
非比較排序-----計數排序,基數排序。
排序總歸來說可分為兩大類,比較排序與非比較排序。比較排序就是我們常用到的氣泡排序,插入排序,希爾排序,選擇排序,堆排序,快速排序,歸併排序。非比較排序不常用,但是在對一些特殊的情況進行處理時,它的速度反而更快。
1、計數排序
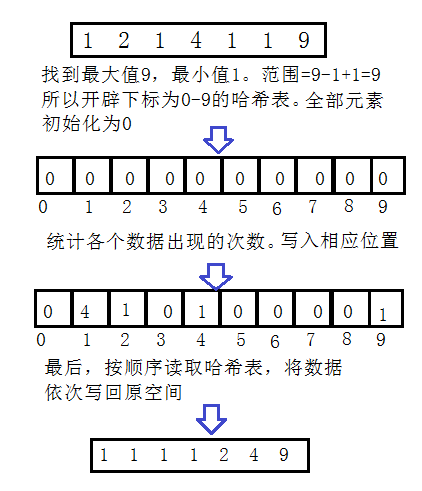
排序原理:利用雜湊的方法,將每個資料出現的次數都統計下來。雜湊表是順序的,所以我們統計完後直接遍歷雜湊表,將資料再重寫回原資料空間就可以完成排序。
注意事項:
①因為要建立雜湊表,計數排序只適用於對資料範圍比較集中的資料集合進行排序。範圍分散情況太浪費空間。如我有100個數,其中前99個都小於100,最後一個數位是10000,我們總不能開闢10000個數據大小的雜湊表來進行排序吧!這樣空間就太浪費了。 此時,就得考慮其他的演算法了。當然,這個例子也可能不恰當,這裡只是想讓你們直觀的理解。
②除了上面那種情況,還有一個問題,例如我有一千個數,1001~2000,此時我的雜湊表該怎麼開闢呢? 開0~2000個?那前面1000個空間就浪費了!直接從1001開始開闢?你想多了!所以這種情況我們就需要遍歷一遍資料,找出最大值與最小值,求出資料範圍。範圍 = 最大值 - 最小值+1。 例如,2000-1001+1 = 1000,這樣我們就開闢0~1000個空間,用1代表1001,1000代表2000。節省了大量的空間。
③肯定有同學想到用點陣圖(BitMap)來做,但是點陣圖(BitMap)有侷限性,它要求每個資料只能出現一次。演算法有些複雜,但是可以嘗試。
時間複雜度分析:綜上所述,我們總需要兩遍遍歷,第一遍統計字資料出現次數,遍歷原資料,複雜度為O(N),第二遍遍歷雜湊表,向原空間寫資料,遍歷了範圍次(range),時間複雜度為O(range),所以總的時間複雜度為O(N+range)。
空間複雜度分析:開闢了範圍(range)大小的輔助雜湊表,所以空間複雜度為O(range)。
下面我對一組資料進行排序做出圖解:
c++程式碼實現:
void CountSort(int *a, int n) { assert(a); int max = a[0]; int min = a[0]; //選出最大數與最小數,確定雜湊表的大小 for (int i = 0; i < n; ++i) { if (a[i] > max) { max = a[i]; } if (a[i] < min) { min = a[i]; } } int range = max - min + 1; int *count = new int[range]; memset(count, 0, sizeof(int)*range);//當初始化成0或-1的時候可以用memset,其他情況均用for迴圈 /*for (int i = 0; i < range; ++i) { count[i] = 0; }*/ for (int i = 0; i < n; ++i) { count[a[i] - min]++; } //將資料重新寫回陣列 int j = 0; for (int i = 0; i < range; ++i) { while ((count[i]--) > 0) { a[j] = i + min; j++; } } }
2、基數排序
基數排序是基於資料位數的一種排序演算法,什麼叫排序位數呢?個,十,百,千,萬...明白了吧!。
它有兩種演算法
①LSD--Least Significant Digit first 從低位(個位)向高位排。
②MSD-- Most Significant Digit first 從高位向低位(個位)排。
排序原理:
因為是按位進行排序,資料可能不統一,有的最大位為十位,有的最大位為百位。我們需要找到最大的位數來進行決定迴圈的次數。
LSD和MSD的兩種演算法思想一致,下面以一組資料用LSD進行排序:
在上圖中最大的位數為4位,所以我們要對個,十,百,千,四位各進行一次迴圈排序。下面以個位為例進行示範。
①我們知道無論個十百千萬哪個位,都只有10種情況,0-9,所以我們先建立一個大小為10 的雜湊表,統計出每個位各有多少資料。例如上圖資料中個位為0的出現1次,個位為1的出現2次,個位為2的出現1次,個位為3的出現2次,個位為9的出現1次。所以雜湊表建立後得:

②再得出次數之後,我們需要開闢一個輔助空間tmp,並按0~9的順序將其重新寫入輔助空間,但是怎麼寫呢?這裡我們就需要用到矩陣轉置的思想了,再開闢一個大小為10 的陣列,用來記錄每個位(0~9)上的資料重新寫入輔助空間時的起始下標。
例如:
0位有1個數據,但是0位之前再其他位,所以0位的起始下標就為0。
1位有2個數據,1位之前有個0位,並且0位有一個數據,所以1位的起始下標為1。
2位有1個數據,2位之前有兩個位(0和1),所以2位之前一共有3個數據,所以2位的起始下標就為3。
由上面刻得出,每個位的起始下標就等於每個位之前的總資料個數之和。
所以得出起始下標陣列為:

③現在起始下標得到了,我們就可以遍歷原陣列往輔助空間裡寫資料了,但是有一點要注意,每寫入一個數據,起始下標陣列相應位的起始下標就要加1。最後得:

到這裡,我們的資料還在輔助空間tmp內,我們需要將其重新寫回我們原資料空間。這樣我們一趟排序就完成了,其他十位,百位,千位的排序只要在低位排序的基礎上進行上面相似的排序即可。
時間複雜度分析:排序最大位數次,每次都要對陣列進行一次排序,所以時間複雜度為O(N*最大位數)。
空間複雜度分析:建立與原陣列同樣大小的輔助空間,再無其他空間開銷,所以空間複雜度為O(N)。
實現程式碼:
//基數排序
//LSD 先以低位排,再以高位排
//MSD 先以高位排,再以低位排
void LSDSort(int *a, int n)
{
assert(a);
//求出其最大位數 個 十 百 千 萬....
int digit = 0;
int bash = a[0];
for (int i = 0; i < n; ++i)
{
while (a[i] > (pow(10,digit)))
{
digit++;
}
}
int flag = 1;
for (int j = 1; j <= digit; ++j)
{
//建立陣列統計每個位出現數據次數
int Digit[10] = { 0 };
for (int i = 0; i < n; ++i)
{
Digit[(a[i] / flag)%10]++;
}
//建立陣列統計起始下標
int BeginIndex[10] = { 0 };
for (int i = 1; i < 10; ++i)
{
BeginIndex[i] = BeginIndex[i - 1] + Digit[i - 1];
}
//建立輔助空間
int *tmp = new int[n];
memset(tmp, 0, sizeof(int)*n);//初始化
//將資料寫入輔助空間
for (int i = 0; i < n; ++i)
{
int index = (a[i] / flag)%10;
tmp[BeginIndex[index]++] = a[i];
}
//將資料重新寫回原空間
for (int i = 0; i < n; ++i)
{
a[i] = tmp[i];
}
flag = flag * 10;
delete[] tmp;
}
}
相關推薦
非比較排序-----計數排序,基數排序。
排序總歸來說可分為兩大類,比較排序與非比較排序。比較排序就是我們常用到的氣泡排序,插入排序,希爾排序,選擇排序,堆排序,快速排序,歸併排序。非比較排序不常用,但是在對一些特殊的情況進行處理時,它的速度反而更快。 1、計數排序 排序原理:利用雜湊的方法,將每個資料出現的
線性排序演算法 --- 計數排序,基數排序,桶排序
計數排序應用: J - Jeronimo's List Gym - 101466J http://codeforces.com/gym/101466/problem/J 線性排序演算法計數排序應該挺好理解的,每次把數字出現的次數記錄下來,然後做成字首,字首就是
排序演算法(計數排序,基數排序,桶排序)
1. 計數排序 思想:對於有限個一定範圍內的整數,我們可以採用遍歷的方式得出每一個數的個數,放入相應的值所對應的下標陣列的位置中,再通過將原陣列從後往前遍歷,並對照與 計數陣列之間的關係,將原陣列資料排好序放入新的陣列中。一般情況下k&
【演算法導論】8.線性時間排序(計數排序,基數排序,桶排序)
三種線性時間複雜度的排序演算法:計數排序,基數排序,桶排序。 8.1排序演算法的下界 給定兩個元素ai和aj,如果使用比較排序,可以有ai<aj,ai<=aj,ai=aj,ai>aj,ai>=aj五種操作來確定其相對次序。本節假設所有的比較採用ai<=aj形
九種經典排序演算法詳解(氣泡排序,插入排序,選擇排序,快速排序,歸併排序,堆排序,計數排序,桶排序,基數排序)
綜述 最近複習了各種排序演算法,記錄了一下學習總結和心得,希望對大家能有所幫助。本文介紹了氣泡排序、插入排序、選擇排序、快速排序、歸併排序、堆排序、計數排序、桶排序、基數排序9種經典的排序演算法。針對每種排序演算法分析了演算法的主要思路,每個演算法都附上了虛擬
計數排序,桶排序,基數排序,
計數排序->桶排序->基數排序,三者的排序思想是相通的,是逐漸複雜,使用性更廣的.(個人理解,歡迎指正,wiki上說基數排序是桶排序的變形,兩者的方法相似,都是分配和收集.百度百科說基數排序又叫bucket sort,基數在這裡個人理解就是基座,如果當前數的要分
桶排序,計數排序,基數排序
桶排序: 要排序的資料有n個,均勻地劃分到m個桶內,每個桶裡就有k=n/m個元素。每個桶內部使用快速排序,時間複雜度為O(k*logk)。m個桶排序的時間複雜度是O(m*k*logk),因為k=n/m,所以整個桶排序的時間複雜度就是O(n*log(n/m))。當桶個數m接近
面試題22——編碼實現堆排,歸併排序,基數排序
堆排(大根堆): void adjust(int*arr,int start,int end) { int tmp=arr[start]; for(int i=2*start+1;i<=end;i=2*i+1) { if(i<end&&arr[i]&
順序表儲存實現氣泡排序,選擇排序,插入排序,希爾排序,基數排序
#include<iostream> using namespace std; const int MAXSIZE = 100; typedef int ElemType; struct Data { ElemType key; // int shu
Comparator比較器的使用,Map排序
專案開發過程中,總會遇到各種沒有遇見過的需求,今天遇到了一個map排序問題。 Map<String,Object> testMap = new HashMap<String,Object>(); KEY 值的規則是這樣的: xx
排序(冒泡,插入,希爾,歸併,快排,選擇,堆排序,桶排序,基數排序,雞尾酒排序)
穩定的排序 時間複雜度 空間複雜度 氣泡排序 最差、平均O(n^2),最好O(N) 1 雞尾酒排序(雙向氣泡排序) 最差、平均O(n^2),最好O(N) 1 插入排序 最差、平均O(n^2),最好O(N) 1 歸
氣泡排序,插入排序,基數排序,互動排序演算法
一、實驗內容 1、輸入2-10個不為零的正整數,遇到0,代表輸入結束。 2、數字選擇排序方法,1-氣泡排序、2-插入排序、3-基數排序。 3、使用所選排序方法的排序,結果輸出所用方法以及結果,每個數之間用“,”隔開,中間不要有空格。 //===========
八大排序算法之基數排序
輸出 bsp 交換 and del 當前 print [] radixsort 設計思想 它是根據關鍵字中各位的值,通過對排序的N個元素進行若幹趟“分配”與“收集”來實現排序的。它不要比較關鍵字的大小。 假設:R {50, 123, 543, 187, 49, 30
排序算法之基數排序
java 算法 排序 根據維基百科,基數排序的定義為: 基數排序(英語:Radix sort)是一種非比較型整數排序算法,其原理是將整數按位數切割成不同的數字,然後按每個位數分別比較。由於整數也可以表達字符串(比如名字或日期)和特定格式的浮點數,所以基數排序也不是只能使用於整數。 基數排序的思路是
排序演算法10——圖解基數排序(次位優先法LSD和主位優先法MSD)
排序演算法1——圖解氣泡排序及其實現(三種方法,基於模板及函式指標) 排序演算法2——圖解簡單選擇排序及其實現 排序演算法3——圖解直接插入排序以及折半(二分)插入排序及其實現 排序演算法4——圖解希爾排序及其實現 排序演算法5——圖解堆排序及其實現 排序演算法6——圖解歸併排序及其遞迴與非
基數排序與鏈式基數排序
折騰資料結構實驗的時候遇到這一個演算法。之前對此不甚瞭解,總算也找到一篇不錯的文章。轉載如下 基數排序 (Radix Sort) 基數排序是採用“分配”與“收集”的辦法,用對多關鍵碼進行排序的思想實現對單關鍵碼進行排序的方法。 多關鍵碼排序: 1.以撲克牌排序為例。每張
內部排序演算法5(基數排序)
基數排序 多排序碼排序的概念 如果每個元素的排序碼都是由多個數據項組成的組項,則依據它進行排序時就需要利用多排序碼排序。實現多排序碼排序有兩種常用的方法,最高位優先(Most Significant Digit (MSD) First)和最低位優先(Le
非比較排序之 計數排序與基數排序
非比較排序 與插入、希爾、快速、歸併、堆排序等等排序方式不同的是 以上這些排序演算法都涉及到待排序列中元素值的比較。 然而也有不需要比較的排序演算法。 計數排序 計數排序主要思想: 給定一組要排序的序列,找出這組序列中的最大值,然後開闢一個最
非比較排序:計數排序、桶排序、基數排序
一:什麼是非比較排序 眾所周知,排序有很多種辦法,其中無非就是比較陣列中的值,另一種就是一種分配的思想,類似於一個蘿蔔一個坑,這也就是非比較排序。二:有哪些非比較排序呢? 可以分為三大類 計數排序 、 基數排序 、 桶排序 。這是比較常見的三種排
排序演算法(六)非比較排序----計數排序和基數排序
前邊的幾篇文章介紹的幾種排序演算法都是比較排序,接下來的文章將會介紹兩種非比較排序。 計數排序: 計數排序通過雜湊的方法將一組資料對映到一個數組裡,最後將陣列中的數依次讀取,並寫進原來的陣列,讀出的資