
Deep Learning及NLP(自然語言處理)雜談--第二部分
本雜談分為三個部分,此文為第二部分。
第二部分總結
這一部分主要講了四個對NLP方面效果比較好的模型:1.GRUs(Gated Feedback Recurrent Neural Networks) 2.LSTMs(Long Short-Term Memory]) 3.Recurrent neural network 4.Recursive neural network
語言模型就是計算一串單詞是否是“合理”、“正確”的一串單詞的概率。
這個東東很有用哦。1.在機器翻譯方面,我們都知道不同語言的語序可能會不一樣,日本人說中文常常會說成“你的什麼的幹活”這種形式。這就犯了一個使用日語語法,但是使用中文單詞的錯誤。2.在單詞的選擇方面也很有用處,還是上一個例子“你的什麼的幹活”如果地道的中國人說應該是“你是做什麼的”。如果語言模型合理的話P("你的什麼的幹活")會小於P(“你是做什麼的”),以上兩個就是LM的最廣泛的用處。
以上四個models是近些年才被人廣泛引起重視的models,在廣泛重視這四個models之前還有使用過其他的language models如果學過PGM(概率圖模型)的朋友一定知道,之前使用的語言模型現今大多被稱作Traditional language models而在TLM裡最著名的就是基於Markov assumption的models。
這種模型常用的是unigrams和bigrams也就是隻基於之前的一個或者兩個單詞。
Recurrent neural network
Recurrent NN很符合人們對語言的簡單認識,人們不論是說話還是寫作都是順序的(sequence)把一串文字說出來,Recurrent NN就試圖模擬這個過程。
而且和傳統語言模型不同的是理論上Recurrent NN中某一個單詞出現的概率是會基於之前所有單詞的概率的。
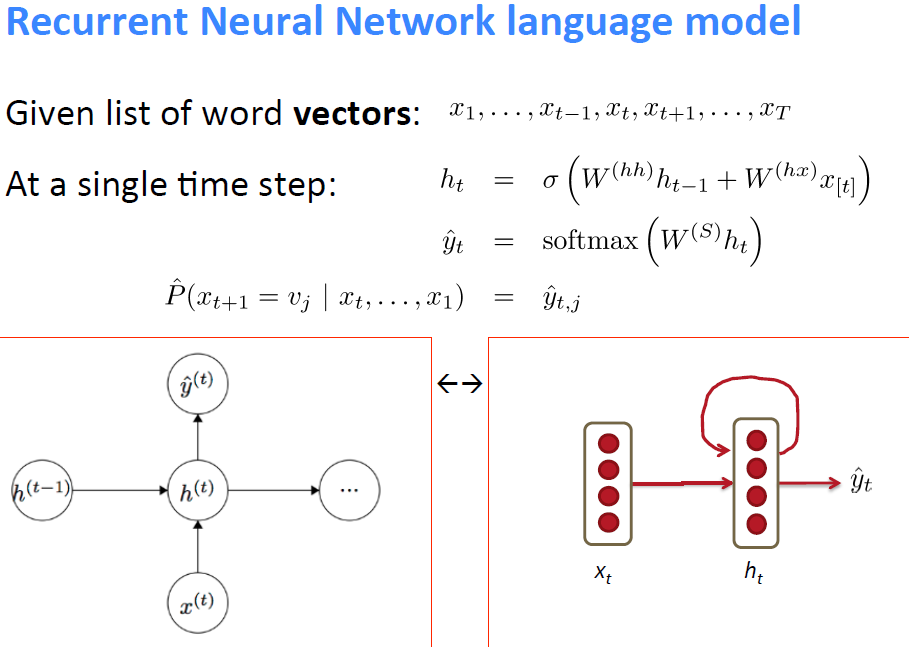
上圖就是Recurrent NN的一個通用的(temporal)模組,把這麼一個模組向左或者向右可以無限延伸,也就構成了一個language model
Recurrent NN的調優
NN存在兩個固有的問題,一個是vanishing,另一個是exploding。
這兩個問題其實在很小的NN中也存在只是Recurrent NN非常的長這兩個問題也就凸顯的比較明顯罷了。
下面說說對於這兩種問題的處理方法:
vanishing
vanishing顧名思義就是error rate從之前的node傳下來的越來越小以至於之前的node的更新速度非常慢,理論上這個model在無限長的時間內肯定能夠調優,但是我們有可能沒有那麼多的資料,也沒有那麼多的時間。
1.解決方法就是從問題的癥結處入手。error從上一node傳下來如果本node的|weight| < 1的話那麼下一層得到的error就會比這一層的小,鑑於此我們在初始化weight的時候先把所有的weight都初始化為identity matrix
2.error從上一node傳下來如果本node的|non-linear| < 1的話那麼下一層得到的error也會比這一層的小,鑑於此我們使用Relu unit作為non-linear unit這樣error在通過non-linear unit的時候就不會衰減。
exploding
之前介紹的是vanishing的情況,vanishing出現的機率要大一些,但是有時候也會出現error exploding的情況。
這樣的話就會使得node裡的weight在調優的時候幅度(scale)過大適得其反了。
我們使用clipping trick來處理這種情況。

一旦超過threshold就clip,以此來防止gradient的步幅過大
threshold一般選擇範圍是3~5。
Recurrent NN的一種改進措施
在softmax處改進
在Basic圖裡我們計算y_hat的時候用到了softmax,softmax在詞庫(vocabulary)很大的時候計算的cost是很大的。由此在這方面入手提出改進措施。
可以在word和預測的history之間增添一個class。class的數目肯定就比vocabulary的數目小很多了。然後在算p(w_t | c_t)這樣就能在不顯著降低performance的情況下大幅度提高運算速度。
在模型本身改進
這裡講講在模型本身改進model的方法,前面的recurrent NN是最簡單最原始的recurrent NN顯然它所能達到的精確度不能達到人們的要求。追究其原因就是因為它所能提取出的資訊太少了。於是我們把模型改造的複雜一些使它能提取出更多的資訊。
有兩種改良的措施第一種是Bidirectional RNNs就是你當前的單詞是什麼不僅僅取決於你之前的單詞,還取決於你之後的單詞。第二種是Deep Bidirectional RNNs就是能夠更多的提取出資訊。測試結果是使用Deep Bidirectional RNNs效果更好。
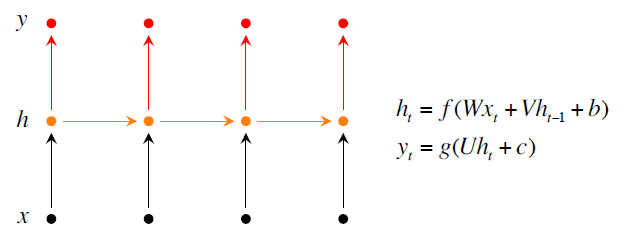
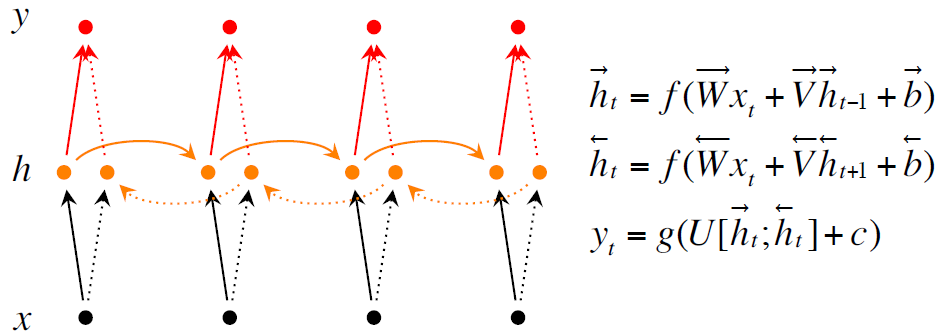
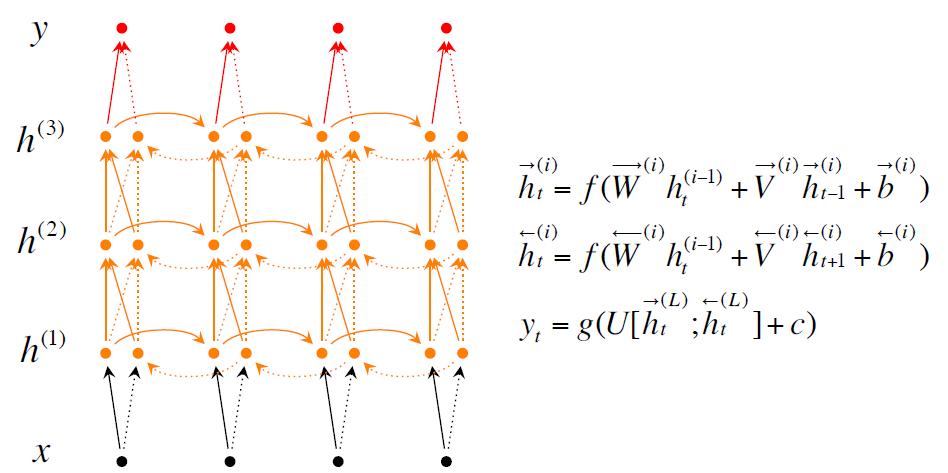
上面三張圖分別是普通的Recurrent NN, Bidirectional RNNs, Deep Bidirectional RNNs
Recurrent NN在MT方面的應用
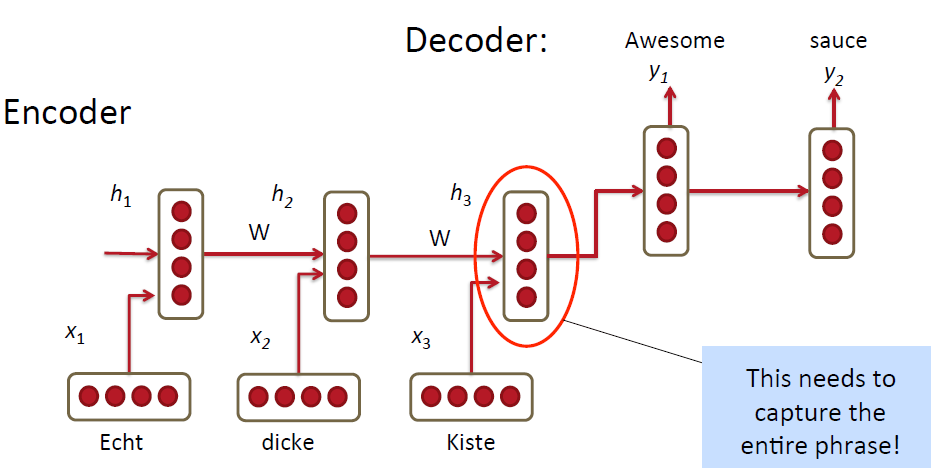
上圖是屌絲版本,也就是最原始的處理方法。使用RNN把source language的單詞一個一個的輸入到model裡,最終把這一整句話用一個vector表示出來,也就是encoder的過程;然後得到最終的vector之後再decoder將原始的句子用target language表示出來。看起來挺誘人挺高效的有木有!但是其實米有這麼簡單呀!
改良版
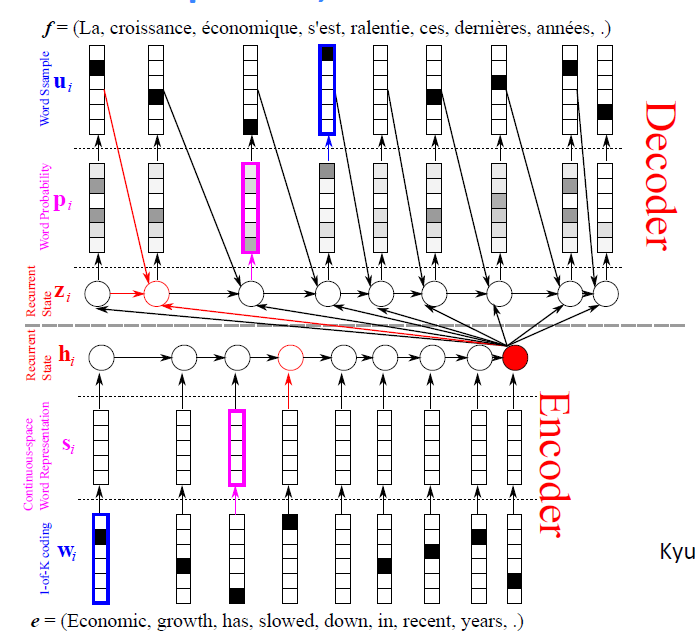
decoder的過程不僅僅是從最後一個hidden node(以下簡寫為C)中提取資訊,還從前一個decoder出來的單詞及前一個hidden node裡提取資訊。
還有幾個改良方法就和上一講講得類似了一是改良方法是使用stacked/deep RNNs;二是使用bidirectional encoder,而不是使用最簡單的一層的encoder。
還有一個改良方法是把單詞的順序倒個個,原因說的是第一個單詞的資訊能很容易保留下來,然後target language就能很容易從中提取出資訊,做出有效的翻譯。
GRU
GRU其實也可以認為是Recurrent NN一種改良版,他是針對Recurrent NN的兩個問題進行了改進。一個問題是越靠前的單詞對當然hidden node的影響會越小,第二個問題是產生error的時候這個error可能是有某一位或者某幾位單詞誘發的,所以應當僅僅對某一位或者某幾位單詞的weight進行update。
main ideas: 1.keep around memories to capture long distance dependencies
2.allow error messages to flow at different strengths depending on the inputs
GRU的思路是首先根據當前word vector及前一個hidden state計算出update gate和reset gate;再根據reset gate、當前word vector及前一個hidden state計算出new memory content。
reset gate的用處很明確了,就是當reset gate為1的時候,new memory content忽略之前所有的memory。最終的memory是之前的hidden node及new memory content的綜合體
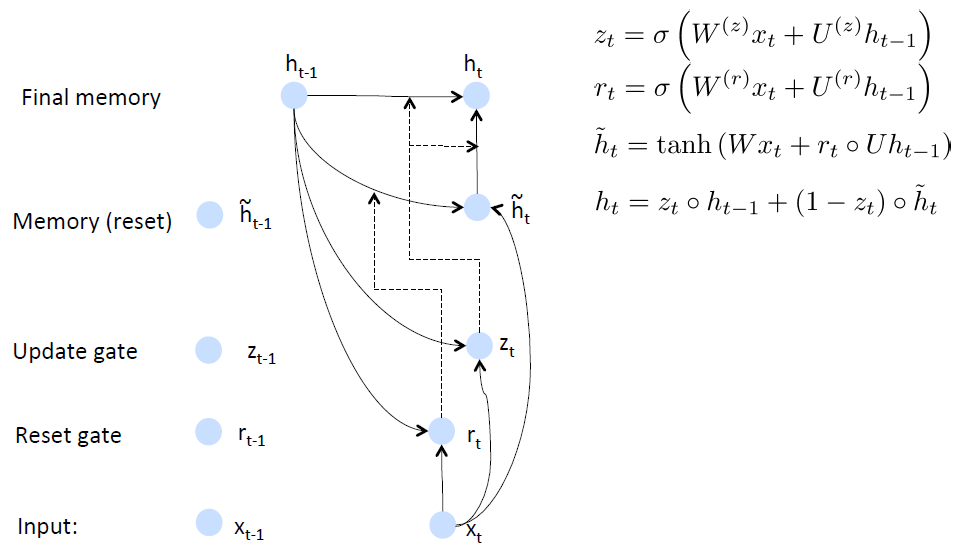
LSTMs
LSTMs所針對的問題其實也是上面說的兩個問題。

GRUs和LSTMs的區別
說實話GRU和LSTMs其實是很像的先上個對比圖吧:
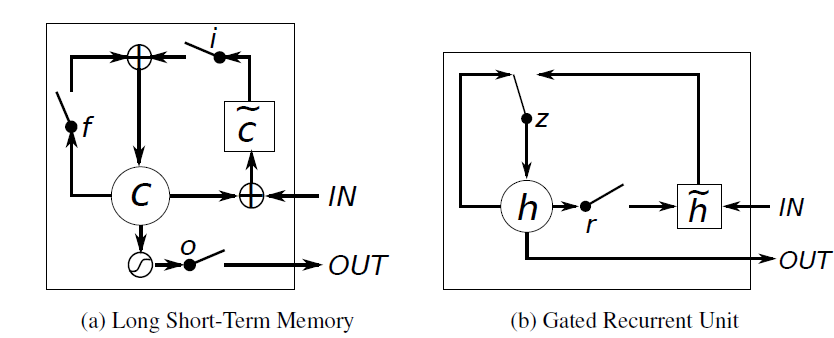
以下說說他們之間的相同與不同:
1.new memory的計算方法都是根據之前的state及input計算,但是GRU有一個R gate控制之前state的進入量,在LSTM裡沒有這個gate
2.產生新的state的方式不同,LSTM有兩個不同的gate分別是f gate和i gate;GRU只有一個gate就是z gate
3.LSTM對新產生的state有一個o gate可以調節大小;GRU直接輸出無任何調節。
Recursive NN
Parsing
在一定程度上可以認為Recurrent NN是Recursive NN的一種變體。Recursive NN更general。
一個句子的意思是基於1.這個句子所包含的單詞的意思;2.這個句子的構建方式。
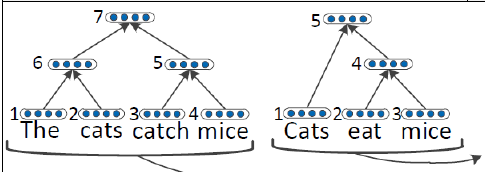
這樣我們就知道了首先得學出來某一個句子的Parsing Tree。下圖就是Parsing tree的例子。上面的是recursive NN的parsing tree,下面的是recurrent NN的parsing tree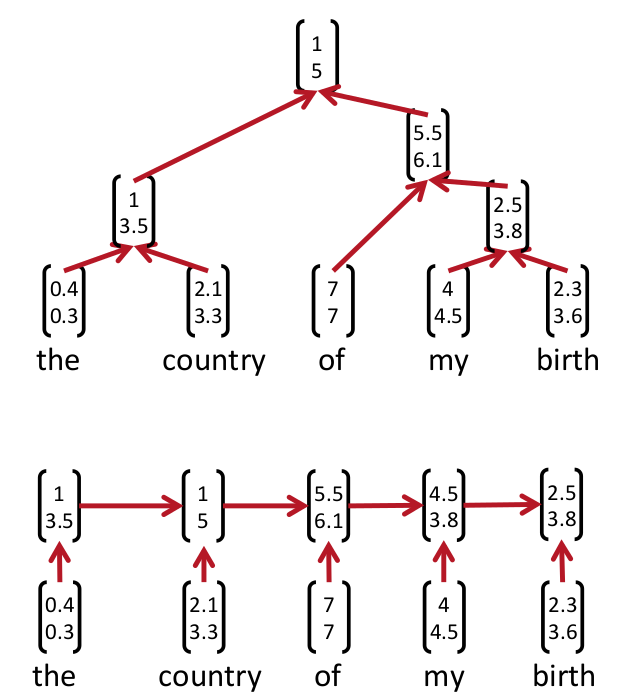
學習出這個parsing tree的方法叫beam search就是bottom-up的方法,從最低下開始,計算哪兩個成為好基友的score最大,然後取出來最大的score的倆個node然後他倆就merge了(好邪惡)。最後一直到最上面全部都merge起來了就形成了一個parsing tree。
models
在學出來parsing tree之後下一步就要對parsing tree建立model了
有四個比較出名的recursive NN

standard RNNs
RNNs for Paraphrase Detection主要包含兩個方面。第一方面是Recursive Autoencoder,第二方面是Neural Network for Variable-Sized Input
這個模型在第二篇paper裡講得很詳細。
首先我們已經有了一個parse tree,有一個可信的parse tree對於paraphrase detection很重要。
Recursive Autoencoder有兩種Autoencoder的方法。
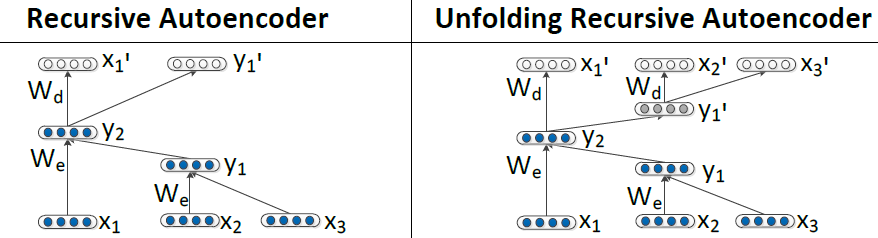
第一種是左邊的這種,每次decoder只decoder出一層,然後求所有non-terminal nodes的error的和作為loss function。non-terminal nodes的error是其兩個children的vectors先連接出來,然後再求歐式距離得到的。
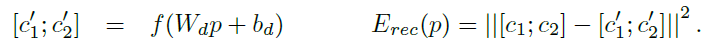
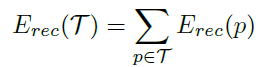
上面兩式中,其中下面的式子中的T集合是所有non-terminal nodes,上面的式子中的c1, c2分別是p的兩個children
由於non-terminal nodes的值可以通過無限shrinking the norms of the hidden layers來實現,所以必須對non-terminal nodes的值p進行normalization
第二種是上面圖片裡右邊的那種reconstruct the entire spanned subtree underneath each nodes
就是把所有的leaf nodes全部decode出來,然後把所有leaf nodes連線起來,求歐式距離作為loss function
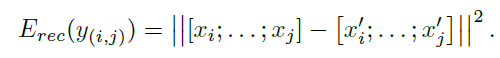
上面的model tune好了,然後進行下一個階段。
以上是tune好的tree
首先先建立一個similarity matrix,其中column和row分別按照單詞的從左到右的順序以及上面的hidden nodes從下到上從右到左的順序排列
第二步是pooling,其中pooling layer的是一個square matrix先對#col及#row取一個fixed值,設為n_p。論文裡是使用的非over-lapping的方法,就是不重疊行或者列。
如果#col > n_p, #row > n_p,每#col/n_p及#row/n_p作為一個pool最後會剩下一個比較小的pool行或者列都小於n_p。
如果#col < n_p,#row < n_p,先duplicating pixels小於n_p的那一邊,然後直到那一邊的pixels大於n_p為止。
在每個pool裡取其最小值,然後在pool之後normalize每個entry使其mean = 0及variance = 1
paper裡提到了一個對於數字的改進方法:第一如果兩個句子裡的數字完全一樣或沒有數字,設為1,反之設為0;第二如果兩個句子裡包含一樣的數字,設為1;第三一個句子裡的數字嚴格的是另一個句子裡數字的子集,設為1
這種方法有兩個缺點:第一是僅僅比較單詞或者phrase的相似性遺失了語法結構;第二是計算similarity matrix也遺漏了部分資訊。
最後把得到的similarity matrix輸入到一個NN裡或者softmax classifier裡再建立loss function就能進行優化計算了。
Matrix-Vector RNNs
Matrix-Vector RNNs這個模型比較簡單就是在表示一個word的時候不僅僅只用vector的形式表示,用matrix加vector結合起來的方式表示一個word
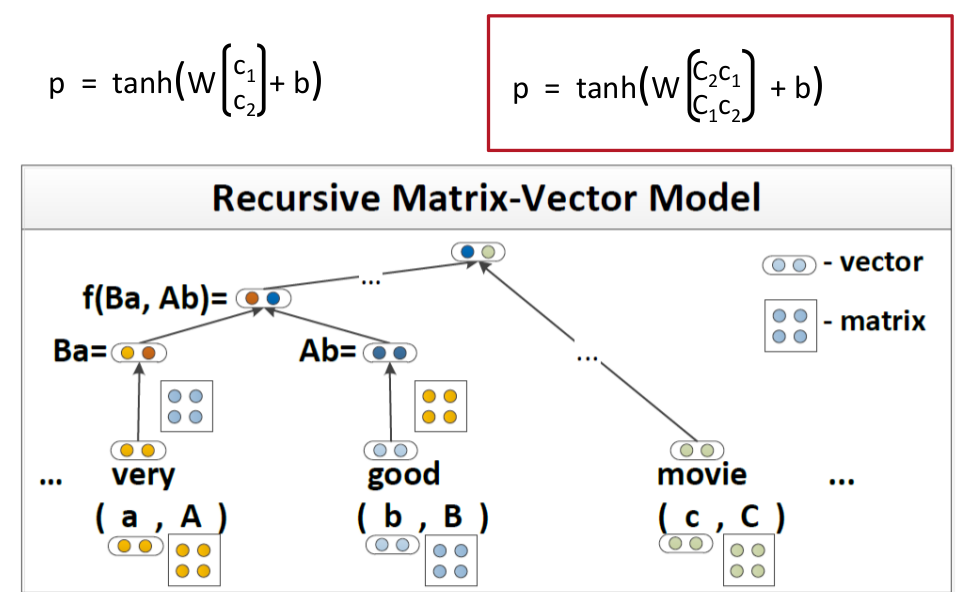
以上就是Matrix-Vector的表示方法,和stardard的差異比較小。
課上說這個模型對Relationship Classification的效果比較好。
Relationship Classification簡單的說就像以前中學從一句話裡提取出關鍵詞。
RNTN
Bag-of-words的方式進行sentiment detection比較不靠譜,因為bag-of-words不能capture一個句子的parse tree還有linguistic features
使用好的corpus也會提高精確度,很誘人哦!
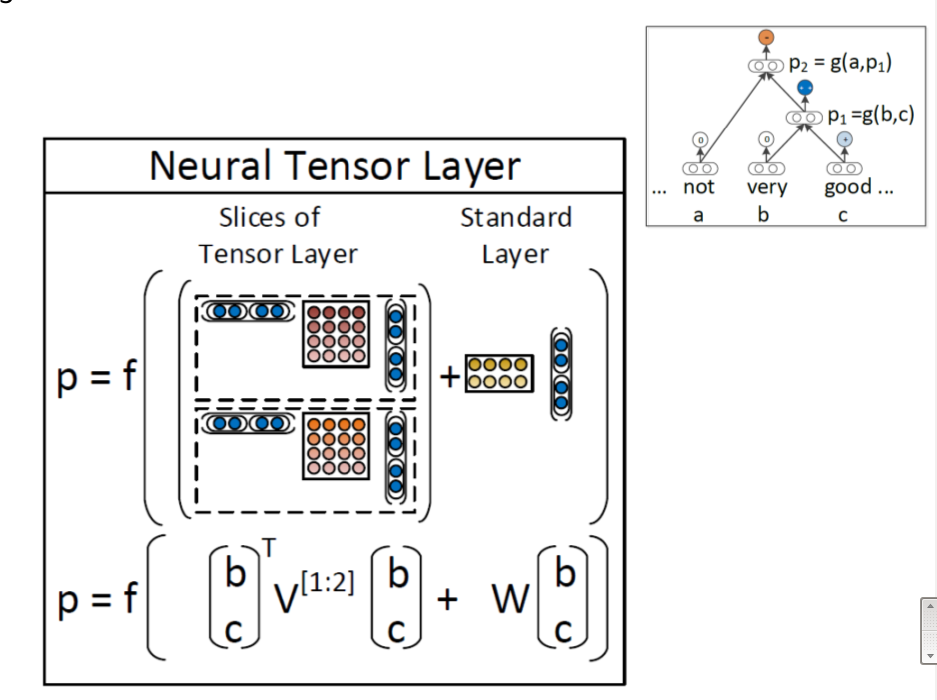
其實整體模型改動也不太大,也很好理解,這樣就能很好的捕捉到句子的sentiment
這個模型的優化和之前的略有不同:

這個模型據說是現今唯一能夠capture negation及其scope的模型。
Tree LSTMs
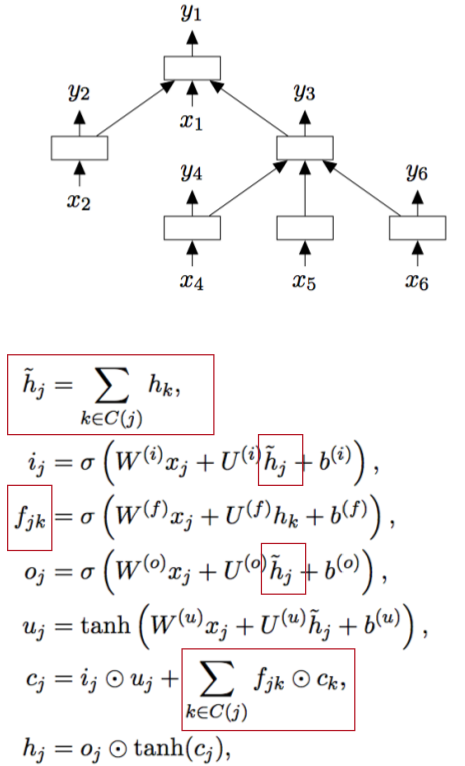
Tree LSTMs和普通的LSTMs的不同之處在於Tree LSTMs是從tree的結構中進行LSTMs的建模。
普通的LSTMs也可以看作是Tree LSTMs的一種特殊情況。
Tree LSTMs裡leaf node的hidden計算和之前的普通的hidden計算方法一樣,只是其parents的計算略有不同。具體公式見上圖。
parent的hidden是其children的hiddens的和,每一個forget unit是根據具體的某個node來計算的,計算最終cell時要把所有forget units和對應的cells相乘並求和,其他都是和普通LSTMs一樣的計算方法了。
這個模型對於semantic similarity目前還是最適用的。如圖:
有用的連結
GRU LSTM
http://www.ubi.com/
https://github.com/jych/librnn.git
recursive NN
nlp.stanford.edu
http://repository.cmu.edu/robotics
www.socher.org
HW
Python generators
The difference between range and xrange
退火演算法:
相關推薦
Deep Learning及NLP(自然語言處理)雜談--第二部分
本雜談分為三個部分,此文為第二部分。 第二部分總結 這一部分主要講了四個對NLP方面效果比較好的模型:1.GRUs(Gated Feedback Recurrent Neural Networks) 2.LSTMs(Long Short-Term Memory]
Deep Learning及NLP(自然語言處理)雜談--第三部分
歡迎轉載,轉載請註明出處: 本雜談分為三個部分,此文為第一部分。 第一部分 第二部分 第三部分 第三部分 這一部分只介紹了一個model,就是在CV領域大名鼎鼎的CNN其他課程大多請的外賓過來講課,講得都是DL如何在實際情況下的應用。 CNN
NLP自然語言處理常用的Python庫 及安裝方法
1、NLTK Natural Language Toolkit,自然語言處理工具包,在NLP領域中,最常使用的一個Python庫。 安裝:pip install nltk 2、Gensim 可以用來從文件中自勱提取語義主題。它包含了很多非監督學習演算法如:TF/IDF,潛在語義分
NLP自然語言處理相關技術說明及樣例(附原始碼)
https://segmentfault.com/a/1190000010320214 1、簡單概述 1.1 NLP概念 NLP(Natural Language Processing),自然語言處理,又稱NLU(Natural Language Understan
[NLP自然語言處理]谷歌BERT模型深度解析
BERT模型程式碼已經發布,可以在我的github: NLP-BERT--Python3.6-pytorch 中下載,請記得start哦 目錄 一、前言 二、如何理解BERT模型 三、BERT模型解析 論文的核心:詳解BE
NLP自然語言處理例項:預測天氣冷暖
NLP:自然語言處理(Natural Language Processing)是人工智慧和語言學領域的分支學科。主要包括自然語言理解和生成,自然語言理解系統把自然語言轉化為計算機程式更易於處理的形式即讓電腦懂人類的語言。自然語言生成系統把計算機資料轉化自然語言。 處理過程:形式化描述->數
facebook NLP 自然語言處理框架 Pytext 簡介
自然語言處理(NLP)在現代深度學習生態中越來越常見。從流行的深度學習框架到雲端API的支援,例如Google雲、Azure、AWS或Bluemix,NLP是深度學習平臺不可或缺的部分。儘管已經取得了令人難以置信的進步,但構建大規模的NLP應用依然還有極大的挑戰,在學習研究和生產部署之間還存
NLP--自然語言處理與機器學習會議
整理至11月中旬在重慶參加的自然語言處理與機器學習會議,第一講為自然語言處理。 由基本理論到實際運用,整理了基本的框架。 1. 自然語言處理基礎 詞性標註(POS): 為句子中的每個詞語標註詞性,可看做是句法分析的關鍵任務,也可以看做是句法分析的最低層次.對後
NLP自然語言處理庫系列教程——gensim庫
Gensim是一款開源的第三方Python工具包,用於從原始的非結構化的文字中,無監督地學習到文字隱層的主題向量表達。它支援包括TF-IDF,LSA,LDA,和word2vec在內的多種主題模型演算法,支援流式訓練,並提供了諸如相似度計算,資訊檢索等一些常用任務
NLP自然語言處理入門-- 文本預處理Pre-processing
檢查 bag 領域 影響 rds except clean numpy 我只 引言 自然語言處理NLP(nature language processing),顧名思義,就是使用計算機對語言文字進行處理的相關技術以及應用。在對文本做數據分析時,我們一大半的時間都會花在文本
初識NLP 自然語言處理(一)
系統 語言 數學 實現 一段 這一 如何 其中 proc 接下來的一段時間,要深入研究下自然語言處理這一個學科,以期能夠帶來工作上的提升。 學習如何實用python實現各種有關自然語言處理有關的事物,並了解一些有關自然語言處理的當下和新進的研究主題。 NLP,Natur
NLP自然語言處理中英文分詞工具集錦與基本使用介紹
一、中文分詞工具 (1)Jieba (2)snowNLP分詞工具 (3)thulac分詞工具 (4)pynlp
NLP自然語言處理
# NLP ## 應用例子 - 垃圾郵件過濾 Spam Filtering - 機器翻譯 Machine Translation - 資訊檢索 Information Retrieval - 問答系統 Question Answering - 資訊提取 Information Extraction - 內
統計自然語言處理(第二版)筆記1
這也 輸出 法規 ret 規則 輸入 允許 信號 analysis 第一章緒論 1.1基本概念 1.1.1語言學與語音學 語言學(linguistics)是指對語言的科學研究。 語音學(phonetics)是研究人類發音特點,特別是語音發音特點,並提出各種語音描述、
聊天機器人(chatbot)終極指南:自然語言處理(NLP)和深度機器學習(Deep Machine Learning)
為了這份愛 在過去的幾個月中,我一直在收集自然語言處理(NLP)以及如何將NLP和深度學習(Deep Learning)應用到聊天機器人(Chatbots)方面的最好的資料。 時不時地我會發現一個出色的資源,因此我很快就開始把這些資源編製成列表。 不久,我就
自然語言處理(NLP)的基本原理及應用
本文由Markdown語法編輯器編輯完成。 自然語言處理要解決的主要問題有: (1)垃圾郵件識別 (2)中文輸入法 (3)機器翻譯 (4)自動問答、客服機器人 這裡簡單羅列了一些NLP的常見
阿里自然語言處理部總監分享:NLP技術的應用及思考
本文整理自阿里巴巴iDST自然語言處理部總監郎君博士的題為“NLP技術的應用及思考”的演講。本文從NLP背景開始談起,重點介紹了AliNLP平臺,接著分享了NLP相關的應用例項,最後對NLP的未來進行了思考。 背景介紹 阿里巴巴的生態系統下面有很多的計算平臺,上面
自然語言處理中的Attention Model:是什麽及為什麽
機器 逆序 mar 回來 是什麽 all 意義 及其 creation /* 版權聲明:可以任意轉載,轉載時請標明文章原始出處和作者信息 .*/ author: 張俊
NLP系列(1)_從破譯外星人文字淺談自然語言處理的基礎
應用 展現 發現 func 文本 詞幹 pos 中文分詞 漢語 作者:龍心塵 &&寒小陽 時間:2016年1月。 出處: http://blog.csdn.net/longxinchen_ml/article/details/505
(zhuan) 自然語言處理中的Attention Model:是什麽及為什麽
機器 pri 概念 max page acf 集中 use tps 自然語言處理中的Attention Model:是什麽及為什麽 2017-07-13 張俊林 待字閨中 要是關註深度學習在自然語言處理方面的研究進展,我相信你一定聽說過Attention Model(