
BP神經網路的自適應步長問題
BP中文名為誤差後向傳播演算法,其是針對前饋神經網路的常用訓練演算法。BP的演算法原理資料很多,這裡就不一一贅述。
一、演算法的思考與改進
BP演算法雖然很強大,但是其收斂速度慢,訓練時間長、容易落入區域性最優值等缺點一直為人詬病。而對於BP演算法的改進方法有如:自適應步長、增加動量項等。
固定步長:
如下對於這是簡單的線性資料擬合,差不到200+次迭代神經網路才收斂:
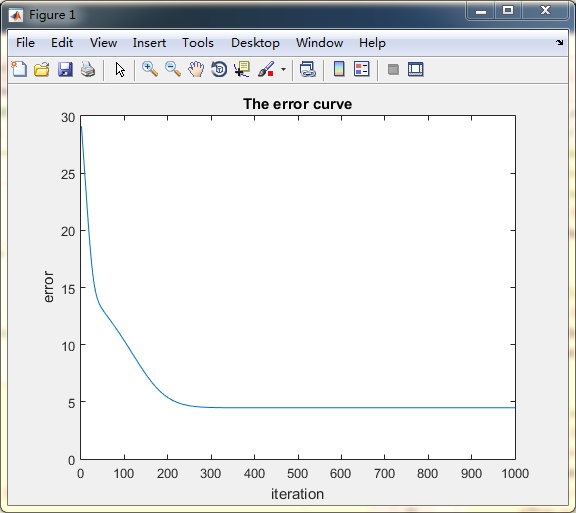
調整策略1:
這個調整策略來自參考文獻[1]的變學習率公式,前期的步長十分大,而後學習率隨著迭代次數增加而線性減小:
stepDist = max_step - ((max_step - min_step) * cntIter / nIter); 其接近20次就基本收斂了:
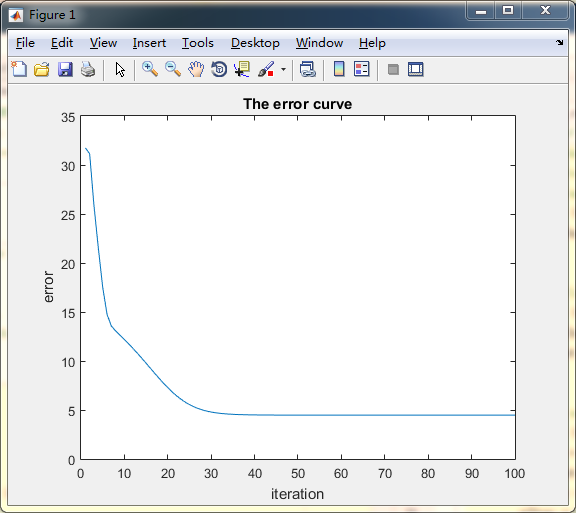
調整策略2:
使用前後兩次的迭代誤差的差值來確定是否增加還是減少學習率,更加差值的大小,確定步長的變化幅度。而且變化的步長使用差值的log函式作為最為單位步長的倍數,使用對數函式能減緩變化的速度,減少網路發散的可能。
這個演算法是我自己想的,雖然能提升收斂速度,但是收斂的過程中單位步長應該更小一些,震盪才不會那麼厲害
sde = 0.01;%%變化的單位步長%
k = err(1) - err(2); %%前後兩次的迭代誤差的差值%
if k > 0.01
stepDist = stepDist - (log(k) + 1 
<未完待續>
相關推薦
BP神經網路的自適應步長問題
BP中文名為誤差後向傳播演算法,其是針對前饋神經網路的常用訓練演算法。BP的演算法原理資料很多,這裡就不一一贅述。 一、演算法的思考與改進 BP演算法雖然很強大,但是其收斂速度慢,訓練時間
BP神經網路基於Tensorflow的實現(程式碼註釋詳細)
BP(back propagation)神經網路是1986年由Rumelhart和McClelland為首的科學家提出的概念,是一種按照誤差逆向傳播演算法訓練的多層前饋神經網路,是目前應用最廣泛的神經網路。 在一般的BP神經網路中,單個樣本有m個輸入和n個輸出,在輸入層
BP神經網路 如何進行權值的初始化
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
遺傳演算法+BP神經網路組合求解非線性函式
用遺傳演算法求解非線性問題是常見的求解演算法之一,求解的過程就是隨機生成解,計算適應度,然後選擇,交叉,變異,更新種群,不斷迭代,這樣,每個個體都會向每代中最佳的個體學習並靠攏,這是區域性最優解;而變異操作是為了在靠近當前最優解的同時還有機會變異出更佳的基因,從而跳出區域性最優解而達到全域性最優解。
BP神經網路說明及推導
學習神經網路,很多基礎知識不用就會忘了,這段時間重新進行一下整理和總結。在此留做記錄。首先從最基礎的BP神經網路開始。並進行相關演算法的推導。 人工神經網路是仿照人大腦的功能而用數學公式搭建的一種結構。現在藉助計算機語言在高效能的計算機上得
神經網路學習(3)————BP神經網路以及python實現
一、BP神經網路結構模型 BP演算法的基本思想是,學習過程由訊號的正向傳播和誤差的反向傳播倆個過程組成,輸入從輸入層輸入,經隱層處理以後,傳向輸出層。如果輸出層的實際輸出和期望輸出不符合
BP神經網路演算法的理解
BP神經網路在百度百科中的解釋就是:BP(back propagation)神經網路是1986年由Rumelhart和McClelland為首的科學家提出的概念,是一種按照誤差逆向傳播演算法訓練的多層前饋神經網路,是目前應用最廣泛的神經網路。大家應該對基本的神經網路模型有一定程度的瞭解,
單隱層BP神經網路C++實現
這幾天抽時間學習了一下很久之前就想學習的BP神經網路。通過閱讀西瓜書的神經網路部分的原理和參考了網上幾篇部落格,我自己用C++編寫、實現了一個單隱層BP神經網路。 簡單畫了個示意圖,好理解下面給出的公式:(注意:圖中省略了其他的節點之間的連
神經網路學習(三)——BP神經網路演算法
前面學習了感知器和自適應線性神經網路。 下面介紹經典的三層神經網路結構,其中每個神經元的啟用函式採用Sigmoid。PS:不同的應用場景,神經網路的結構要有針對性的設計,這裡僅僅是為了推導演算法和計算方便才採用這個簡單的結構。 訓練步驟: 1.正向傳播 2.反向傳播(BP)
Tensorflow實現BP神經網路
Tensorflow實現BP神經網路 摘要:深度學習中基本模型為BP深度神經網路,其包括輸入層、隱含層和輸出層。輸入層的神經元個數取決於資料集屬性特徵的個數,輸出層神經元個數取決於劃分類標的個數。BP神經網路通過梯度下降法不斷調整權重矩陣和偏向進行調參,實現神經網路的訓練。 本人
基於PCA與BP神經網路的人臉識別
基於PCA與BP神經網路的人臉識別 引言 1、PCA演算法 2、PCA原理推導 3、神經網路 4、matlab程式碼 5、C++程式碼 引言 前面的特徵提取部分採用的是PCA,後面的識別分類
BP神經網路 MATLAB源程式
和以前的習慣一樣,只舉典例,然後給程式和執行結果進行說明。 問題背景是: 給定某地區20年的資料,6列,21行,第一列值為年份,第二列為人數,第三列為機動車數量,第四列為公路面積,第五列為公路客運量,第六列為公路貨運量,這20年是1990年到2009年,現在給我們2010和2011年,第二、
BP神經網路&卷積神經網路概念
1、BP神經網路 1.1 神經網路基礎 神經網路的基本組成單元是神經元。神經元的通用模型如圖 1所示,其中常用的啟用函式有閾值函式、sigmoid函式和雙曲正切函式。 圖 1 神經元模型 神經元的輸出為: y=f(∑i=1m
小川學習筆記--BP神經網路JAVA程式碼解析
小川學習筆記–BP神經網路JAVA程式碼解析 闊別有些時日了,今天我就寫一篇最近學習BP神經網路JAVA程式碼的一個筆記,我們大家都知道BP神經網路是在上個世紀進行了兩次熱潮,由於反向傳播的發現從而促進了神經網路的發展。由於筆者在本科期間還未學習過JAVA,因此還在學習階段,對於一些程式
BP神經網路的理解
1.整個執行流程 首先,使用x與w相乘,開始的時候是隨機的給定w的值; 然後,將乘積與偏執b加起來,對於b的理解是就像一元線性迴歸中的常數項,是用來修正值的。 其次,將和帶入啟用函式; 最後,將啟用函式的
BP神經網路演算法的深度解析和工程例項搭建
首先宣告,這篇文章不是神經網路的掃盲文,如果只想知道神經網路的概念那筆者還是推薦找一些深入淺出的文章來看。但是如果需要自己實際搭建和使用一個神經網路,同時具備一定的數學功底的話,那這篇文章就是為了深入的剖析神經網路演算法的工作過程和模型而寫的。這裡筆者把整個神經網路的工作過程
Pytorch 神經網路—自定義資料集上實現
第一步、匯入需要的包 import os import scipy.io as sio import numpy as np import torch import torch.nn as nn import torch.backends.cudnn as cudnn im
keras實現網路流量分類功能的BP神經網路
資料集選用KDD99 資料下載地址:http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html 需求:https://blog.csdn.net/com_stu_zhang/article/details/6987632
BP神經網路——訓練一個加法運算
#include <stdio.h> #include <math.h> #include <time.h> #include <stdlib.h> #define num 3000 #define learn 0.001 double qian
BP神經網路
意義 基本原理 結構圖 啟用函式(σ函式) BP網路輸入輸出關係 BP網路的學習演算法 –思想 – 學習過程 –學習本質 BP演算法實現 意義: 通過比較簡單的概念構建複雜的概念 基本原理: 利用輸出後的誤差來估計輸出層的直接前導層的誤差,再用這個誤差估計更