
Week6_Machine Learning System Design課後習題解答
大家好,這篇文章主要和大家討論coursra網站上斯坦福大學機器學習第6周第二部分Machine Learning System Design的課後習題。我將給出習題的大致翻譯和本人的解題思路,其中可能存在錯誤,歡迎大家批評指正!
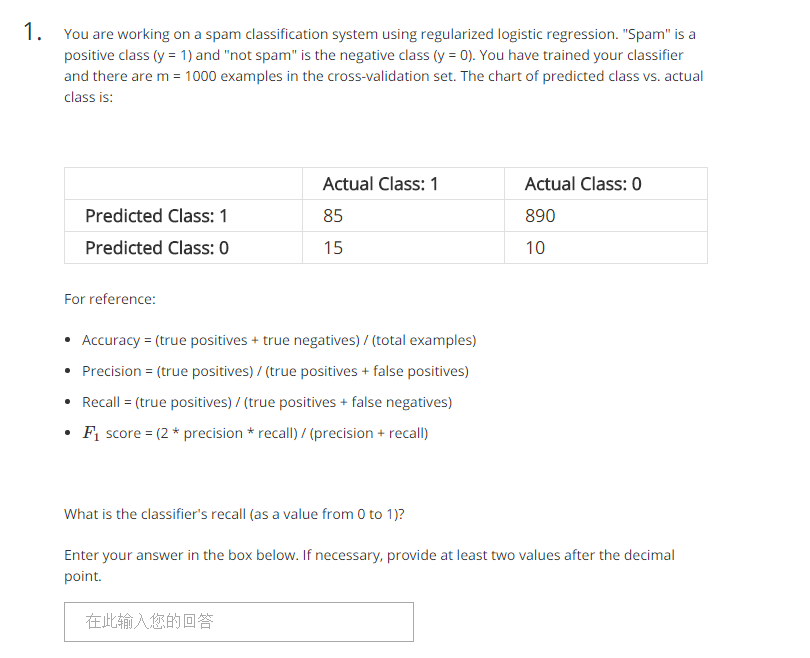
題意:你用正則化邏輯迴歸構造一個垃圾郵件分類器,垃圾郵件y=1這類,非垃圾郵件為y=0這類。你已經訓練好了你的分類器,並且有1000個交叉驗證資料集。預測分類和實際分類的圖示如下。
請問這個分類器的recall(召回率)為多少?將答案填入下面框內,不少於兩位小數。
分析:
| Tables | Actuall 1 | Actuall 0 |
|---|---|---|
| prediction 1 | True possitive | False possitive |
| prediction 0 | False Negative | True Negative |
85對應的是True possitive,890對應的是False possitive,15對應的是False negative,10對應的是True negative.召回率對應第三個公式,帶入計算即可。
答案:recall = 85/(85+15)=0.85. 注意,不同學生計算的內容可能不同,看清計算recalll,accuracy,prediction,F1 score.

題意:假設有大量的資料集可以用於訓練機器學習演算法。當下列選項中有的兩個為真時,利用大量的資料訓練有良好的效果。請問是哪兩個?
1.當我們想要利用高次多項式作為特徵,如x1^2,x1x2等
2.資料不是偏斜類
3.我們學習演算法可以相當複雜(比如利用很多引數訓練神經網路和其他一些演算法)
4.當給定特徵x時,專家可以確定的預測y。即x提供了足夠的特徵,我們特定方法可以準確的預測y。
分析:因為有大量的訓練資料,所以不會出現過擬合(或稱為高方差high variance)問題,所以我們要解決欠擬合(或成為高偏差high bias)問題。
答案:3,4

題意:假設你訓練了一個邏輯迴歸分類器,他的輸出是h(x)。目前,當h(x)大於threshold,預測為1;當h(x)小於threshold,預測為0,目前的threshold定為0.5。假設你增加threshold到0.9,下面哪些是正確的?
1.分類器的查準率和召回率不變,因此F1 score不變
2.分類器有更高查準率
3.分類器有更高召回率
4.分類器查準率和召回率不變,但是準確率更高了
分析:threshold提升到0.9,即你在非常確定的情況下才把它歸為y=1,查準率自然提升了,召回率降低了。
答案:2
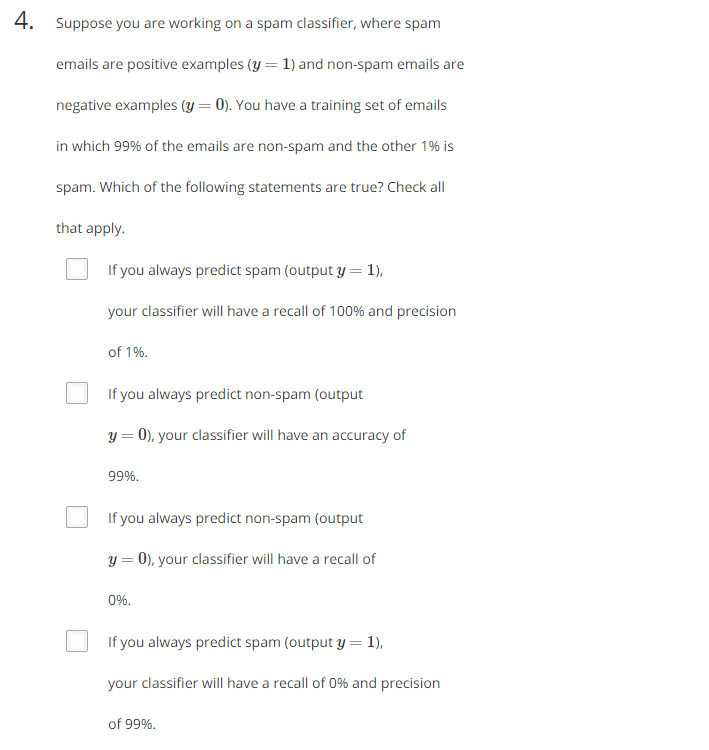
題意:假設你在建立一個垃圾郵件分類器,垃圾郵件被歸為y=1類,非垃圾郵件被歸為y=0類。用於訓練的郵件99%是非垃圾郵件,1%是垃圾郵件。下面哪些陳述時正確的。
1.如果你總是預測輸入為垃圾郵件,分類器的recall為100%,prediction為1%
2.如果總預測輸入為非垃圾郵件,則正確率為99%
3.如果總預測輸入為非垃圾郵件,recall為0%
4.如果總是預測輸入為垃圾郵件,recall為0%,prediction=99%
分析:predicetion,recall,accurary,F1 score的計算公式在第一題中已經給出。假設總共有m封郵件。
1.總是預測輸入為垃圾郵件,則Ture possitive為1%m,false possitive 為99%m,false negative 為0,Ture negative為0。所以prediction=1%,recall=99%,選。
2.上面四個量分別為:0,0,1%m,99%m,正確率=99%,選。
3.上面四個量分別為:0,0,1%m,99%m,recall=0,選。
4.上面四個量分別為:1%m,99%m,0,0,recall = 100%,prediction=1%,不選。
答案:1,2,3
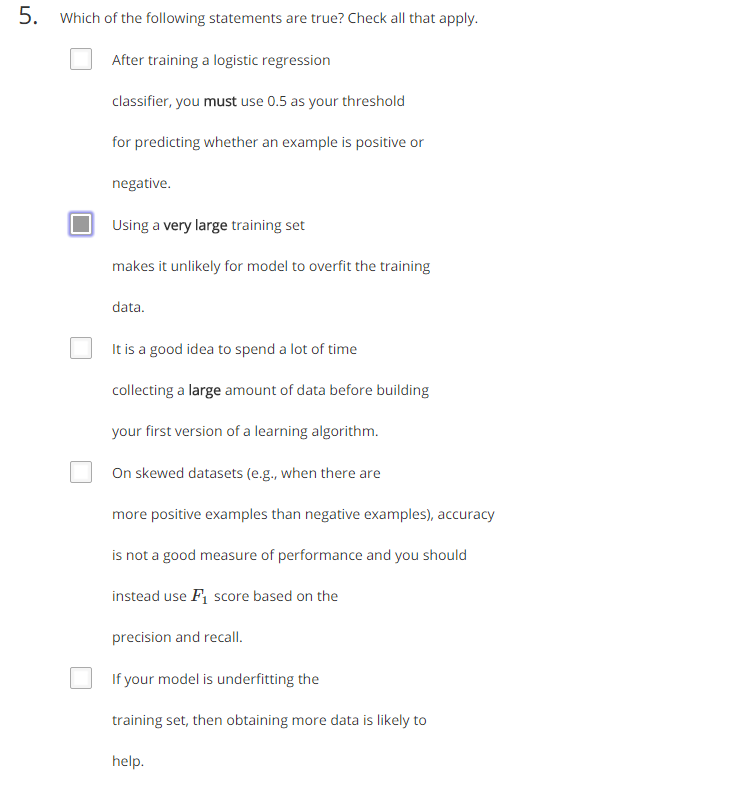
題意:選出下列陳述所有正確的。
1.當訓練了一個邏輯迴歸分了,必須以0.5為分類器的臨界值。
2.用大量的資料讓模型不太容易產生過擬合問題。
3.在機器學習演算法建立之初就花大量時間蒐集大量資料是一個好方法。
4.對於偏斜類,正確率不是衡量模型好壞的好標準,應該用基於prediction和recall的F1 score衡量。
5.如果模型對訓練樣本欠擬合,新增更多的資料對模型有幫助。
分析:1.錯誤,可以根據實際情況修改theshold的值,不選
2.正確,資料量大不容易產生過擬合,從learning curves曲線也可看出
3.錯誤,模型建立之初需要儘快建立模型,分析資料確定改進方法。
4.正確
5.錯誤,增加訓練樣本數可以幫助解決overfitting,不是unfderfitting.
答案:2,4

相關推薦
Week6_Machine Learning System Design課後習題解答
大家好,這篇文章主要和大家討論coursra網站上斯坦福大學機器學習第6周第二部分Machine Learning System Design的課後習題。我將給出習題的大致翻譯和本人的解題思路,其中可能存在錯誤,歡迎大家批評指正! 題意:你用正則
機器學習基石(Machine Learning Foundations) 機器學習基石 作業四 課後習題解答
大家好,我是Mac Jiang,今天和大家分享coursera-NTU-機器學習基石(Machine Learning Foundations)-作業四的習題解答。筆者在做這些題目時遇到很多困難,當我在網上尋找答案時卻找不到,而林老師又不提供答案,所以我就想把自己做題
Ng第十一課:機器學習系統的設計(Machine Learning System Design)
未能 計算公式 pos 構建 我們 行動 mic 哪些 指標 11.1 首先要做什麽 11.2 誤差分析 11.3 類偏斜的誤差度量 11.4 查全率和查準率之間的權衡 11.5 機器學習的數據 11.1 首先要做什麽 在接下來的視頻將談到機器
斯坦福大學公開課機器學習:machine learning system design | trading off precision and recall(F score公式的提出:學習算法中如何平衡(取舍)查準率和召回率的數值)
ron 需要 color 不可 關系 machine 同時 機器學習 pos 一般來說,召回率和查準率的關系如下:1、如果需要很高的置信度的話,查準率會很高,相應的召回率很低;2、如果需要避免假陰性的話,召回率會很高,查準率會很低。下圖右邊顯示的是召回率和查準率在一個學習算
斯坦福大學公開課機器學習:machine learning system design | data for machine learning(數據量很大時,學習算法表現比較好的原理)
ali 很多 好的 info 可能 斯坦福大學公開課 數據 div http 下圖為四種不同算法應用在不同大小數據量時的表現,可以看出,隨著數據量的增大,算法的表現趨於接近。即不管多麽糟糕的算法,數據量非常大的時候,算法表現也可以很好。 數據量很大時,學習算法表現比
演算法導論(第三版) 課後習題解答
Perface:開始學習演算法導論,在這裡記錄自己的課後習題答案。希望自己能每天堅持更新一節的習題解答。 目前計劃的學習順序:第3部分資料結構和第5部分高階資料結構的全部內容 希望大家有什麼看不懂的地方可以提出來,我會盡量解答的; 如果有什麼出錯的地方,也希望大家能夠指正出來,萬分感謝! 於此同時,如
網路作業系統第二章課後習題解答
1.Windows Server 2008 中的使用者有哪些型別?系統預設的使用者有哪些? 使用者型別: (1)使用者; (2)InetOrgPerson; (3)聯絡人; (4)預設使用者賬戶。 預設使用者: (1)Administrator; (2)Guest。 2.如何在 W
網路作業系統第一章課後習題解答
1.什麼是網路作業系統?網路作業系統具有哪些基本功能? 答:網路作業系統可以理解為網路使用者與計算機網路之間的介面,它是專門為網路使用者提供操作介面的系統軟體,除了管理計算機的軟體和硬體資源,具備單機作業系統所有的功能外,還具有向網路計算機提供網路通訊
網路作業系統第五章課後習題解答
1.比較說明FAT檔案系統和NTFS檔案系統的特點。 答:FAT檔案系統 檔案分配表(File Allocation Table,FAT)是用來記錄檔案所在位置的表格,它對於硬碟驅動器的使用非常重要,假若檔案分配表丟失,那麼
網路作業系統第四章課後習題解答
1.磁碟的資料結構包括哪些內容? (1)主引導扇區; (2)作業系統引導扇區; (3)檔案分配表; (4)目錄區; (5)資料區。 2.什麼是基本磁碟和動態磁碟? 基本磁碟: 基本磁碟和舊版本Windows作業系統中使用了相同的磁碟結構。在使
作業系統第一章——概論(課後習題解答)
1. 設計現代OS的主要目標是什麼? 2. OS的作用可表現在哪幾個方面? 3. 為什麼說作業系統實現了對計算機資源的抽象? 4. 試說明推動多道批處理系統形成和發展的主要動力是什麼? 5. 何謂離線I/O和聯機I/O 6. 試說明推動分時系統形成和發展的主要動
Coursera-吳恩達-機器學習-第六週-測驗-Machine Learning System Design
說實話,這一次的測驗對我還是有一點難度的,為了刷到100分,刷了7次(哭)。 無奈,第2道和第4道題總是出錯,後來終於找到錯誤的地方,錯誤原因是思維定式,沒有動腦和審題正確。 這兩道題細節會在下面做出講解。 第二題分析:題意問,使用大量的資料,在哪兩種情況時
【原】Coursera—Andrew Ng機器學習—課程筆記 Lecture 11—Machine Learning System Design
Lecture 11—Machine Learning System Design 11.1 垃圾郵件分類 本章中用一個實際例子: 垃圾郵件Spam的分類 來描述機器學習系統設計方法。首先來看兩封郵件,左邊是一封垃圾郵件Spam,右邊是一封非垃圾郵件Non-Spam:垃圾郵件有很多features。如果我
Stanford機器學習筆記-7. Machine Learning System Design
Error analysis: Manually examine the examples (in cross validation set) that your algorithm made errors on. See if you spot any systematic trend in what ty
周志華《機器學習》課後習題解答系列(三):Ch2
本章概要 本章講述了模型評估與選擇(model evaluation and selection)的相關知識: 2.1 經驗誤差與過擬合(empirical error & overfitting) 精度accuracy、訓練誤差(經驗誤差)
周志華《機器學習》課後習題解答系列(一):目錄
對機器學習一直很感興趣,也曾閱讀過李航老師的《統計學習導論》和Springer的《統計學習導論-基於R應用》等相關書籍,但總感覺自己缺乏深入的理解和系統的實踐。最近從實驗室角落覓得南京大學周志華老師《機器學習》一書,隨意翻看之間便被本書內容文筆深深吸引,如獲至寶
周志華《機器學習》課後習題解答系列(六):Ch5.8
SOM神經網路實驗 注:本題程式分別基於Python和Matlab實現(這裡檢視完整程式碼和資料集)。 1 基礎概述 1.1 SOM網路概念 SOM(Self-Organizing Map,自組織對映)網路是一種無監督的競爭型神經
周志華《機器學習》課後習題解答系列(六):Ch5.10
卷積神經網路實驗 - 手寫字元識別 注:本題程實現基於python-theano(這裡檢視完整程式碼和資料集)。 1. 基礎知識回顧 1.1. 核心思想 卷積神經網路(Convolutional Neural Network, C
周志華《機器學習》課後習題解答系列(六):Ch5.5
這裡的程式設計基於Python-PyBrain。Pybrain是一個以神經網路為核心的機器學習包,相關內容可參考神經網路基礎 - PyBrain機器學習包的使用 5.5 BP演算法實現 實驗過程:基於PyBrain分別實現標準
周志華《機器學習》課後習題解答系列(六):Ch5.7
5.7. RBF神經網路實驗 注:本題程式基於Python實現(這裡檢視完整程式碼和資料集)。 1. RBF網路基礎 RBF網路採用RBF(Radial Basis Function函式)作為隱層神經元啟用函式,是一種區域性逼近神經