
第十六節、特徵描述符BRIEF(附原始碼)
我們已經知道SIFT演算法採用128維的特徵描述子,由於描述子用的是浮點數,所以它將會佔用512位元組的空間。類似的SUFR演算法,一般採用64維的描述子,它將佔用256位元組的空間。如果一幅影象中有1000個特徵點,那麼SIFT或SURF特徵描述子將佔用大量的記憶體空間,對於那些資源緊張的應用,尤其是嵌入式的應用,這樣的特徵描述子顯然是不可行的。而且,越佔有越大的空間,意味著越長的匹配時間。
但是實際上SIFT或SURF的特徵描述子中,並不是所有維都在匹配中有著實質性的作用。我們可以用PCA、LDA等特徵降維的方法來壓縮特徵描述子的維度。還有一些演算法,例如區域性敏感雜湊(Locality-Sensitive Hashing, LSH),將SIFT的特徵描述子轉換為一個二值的碼串,然後這個碼串用漢明距離進行特徵點之間的匹配。這種方法將大大提高特徵之間的匹配,因為漢明距離的計算可以用異或操作然後計算二進位制位數來實現,在現代計算機結構中很方便。下面我們來提取一種二值碼串的特徵描述子。
一 BRIEF簡述
BRIEF(Binary Robust Independent Elementary Features)應運而生,它提供了一種計算二值化的捷徑,並不需要計算一個類似於SIFT的特徵描述子。它需要先平滑影象,然後在特徵點周圍選擇一個Patch,在這個Patch內通過一種選定的方法來挑選出來$n_d$個點對。然後對於每一個點對$(p,q)$,我們比較這兩個點的亮度值,如果$I(p)<I(q)$,則對應在二值串中的值為1,否則為0,。所有$n_d$個點對,都進行比較之間,我們就生成了一個$n_d$長的二進位制串。
對於$n_d$的選擇,我們可以設定為128,256或者512,這三個引數在OpenCV中都有提供,但是OpenCV中預設的引數是256,這種情況下,經過大量實驗資料測試,不匹配的特徵點的描述子的漢明距離在128左右,匹配點對描述子的漢明距離則遠小於128。一旦維數選定了,我們就可以用漢明距離來匹配這些描述子了。
我們總結一下特徵描述子的建立過程:
- 利用Harris或者FAST等方法檢測特徵點;
- 選定建立特徵描述子的區域(特徵點的一個正方形鄰域);
- 對該鄰域用$\sigma=2$視窗尺寸為9的的高斯核卷積,以消除一些噪聲。因為該特徵描述子隨機性強,對噪聲較為敏感;
- 以一定的隨機化演算法生成點對$(p,q)$,若點$I(p)<I(q)$的亮度,則返回1,否則返回0;
- 重複第三步若干次(如256次),得到一個256位的二進位制碼串,即該特徵點的描述子;
值得注意的是,對於BRIEF,它僅僅是一種特徵描述符,它不提供提取特徵點的方法。所以,如果你必須使一種特徵點定位的方法,如FAST、SIFT、SURF等。這裡,我們將使用CenSurE方法來提取關鍵點,對BRIEF來說,CenSurE的表現比SURF特徵點稍好一些。
總體來說,BRIEF是一個效率很高的提取特徵描述子的方法,我們總結一下該特徵描述子的優缺點:
首先,它拋棄了傳統的利用影象區域性鄰域的灰度直方圖或梯度直方圖提取特徵方法,改用檢測隨機響應,大大加快了描述子的建立速度;生成的二進位制特徵描述子便於高速匹配(計算漢明距離只需要通過異或操作加上統計二進位制編碼中"1"的個數,這些通過底層運算可以實現),且便於在硬體上實現。其次,該特徵描述子的缺點很明顯就是旋轉不變形較差,需要通過新的方法來改進。
通過實驗,作者進行結果比較:
- 在旋轉程度較小的影象中,使用BRIEF特徵描述子的匹配質量非常高,測試的大多數情況都超過了SURF,但是在旋轉大於30°後,BRIEF特徵描述子的匹配率快速降到0左右;
- BRIEF的耗時非常短,在相同情況下計算512個特徵點的描述子是,SURF耗時335ms,BRIEF僅8.18ms;匹配SURF描述子需要28.3ms,BRIEF僅需要2.19ms,在要求不太高的情形下,BRIEF描述子更容易做到實時;
BRIEF的優點主要在於速度,缺點也很明顯:
- 不具有旋轉不變形;
- 對噪聲敏感
- 不具有尺度不變性
因此為了解決前兩個缺點,並且綜合考慮速度和效能,提出了ORB演算法,該演算法將基於FAST關鍵點檢測的技術和BRIEF特徵描述子技術相結合。
二 點對的選擇
設我們在特徵點的鄰域塊大小為$S\times{S}$內選擇$n_d$個點對$(p,q)$,Colonder的實驗中測試了5種取樣方法。
- 在影象塊內平均取樣;
- $p$和$q$都符合$(0,\frac{1}{25}S^2)$的 高斯分佈;
- $p$符合$(0,\frac{1}{25}S^2)$的高斯分佈,而$q$符合$(0,\frac{1}{100}S^2)$的高斯分佈;
- 在空間量化極座標下的離散位置隨機取樣;
- 把$p$固定為(0,0),$q$在周圍平均取樣;
下面是5種取樣方法的結果示意圖:


三 OpenCV實現
我們使用OpenCV演示一下特徵點提取、BRIEF特徵描述子提取、以及特徵點匹配的過程:
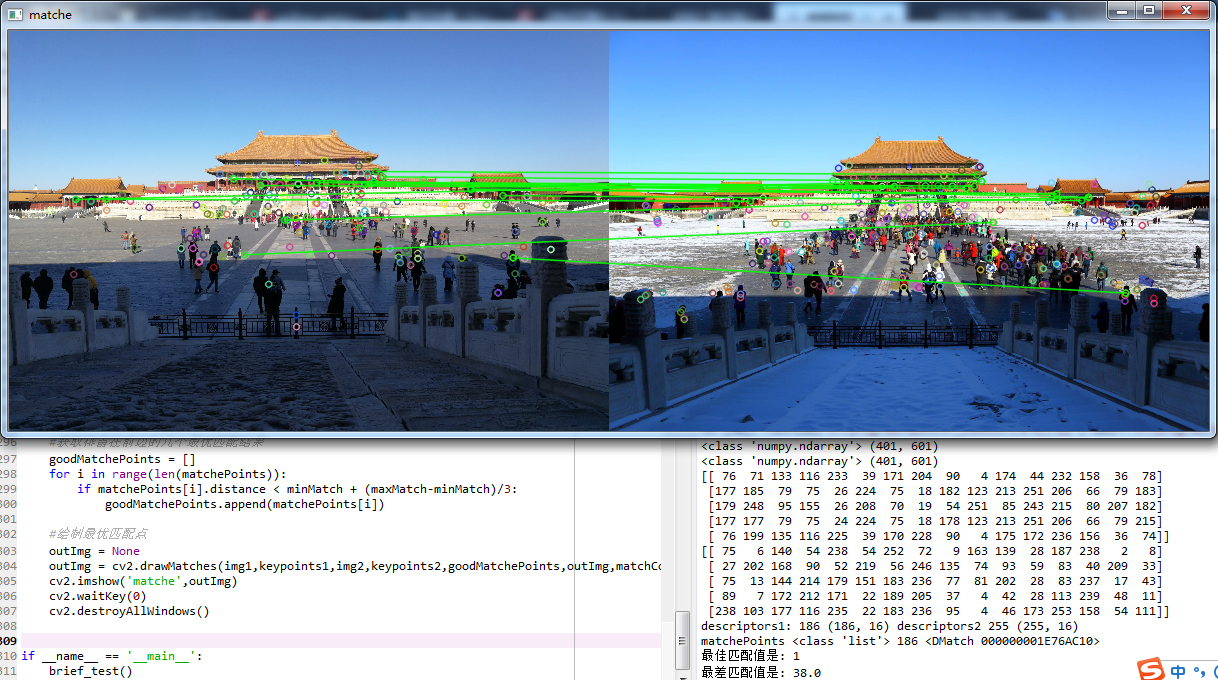
# -*- coding: utf-8 -*- """ Created on Mon Sep 10 09:59:22 2018 @author: zy """ ''' 使用BRIEF特徵描述符 ''' import cv2 import numpy as np def brief_test(): #載入圖片 灰色 img1 = cv2.imread('./image/match1.jpg') img1 = cv2.resize(img1,dsize=(600,400)) gray1 = cv2.cvtColor(img1,cv2.COLOR_BGR2GRAY) img2 = cv2.imread('./image/match2.jpg') img2 = cv2.resize(img2,dsize=(600,400)) gray2 = cv2.cvtColor(img2,cv2.COLOR_BGR2GRAY) image1 = gray1.copy() image2 = gray2.copy() image1 = cv2.medianBlur(image1,5) image2 = cv2.medianBlur(image2,5) ''' 1.使用SURF演算法檢測關鍵點 ''' #建立一個SURF物件 閾值越高,能識別的特徵就越少,因此可以採用試探法來得到最優檢測。 surf = cv2.xfeatures2d.SURF_create(3000) keypoints1 = surf.detect(image1) keypoints2 = surf.detect(image2) #在影象上繪製關鍵點 image1 = cv2.drawKeypoints(image=image1,keypoints = keypoints1,outImage=image1,color=(255,0,255),flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS) image2 = cv2.drawKeypoints(image=image2,keypoints = keypoints2,outImage=image2,color=(255,0,255),flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS) #顯示影象 cv2.imshow('sift_keypoints1',image1) cv2.imshow('sift_keypoints2',image2) cv2.waitKey(20) ''' 2.計算特徵描述符 ''' brief = cv2.xfeatures2d.BriefDescriptorExtractor_create(32) keypoints1, descriptors1 = brief.compute(image1, keypoints1) keypoints2, descriptors2 = brief.compute(image2, keypoints2) print('descriptors1:',len(descriptors1),'descriptors2',len(descriptors2)) ''' 3.匹配 漢明距離匹配特徵點 ''' matcher = cv2.BFMatcher_create(cv2.HAMMING_NORM_TYPE) matchePoints = matcher.match(descriptors1,descriptors2) print(type(matchePoints),len(matchePoints),matchePoints[0]) #提取強匹配特徵點 minMatch = 1 maxMatch = 0 for i in range(len(matchePoints)): if minMatch > matchePoints[i].distance: minMatch = matchePoints[i].distance if maxMatch < matchePoints[i].distance: maxMatch = matchePoints[i].distance print('最佳匹配值是:',minMatch) print('最差匹配值是:',maxMatch) #獲取排雷在前邊的幾個最優匹配結果 goodMatchePoints = [] for i in range(len(matchePoints)): if matchePoints[i].distance < minMatch + (maxMatch-minMatch)/3: goodMatchePoints.append(matchePoints[i]) #繪製最優匹配點 outImg = None outImg = cv2.drawMatches(img1,keypoints1,img2,keypoints2,goodMatchePoints,outImg,matchColor=(0,255,0),flags=cv2.DRAW_MATCHES_FLAGS_DEFAULT) cv2.imshow('matche',outImg) cv2.waitKey(0) cv2.destroyAllWindows() if __name__ == '__main__': brief_test()

由於BRIEF描述子對噪聲比較敏感,因此我們對圖片進行了中值濾波處理,雖然消除了部分誤匹配點,但是從上圖中可以看到匹配的效果並不是很好。在實際應用上,我們應該選取兩個近似一致並且噪聲點較少的影象,這樣才能取得較高的匹配質量。
四 自己實現
下面我們嘗試自己去實現BRIEF描述符,程式碼如下(注意這個程式碼是仿照OpenCV的C++實現):
# -*- coding: utf-8 -*- """ Created on Mon Sep 10 15:38:39 2018 @author: zy """ ''' 自己實現一個BRIEF特徵描述符 參考:Opencv2.4.9原始碼分析——BRIEF https://blog.csdn.net/zhaocj/article/details/44236863 ''' import cv2 import numpy as np import functools class BriefDescriptorExtractor(object): ''' BRIEF描述符實現 ''' def __init__(self,byte=16): ''' args: byte:描述子佔用的位元組數,這裡只實現了16,32和64的沒有實現 ''' #鄰域範圍 self.__patch_size = 48 #平均積分核大小 self.__kernel_size = 9 #佔用位元組數16,對應描述子長度16*8=128 128個點對 self.__bytes = byte def compute(self,image,keypoints): ''' 計算特徵描述符 args: image:輸入影象 keypoints:影象的關鍵點集合 return: 特徵點,特徵描述符元組 ''' if len(image.shape) == 3: gray_image = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY) else: gray_image = image.clone() #計算積分影象 self.__image_sum = cv2.integral(gray_image,sdepth = cv2.CV_32S) print(type(self.__image_sum),self.__image_sum.shape) #移除接近邊界的關鍵點 keypoints_res = [] rows,cols = image.shape[:2] for keypoint in keypoints: point = keypoint.pt if point[0] > (self.__patch_size + self.__kernel_size)/2 and point[0] < cols-(self.__patch_size + self.__kernel_size/2): if point[1] > (self.__patch_size+self.__kernel_size)/2 and point[1] < rows - (self.__patch_size + self.__kernel_size )/2: keypoints_res.append(keypoint) #計算特徵點描述符 return keypoints_res,self.pixelTests16(keypoints_res) def pixelTests16(self,keypoints): ''' 建立BRIEF描述符 args: keypoints:關鍵點 return: descriptors:返回描述符 ''' descriptors = np.zeros((len(keypoints),self.__bytes),dtype=np.uint8) for i in range(len(keypoints)): #固定預設引數 SMOOTHED = functools.partial(self.smoothed_sum,keypoint=keypoints[i]) descriptors[i][0] = (((SMOOTHED(-2, -1) < SMOOTHED(7, -1)) << 7) + ((SMOOTHED(-14, -1) < SMOOTHED(-3, 3)) << 6) + ((SMOOTHED(1, -2) < SMOOTHED(11, 2)) << 5) + ((SMOOTHED(1, 6) < SMOOTHED(-10, -7)) << 4) + ((SMOOTHED(13, 2) < SMOOTHED(-1, 0)) << 3) + ((SMOOTHED(-14, 5) < SMOOTHED(5, -3)) << 2) + ((SMOOTHED(-2, 8) < SMOOTHED(2, 4)) << 1) + ((SMOOTHED(-11, 8) < SMOOTHED(-15, 5)) << 0)) descriptors[i][1] = (((SMOOTHED(-6, -23) < SMOOTHED(8, -9)) << 7) + ((SMOOTHED(-12, 6) < SMOOTHED(-10, 8)) << 6) + ((SMOOTHED(-3, -1) < SMOOTHED(8, 1)) << 5) + ((SMOOTHED(3, 6) < SMOOTHED(5, 6)) << 4) + ((SMOOTHED(-7, -6) < SMOOTHED(5, -5)) << 3) + ((SMOOTHED(22, -2) < SMOOTHED(-11, -8)) << 2) + ((SMOOTHED(14, 7) < SMOOTHED(8, 5)) << 1) + ((SMOOTHED(-1, 14) < SMOOTHED(-5, -14)) << 0)) descriptors[i][2] = (((SMOOTHED(-14, 9) < SMOOTHED(2, 0)) << 7) + ((SMOOTHED(7, -3) < SMOOTHED(22, 6)) << 6) + ((SMOOTHED(-6, 6) < SMOOTHED(-8, -5)) << 5) + ((SMOOTHED(-5, 9) < SMOOTHED(7, -1)) << 4) + ((SMOOTHED(-3, -7) < SMOOTHED(-10, -18)) << 3) + ((SMOOTHED(4, -5) < SMOOTHED(0, 11)) << 2) + ((SMOOTHED(2, 3) < SMOOTHED(9, 10)) << 1) + ((SMOOTHED(-10, 3) < SMOOTHED(4, 9)) << 0)) descriptors[i][3] = (((SMOOTHED(0, 12) < SMOOTHED(-3, 19)) << 7) + ((SMOOTHED(1, 15) < SMOOTHED(-11, -5)) << 6) + ((SMOOTHED(14, -1) < SMOOTHED(7, 8)) << 5) + ((SMOOTHED(7, -23) < SMOOTHED(-5, 5)) << 4) + ((SMOOTHED(0, -6) < SMOOTHED(-10, 17)) << 3) + ((SMOOTHED(13, -4) < SMOOTHED(-3, -4)) << 2) + ((SMOOTHED(-12, 1) < SMOOTHED(-12, 2)) << 1) + ((SMOOTHED(0, 8) < SMOOTHED(3, 22)) << 0)) descriptors[i][4] = (((SMOOTHED(-13, 13) < SMOOTHED(3, -1)) << 7) + ((SMOOTHED(-16, 17) < SMOOTHED(6, 10)) << 6) + ((SMOOTHED(7, 15) < SMOOTHED(-5, 0)) << 5) + ((SMOOTHED(2, -12) < SMOOTHED(19, -2)) << 4) + ((SMOOTHED(3, -6) < SMOOTHED(-4, -15)) << 3) + ((SMOOTHED(8, 3) < SMOOTHED(0, 14)) << 2) + ((SMOOTHED(4, -11) < SMOOTHED(5, 5)) << 1) + ((SMOOTHED(11, -7) < SMOOTHED(7, 1)) << 0)) descriptors[i][5] = (((SMOOTHED(6, 12) < SMOOTHED(21, 3)) << 7) + ((SMOOTHED(-3, 2) < SMOOTHED(14, 1)) << 6) + ((SMOOTHED(5, 1) < SMOOTHED(-5, 11)) << 5) + ((SMOOTHED(3, -17) < SMOOTHED(-6, 2)) << 4) + ((SMOOTHED(6, 8) < SMOOTHED(5, -10)) << 3) + ((SMOOTHED(-14, -2) < SMOOTHED(0, 4)) << 2) + ((SMOOTHED(5, -7) < SMOOTHED(-6, 5)) << 1) + ((SMOOTHED(10, 4) < SMOOTHED(4, -7)) << 0)) descriptors[i][6] = (((SMOOTHED(22, 0) < SMOOTHED(7, -18)) << 7) + ((SMOOTHED(-1, -3) < SMOOTHED(0, 18)) << 6) + ((SMOOTHED(-4, 22) < SMOOTHED(-5, 3)) << 5) + ((SMOOTHED(1, -7) < SMOOTHED(2, -3)) << 4) + ((SMOOTHED(19, -20) < SMOOTHED(17, -2)) << 3) + ((SMOOTHED(3, -10) < SMOOTHED(-8, 24)) << 2) + ((SMOOTHED(-5, -14) < SMOOTHED(7, 5)) << 1) + ((SMOOTHED(-2, 12) < SMOOTHED(-4, -15)) << 0)) descriptors[i][7] = (((SMOOTHED(4, 12) < SMOOTHED(0, -19)) << 7) + ((SMOOTHED(20, 13) < SMOOTHED(3, 5)) << 6) + ((SMOOTHED(-8, -12) < SMOOTHED(5, 0)) << 5) + ((SMOOTHED(-5, 6) < SMOOTHED(-7, -11)) << 4) + ((SMOOTHED(6, -11) < SMOOTHED(-3, -22)) << 3) + ((SMOOTHED(15, 4) < SMOOTHED(10, 1)) << 2) + ((SMOOTHED(-7, -4) < SMOOTHED(15, -6)) << 1) + ((SMOOTHED(5, 10) < SMOOTHED(0, 24)) << 0)) descriptors[i][8] = (((SMOOTHED(3, 6) < SMOOTHED(22, -2)) << 7) + ((SMOOTHED(-13, 14) < SMOOTHED(4, -4)) << 6) + ((SMOOTHED(-13, 8) < SMOOTHED(-18, -22)) << 5) + ((SMOOTHED(-1, -1) < SMOOTHED(-7, 3)) << 4) + ((SMOOTHED(-19, -12) < SMOOTHED(4, 3)) << 3) + ((SMOOTHED(8, 10) < SMOOTHED(13, -2)) << 2) + ((SMOOTHED(-6, -1) < SMOOTHED(-6, -5)) << 1) + ((SMOOTHED(2, -21) < SMOOTHED(-3, 2)) << 0)) descriptors[i][9] = (((SMOOTHED(4, -7) < SMOOTHED(0, 16)) << 7) + ((SMOOTHED(-6, -5) < SMOOTHED(-12, -1)) << 6) + ((SMOOTHED(1, -1) < SMOOTHED(9, 18)) << 5) + ((SMOOTHED(-7, 10) < SMOOTHED(-11, 6)) << 4) + ((SMOOTHED(4, 3) < SMOOTHED(19, -7)) << 3) + ((SMOOTHED(-18, 5) < SMOOTHED(-4, 5)) << 2) + ((SMOOTHED(4, 0) < SMOOTHED(-20, 4)) << 1) + ((SMOOTHED(7, -11) < SMOOTHED(18, 12)) << 0)) descriptors[i][10] = (((SMOOTHED(-20, 17) < SMOOTHED(-18, 7)) << 7) + ((SMOOTHED(2, 15) < SMOOTHED(19, -11)) << 6) + ((SMOOTHED(-18, 6) < SMOOTHED(-7, 3)) << 5) + ((SMOOTHED(-4, 1) < SMOOTHED(-14, 13)) << 4) + ((SMOOTHED(17, 3) < SMOOTHED(2, -8)) << 3) + ((SMOOTHED(-7, 2) < SMOOTHED(1, 6)) << 2) + ((SMOOTHED(17, -9) < SMOOTHED(-2, 8)) << 1) + ((SMOOTHED(-8, -6) < SMOOTHED(-1, 12)) << 0)) descriptors[i][11] = (((SMOOTHED(-2, 4) < SMOOTHED(-1, 6)) << 7) + ((SMOOTHED(-2, 7) < SMOOTHED(6, 8)) << 6) + ((SMOOTHED(-8, -1) < SMOOTHED(-7, -9)) << 5) + ((SMOOTHED(8, -9) < SMOOTHED(15, 0)) << 4) + ((SMOOTHED(0, 22) < SMOOTHED(-4, -15)) << 3) + ((SMOOTHED(-14, -1) < SMOOTHED(3, -2)) << 2) + ((SMOOTHED(-7, -4) < SMOOTHED(17, -7)) << 1) + ((SMOOTHED(-8, -2) < SMOOTHED(9, -4)) << 0)) descriptors[i][12] = (((SMOOTHED(5, -7) < SMOOTHED(7, 7)) << 7) + ((SMOOTHED(-5, 13) < SMOOTHED(-8, 11)) << 6) + ((SMOOTHED(11, -4) < SMOOTHED(0, 8)) << 5) + ((SMOOTHED(5, -11) < SMOOTHED(-9, -6)) << 4) + ((SMOOTHED(2, -6) < SMOOTHED(3, -20)) << 3) + ((SMOOTHED(-6, 2) < SMOOTHED(6, 10)) << 2) + ((SMOOTHED(-6, -6) < SMOOTHED(-15, 7)) << 1) + ((SMOOTHED(-6, -3) < SMOOTHED(2, 1)) << 0)) descriptors[i][13] = (((SMOOTHED(11, 0) < SMOOTHED(-3, 2)) << 7) + ((SMOOTHED(7, -12) < SMOOTHED(14, 5)) << 6) + ((SMOOTHED(0, -7) < SMOOTHED(-1, -1)) << 5) + ((SMOOTHED(-16, 0) < SMOOTHED(6, 8)) << 4) + ((SMOOTHED(22, 11) < SMOOTHED(0, -3)) << 3) + ((SMOOTHED(19, 0) < SMOOTHED(5, -17)) << 2) + ((SMOOTHED(-23, -14) < SMOOTHED(-13, -19)) << 1) + ((SMOOTHED(-8, 10) < SMOOTHED(-11, -2)) << 0)) descriptors[i][14] = (((SMOOTHED(-11, 6) < SMOOTHED(-10, 13)) << 7) + ((SMOOTHED(1, -7) < SMOOTHED(14, 0)) << 6) + ((SMOOTHED(-12, 1) < SMOOTHED(-5, -5)) << 5) + ((SMOOTHED(4, 7) < SMOOTHED(8, -1)) << 4) + ((SMOOTHED(-1, -5) < SMOOTHED(15, 2)) << 3) + ((SMOOTHED(-3, -1) < SMOOTHED(7, -10)) << 2) + ((SMOOTHED(3, -6) < SMOOTHED(10, -18)) << 1) + ((SMOOTHED(-7, -13) < SMOOTHED(-13, 10)) << 0)) descriptors[i][15] = (((SMOOTHED(1, -1) < SMOOTHED(13, -10)) << 7) + ((SMOOTHED(-19, 14) < SMOOTHED(8, -14)) << 6) + ((SMOOTHED(-4, -13) < SMOOTHED(7, 1)) << 5) + ((SMOOTHED(1, -2) < SMOOTHED(12, -7)) << 4) + ((SMOOTHED(3, -5) < SMOOTHED(1, -5)) << 3) + ((SMOOTHED(-2, -2) < SMOOTHED(8, -10)) << 2) + ((SMOOTHED(2, 14) < SMOOTHED(8, 7)) << 1) + ((SMOOTHED(3, 9) < SMOOTHED(8, 2)) << 0)) return descriptors def smoothed_sum(self,y,x,keypoint): ''' 這裡我們採用隨機點平滑,不採用論文中的高斯平滑,而是採用隨機點鄰域內積分和代替,同樣可以降低噪聲的影響 args: self.__image_sum:影象積分圖 屬性 keypoint:其中一個關鍵點 y,x:x和y表示點對中某一個畫素相對於特徵點的座標 return: 函式返回濾波的結果 ''' half_kernel = self.__kernel_size // 2 #計算點對中某一個畫素的絕對座標 img_y = int(keypoint.pt[1] + 0.5) + y img_x = int(keypoint.pt[0] + 0.5) + x #計算以該畫素為中心,以KERNEL_SIZE為邊長的正方形內所有畫素灰度值之和,本質上是均值濾波 ret = self.__image_sum[img_y + half_kernel+1][img_x + half_kernel+1] \ -self.__image_sum[img_y + half_kernel+1][img_x - half_kernel] \ -self.__image_sum[img_y - half_kernel][img_x + half_kernel+1] \ +self.__image_sum[img_y - half_kernel][img_x - half_kernel] return ret def brief_test(): #載入圖片 灰色 img1 = cv2.imread('./image/match1.jpg') img1 = cv2.resize(img1,dsize=(600,400)) gray1 = cv2.cvtColor(img1,cv2.COLOR_BGR2GRAY) img2 = cv2.imread('./image/match2.jpg') img2 = cv2.resize(img2,dsize=(600,400)) gray2 = cv2.cvtColor(img2,cv2.COLOR_BGR2GRAY) image1 = gray1.copy() image2 = gray2.copy() image1 = cv2.medianBlur(image1,5) image2 = cv2.medianBlur(image2,5) ''' 1.使用SURF演算法檢測關鍵點 ''' #建立一個SURF物件 閾值越高,能識別的特徵就越少,因此可以採用試探法來得到最優檢測。 surf = cv2.xfeatures2d.SURF_create(3000) keypoints1 = surf.detect(image1) keypoints2 = surf.detect(image2) #print(keypoints1[0].pt) #(x,y) #在影象上繪製關鍵點 image1 = cv2.drawKeypoints(image=image1,keypoints = keypoints1,outImage=image1,color=(255,0,255),flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS) image2 = cv2.drawKeypoints(image=image2,keypoints = keypoints2,outImage=image2,color=(255,0,255),flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS) #顯示影象 #cv2.imshow('surf_keypoints1',image1) #cv2.imshow('surf_keypoints2',image2) #cv2.waitKey(20) ''' 2.計算特徵描述符 ''' brief = BriefDescriptorExtractor(16) keypoints1,descriptors1 = brief.compute(image1, keypoints1) keypoints2,descriptors2 = brief.compute(image2, keypoints2) print(descriptors1[:5]) print(descriptors2[:5]) print('descriptors1:',len(descriptors1),descriptors1.shape,'descriptors2',len(descriptors2),descriptors2.shape) ''' 3.匹配 漢明距離匹配特徵點 ''' matcher = cv2.BFMatcher_create(cv2.HAMMING_NORM_TYPE) matchePoints = matcher.match(descriptors1,descriptors2) print('matchePoints',type(matchePoints),len(matchePoints),matchePoints[0]) #提取強匹配特徵點 minMatch = 1 maxMatch = 0 for i in range(len(matchePoints)): if minMatch > matchePoints[i].distance: minMatch = matchePoints[i].distance if maxMatch < matchePoints[i].distance: maxMatch = matchePoints[i].distance print('最佳匹配值是:',minMatch) print('最差匹配值是:',maxMatch) #獲取排雷在前邊的幾個最優匹配結果 goodMatchePoints = [] for i in range(len(matchePoints)): if matchePoints[i].distance < minMatch + (maxMatch-minMatch)/3: goodMatchePoints.append(matchePoints[i]) #繪製最優匹配點 outImg = None outImg = cv2.drawMatches(img1,keypoints1,img2,keypoints2,goodMatchePoints,outImg,matchColor=(0,255,0),flags=cv2.DRAW_MATCHES_FLAGS_DEFAULT) cv2.imshow('matche',outImg) cv2.waitKey(0) cv2.destroyAllWindows() if __name__ == '__main__': brief_test()
參考文章:
相關推薦
第十六節、特徵描述符BRIEF(附原始碼)
我們已經知道SIFT演算法採用128維的特徵描述子,由於描述子用的是浮點數,所以它將會佔用512位元組的空間。類似的SUFR演算法,一般採用64維的描述子,它將佔用256位元組的空間。如果一幅影象中有1000個特徵點,那麼SIFT或SURF特徵描述子將佔用大量的記憶體空間,對於那些資源緊張的應用,尤其是嵌入式
第十七節、影象描述符匹配演算法、以及目標匹配
在前面的一些小節中,我們已經使用到的影象描述符匹配相關的函式,在OpenCV中主要提供了暴力匹配、以及FLANN匹配函式庫。 一 暴力匹配以及優化(交叉匹配、KNN匹配) 暴力匹配即兩兩匹配。該演算法不涉及優化,假設從圖片A中提取了$m$個特徵描述符,從B圖片提取了$n$個特徵描述符。對於A中$m$個特徵描述
第十四節、FAST角點檢測(附原始碼)
在前面我們已經陸續介紹了許多特徵檢測運算元,我們可以根據影象區域性的自相關函式求得Harris角點,後面又提到了兩種十分優秀的特徵點以及他們的描述方法SIFT特徵和SURF特徵。SURF特徵是為了提高運算效率對SIFT特徵的一種近似,雖然在有些實驗環境中已經達到了實時,但是我們實踐工程應用中,特徵點的提取與匹
第十六節、基於ORB的特徵檢測和特徵匹配
之前我們已經介紹了SIFT演算法,以及SURF演算法,但是由於計算速度較慢的原因。人們提出了使用ORB來替代SIFT和SURF。與前兩者相比,ORB有更快的速度。ORB在2011年才首次釋出。在前面小節中,我們已經提到了ORB演算法。ORB演算法將基於FAST關鍵點的技術和基於BRIEF描述符的技術相結合,關
第十六節、模組化操作
在ES5中我們要進行模組華操作需要引入第三方類庫,隨著前後端分離,前端的業務日漸複雜,ES6為我們增加了模組話操作。模組化操作主要包括兩個方面。 export :負責進行模組化,也是模組的輸出。 import:負責八模組引入,也是模組的引入操作。 exp
第十五節、韋伯局部描述符(WLB)
times 向量 font .com ima 灰度共生矩陣 領域 局部特征 limit 紋理作為一種重要的視覺線索,是圖像中普遍存在而又難以描述的特征,圖像的紋理特征一般是指圖像上地物重復排列造成的灰度值有規則的分布。紋理特征的關鍵在於紋理特征的提取方法。目前,用於紋理特征
第十五節、韋伯區域性描述符(WLD,附原始碼)
紋理作為一種重要的視覺線索,是影象中普遍存在而又難以描述的特徵,影象的紋理特徵一般是指影象上地物重複排列造成的灰度值有規則的分佈。紋理特徵的關鍵在於紋理特徵的提取方法。目前,用於紋理特徵提取的方法有很多,最具有代表性的是有基於二階概率密度的灰度共生矩陣、符合人眼視覺特性的小波變換、紋理譜法以及基於影象結構基元
第十二節、尺度不變特徵(SIFT)
上一節中,我們介紹了Harris角點檢測。角點在影象旋轉的情況下也可以檢測到,但是如果減小(或者增加)影象的大小,可能會丟失影象的某些部分,甚至導致檢測到的角點發生改變。這樣的損失現象需要一種與影象比例無關的角點檢測方法來解決。尺度不變特徵變換(Scale-Invariant Feature Transfor
學習筆記第十六節課
作業 學習筆記 第十六節課 lvm講解 lvm有很大的便利性,可以方便的擴容和縮容磁盤的空間。(但是也有局限性) 一旦出現問題,磁盤使用lvm,文件系統壞了,數據沒了,恢復數據的時候很麻煩。 做個實驗:創建三個磁盤分區,(這裏要註意下ID 是83,說明他是普通的分區。如果要想使用lvm,就要修改
【php增刪改查實例】第十六節 - 用戶新增
img dialog onsubmit null 允許 array 增刪改查 res UNC 6.1工具欄 <div id="toolbar"> <a href="javascript:openDialog()" class="easyu
第十一節、Harris角點檢測原理
str 物體 per 權重 模式 windows www http 特定 OpenCV可以檢測圖像的主要特征,然後提取這些特征、使其成為圖像描述符,這類似於人的眼睛和大腦。這些圖像特征可作為圖像搜索的數據庫。此外,人們可以利用這些關鍵點將圖像拼接起來,組成一個更大的圖像,比
第十九節、基於傳統影象處理的目標檢測與識別(詞袋模型BOW+SVM附程式碼)
在上一節、我們已經介紹了使用HOG和SVM實現目標檢測和識別,這一節我們將介紹使用詞袋模型BOW和SVM實現目標檢測和識別。 一 詞袋介紹 詞袋模型(Bag-Of-Word)的概念最初不是針對計算機視覺的,但計算機視覺會使用該概念的升級。詞袋最早出現在神經語言程式學(NLP)和資訊檢索(IR)領域,該模型
學習筆記第十六節:第一類,第二類斯特林數和Bell數(坑)
正題 百度:“ 在組合數學,Stirling數可指兩類數,第一類Stirling數和第二類Stirling數,都是由18世紀數學家James Stirling提出的。
第十六節,使用函式封裝庫tf.contrib.layers
這一節,介紹TensorFlow中的一個封裝好的高階庫,裡面有前面講過的很多函式的高階封裝,使用這個高階庫來開發程式將會提高效率。 我們改寫第十三節的程式,卷積函式我們使用tf.contrib.layers.conv2d(),池化函式使用tf.contrib.layers.max_pool2d(
第十六節課:第16,17章,Squid服務和iscsi網路儲存
第十六章 squid總結: 正向代理:yum 安裝後清空防火牆即可正常使用,客戶端設定瀏覽器 透明正向代理:vim /etc/squid/squid.conf &
第十六節20181214
Squid是Linux系統中最為流行的一款高效能代理服務軟體, 通常用作Web網站的前置快取服務,能夠代替使用者向網站 伺服器請求頁面資料並進行快取。 硬碟介面型別主要有IDE、SCSI和SATA這3種 DE是一種成熟穩定、價格便宜的並行傳輸介面。 SATA是一種傳輸速度
Spark修煉之道(進階篇)——Spark入門到精通:第十六節 Spark Streaming與Kafka
作者:周志湖 主要內容 Spark Streaming與Kafka版的WordCount示例(一) Spark Streaming與Kafka版的WordCount示例(二) 1. Spark Streaming與Kafka版本的WordCount示例
Scala入門到精通——第十六節 泛型與註解
本節主要內容 泛型(Generic Type)簡介 註解(Annotation)簡介 註解常用場景 1. 泛型(Generic Type)簡介 泛型用於指定方法或類可以接受任意型別引數,引數在實際使用時才被確定,泛型可以有效地增強程式的適用性,使用
第十二節、css進階:消除未使用的css
相信有很多人都用過Bootstrap這個框架,我們在使用的時候每個頁面只使用了其中一小部分的css樣式,對著專案的推進,css程式碼會越來越多,有些是你自己寫的,有的是你直接使用框架定義好的,到後期進行需求更改的時候我們可能就無暇關注css樣式,造成很多css的冗餘。這節內
Spring入門學習(AOP返回通知&異常通知&環繞通知&切面的優先順序) 第十六節
Spring入門學習(AOP返回通知&異常通知&環繞通知) 返回通知 異常通知 環繞通知 切面的優先順序 返回通知 使用`@AfterReturning`註解,在方法正常結束後執行的通知,它是可以獲得方法的返回