
論文(3) Focal Loss
Focal Loss
@(目標檢測)
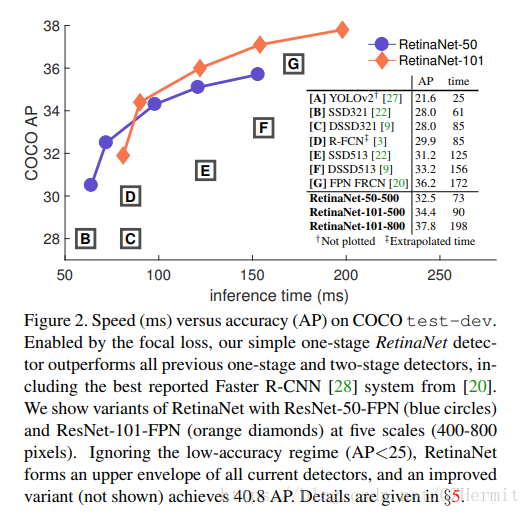
Focal Loss是KaiMing大神提出來的,這篇文章的重點在於分析了one-stage網路的檢測精度為什麼會弱於two-stage的網路。當原理分析出來之後,其實公式的更改就很簡單了。這篇paper也自建了一個網路RetinaNet,在COCO資料集上的檢測效果達到了40%的效果,提升效果非常明顯。
這篇文章提出One-Stage網路檢測精度較於Two-Stage網路差的原因主要是Class Imbalance,類別不均衡。
這個類別不均衡包括了一個數據集裡面,
- 不同類的物體數量差距巨大(比如一個數據集裡面每張圖片車很多人很少);
- 同類物體的圖片裡前景和背景的數量差距巨大(比如一張圖片本身很大,但是裡面只有一個孤零零的小人);
- 樣本與樣本檢測的難易(easy exampling 和 hard example,有些圖片裡面的人可能比較大很好檢測,有些圖片裡的人比較小就難檢測了);
等等,資料集自帶的資料不平衡的弊端,會嚴重影響資料集訓練出來的網路效果。
One-Stage的網路,會對每個圖片預測出成千上萬個備選框 (作者舉例如DPMs,SSD等,但是Yolo好像不是這樣啊。Yolo v1一共預測98個框子,Yolo v2倒是上千了。),備選框多了會導致兩個問題。
1. 負例樣本數遠超正例樣本數會導致網路訓練不到足夠的正例樣本的特徵,這使得訓練沒有什麼效果。
2. 負例樣本數量多,容易學習,會導致訓練方向完全導向學習負例樣本的方向。
這兩個問題很好理解。其實就是負例樣本貢獻的loss太多,會把正例樣本貢獻的loss給淹沒掉,所以模型訓練就跑偏了。
為什麼Two-Stage的網路就不會出這種問題呢?
因為它們在生成預測框的時候,首先控制了數量,其次控制了正負樣例的比例,還有諸如OHEM等方法去控制樣本難易程度等,所以就不會,詳情見RCNN系列。
回到文章,那面對樣本類別不均衡,難易不均衡的問題,應該如何解決呢?
Focal Loss Definition
作者的想法很簡單:既然用的是不平衡的資料集,那麼為什麼要用平衡的loss函式呢?
首先給出公式。
其中,
這個公式有兩個超引數,一個,一個,而被稱為調製因子(modulating factor)。
為了方便起見,解釋這個公式的時候,我們從二分類來舉例。因為多分類裡每一個類都是在二分類。
我們先定義,CE即cross entropy,其中的定義同上。選擇函式的理由顯而易見,首先在[0,1]間單調遞減,其次始終為正值,最後p_t越小,loss大的程度越厲害,就像一個小孩回答問題錯得越離譜,老師不僅打的板子多,每板子的重量還越大。
CE這個loss函式問題在於,很容易分類(即)的樣例在資料集中的數量是不能忽略的,當易分類樣例的數量太多,它們貢獻出來的loss總和會覆蓋掉那些特殊的難分類樣例。
Balanced Cross Entropy
那麼作個平衡?首先考慮一個樣例分類的難易是和這個樣例本身屬於正負樣例相關的。我們前面提到,由於資料集中正負樣例比例相差太大,會導致模型學到後期學的大多是負樣例的特徵,因此區分負樣例會很簡單。所以為了遏制這種正負樣例不均衡的情況,我們考慮增加一個係數,這個係數的計算公式如下,
可以想見,公式裡的肯定是要在[0.5,1]之間的,原因很簡單。我們現在的情況是正樣例被負樣例壓過了,那麼就導致正樣例的值不太高(因為沒學好),負樣例的值很低(因為負樣例的時候,log裡面計算的是)。所以為了抑制住負樣例的loss貢獻,我們給它乘上的係數肯定要比正樣例的loss貢獻所乘上的係數要小。反過來,如果是負樣例被正樣例壓制了,那麼則是在[0,0.5]之間。
Modulating Factor
論文同時指出,光有Balanced Cross Entropy是不夠的,因為這樣只是考慮了正負樣本的均衡,而忽視了樣本本身的難易之分,為了讓模型更好的去學習難樣本而不是選擇忽略難樣本,作者加入了一個稱作調製係數的引數,即。這個係數是依靠一個樣本的分類概率來判定這個樣本分類的難易程度。概率越高,說明這個樣本越容易分類。所以該樣本提供的loss就應該越少。這是一個很直觀的係數。而這個係數能夠起到效果很好,如果概率是0.9,那麼按照作者給的最優係數(),那麼loss會降到原來的1/100,效果還是很好的。
所以最後公式就是,
還要提一點的是,文中給的最優超引數是:,為什麼呢?好奇怪呀?分析原因應該是負樣例由於分類簡單,所以預測概率很低,那麼