
高方差與高偏差
阿新 • • 發佈:2019-01-17
1.資料欠擬合會出現高偏差問題,比如資料的趨勢是二次函式,用一次函式取擬合會出現高的偏差。
2.資料過度的擬合會出現高方差問題,比如用10個數據特徵去擬合9個數據會出現高的方差。
3.怎麼處理高偏差和高方差問題:
高偏差:訓練誤差很大,訓練誤差與測試誤差差距小,隨著樣本資料增多,訓練誤差增大。解決方法:
1.尋找更好的特徵(具有代表性的)
2.用更多的特徵(增大輸入向量的維度)
高方差:訓練誤差小,訓練誤差與測試誤差差距大,可以通過增大樣本集合來減小差距。隨著樣本資料增多,測試誤差會減小。解決方案:
1.增大資料集合(使用更多的資料)
2.減少資料特徵(減小資料維度)

圖1
從圖中可以看出當資料出現高方差即過擬合,隨著訓練集合增加,訓練誤差會隨著增加,測試誤差會隨著減小,從圖中可以看出,提供更多的資料可以減少測試誤差與訓練誤差之間的差距。
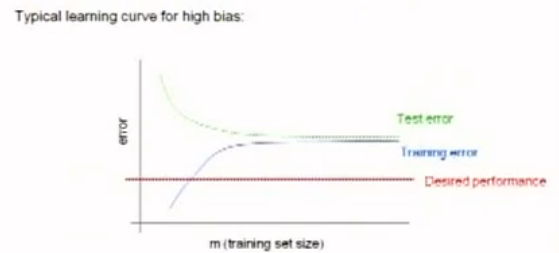
圖2
從圖中2可以看出隨著訓練集合增加,測試誤差會減少,但是減少到某個程度時,測試誤差會持平,訓練誤差會增大。訓練誤差和測試誤差會超過預期的誤差值。
一般採取判斷某函式是高方差還是高偏差,簡單的判斷是看訓練誤差與測試誤差的差距,差距大說明是高方差的,差距小說明是高偏差的。