
}
int main(void)
{
Array arr;
InitArray(&arr, 3, 3, 4, 5);
for (int i = 0; i < 3; ++i)
{
for (int j = 0; j < 4; ++j)
{
for (int k = 0; k < 5; ++k)
{
Assign(&arr, i + j + k, i, j, k);
}
}
}
for (int i = 0; i < 3; ++i)
{
for (int j = 0; j < 4; ++j)
{
for (int k = 0; k < 5; ++k)
{
int tmp = 1;
Value(&arr, &tmp, i, j, k);
printf("%5d", tmp);
}
printf("\n");
}
printf("\n");
}
printf("\n");
return 0;
}參考資料:
《資料結構》嚴蔚敏版
http://justsee.iteye.com/blog/1637173
相關推薦
資料結構之陣列(C語言實現)
陣列是大家很熟悉的一種資料型別,而且在我們的程式設計中也應用非常廣泛。這裡以抽象資料型別的形式討論陣列的定義和實現。 一、陣列的定義 假設n維陣列中含有第i維的長度為b(i),則陣列的總長度為b(0) *b(1)*...*b(n-1),每個元素都受著n個
資料結構之連結串列C語言實現以及使用場景分析
連結串列是資料結構中比較基礎也是比較重要的型別之一,那麼有了陣列,為什麼我們還需要連結串列呢!或者說設計連結串列這種資料結構的初衷在哪裡? 這是因為,在我們使用陣列的時候,需要預先設定目標群體的個數,也即陣列容量的大小,然而實時情況下我們目標的個數我們是不確定的,因此我們總是要把陣列的容量設定的
資料結構中,幾種樹的結構表示方法(C語言實現)
//***************************************** //樹的多種結構定義 //***************************************** #define MAX_TREE_SIZE 100 typedef int TempType;
資料結構之堆排序C語言實現
堆排序: 時間複雜度:O(nlogn) 穩定性:不穩定 實現原理:將待排序的序列構造成一個大頂堆(或小頂堆) 整個序列的最大值就是堆頂的根節點,將它移走 (就是將其與對陣列的末尾元素交換,此時末尾元素就是最大值)。然後將剩餘的n-1個序列重新 構成
資料結構之圖(鄰接表實現)(C++)
一、圖的鄰接表實現 1.實現了以頂點順序表、邊連結串列為儲存結構的鄰接表; 2.實現了圖的建立(有向/無向/圖/網)、邊的增刪操作、深度優先遞迴/非遞迴遍歷、廣度優先遍歷的演算法; 3.採用頂點物件列表、邊(弧)物件列表的方式,對圖的建立進行初始化;引用 "ObjArr
《資料結構題集(C語言版)》電子書下載 -(百度網盤 高清版PDF格式)
作者:嚴蔚敏,吳偉民,米寧 出版日期:1999-2-1 出版社:清華出版社 頁數:234 ISBN:9787302033141 檔案格式:PDF 檔案大小:18.13 MB 本
資料結構學習筆記——線性表之順序表(c語言實現)
1.概念 順序表即線性表的順序儲存結構 ,指的是用一段地址連續的儲存單元依次儲存線性表資料元素。線上性表中,每個資料元素的型別都相同,一般可以用一維陣列來實現順序儲存結構。 2.實現 (1)建立順序表的結構 利用c語言結構體來建立順序表的結構,順序表結構體中
資料結構學習筆記——堆疊之鏈式儲存結構(c語言實現)
棧的鏈式儲存結構使用單鏈表實現,同線性表一樣,鏈式儲存結構的堆疊在儲存空間的利用上顯得更加靈活,只要硬體允許一般不會出現溢位的情況。但鏈式棧相對於順序棧稍顯麻煩,若所需堆疊空間確定,順序棧顯得方便一些。關於鏈式和順序式的選擇視具體情況而定。 1.棧的鏈式儲存結構
資料結構之 二叉查詢樹(C語言實現)
資料結構之 二叉查詢樹 1. 二叉查詢樹的定義 二叉查詢樹(binary search tree)是一棵二叉樹,或稱為二叉搜尋樹,可能為空;一棵非空的二叉查詢樹滿足一下特徵: 每個元素有一個關鍵字,並且任意兩個元素的關鍵字都不同;因此,所有的關鍵字都是唯
資料結構排序演算法之歸併排序(c語言實現)
博主身為大二萌新,第一次學習資料結構,自學到排序的時候,對於書上各種各樣的排序演算法頓覺眼花繚亂,便花了很長的時間盡力把每一個演算法都看懂,但限於水平有限,可能還是理解較淺,於是便將它們逐個地整理實現出來,以便加深理解。 歸併排序就是通過將一個具有n個key記錄的線性表,看
資料結構之二叉排序樹(C語言實現)
一、基本概念1.二叉排序樹 二叉排序樹(Binary sort tree,BST),又稱為二叉查詢樹,或者是一棵空樹;或者是具有下列性質的二叉樹: (1)若它的左子樹不為空,則左子樹上所有節點的值均小於它的根節點的值; (2)若它的右
資料結構之 AVL樹(平衡二叉樹)(C語言實現)
AVL樹(平衡二叉樹) 1. AVL樹定義和性質 AVL(Adelson-Velskii和Landis發明者的首字母)樹時帶有平衡條件的二叉查詢樹。 二叉查詢樹的效能分析: 在一顆左右子樹高度平衡情況下,最優的時間複雜度為O(log2n),這與這半
資料結構之串的模式匹配(C語言實現)
一、暴力匹配演算法(BF) BF全稱為Brute-Force,最簡單直觀的模式匹配演算法。 1.演算法思想 兩個字串進行匹配時,一個主串和一個模式串,就是按照我們最容易想到的演算法來進行匹配。用兩個變數i,j分別記錄主串和模式串的匹配位置,如果兩者在某個字
資料結構(嚴蔚敏)之五——迴圈佇列(c語言實現)
在這裡我先強調幾點概念: 1、在非空佇列中,頭指標始終指向佇列頭元素,而尾指標始終指向佇列尾元素的下一個位置。 2、在單佇列中我們判斷佇列是否為空的條件是:Q.front==Q.rear;而在迴圈佇列
資料結構排序演算法之快速排序(c語言實現)
快排的原理就是通過一趟排序將待排記錄分割成獨立的兩部分,其中的一部分記錄的關鍵字均比另一部分記錄的關鍵字小,則可分別對這兩部分記錄繼續進行排序,以達到整個序列有序。這其中,可以使用遞迴呼叫某一關鍵函式的辦法來實現這樣的功能。 分割的方法就是,選取一個樞軸,將所有關鍵字比它
資料結構——順序表操作(C語言實現)
//順序表list #include"stdio.h" #define maxsize 15 typedef struct{ int a[maxsize]; int size; }list; //建立 void create(lis
資料結構—— 一元多項式的表示及相加(C語言實現)
程式碼比較簡單,沒有完全按照嚴蔚敏版《資料結構(C語言版)》上39頁到43頁上的要求,只是實現了簡單功能,且此程式碼輸入多項式時只能按升冪的順序輸入(因為沒有寫多項式排序的函式) 個人感覺此程式碼短小精悍,且易理解,看懂了的話可以嘗試完全按照書上的要求自己寫程式
資料結構(C語言實現):判斷兩棵二叉樹是否相等,bug求解
判斷兩棵二叉樹是否相等。 遇到了bug,求大神幫忙!!! C語言原始碼: #include <stdio.h> #include <stdlib.h> #include <malloc.h> #define OK 1 #define
資料結構——入棧,出棧,佇列相關操作(C語言實現)
閱讀過程之中可能會花費比較多的時間:建議直接翻到最後,有完整的程式碼可以使用 程式準備工作 #include <stdio.h> #include <malloc.h> #include <stdlib.h> #include<proc
資料結構——哈夫曼樹的實現以及編碼(C語言實現)
1、問題描述 利用哈夫曼編碼進行通訊可以大大提高通道利用率,縮簡訊息傳輸時間,降低傳輸成本。構造哈夫曼樹時,首先將由n個字 符形成的n個葉子結點存放到陣列HuffNode的前n個分量中,然後根據哈夫曼方法的基本思想,不斷將兩個較小的子樹合併為一個