
語義分割 TensorFlow
如何用TensorFlow和TF-Slim實現影象分類與分割
2017年04月08日 11:29:56
閱讀數:1282
本文將介紹如何用近日釋出的TF-Slim工具包和預訓練的模型來完成影象分類和影象分割。
引言
筆者將和大家分享一個結合了TensorFlow和最近釋出的slim庫的小應用,來實現影象分類、影象標註以及影象分割的任務,圍繞著slim展開,包括其理論知識和應用場景。
之前自己嘗試過許多其它的庫,比如Caffe、Matconvnet、Theano和Torch等。它們各有優劣,而我想要一個可靠靈活的、自帶預訓練模型的Python庫。最近,新推出了一款名叫slim的庫,slim自帶了許多預訓練的模型,比如ResNet、VGG、Inception-ResNet-v2(
下文中會用到Tensorflow和卷積神經網路的知識。Tensorflow的網站上有兩者的完美教程,不瞭解的讀者可以前去閱讀。
我是用jupyter notebook完成的寫作。因此,每一段程式碼之後都列印了執行結果。讀者們也可以下載完整的notebook。本文中有一部分內容借鑑了此文
安裝
在執行程式碼之前,首先需要安裝Tensorflow。我用的是0.11版本。你可以從github的tensorflow/models程式碼庫克隆程式碼。
git clone https://github.com/tensorflow/models
我還會用到scikit-image和numpy等依賴,把它們都先裝上。在這裡我推薦先下載並安裝Anaconda,然後通過conda install命令安裝其它的python庫。
首先,我們指定tensorflow使用第一塊GPU。否則tensorflow預設會佔用所有可用的記憶體資源。其次,新增克隆下來的程式碼庫路徑,這樣python執行的時候就能找到需要的程式碼。
-
import sys -
import os -
os.environ["CUDA_VISIBLE_DEVICES"] = '0' -
sys.path.append("/home/dpakhom1/workspace/models/slim")
接著,下載VGG-16模型,我們將用它來對影象做分類和分割。也可以選用其它佔用記憶體少的網路模型(比如,AlexNet)。關於模型的詳細內容,請參考此頁面。
-
from datasets import dataset_utils -
import tensorflow as tf -
url = "http://download.tensorflow.org/models/vgg_16_2016_08_28.tar.gz" -
# 指定儲存路徑 -
checkpoints_dir = '/home/dpakhom1/checkpoints' -
if not tf.gfile.Exists(checkpoints_dir): -
tf.gfile.MakeDirs(checkpoints_dir) -
dataset_utils.download_and_uncompress_tarball(url, checkpoints_dir) -
>> Downloading vgg_16_2016_08_28.tar.gz 100.0% -
Successfully downloaded vgg_16_2016_08_28.tar.gz 513324920 bytes.
影象分類
我們剛剛下載的模型可以將影象分成1000類。類別的覆蓋度非常廣。在本文中,我們就用這個預訓練的模型來給圖片分類、標註和分割,對映到這1000個類別。
下面是一個影象分類的例子。影象首先要做預處理,經過縮放和裁剪,輸入的影象尺寸與訓練集的圖片尺寸相同。
-
%matplotlib inline -
from matplotlib import pyplot as plt -
import numpy as np -
import os -
import tensorflow as tf -
import urllib2 -
from datasets import imagenet -
from nets import vgg -
from preprocessing import vgg_preprocessing -
checkpoints_dir = '/home/dpakhom1/checkpoints' -
slim = tf.contrib.slim -
# 網路模型的輸入影象有預設的尺寸 -
# 因此,我們需要先調整輸入圖片的尺寸 -
image_size = vgg.vgg_16.default_image_size -
with tf.Graph().as_default(): -
url = ("https://upload.wikimedia.org/wikipedia/commons/d/d9/" -
"First_Student_IC_school_bus_202076.jpg") -
# 連線網址,下載圖片 -
image_string = urllib2.urlopen(url).read() -
# 將圖片解碼成jpeg格式 -
image = tf.image.decode_jpeg(image_string, channels=3) -
# 對圖片做縮放操作,保持長寬比例不變,裁剪得到圖片中央的區域 -
# 裁剪後的圖片大小等於網路模型的預設尺寸 -
processed_image = vgg_preprocessing.preprocess_image(image, -
image_size, -
image_size, -
is_training=False) -
# 可以批量匯入影象 -
# 第一個維度指定每批圖片的張數 -
# 我們每次只匯入一張圖片 -
processed_images = tf.expand_dims(processed_image, 0) -
# 建立模型,使用預設的arg scope引數 -
# arg_scope是slim library的一個常用引數 -
# 可以設定它指定網路層的引數,比如stride, padding 等等。 -
with slim.arg_scope(vgg.vgg_arg_scope()): -
logits, _ = vgg.vgg_16(processed_images, -
num_classes=1000, -
is_training=False) -
# 我們在輸出層使用softmax函式,使輸出項是概率值 -
probabilities = tf.nn.softmax(logits) -
# 建立一個函式,從checkpoint讀入網路權值 -
init_fn = slim.assign_from_checkpoint_fn( -
os.path.join(checkpoints_dir, 'vgg_16.ckpt'), -
slim.get_model_variables('vgg_16')) -
with tf.Session() as sess: -
# 載入權值 -
init_fn(sess) -
# 圖片經過縮放和裁剪,最終以numpy矩陣的格式傳入網路模型 -
np_image, network_input, probabilities = sess.run([image, -
processed_image, -
probabilities]) -
probabilities = probabilities[0, 0:] -
sorted_inds = [i[0] for i in sorted(enumerate(-probabilities), -
key=lambda x:x[1])] -
# 顯示下載的圖片 -
plt.figure() -
plt.imshow(np_image.astype(np.uint8)) -
plt.suptitle("Downloaded image", fontsize=14, fontweight='bold') -
plt.axis('off') -
plt.show() -
# 顯示最終傳入網路模型的圖片 -
# 影象的畫素值做了[-1, 1]的歸一化 -
# to show the image. -
plt.imshow( network_input / (network_input.max() - network_input.min()) ) -
plt.suptitle("Resized, Cropped and Mean-Centered input to network", -
fontsize=14, fontweight='bold') -
plt.axis('off') -
plt.show() -
names = imagenet.create_readable_names_for_imagenet_labels() -
for i in range(5): -
index = sorted_inds[i] -
# 列印top5的預測類別和相應的概率值。 -
print('Probability %0.2f => [%s]' % (probabilities[index], names[index+1])) -
res = slim.get_model_variables()


-
Probability 1.00 => [school bus] -
Probability 0.00 => [minibus] -
Probability 0.00 => [passenger car, coach, carriage] -
Probability 0.00 => [trolleybus, trolley coach, trackless trolley] -
Probability 0.00 => [cab, hack, taxi, taxicab]
圖片標註和分割
從上面的例子中可以看到,網路模型只處理了原始影象中的一部分割槽域。這種方式只適用於單一預測結果的場景。
某些場景下,我們希望從圖片中獲得更多的資訊。舉個例子,我們想知道圖片中出現的所有物體。網路模型就告訴我們圖片中有一輛校車,還有幾輛小汽車和幾幢建築物。這些資訊可以協助我們搭建一個圖片搜尋引擎。以上就是一個圖片標註的簡單應用。
但是,如果我們也想得到物體的空間位置該怎麼辦。網路能告訴我們它在圖片的中央看到一輛校車,在右上角看到幾幢建築物?這樣,我們就可以建立一個更具體的搜尋查詢詞:“我想要找到中間有一輛校車,左上角有幾隻花盆的所有符合要求的圖片”。
某些情況下,我們需要對影象的每個畫素進行分類,也被稱作是影象的分割。想象一下,假如有一個巨大的圖片資料集,需要給人臉打上馬賽克,這樣我們就不必得到所有人的許可之後才能釋出這些照片。例如,谷歌街景都對行人的臉做了模糊化處理。當然,我們只需要對圖片中的人臉進行模糊處理,而不是所有的內容。圖片分割可以幫助我們實現類似的需求。我們可以分割得到屬於人臉的那部分畫素,並只對它們進行模糊處理。
下面將介紹一個簡單的圖片分割例子。我們可以使用現有的卷積神經網路,通過完全卷積的方式進行分割。若想要輸出的分割結果與輸入影象尺寸保持一致,可以增加一個去卷積層。
-
from preprocessing import vgg_preprocessing -
# 載入畫素均值及相關函式 -
from preprocessing.vgg_preprocessing import (_mean_image_subtraction, -
_R_MEAN, _G_MEAN, _B_MEAN) -
# 展現分割結果的函式,以不同的顏色區分各個類別 -
def discrete_matshow(data, labels_names=[], title=""): -
#獲取離散化的色彩表 -
cmap = plt.get_cmap('Paired', np.max(data)-np.min(data)+1) -
mat = plt.matshow(data, -
cmap=cmap, -
vmin = np.min(data)-.5, -
vmax = np.max(data)+.5) -
#在色彩表的整數刻度做記號 -
cax = plt.colorbar(mat, -
ticks=np.arange(np.min(data),np.max(data)+1)) -
# 新增類別的名稱 -
if labels_names: -
cax.ax.set_yticklabels(labels_names) -
if title: -
plt.suptitle(title, fontsize=14, fontweight='bold') -
with tf.Graph().as_default(): -
url = ("https://upload.wikimedia.org/wikipedia/commons/d/d9/" -
"First_Student_IC_school_bus_202076.jpg") -
image_string = urllib2.urlopen(url).read() -
image = tf.image.decode_jpeg(image_string, channels=3) -
# 減去均值之前,將畫素值轉為32位浮點 -
image_float = tf.to_float(image, name='ToFloat') -
# 每個畫素減去畫素的均值 -
processed_image = _mean_image_subtraction(image_float, -
[_R_MEAN, _G_MEAN, _B_MEAN]) -
input_image = tf.expand_dims(processed_image, 0) -
with slim.arg_scope(vgg.vgg_arg_scope()): -
# spatial_squeeze選項指定是否啟用全卷積模式 -
logits, _ = vgg.vgg_16(input_image, -
num_classes=1000, -
is_training=False, -
spatial_squeeze=False) -
# 得到每個畫素點在所有1000個類別下的概率值,挑選出每個畫素概率最大的類別 -
# 嚴格說來,這並不是概率值,因為我們沒有呼叫softmax函式 -
# 但效果等同於softmax輸出值最大的類別 -
pred = tf.argmax(logits, dimension=3) -
init_fn = slim.assign_from_checkpoint_fn( -
os.path.join(checkpoints_dir, 'vgg_16.ckpt'), -
slim.get_model_variables('vgg_16')) -
with tf.Session() as sess: -
init_fn(sess) -
segmentation, np_image = sess.run([pred, image]) -
# 去除空的維度 -
segmentation = np.squeeze(segmentation) -
unique_classes, relabeled_image = np.unique(segmentation, -
return_inverse=True) -
segmentation_size = segmentation.shape -
relabeled_image = relabeled_image.reshape(segmentation_size) -
labels_names = [] -
for index, current_class_number in enumerate(unique_classes): -
labels_names.append(str(index) + ' ' + names[current_class_number+1]) -
discrete_matshow(data=relabeled_image, labels_names=labels_names, title="Segmentation")

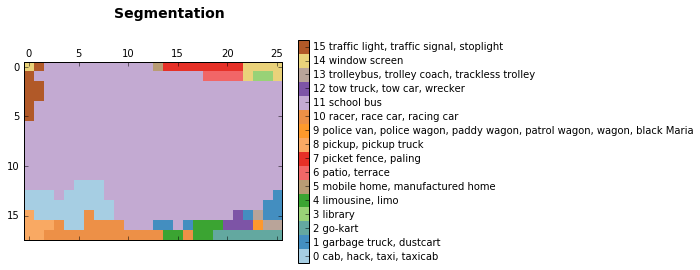
我們得到的結果顯示網路模型確實可以從圖片中找到校車,以及左上角顯示不太清晰的交通標誌。而且,模型可以找到左上角建築物的窗戶,甚至猜測說這是一個圖書館(我們無法判斷是否屬實)。它做出了一些不那麼正確的預測。這些通常是由於網路在預測的時候只能看到當前畫素周圍的一部分影象。網路模型表現出來的這種特性被稱為感受視野。在本文中,我們使用的網路模型的感受視野是404畫素。所以,當網路只能觀察到校車的一部分圖片時,與計程車和皮卡車混淆了。
正如我們在上面所看到的,我們得到了圖片的一個簡單分割結果。它不算很精確,因為最初訓練網路是用來進實現分類任務,而不是影象分割。如果想得到更好的結果,我們還是需要重新訓練一個模型。不管怎麼說,我們得到的結果是可以用作影象標註的。
使用卷積神經網路進行影象分割,可以被看作是對輸入影象的不同部分進行分類。我們將網路聚焦於某個畫素點,進行預測判斷,並輸出該畫素的類別標籤。這樣,我們給分類和分割的結果增加了空間資訊。
小結
本文介紹了用slim庫實現影象的分類和分割,並且簡要闡述了技術原理。
自帶預訓練模型的slim庫是一款強大而靈活的工具,可以配合tensorflow使用。由於最近剛剛釋出,文件不是很完善,有時候甚至要閱讀程式碼來幫助理解。Google正在加快進度完善後續的工作
相關推薦
語義分割 TensorFlow
如何用TensorFlow和TF-Slim實現影象分類與分割 2017年04月08日 11:29:56 閱讀數:1282 本文將介紹如何用近日釋出的TF-Slim工具包和預訓練的模型來完成影象分類和影象分割。 引言 筆者將和大家分享一個結合了TensorFlow和最
TensorFlow之deeplab語義分割API介面除錯
在之前的文章中,對tensorflow目標檢測API進行了詳細的測試,成功應用其模型做簡單的檢測任務。本文對另一模組DeepLab的API進行測試,實現語義分割。 經過了好幾天的吐血折騰,終於將該模組調通,其中的bug真是數不勝數…… 1 檔案結構 首先在research/deepl
【影象語義分割】Semantic Segmentation Suite in TensorFlow---GitHub_Link
Semantic Segmentation Suite in TensorFlow News What's New Added the BiSeNet model from ECCV 2018! Added the Dense Decoder Shor
tensorflow語義分割api使用(deeplab訓練cityscapes)
安裝教程:https://github.com/tensorflow/models/blob/master/research/deeplab/g3doc/installation.md cityscapes訓練:https://github.com/tensorflow/models/blob/ma
Tensorflow實時語義分割開源工程
https://github.com/MSiam/TFSegmentationReal-time Semantic Segmentation Comparative StudyThe repository contains the official TensorFlow co
tensorflow下怎麼解決語義分割交叉熵損失總是nan
本次訓練一個帶有語義分割任務的網路,發現語義分割的交叉熵損失一直是nan,而且是從剛開始迭代就是nan,檢查了網路一直沒發現問題,學習率調小也不起作用,推測是損失函式計算中log傳入了0,考慮到用的啟用函式是tanh,會產生0值,所以考慮將啟用函式換成不帶0的s
基於深度學習的圖像語義分割技術概述之5.1度量標準
-s 公平性 的確 由於 表示 n-2 sub 包含 提升 本文為論文閱讀筆記,不當之處,敬請指正。 A Review on Deep Learning Techniques Applied to Semantic Segmentation:原文鏈接 5.1度量標準 為何需
Pytorch實現的語義分割器
獲取 發生 文件夾 rect OS 取消 方法安裝 tools 問題 使用Detectron預訓練權重輸出 *e2e_mask_rcnn-R-101-FPN_2x* 的示例 從Detectron輸出的相關示例 使用Detectron預訓練權重輸出 *e2e_keypo
語義分割(semantic segmentation) 常用神經網絡介紹對比-FCN SegNet U-net DeconvNet,語義分割,簡單來說就是給定一張圖片,對圖片中的每一個像素點進行分類;目標檢測只有兩類,目標和非目標,就是在一張圖片中找到並用box標註出所有的目標.
avi projects div 般的 ict 中間 接受 img dense from:https://blog.csdn.net/u012931582/article/details/70314859 2017年04月21日 14:54:10 閱讀數:4369
圖像語義分割代碼實現(1)
getcwd classes ner copy imp rec snapshot ini str 谷歌最新語義圖像分割模型 DeepLab-v3+ 現已開源 https://www.oschina.net/news/94257/google-open-sources-pix
一文概覽主要語義分割網路(轉)
文章來源:https://www.tinymind.cn/articles/410 本文來自 CSDN 網站,譯者藍三金 影象的語義分割是將輸入影象中的每個畫素分配一個語義類別,以得到畫素化的密集分類。雖然自 2007 年以來,語義分割/場景解析一直是計算機視覺社群的一部分,但與
處理coco資料集-語義分割
PythonAPI/cocoSegmentationToPngDemo.py函式是用來做語義分割的,參考這裡https://blog.csdn.net/qq_33000225/article/details/78985635?utm_source=blogxgwz2 由於我用的是2017資料
U-NET語義分割方法解讀
2014年,加州大學伯克利分校的Long等人提出的 全卷積網路(FCN) ,推廣了原有的CNN結構, 在不帶有全連線層的情況下能進行密集預測。 這種結構的提出使得分割圖譜可以生成任意大小的影象,且與影象塊分類方法相比,也提高了處理速度。在後來,幾乎所有關於語義
語義分割中資料樣本的整理標註及調色盤程式碼
語義分割中標註的彩色圖如何利用調色盤轉為只包含對應label的灰度圖,其中會有一些繁瑣的地方,下面將自己寫的程式碼分享出來。程式碼主要作用如下圖所示,將標註的彩色圖按照事先定義的調色盤轉成只含label的groundtruth圖片。 程式碼中的關鍵部分在於定義的myquantize函式,如果
【深度學習】Semantic Segmentation 語義分割
翻譯自 A 2017 Guide to Semantic Segmentation with Deep Learning What exactly is semantic segmentation? 對圖片的每個畫素都做分類。 較為重要的語義分割資料集有:VOC2
語義分割,去除邊緣線程式碼
import tensorflow as tf import scipy.misc as msc ''' 對於語義分割的邊緣線,白色的為255,進行去除 ''' def remove_ignore_label(gt ,output=None ,pred=None):
語義分割--PANet和Understanding Convolution for Semantic Segmentation
語義分割 PAN Pyramid Attention Network for Semantic Segmentation FCN作為backbone的結構對小型目標預測不佳,論文認為這存在兩個挑戰。 物體因為多尺度的原因,造成難以分類。針對這個問題,PSPNet和De
深度學習之---語義分割+視訊分割 開原始碼文獻集合
語義分割 Light-Weight RefineNet for Real-Time Semantic Segmentation BMVC 2018 https://github.com/DrSleep/light-weight-refinenet 語義分割 ESPNet: Efficient S
語義分割與目標檢測入門:若干經典工作綜述
語義分割 從原理上來說,語義分割就是畫素級別的分類,傳統的方法也是直接按照這個思路來做的,效率比較低,而從FCN開始,語義分割有了相對比較專用的方法。 0. 重要的資料集:PASCAL VOC和COCO 1. FCN 用於影象(N×M)分類的網路前端用卷積層提取特徵,後端用全連線層進
影象語義分割技術
https://www.leiphone.com/news/201705/YbRHBVIjhqVBP0X5.html 大多數人接觸 “語義” 都是在和文字相關的領域,或語音識別,期望機器能夠識別你發出去的訊息或簡短的語音,然後給予你適當的反饋和回覆。嗯,看到這裡你應該已經猜到了,影象領域也是存