
第十四節、FAST角點檢測(附原始碼)
在前面我們已經陸續介紹了許多特徵檢測運算元,我們可以根據影象區域性的自相關函式求得Harris角點,後面又提到了兩種十分優秀的特徵點以及他們的描述方法SIFT特徵和SURF特徵。SURF特徵是為了提高運算效率對SIFT特徵的一種近似,雖然在有些實驗環境中已經達到了實時,但是我們實踐工程應用中,特徵點的提取與匹配只是整個應用演算法中的一部分,所以我們對於特徵點的提取必須有更高的要求,從這一點來看前面介紹的的那些特徵點方法都不可取。
一 FAST演算法原理
為了解決這個問題,Edward Rosten和Tom Drummond在2006年發表的“Machine learning for high-speed corner detection”文章中提出了一種FAST特徵,並在2010年對這篇論文作了小幅度的修改後重新發表。FAST的全稱為Features From Accelerated Segment Test。
Rosten等人將FAST角點定義為:若某畫素點與其周圍領域內足夠多的畫素點處於不同的區域,則該畫素點可能為角點。也就是某些屬性與眾不同,考慮灰度影象,即若該點的灰度值比其周圍領域內足夠多的畫素點的灰度值大或者小,則該點可能為角點。
二 FAST演算法步驟
- 從圖片中選取一個畫素$P$,下面我們將判斷它是不是一個特徵點。我們首先把它的亮度值設為$I_p$;
- 設定一個合適的閾值$t$;
- 考慮以該畫素點為中心的一個半徑等於3畫素的離散化的Bresenham圓,這個圓的邊界上有16個畫素;

4.現在,如果在這個大小為16個畫素的圓上有$n$個連續的畫素點,他們的畫素值要麼都比$I_p+t$大,要麼都比$I_p-t$小,那麼他就是一個角點。$n$的值可以設定為12或者9,實驗證明選擇9可能會有更好的效果。
上面的演算法中,對於影象中的每一個點,我們都要去遍歷其鄰域圓上的16個點的畫素,效率較低。我們下面提出了一種高效的測試(high-speed test)來快速排除一大部分非角點的畫素。該方法僅僅檢查在位置1,9,5和13四個位置的畫素,首先檢測位置1和位置9,如果它們都比閾值暗或比閾值亮,再檢測位置5和位置13。如果$p$是一個角點,那麼上述四個畫素點中至少有3個應該必須都大於$I_p+t$或者小於$I_p-t$,因為若是一個角點,超過四分之三圓的部分應該滿足判斷條件。如果不滿足,那麼$p$不可能是一個角點。對於所有點做上面這一部分初步的檢測後,符合條件的將成為候選的角點,我們再對候選的角點,做完整的測試,即檢測圓上的所有點。
上面的演算法效率實際上是很高的,但是有點一些缺點:
- 當我們設定$n<12$時就不能使用快速演算法來過濾非角點的點;
- 檢測出來的角點不是最優的,這是因為它的效率取決於問題的排序與角點的分佈;
- 對於角點分析的結果被丟棄了;
- 多個特徵點容易擠在一起。
三 使用機器學習做一個角點分類器
- 首先選取你進行角點提取的應用場景下很多張的測試圖片;
- 使用 FAST 演算法找出每幅影象的特徵點;
- 對每一個特徵點,將其周圍的 16 個畫素儲存構成一個向量。對於步驟二中得到的角點,把他儲存在$P$中;
- 對於影象上的每一個畫素點,它周圍鄰域圓上位置為$x$,$x\in\{1,2,...,16\}$的點表示為$p\to{x}$,可以用下面的判斷公式將該點$p\to{x}$分為三類:$$S_{p\to{x}}=\begin{cases}d,I_{p\to{x}}≤I_p-t \quad(darker)\\ s, I_p-t < I_{p\to{x}}<I_p+t \quad(similar)\\ b, I_p+t≤I_{p\to{x}} \quad(brighter)\end{cases}$$
- 我們任意16個位置中的一個位置$x$,可以把集合$P$分為三個部分$P_d,P_s,P_b$,其中$P_d$的定義如下,$P_s$和$P_b$的定義與其類似:$$P_b=\{p\in{P}:S_{p\to{x}}=b\}$$ 換句話說,對於給定的位置$x$,它都是可以把所有影象中的點分為三類,第一類$P_d$包含了所有位置$x$處的畫素在閾值$t$下暗於中心畫素,$P_b$包含了所有位置$x$處的畫素在閾值$t$亮於中心元素;
- 定義一個新的布林變數$K_p$,如果$p$是一個角點,那些$K_p$為真,否則為假;
- 使用ID3演算法(決策樹分類器)來查詢每一個子集;
- 遞迴計算所有的子集直至$K_p$的熵為0;
- 被建立的決策樹就用於於其他圖片的FAST檢測。
四 非極大值抑制
如何解決從鄰近的位置選取了多個特徵點的問題,我們可以使用Non-Maximal Suppression來解決。
- 為每一個檢測到的特徵點計算它的響應大小(score function)$V$,這裡$V$定義為點$p$和它周圍16個畫素點的絕對偏差之和;
- 考慮兩個相鄰的特徵點,並比較它們的$V$值;
- $V$值較低的點會被刪除。
五 OpenCV庫FAST特徵檢測
# -*- coding: utf-8 -*- """ Created on Mon Aug 27 16:09:48 2018 @author: lenovo """ ''' FAST角點檢測 ''' import cv2 '''1、載入圖片''' img1 = cv2.imread('./image/match1.jpg') img1 = cv2.resize(img1,dsize=(600,400)) image1 = img1.copy() '''2、提取特徵點''' #建立一個FAST物件,傳入閾值t 可以處理RGB色彩空間影象 fast = cv2.FastFeatureDetector_create(threshold=50) keypoints1 = fast.detect(image1,None) #在影象上繪製關鍵點 image1 = cv2.drawKeypoints(image=image1,keypoints = keypoints1,outImage=image1,color=(255,0,255),flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS) #輸出預設引數 print("Threshold: ", fast.getThreshold()) print("nonmaxSuppression: ", fast.getNonmaxSuppression()) print("neighborhood: ", fast.getType()) print("Total Keypoints with nonmaxSuppression: ", len(keypoints1)) #顯示影象 cv2.imshow('fast_keypoints1',image1) cv2.waitKey(20) #關閉非極大值抑制 fast.setNonmaxSuppression(0) keypoints1 = fast.detect(image1,None) print("Total Keypoints without nonmaxSuppression: ", len(keypoints1)) image1 = cv2.drawKeypoints(image=image1,keypoints = keypoints1,outImage=image1,color=(255,0,255),flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS) cv2.imshow('fast_keypoints1 nms',image1) cv2.waitKey(0) cv2.destroyAllWindows()
程式執行效果如下:

可以看到經過非極大值抑制之後,特徵點從2092個降低到了1106個。如果你修改閾值$t$,你會發現$t$越大,檢測到的特徵點越小。
如果你還記得我們之前介紹SIFT特徵和SURF特徵,我們忽略演算法引數的影響,從總體上來看,你會發現FAST的特徵點數量遠遠多於前著。這是受多方面元素影響,一方面是受演算法本身影響,這兩個演算法是完全不同的;另一方面FAST特徵對噪聲比較敏感,從圖片上我們也可以觀察到,比如廣場上許多的的噪聲點。
除了上面我所說的這些,FAST演算法還有以下需要改進的地方:
- 由於FAST演算法依賴於一個閾值$t$,因此演算法還需要人為干涉;
- FAST演算法不產生多尺度特徵而且FAST特徵點沒有方向資訊,這樣就會失去旋轉不變性;
後面我會介紹ORB演算法,ORB將基於FAST關鍵點檢測的技術和基於BRIFE描述符的技術相結合,ORB演算法解決了上面我所講述到的缺點,可以用來替代SIFT和SURF演算法,與兩者相比,ORB擁有更快的速度。
六 自己實現FAST特徵檢測
由於FAST演算法比較簡單,因此我們可以按照我們之前所講述的步驟,自己去實現它,程式碼如下:
# -*- coding: utf-8 -*- """ Created on Mon Aug 27 20:22:51 2018 @author: lenovo """ import numpy as np import cv2 from matplotlib import pyplot as plt ''' 自己實現FAST角點檢測演算法:不依賴OpenCV庫 參考程式碼:https://github.com/tbliu/FAST ''' def rgb2gray(image): ''' 轉換圖片空間RGB->gray args: image:輸入RGB圖片資料 return: 返回灰度圖片 ''' rows,cols = image.shape[:2] grayscale = np.zeros((rows,cols),dtype=np.uint8) for row in range(0,rows): for col in range(0,cols): red,green,blue = image[row][col] gray = int(0.3*red+0.59*green+0.11*blue) grayscale[row][col] = gray return grayscale def bgr2gray(image): ''' 轉換圖片空間BGR->gray args: image:輸入BGR圖片資料 return: 返回灰度圖片 ''' rows,cols = image.shape[:2] grayscale = image.copy()for row in range(0,rows): for col in range(0,cols): blue,green,red = image[row][col] gray = int(0.3*red+0.59*green+0.11*blue) grayscale[row][col] = gray return grayscale def medianBlur(image,ksize=3,): ''' 中值濾波,去除椒鹽噪聲 args: image:輸入圖片資料,要求為灰度圖片 ksize:濾波視窗大小 return: 中值濾波之後的圖片 ''' rows,cols = image.shape[:2] #輸入校驗 half = ksize//2 startSearchRow = half endSearchRow = rows-half-1 startSearchCol = half endSearchCol = cols-half-1 dst = np.zeros((rows,cols),dtype=np.uint8) #中值濾波 for y in range(startSearchRow,endSearchRow): for x in range(startSearchCol,endSearchCol): window = [] for i in range(y-half,y+half+1): for j in range(x-half,x+half+1): window.append(image[i][j]) #取中間值 window = np.sort(window,axis=None) if len(window)%2 == 1: medianValue = window[len(window)//2] else: medianValue = int((window[len(window)//2]+window[len(window)//2+1])/2) dst[y][x] = medianValue return dst def circle(row,col): ''' 對於圖片上一畫素點位置(row,col),獲取其鄰域圓上16個畫素點座標,圓由16個畫素點組成 args: row:行座標 注意row要大於等於3 col:列座標 注意col要大於等於3 ''' if row < 3 or col < 3: return point1 = (row-3, col) point2 = (row-3, col+1) point3 = (row-2, col+2) point4 = (row-1, col+3) point5 = (row, col+3) point6 = (row+1, col+3) point7 = (row+2, col+2) point8 = (row+3, col+1) point9 = (row+3, col) point10 = (row+3, col-1) point11 = (row+2, col-2) point12 = (row+1, col-3) point13 = (row, col-3) point14 = (row-1, col-3) point15 = (row-2, col-2) point16 = (row-3, col-1) return [point1, point2,point3,point4,point5,point6,point7,point8,point9,point10,point11,point12, point13,point14,point15,point16] def is_corner(image,row,col,threshold): ''' 檢測影象位置(row,col)處畫素點是不是角點 如果圓上有12個連續的點滿足閾值條件,那麼它就是一個角點 方法: 如果位置1和9它的畫素值比閾值暗或比閾值亮,則檢測位置5和位置15 如果這些畫素符合標準,請檢查畫素5和13是否相符 如果滿足有3個位置滿足閾值條件,則它是一個角點 重複迴圈函式返回的每個點如果沒有滿足閾值,則不是一個角落 注意:這裡我們簡化了論文章中的角點檢測過程,會造成一些誤差 args: image:輸入圖片資料,要求為灰度圖片 row:行座標 注意row要大於等於3 col:列座標 注意col要大於等於3 threshold:閾值 return : 返回True或者False ''' #校驗 rows,cols = image.shape[:2] if row < 3 or col < 3 : return False if row >= rows-3 or col >= cols-3: return False intensity = int(image[row][col]) ROI = circle(row,col) #獲取位置1,9,5,13的畫素值 row1, col1 = ROI[0] row9, col9 = ROI[8] row5, col5 = ROI[4] row13, col13 = ROI[12] intensity1 = int(image[row1][col1]) intensity9 = int(image[row9][col9]) intensity5 = int(image[row5][col5]) intensity13 = int(image[row13][col13]) #統計上面4個位置中滿足 畫素值 > intensity + threshold點的個數 countMore = 0 #統計上面4個位置中滿足 畫素值 < intensity - threshold點的個數 countLess = 0 if intensity1 - intensity > threshold: countMore += 1 elif intensity1 + threshold < intensity: countLess += 1 if intensity9 - intensity > threshold: countMore += 1 elif intensity9 + threshold < intensity: countLess += 1 if intensity5 - intensity > threshold: countMore += 1 elif intensity5 + threshold < intensity: countLess += 1 if intensity13 - intensity > threshold: countMore += 1 elif intensity13 + threshold < intensity: countLess += 1 return countMore >= 3 or countLess>=3 def areAdjacent(point1, point2): """ 通過尤拉距離來確定兩個點是否相鄰,如果它們在彼此的四個畫素內,則兩個點相鄰 args: point1:畫素點1的位置 point2:畫素點2的位置 return : 返回True或者False """ row1, col1 = point1 row2, col2 = point2 xDist = row1 - row2 yDist = col1 - col2 return (xDist ** 2 + yDist ** 2) ** 0.5 <= 4 def calculateScore(image,point): """ 計算非極大值抑制的分數 為每一個檢測到的特徵點計算它的響應大小,得分V定義為p和它周圍16個畫素點的絕對偏差之和 考慮兩個相鄰的特徵點,並比較它們的V,V值較小的點移除 args: image:輸入圖片資料,要求為灰度圖片 point: 角點座標 """ col, row = point intensity = int(image[row][col]) ROI = circle(row,col) values = [] for p in ROI: values.append(int(image[p])) score = 0 for value in values: score += abs(intensity - value) return score def suppress(image, corners): ''' Performs non-maximal suppression on the list of corners. For adjacent corners, discard the one with the smallest score. Otherwise do nothing Since we iterate through all the pixels in the image in order, any adjacent corner points should be next to each other in the list of all corners Non-maximal suppression throws away adjacent corners which are the same point in real life args: image: is a numpy array of intensity values. NOTE: Image must be grayscale corners : a list of (x,y) tuples where x is the column index,and y is the row index ''' i = 1 #由於相鄰的角點在corners列表中彼此相鄰,所以我們寫成下面形式 while i < len(corners): currPoint = corners[i] prevPoint = corners[i - 1] #判斷兩個角點是否相鄰 if areAdjacent(prevPoint, currPoint): #計算非極大值抑制的分數 currScore = calculateScore(image, currPoint) prevScore = calculateScore(image, prevPoint) #移除較小分數的點 if (currScore > prevScore): del(corners[i - 1]) else: del(corners[i]) else: i += 1 continue return def detect(image, threshold=50,nonMaximalSuppress=True): ''' corners = detect(image, threshold) performs the detection on the image and returns the corners as a list of (x,y) tuples where x is the column index, and y is the row index Nonmaximal suppression is implemented by default. args: image: is a numpy array of intensity values. NOTE: Image must be grayscale threshold:threshold is an int used to filter out non-corners. return: returns the corners as a list of (x,y) tuples where x is the column index, and y is the row index ''' corners = [] rows,cols = image.shape[:2] #中值濾波 image = medianBlur(image,3) cv2.imshow('medianBlur',image) cv2.waitKey(20) #開始搜尋角點 for row in range(rows): for col in range(cols): if is_corner(image, row, col, threshold): corners.append((col, row)) #非極大值抑制 if nonMaximalSuppress: suppress(image, corners) return corners; def test(): image = cv2.imread('./image/match1.jpg') image = cv2.resize(image,dsize=(600,400)) imgray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) corners = detect(imgray) print('檢測到的角點個數為:',len(corners)) for point in corners: cv2.circle(image,point,1,(0,255,0),1) cv2.imshow('FAST',image) cv2.waitKey(0) cv2.destroyAllWindows() if __name__=='__main__': test()
執行之後效果如下:
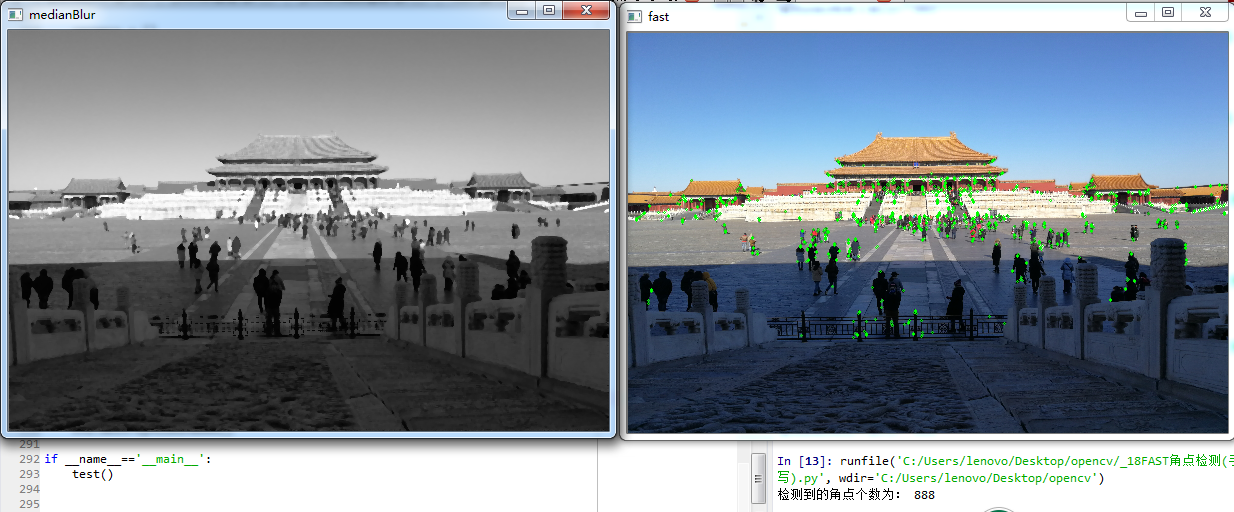
我們在FAST演算法檢測之前使用了中值濾波,為了去除噪聲的影響,你也可以嘗試使用高斯濾波或者均指濾波等濾波手段,這裡就不在介紹,由於我們在實現濾波的時候並沒有對影象邊緣進行填充,因此在圖片四周並不會模糊。
右圖為檢測到的角點,大概有888個畫素點,這是使用了非極大值抑制之後的效果,與我們使用OpenCV庫檢測到的1106個近似相等.
參考文章:
相關推薦
第十四節、FAST角點檢測(附原始碼)
在前面我們已經陸續介紹了許多特徵檢測運算元,我們可以根據影象區域性的自相關函式求得Harris角點,後面又提到了兩種十分優秀的特徵點以及他們的描述方法SIFT特徵和SURF特徵。SURF特徵是為了提高運算效率對SIFT特徵的一種近似,雖然在有些實驗環境中已經達到了實時,但是我們實踐工程應用中,特徵點的提取與匹
第十一節、Harris角點檢測原理
str 物體 per 權重 模式 windows www http 特定 OpenCV可以檢測圖像的主要特征,然後提取這些特征、使其成為圖像描述符,這類似於人的眼睛和大腦。這些圖像特征可作為圖像搜索的數據庫。此外,人們可以利用這些關鍵點將圖像拼接起來,組成一個更大的圖像,比
第十一節、Harris角點檢測原理(附原始碼)
OpenCV可以檢測影象的主要特徵,然後提取這些特徵、使其成為影象描述符,這類似於人的眼睛和大腦。這些影象特徵可作為影象搜尋的資料庫。此外,人們可以利用這些關鍵點將影象拼接起來,組成一個更大的影象,比如將許多影象放在一塊,然後形成一個360度全景影象。 這裡我們將學習使用OpenCV來檢測影象特徵,並利用這些
第十六節、特徵描述符BRIEF(附原始碼)
我們已經知道SIFT演算法採用128維的特徵描述子,由於描述子用的是浮點數,所以它將會佔用512位元組的空間。類似的SUFR演算法,一般採用64維的描述子,它將佔用256位元組的空間。如果一幅影象中有1000個特徵點,那麼SIFT或SURF特徵描述子將佔用大量的記憶體空間,對於那些資源緊張的應用,尤其是嵌入式
Spark修煉之道(進階篇)——Spark入門到精通:第十四節 Spark Streaming 快取、Checkpoint機制
作者:周志湖 微訊號:zhouzhihubeyond 主要內容 Spark Stream 快取 Checkpoint 案例 1. Spark Stream 快取 通過前面一系列的課程介紹,我們知道DStream是由一系列的RDD構成的,
python學習第十四節(正則)
image all flags 正則 asdf alt afa images lag python2和python3都有兩種字符串類型strbytes re模塊find一類的函數都是精確查找。字符串是模糊匹配 findall(pattern,string,flags) r
HTML學習筆記 cs2D3D展示基礎 第十四節 (原創) 參考使用表
safari 學習筆記 ans com div2 s2d spa har tex <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8">
學習筆記第十四節課
作業 學習 筆記 df命令 df 匯報磁盤的使用情況。 這個命令可以直接執行。 linux的磁盤是不能直接訪問的,必須要有掛載點,才能找到磁盤,進入讀寫數據。 df -h 加了h可以根據磁盤大小適當顯示單位。 帶tmpfs的是臨時的文件系統,在這個掛載點裏寫東西,重啟後也會小時。 shm是
【Android測試】【第十四節】Appium——簡述
ios 選擇 ive boot and tro jar appium tomato 前言 同樣的,這一篇我要介紹的也是一款UI自動化工具,地址:http://appium.io/ 第三方(非谷歌)研發的開源測試工具,說到這裏也許有人會問 “為什麽已經介紹了Ui
第十五節、韋伯局部描述符(WLB)
times 向量 font .com ima 灰度共生矩陣 領域 局部特征 limit 紋理作為一種重要的視覺線索,是圖像中普遍存在而又難以描述的特征,圖像的紋理特征一般是指圖像上地物重復排列造成的灰度值有規則的分布。紋理特征的關鍵在於紋理特征的提取方法。目前,用於紋理特征
第十九節、基於傳統影象處理的目標檢測與識別(詞袋模型BOW+SVM附程式碼)
在上一節、我們已經介紹了使用HOG和SVM實現目標檢測和識別,這一節我們將介紹使用詞袋模型BOW和SVM實現目標檢測和識別。 一 詞袋介紹 詞袋模型(Bag-Of-Word)的概念最初不是針對計算機視覺的,但計算機視覺會使用該概念的升級。詞袋最早出現在神經語言程式學(NLP)和資訊檢索(IR)領域,該模型
第十四節----Redis學習總結
14.1 Redis到底是什麼? 在上一小節中學習瞭如何在Java中使用Redis。在Java中使用Redis,只要使用Redis提供的JeRis介面即可。 撥雲見日
第十四節課:第13章,部署DNS域名解析服務(bind服務)
(借鑑請改動) 第十二章收尾 12.2、nfs網路檔案系統 RHEL7預設安裝了nfs,配置檔案在 /etc/export 寫入格式:共享目錄 允許的客戶
2018.12.8第十四節課
主伺服器:在特定區域內具有唯一性,負責維護該區域內的域名與IP地址之間的對應關係。 從伺服器:從主伺服器中獲得域名與IP地址的對應關係並進行維護,以防主伺服器宕機等情況。 快取伺服器:通過向其他域名解析伺服器查詢獲得域名與IP地址的對應關係,並將經常查詢的域名資訊儲存到伺服器本地,以此
Scala入門到精通——第十四節 Case Class與模式匹配(一)
本節主要內容 模式匹配入門 Case Class簡介 Case Class進階 1. 模式匹配入門 在java語言中存在switch語句,例如: //下面的程式碼演示了java中switch語句的使用 public class SwitchDem
第十二節、css進階:消除未使用的css
相信有很多人都用過Bootstrap這個框架,我們在使用的時候每個頁面只使用了其中一小部分的css樣式,對著專案的推進,css程式碼會越來越多,有些是你自己寫的,有的是你直接使用框架定義好的,到後期進行需求更改的時候我們可能就無暇關注css樣式,造成很多css的冗餘。這節內
第十四章、Linux 賬號管理與 ACL 許可權配置
要如何在 Linux 的系統新增一個使用者啊?呵呵~真是太簡單了~我們登陸系統時會輸入 (1)賬號與 (2)口令, 所以建立一個可用的賬號同樣的也需要這兩個資料。那賬號可以使用 useradd 來新建使用者,口令的給予則使用 passwd 這個命令!這兩個命令下達方法如下: us
Spring入門學習(AOP) 第十四節
Spring入門學習(AOP) 為什麼需要AOP 一種方法是使用動態代理解決 使用Spring AOP AOP簡介 AOP術語 為什麼需要AOP 新建一個介面Ari
【Nginx】第十四節 反向代理跟正向代理區別
author:咔咔 wechat:fangkangfk 下面我們需要配置正向代理跟反向代理,所以在這之前先的瞭解一下反向代理跟正向代理的區別 正向代理: 正向代理(forward proxy) ,一個位於客戶端和原始伺服器之間的伺服器,為了從原
ABP module-zero +AdminLTE+Bootstrap Table+jQuery許可權管理系統第十四節--後臺工作者HangFire與ABP框架Abp.Hangfire及擴充套件
HangFire與Quartz.NET相比主要是HangFire的內建提供整合化的控制檯,方便後臺檢視及監控,對於大家來說,比較方便。 HangFire是什麼 Hangfire是一個開源框架(.NET任務排程框架),可以幫助您建立,處理和管理您的後臺作業,處理你不希望放入請求處理管道的操作: 通知/通訊;