
高偏差和高方差
首先我來介紹一下高方差和高偏差的概念,可能很多人理解的不是很清楚。
偏差:描述的是預測值和真實值之間的偏差。偏差越大,預測值越偏離真實值。偏差衡量模型的預測能力,物件是一個模型,形容這個模型對真實值的預測能力。
方差:描述的是預測值的變化範圍,離散程度,也就是離其期望值的距離。方差越大,預測結果資料的分佈越散。方差用於衡量預測值之間的關係,和真實值無關。物件是多個模型,表示選取不同的訓練集,得出的模型之間的差異性。
記住:方差和偏差都是衡量模型的,方差表示選取不同的訓練集,訓練出模型的差異有多大,而偏差是指一個模型預測值和真實值之間的偏差。

假設上面打靶圖中的紅點是真實值,每一個藍色的點代表了一個根據不同的訓練集訓練出一個訓練模型的預測資料,
分析上面的四幅圖,左上是低偏差,低方差,因為首先每個模型預測的點都相距很近,所以選取不同的訓練集,預測出他們模型之間的差異比較小,所以每個模型的方差比較低,其次對於每一個的模型,他們預測的值和紅點之間的距離很近,準確率很高,偏差很小,所以他們是低偏差的。右上是低偏差,高方差,因為首先每個模型預測的點都相距很離散,所以選取不同的訓練集,預測出他們模型之間的差異比較大,所以每個模型的方差比較高,其次對於每一個的模型,他們預測的值準確率很高,結果比較集中,偏差比較小,所以他們是低偏差的。左下是高偏差,低方差,因為首先每個模型預測的點都相距很近,所以選取不同的訓練集,預測出他們模型之間的差異比較小,所以每個模型的方差比較小,其次對於每一個的模型,他們預測的值準確率很差,離紅心點比較遠,偏差比較大,所以他們是高偏差的。右下是高偏差,高方差,因為首先每個模型預測的點都相距很離散,所以選取不同的訓練集,預測出他們模型之間的差異比較大,所以每個模型的方差比較大,其次對於每一個的模型,他們預測的值準確率很差,離紅心點比較遠,偏差比較大,所以他們是高偏差的。
再用一個簡單的例子說明一下

左上中選取模型結構y=ax+b,不管選取什麼訓練集,他們預測出的直線的每個引數是差距不大的,所以說是低方差的,但是對於上面紅線這一個引數已知的模型,預測出來的結果和真實的結果差距較大,所以它是高偏差的。右上的是擬合度剛剛合適。右下的模型真實值和預測值之間的偏差平均最小,所以右下的模型偏差很低,但是對於不同的訓練集,他們訓練出的模型引數差距是比較大的,如下圖所示,

所以說,右下的方差比較大。
吳恩達老師(Andrew)在機器學習的課程中講解了偏差和方差,在這兒我總結一下。
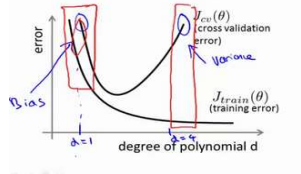
當你的訓練誤差和交叉驗證誤差或測試誤差都很大,且值差不多時,是處於高偏差,低方差,欠擬合狀態,需要增加多項式的次數來解決。
當你的訓練誤差和交叉驗證誤差差距很大,且測試集誤差很小,驗證誤差很大,是處於低偏差,高方差,過擬合狀態,需要減少多項式的次數或者利用正則化來解決。如下圖所示:

利用正則化防止過擬合時,正則化引數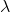

參考文章:https://www.jianshu.com/p/a585d5506b1e
https://blog.csdn.net/u010626937/article/details/74435109