
斯坦福CS231n作業程式碼(漢化)Assignment 2 Q1
一段關於神經網路的故事
編寫:土豆 MoreZheng SlyneD
校對:碧海聽滔 Molly
總校對與稽核:寒小陽
To-Do:
[x] 統一所有的數學符號和程式碼符號
[x] 統一所有的術語名稱
[x] 術語的英文詞彙對應
[x] 線性模型的名字是?perceptron?
[x] 損失函式的計算公式和符號是否嚴格和合適?
[x] denominator layout?
- [ ] BN梯度的證明
- [x] bn_param[‘running_mean’] = running_mean
bn_param[‘running_var’] = running_var
(我是盜圖大仙,所有圖片資源全部來源於網路,若侵權望告知~)
本文是什麼?
本文以CS231n的Assignment2中的Q1-Q3部分程式碼作為例子,目標是由淺入深得搞清楚神經網路,同時以圖片分類識別任務作為我們一步一步構建神經網路的目標。
本文既適合僅看得懂一點Python程式碼、懂得矩陣的基本運算、聽說過神經網路演算法這個詞的朋友,也適合準備學習和正在完成CS231n課程作業的朋友。
本文內容涉及:很細節的Python程式碼解析 + 神經網路中矩陣運算的影象化解釋 + 模組化Python程式碼的流程圖解析
本文是從Python程式設計程式碼的實現角度理解,一層一層撥開神經網路的面紗,以搞清楚資料在其中究竟是怎麼運動和處理的。希望可以為小白,尤其是為正在學習CS231n課程的朋友,提供一個既淺顯又快捷的觀點,用最直接的方式弄清楚並構建一個神經網路出來。所以,此文不適合章節跳躍式閱讀。
本文不是什麼?
不涉及艱深的演算法原理,忽略絕大多數數學細節,也儘量不扯任何生澀的專業術語,也不會對演算法和優化處理技術做任何橫向對比。
CS231n課程講師Andrej Karpathy在他的部落格上寫過一篇文章Hacker’s guide to Neural Networks,其中的精神是我最欣賞的一種教程寫作方式:“My exposition will center around code and physical intuitions instead of mathematical derivations. Basically, I will strive to present the algorithms in a way that I wish I had come across when I was starting out.”
“…everything became much clearer when I started writing code.”
廢話不多說,找個板凳坐好,慢慢聽故事~
待折騰的資料集
俗話說得好:皮褲套棉褲,裡邊有緣故;不是棉褲薄,就是皮褲沒有毛!
我們的神經網路是要用來解決某特定問題的,不是家裡閒置的花瓶擺設,模型的構建都有著它的動機。所以,首先讓我們簡單瞭解下要擺弄的資料集(CIFAR-10),最終的目標是要完成一個圖片樣本資料來源的分類問題。

影象分類資料集:CIFAR-10。
這是一個非常流行的影象分類資料集是CIFAR-10。這個資料集包含了60000張

上圖是圖片樣本資料來源CIFAR-10中訓練集的一部分樣本影象,從中你可以預覽10個標籤類別下的10張隨機圖片。
小結:
在我們的故事中,只需要記得這個訓練集是一堆x來標記。每個圖還配有一個標籤值,總共10個標籤,以後我們都用y來標記。(悄悄告訴你的是:每個畫素點的3個數據維度是有序的,分別對應紅綠藍(RGB))
關於神經網路,你起碼應該知道的!
下圖是將神經網路演算法以神經元的形式繪製的兩個圖例,想必同志們早已見怪不怪了。
但是,你起碼應該知道的是其中各種約定和定義:
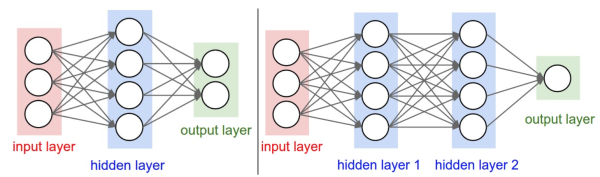
左邊是一個2層神經網路,一個隱藏層(藍色層)有4個神經元(也可稱為單元(unit))組成,輸出層(綠色)由2個神經元組成,輸入層(紅色)是3個”神經元”。右邊是一個3層神經網路,兩個隱藏層,每層分別含4個神經元。注意:層與層之間的神經元是全連線的,但是層內的神經元不連線(如此就是所謂全連線層神經網路)。
這裡有個小坑:輸入層的每個圈圈代表的可不是每一張圖片,其實也不是神經元。應該說整個縱向排列的輸入層包含了一張樣本圖片的所有資訊,也就是說,每個圈圈代表的是某樣本圖片對應位置的畫素數值。可見對於CIFAR-10資料集來說,輸入層的維數就是
在接下來我們的故事中,要從程式碼實現的角度慢慢剖析,先從一個神經元的角度出發,再搞清楚一層神經元們是如何幹活的,然後逐漸的弄清楚一個含有任意神經元個數隱藏層的神經網路究竟是怎麼玩的,在故事的最後將會以CIFAR-10資料集的分類問題為目標一試身手,看看我們構造的神經網路究竟是如何工作運轉的。
所謂的前向傳播
一個神經元的本事
我們先僅前向傳播而言,來談談一個神經元究竟是做了什麼事情。

前向傳播,這名字起的也是神乎其神的,說白了就是將樣本圖片的資料資訊,沿著箭頭正向傳給一個帶引數的神經網路層中咀嚼一番,然後再吐出來一堆資料再餵給後面的一層吃(如此而已,居然就叫做了前向/正向傳播了,讓人忍不住吐槽一番)。那麼,對於一個全連線層(fully-connected layer) 1
的前向傳播來說,所謂的“帶引數的神經網路層”一般就是指對輸入資料來源(此後用”資料來源”這個詞來表示輸入層所有輸入樣本圖片資料總體)先進行一個矩陣乘法,然後加上偏置,得到數字再運用啟用函式”修飾”,最後再反覆迭代罷了(後文都預設使用此線性模型)。
是不是暈了?彆著急,我們進一步嚼碎了來看看一個神經元(處於第一隱藏層)究竟是如何處理輸入層傳來的一張樣本圖片(帶有貓咪標籤)的?

上面提到過,輸入資料來源是一張尺寸為
顯然,一張圖片中的
不能空口套白狼,一張美圖說明問題:
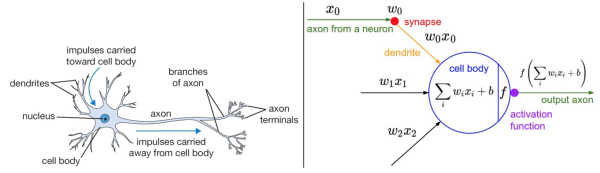
左圖不用看,這個一般是用來裝X用的,並不是真的要嚴格類比。雖然最初的神經網路演算法確實是受生物神經系統的啟發,但是現在早已與之分道揚鑣,成為一個工程問題。關鍵我們是要看右圖的數學模型(嚴格地說,這就是傳說中的感知器perceptron)。
如右圖中的數學模型所示,我們為每一個喂進來的資料
上面的代數表示式看上去很繁雜,不容易推廣,所以我們把它改寫成
上面等式左側這樣算出的一個數字,表示為對於輸入進來的
換句話說,相當於是有一個神經元坐在某選秀的評委席裡,戴著一款度數為
現如今,參加選秀的人可謂趨之若鶩,一個神經元評委該如何同時的批量化打分,提高效率嗯?
也就是說,一個神經元面對
相關推薦
斯坦福CS231n作業程式碼(漢化)Assignment 2 Q1
一段關於神經網路的故事 編寫:土豆 MoreZheng SlyneD 校對:碧海聽滔 Molly 總校對與稽核:寒小陽 To-Do: [x] 統一所有的數學符號和程式碼符號 [x] 統一所有的術語名稱 [x] 術語
斯坦福CS231n作業程式碼(漢化)Assignment 2 Q4
編寫:土豆 MoreZheng SlyneD 校對:碧海聽滔 Molly 總校對與稽核:寒小陽 本系列由斯坦福大學CS231n課後作業提供 CS231N - Assignment2 - Q4 - ConvNet on CIFAR-10 問
斯坦福CS231n作業程式碼(漢化)Assignment 2 Q5
TensorFlow是個什麼東東? 編寫:土豆 MoreZheng SlyneD 校對:碧海聽滔 Molly 總校對與稽核:寒小陽 在前面的作業中你已經寫了很多程式碼來實現很多的神經網路功能。Dropout, Batch Norm 和 2D卷積
斯坦福CS231n作業程式碼(漢化)Assignment 1
[CS231N - Assignment1 - Q5 - Image features exercises] 編寫:郭承坤 觀自在降魔 Fanli SlyneD 校對:毛麗 總校對與稽核:寒小陽 我們已經看到,通過用輸入影象的畫素訓練的線性分類器對影
【ZedGraph】刪除或重新命名(漢化)右鍵選單
本文結合網路資源,結合自身實踐進行了部分整理和改動,現逐步完善中,內容僅供參考。 網路資源部分轉載自:http://blog.sina.com.cn/main_v5/ria/private.html?uid=1806259402 在zedgraph生成的圖表中,右鍵選單會出
【Mac】資料夾多語言設定(漢化)
當我們使用Mac中文語言的時候,使用終端Terminal看到的資料夾列表和直接在Finder裡面看到的不一樣。經常我們使用一箇中文的資料夾在終端cd選擇的時候切換輸入法會感覺比較噁心。 但是系統預設的幾個資料夾“桌面”,“下載”等在終端看到的卻是英文的 “De
Mondrian 表頭中文顯示(漢化)
Mondrian(V3.5)前臺展示使用了JPivot,而Jpivot的表頭中文顯示有亂碼,改成可顯示中文,見下圖 在對應的XML中, <Dimension name="xxx" foreignKey="xxx" caption="月&am
ionic1使用ImagePicker外掛並且顯示中文(漢化)
在使用ionic開發時,開啟相簿應該是使用比較頻繁的外掛之一。下面講講我在專案中使用(這部分官方比較詳細,就簡單描述)以及解決外掛顯示英文問題1、imagepicker安裝cordova plugin add cordova-plugin-image-picker2、在ion
斯坦福cs231n學習筆記(8)------神經網路訓練細節(資料預處理、權重初始化)
神經網路訓練細節系列筆記: 這一篇,我們將繼續介紹神經網路訓練細節。 一、Data Preprocessing(資料預處理) 如圖是原始資料,資料矩陣X有三種常見的資料預處理形式,其中我們假定X的大小為[N×D](N是資料的數量,D是它們的維數
為eclipse EE(漢化版) 配置Tomcat服務器
好的 -- 資源 鼠標 image 分享圖片 blog 發的 發現 很多小朋友在初次使用eclipse進行web開發的時候,很是蒙蔽。以前都是文本編輯器寫好,做好目錄結構,往tomcat下一扔,重啟,搞定。 如今用上eclipse了,反而不適應了。 這篇文章就來帶
CS231N作業記錄(持續更新中)
ssi net tail 安裝ipython ipy 工作 href https 準備 參考資料:《 cs231n 課程作業 Assignment 1 》https://blog.csdn.net/zhangxb35/article/details/55223825 一
斯坦福CS231n專案實戰(一):k最近鄰(kNN)分類演算法
k最近鄰分類(kNN,K Nearest neighbor)分類演算法是一種最簡單的分類器之一。在kNN演算法訓練過程中,它將所有訓練樣本的輸入和輸出label都儲存起來。測試過程中,計算測試樣本與每個訓練樣本的L1或L2距離,選取與測試樣本距離最近的前k個
斯坦福cs231n學習筆記(11)------神經網路訓練細節(梯度下降演算法大總結/SGD/Momentum/AdaGrad/RMSProp/Adam/牛頓法)
神經網路訓練細節系列筆記: 通過學習,我們知道,因為訓練神經網路有個過程: <1>Sample 獲得一批資料; <2>Forward 通過計算圖前向傳播,獲得loss; <3>Backprop 反向傳播計算梯度,這
windows下配置webstorm(漢化及破解)
WebStorm是一款強大的HTML5/JavaScript Web前端開發工具,被廣大JS開發者譽為“Web前端開發神器”。WebStorm 8全新特性中包括對AngularJS的支援,能夠高效準確地
Python環境搭建(win)——Pycharm(破解+漢化)
Pycharm搭建方法(破解+漢化): 本文以pycharm2019.2為例 寫在前面:有能力的朋友,希望大家支援正版。 IDE是整合開發環境 “Integrated Development Environment” 的縮寫。Python的IDE有很多,除了官方自帶的IDLE,網上推薦的還有Eclipse+P
集美大學網絡1413第九次作業成績(團隊五) -- 測試與發布(Alpha版本)
ima worker str ges 運行 .cn png www text NO.NE團隊的項目鏈接有效,六個核桃和六指神功團隊可以請教下他們,避免因IP地址無效或者因tomcat不打開就不能訪問的情況,畢竟助教沒辦法知道此時此刻它是開著還是關閉啊啊啊。。。 題目 團隊作
個人作業3-(Alpha階段)
命令行工具 叠代 big 價值 管理工具 導致 自動化測試 並行 中間 201421123108 王坤彬 網絡1414 一、 總結自己的alpha 過程 1.團隊的整體情況 Alpha階段我們團隊項目進行的很順利,這跟隊長合理的計劃和安排以及我們每位成員的積極配合是分不開
UVA 221 城市化地圖(離散化)
span uva 部分 精度 spa 最大的 分析 重疊 pan 題意: 分析: 記錄一個一開始就想錯的觀點, 以為只要把x 和 width放大到到足夠大(例如10000倍,倍數越高精度越高),然後排序填充一下數軸就可以,就可以解決x坐標是小數的問題。但這樣打了一下,發
團隊作業4(Alpha版本)
round images cells 路徑 第一次 pan logs 音樂 記錄 項目名稱:音樂播放器 項目成員: 張慧敏(201421122032) 蘇曉薇(201421031033)
對Java Serializable(序列化)的理解和總結
編碼 多種方法 light 定制 http 學習 功能 垃圾回收 對象序列化保存 1、序列化是幹什麽的? 簡單說就是為了保存在內存中的各種對象的狀態(也就是實例變量,不是方法),並且可以把保存的對象狀態再讀出來。雖然你可以用你自己的各種各樣的方法來保存objec