
某連鎖酒店洩露資料的分析
宣告
不提供任何下載,不提供任何指引,無需問我怎麼得到,我不會回答。
前言
這個分析純粹是我喜歡資料探勘,週末閒來無事練一下手。
原始檔
原始檔是一個SQL Server資料庫備份檔案,從資料庫“shifenzheng”完整備份,從伺服器GHOSTSLC-6BBFCB備份,備份日期是2013/5/27 0:45:49 備份使用者名稱叫anyi,備份資料庫大小8030071808 (約7.5GB)。
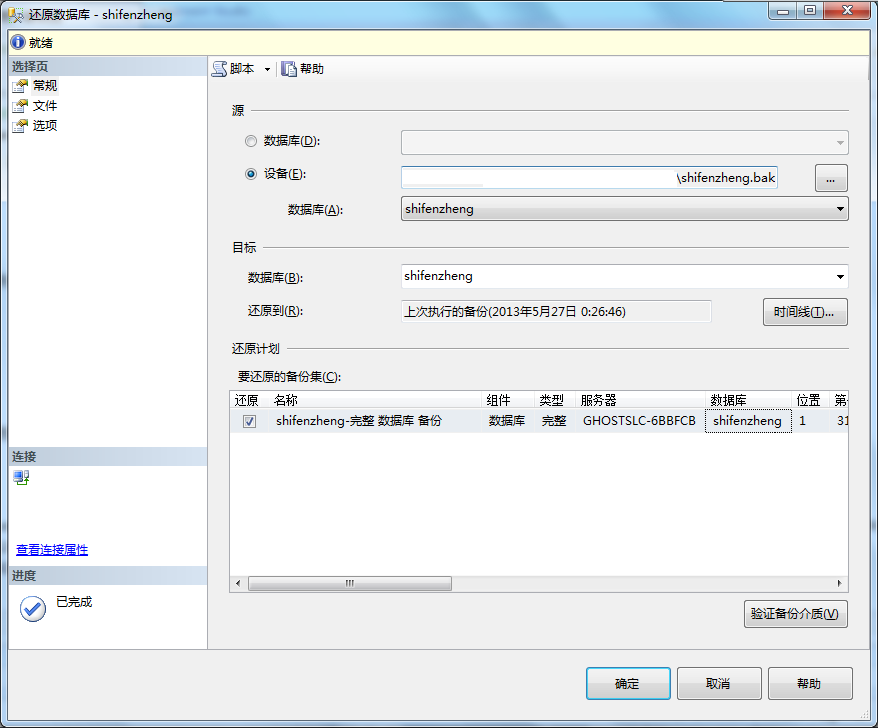
基本資訊
1. 欄位
資料庫只有一個表,叫cdsgus。裡面有姓名、身份證號碼、性別、地址、國家、手機號碼、電子郵件等資料,其它的如卡號、固話、傳真、公司、教育、興趣等基本上是殘缺甚至沒有的,甚至部分人的身份證號碼也是錯亂的,估計匯入的時候沒有處理好。
而每個欄位都設為長度2000的nvarchar,相當蛋痛,相信這不是原始設計,而單純是洩露後自行快速匯入的產物。
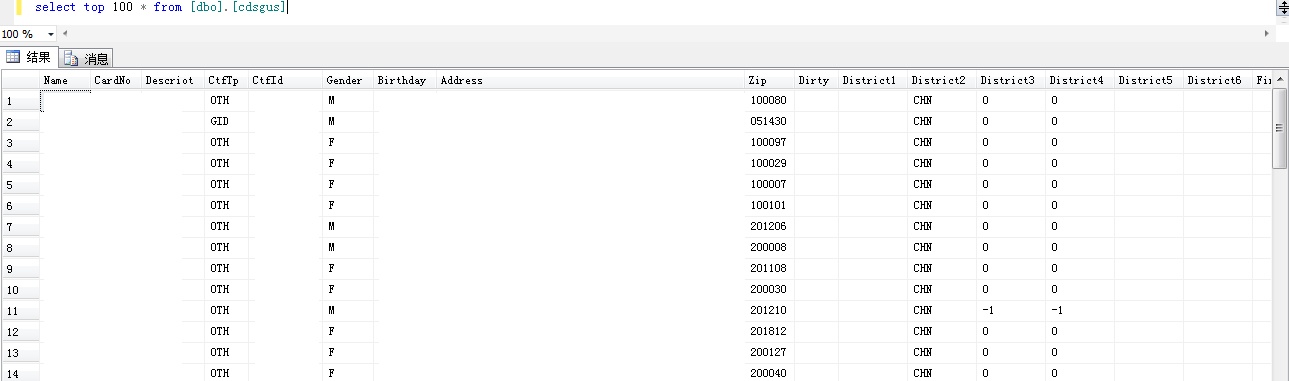
2. 記錄
裡面有20050144條記錄(2005萬)。
3. 姓
取姓名的第一個字元做姓(不考慮複姓),有4644個性,最多是王,其次是張、李、劉、陳,似乎和中國的大姓吻合。有趣的是有人姓“色”、“糊”、“痕”、“&”、“@”、“π”(數學裡面的pi)。。。相信是亂寫的。
10大姓裡面已經佔了821萬用戶。
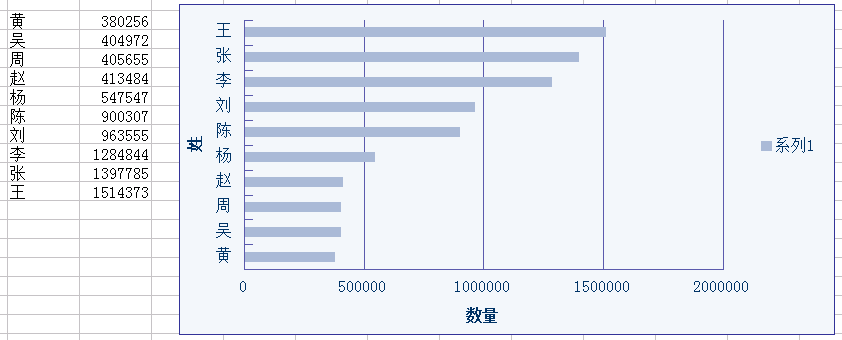
4. 性別
男性比女性多一倍。
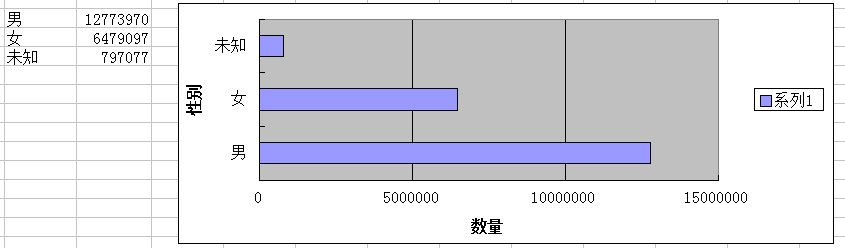
5. 年齡段
剔除那些無效或不靠譜年齡,80後是主力,70後次之。90後只有60後的一半,貌似不科學。。。
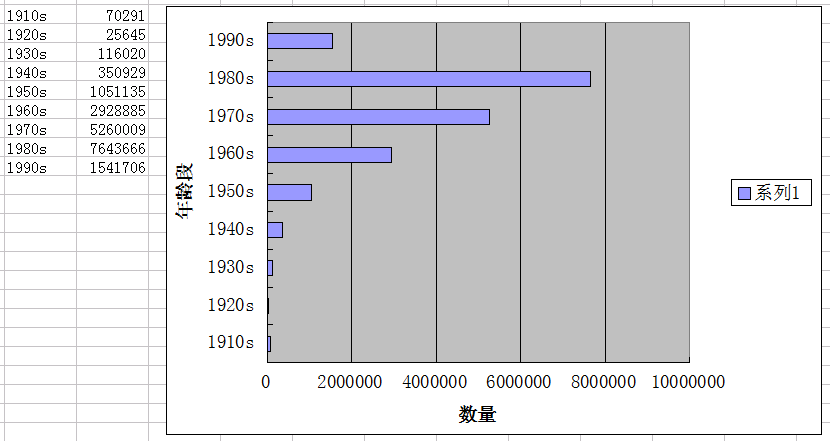
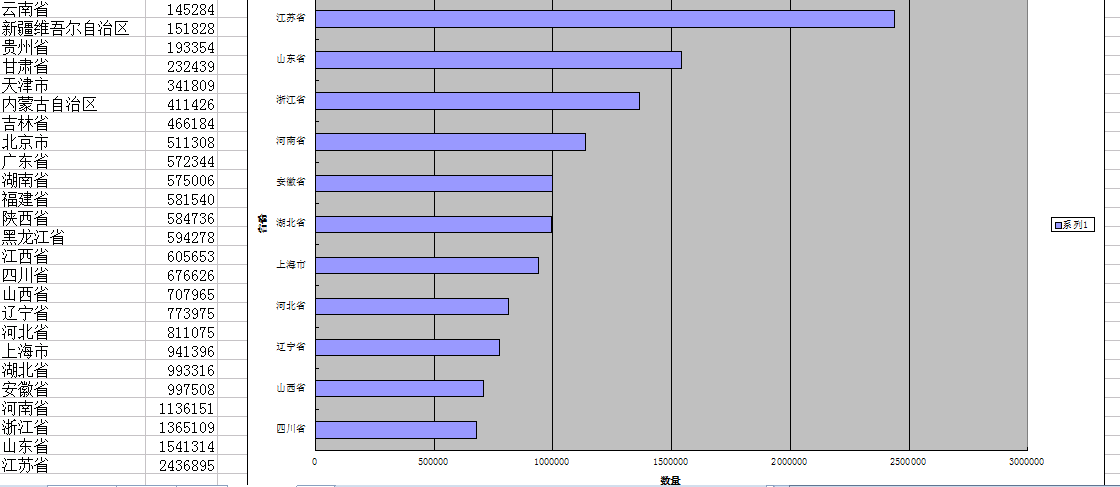
5. 省份
省份資料基於身份證號碼,部分使用者使用的不是身份證號號碼,部分使用者提供了的資料不合法,我都一併剔除了。江蘇、山東和浙江使用者最多,相信是某某連鎖酒店在這些地區網點最多。
6. 更多
其實我還可以分析一下如手機提供商(移動/電信/聯通等)、登記時間的分佈等,甚至多維如不同省份裡的不同年齡段裡的不同手機使用者之類,不過頸椎病發作,強忍疼痛寫了這篇部落格,就此打住了,休息去。
後言
網際網路時代,每天產生的資料越來越多,資料安全問題日益嚴重,譬如之前的CSDN個人資訊洩露,還有幾個大遊戲網站的資料洩露,當然還有諸多沒有公開,只是在某些組織內部流轉的。
我的建議,保護好自己的個人資訊,不要在網上隨意填寫敏感資料,譬如身份證等,儘可能不同服務使用不同密碼並經常修改。電話號碼等,如果非得要填寫,填寫一個備用號碼(專門用來填寫申請/註冊用,可隨便丟棄,不怕別人騷擾)。
相關推薦
某連鎖酒店洩露資料的分析
宣告 不提供任何下載,不提供任何指引,無需問我怎麼得到,我不會回答。 前言 這個分析純粹是我喜歡資料探勘,週末閒來無事練一下手。 原始檔 原始檔是一個SQL Server資料庫備份檔案,從資料庫“shifenzheng”完整備份,從伺服器GHOSTSLC-6BBFCB備份,備份日期是2013
某易52G洩露資料入庫
前段時間下載了網上流傳的 52G葫蘆娃 ,解壓之後,是txt檔案。 網上流傳的52G葫蘆娃 檔案列表 花了點時間,寫了個指令碼把資料入庫。第一次用python
12306洩露資料分析(二)
假裝有人看我的部落格:CSDN部落格要過稽核,稽核時間大概一天左右,看不到這篇就因為我又更新了。 【重要宣告:此次暫未統計香港、澳門、臺灣及南海諸島地區的資料,僅對中國大陸地區的資料進行統計,故在下文中沒有提及以上地區】 注:在原資料集中包含來自香港及其他未
基於某知名招聘網站的上海財務崗位資料分析(含excel視覺化)
1.前言: 之前博主在學習PYTHON的爬蟲,正好有一個很要好的朋友向我詢問上海財務崗位的招聘資訊,便爬取了XX網當時上海財務崗的招聘資訊。 爬蟲採用了PYTHON2.7。其實博主是很看好PYTHON3.4,無奈相關的包並沒有全方面完美支援,網上的教程也面向的是2.7,於是乎
2019最新某象資料分析 資料探勘與分散式爬蟲全套合集
一、配置JanusGraph01、02、03的java環境 mv /usr/bin/java /usr/bin/java.bak 將jdk8上傳至home tar -zxvf ./jdk-8u191-linux-x64.tar.gz -C /usr/local/ vi /etc/profile(
python資料分析與實戰、把dataframe的某一行新增到另一個dataframe
補上昨天沒時間發的一篇文章 最近在學習張良均老師的python資料分析與實戰 昨天在練習用拉格朗日插值法的時候遇到了一個問題,書中程式碼清單4-1中給出的程式碼無法將缺失值所在的行在插值前後展現出來,而是直接將整個data print出來,這樣不利於根據具體
130242014019-(2)-“電商系統某功能模塊”需求分析與設計實驗課小結
img 商品 歷史記錄 模型 需求分析 今天 ges 關鍵字搜索 識別 1)選題討論 今天主要討論的是電商系統中某一個功能模塊的分析,一個電商系統中有很多個功能模塊,如搜索、登錄、購物車等等。我們組選取了其中的最經常使用的搜索功能進行討論。 2)用戶故事討論 1.用戶可
130242014030(2)“電商系統某功能模塊”需求分析與設計實驗課小結
img .com http 二級 電商系統 src 意義 感覺 用戶 這次課老師為了讓我們更加理解敏捷開發,特意請來了王經理給我們介紹。王經理通過讓我們分組,以小組的方式來體驗一下敏捷開發。 分組才用了報數,數字相同的為一組。小組裏沒有明確的分工,大家一起討論,再由
130242014053 (2) “電商系統某功能模塊”需求分析與設計實驗課小結
記錄 關鍵字 軟件 cmm 思想 管理 電商系統 交流 史記 電商系統的搜索功能模塊 一、分組情況 組長:蔡誌峰 組員:樊鎮霄、林夢遠、曾子雲、謝添華,吳幫莉、周陳清、陳敬龍 二、選題討論 經過投票選擇,我們小組決定以電商系統的搜索功能模塊作為我們的選題。
某隊列積壓問題分析、解決
tex 圖片 rim wait uniq timeout mat lock pla 07.29 最高到了115w積壓, 07.30也有持續幾分鐘上萬的走勢 2017.07.29隊列走勢 2017.07.30 隊列走勢 分析 對update_betting_o
「機器學習」Python資料分析之Numpy進階
請點選此處輸入圖片描述 進階 廣播法則(rule) 廣播法則能使通用函式有意義地處理不具有相同形狀的輸入。 廣播第一法則是,如果所有的輸入陣列維度不都相同,一個“1”將被重複地新增在維度較小的陣列上直至所有的陣列擁有一樣的維度。 廣播第二法則確定長度為1的陣列沿著特
「機器學習」Python資料分析之Numpy
請點選此處輸入圖片描述 NumPy的主要物件是同種元素的多維陣列。這是一個所有的元素都是一種型別、通過一個正整數元組索引的元素表格(通常是元素是數字)。在NumPy中維度(dimensions)叫做軸(axes),軸的個數叫做秩(rank)。 例如,在3D空間一個點的座標[1,
網路廣告投放的資料分析,投放應該找誰?
廣告的問題實質是營銷的問題,讓咱們一同共享! 1、網路廣告作用點評方針體系: 網路廣告和傳統媒體廣告蕞大的區別在於:互動性、口碑性和獲韌戶名單, CPC(點選本錢)和CPA(獲客本錢)是點評廣告價效比的重要方針;CPM則一般衡量大尺度廣告的作用;CTR點選率則一般用來衡量廣告的衝擊力和使用者活
App推廣攻略:6種渠道追蹤方法及渠道資料分析的新思路
市場運營:App 渠道追蹤的5種方法以及渠道資料分析的兩大思路,移動網際網路的流量紅利逐漸褪去,數以百萬的 App 正在一個存量市場中搶佔使用者;誰能提高獲客效率,誰就有可能在激烈的競爭中勝。 都在做 App 推廣,為什麼就你的客單價居高不下? 同樣的100塊錢,為何別人花出了500
python資料分析基礎——numpy和matplotlib
numpy庫是python的一個著名的科學計算庫,本文是一個quickstart。 引入:計算BMI BMI = 體重(kg)/身高(m)^2假如有如下幾組體重和身高資料,讓求每組資料的BMI值: weight = [65.4,59.2,63.6,88.4,68.7] heig
【讀書筆記】深入淺出資料分析
目錄 · · · · · · 1 資料分析引言:分解資料 1 2 實驗:檢驗你的理論 37 3 最優化:尋找最大值 75 4 資料圖形化:圖形讓你更精明 111 5 假設檢驗:假設並非如此
資料分析學習筆記part_4
資料分析 Lesson 4 : 統計學 描述性統計學 - 第一部分 資料型別 數值型別 數值資料採用允許我們執行數學運算(例如計算狗的數量)的數值。 分類資料 分類資料用於標記一個群體或一組條目(例如狗的品種 —— 牧羊
資料分析學習筆記part_1
資料分析 Lesson 1 : SQL初探 SQL和移動平均值 SQL簡介 實體關係圖(ERD) 是檢視資料庫中資料的常用方式。下面是我們將用於 Parch & Posey 資料庫的 ERD。包括:1. 表的名稱 2. 每個表中的列 3. 表配合工作的方式。如下圖所
Python資料分析學習路徑圖
本文摘自同行說使用者“風一樣的男子”,原文連結:http://www.yidianzixun.com/n/0CAz84ve?s=1&appid=yidian,如涉及版權問題請及時聯絡小編! Python是一種面向物件、直譯式計算機程式設計語言,由Guido van Rossum於1989
python 將dataframe的某一列離散資料轉換為數值資料
from sklearn import preprocessing def bianma(a, name): type = a.ix[:, name] a[name].fillna('0', inplace=True) le = preprocessing.LabelE